大學畢業了!!上來感嘆一下!并拿出自己的畢業設計分享一下。
這個小東西是用了一個星期完成的。BUG肯定不少,大家湊合著看一下吧。感覺有趣的就拿去玩玩。
說說基本思路。
1.對文件進行分詞處理
2.通過統計訓練文檔當中的詞頻方差,構造評判矩陣
3.之后在構造待分類文檔的評判向量
4.用評判向量和構造矩陣相乘,選出最接近的分類。
具體地方法大家可以參考一下這篇論文:《基于模糊理論的網頁過濾算法的實現》
上圖:
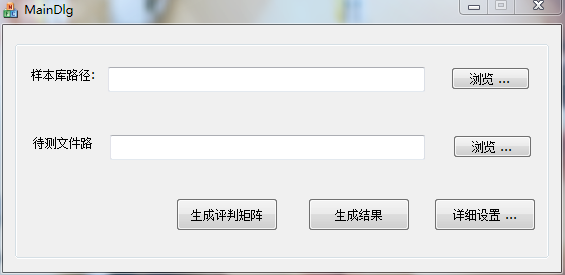
主界面
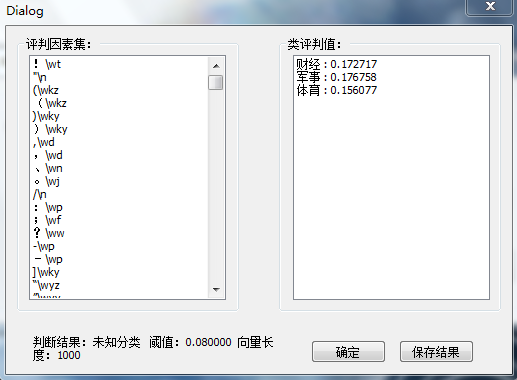
結果文件
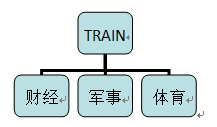
訓練文檔的目錄結構
程序文件:
http://www.namipan.com/d/db9717e2153a1bc504dc597fee9ac32e92b428fcc4fe3900其實正確率還可以進一步提高的。以后有興趣的時候再來重寫一下這個程序吧。
總結:
我盡力優化了這個程序的速度。但還是不理想。
ICTCLAS分詞系統的效率低是其中一個重要原因。
我使用了stlsoft中的aoto_buffer來優化內存的分配。
使所有的string在內存當中只存在一份拷貝。
map和vector容器永遠只存放string*
無法解決的問題:
我想在一個double數組中存放1/N,2/N,3/N......N/N,以便后來使用。
我覺得這些常量應當能在編譯時期確定。但是不知道如何通過定義宏來表示這些數值。
搞的我最后不得不啟動一個線程來專門計算這些值。
有興趣的郵件聯系啊~!
posted on 2009-06-12 21:38
HIT@ME 閱讀(1423)
評論(2) 編輯 收藏 引用