傳統的系統調用是怎樣的? —— int 0x80的時代
.... ;通過寄存器傳參
mov $n ,eax ;將系統調用號放到eax中
int 0x80
sysenter/sysexit的出場
在一個Kernel.org的郵件列表中,有一封郵件討論了“"Intel P6 vs P7 system call performance”,最后得出的結論是采用傳統的int 0x80的系統調用浪費了很多時間(具體原因可以看參考資料1),而sysenter/sysexit可以彌補這個缺點,所以決定在linux內核中用后都替換前者(最終在2.6版本的內核中才加入了此功能,即采用sysenter/sysexit)。
在替換之前首先需要知道滿足如下條件的ntel機器才會有sysenter/sysexit指令對:Family >= 6,Model >= 3,Stepping >= 3
如何用替換sysenter/sysexit替換以前的int 0x80呢?linux kenerl 需要考慮到這點:有的機器并不支持sysenter/sysexit , 于是它跟glibc說好了,“你以后調用系統調用的時候就從我給你的這個地址調用,這個地址指向的內容要么是int 0x80調用方式,要么是sysenter/sysexit調用方式,我會根據機器來選擇其中一個”(kernel與glibc的配合是如此的默契),這個地址便是vsyscall的首地址。
可以將vdso看成一個shared objdect file(這個文件實際上不存在),內核將其映射到某個地址空間,被所有程序所共享。(我覺得這里用到了一個技術:多個虛擬頁面映射到同一個物理頁面。即內核把vdso映射到某個物理頁面上,然后所有程序都會有一個頁表項指向它,以此來共享,這樣每個程序的vdso地址就可以不相同了)
hex108@ubuntu:~/program$ uname -a
Linux ubuntu 2.6.35-22-generic #33-Ubuntu SMP Sun Sep 19 20:34:50 UTC 2010 i686 GNU/Linux
hex108@ubuntu:~/program$ sudo sysctl -w kernel.randomize_va_space=0 //這個是必須的,否則vdso的地址是隨機的(vsyscall的地址也會相應
// 地發生變化 ),在下面dd的時候就會出現錯誤
//dd: reading `/proc/self/mem': Input/output error
kernel.randomize_va_space = 0
hex108@ubuntu:~/program$ cat /proc/self/maps
00110000-0012c000 r-xp 00000000 08:01 260639 /lib/ld-2.12.1.so
0012c000-0012d000 r--p 0001b000 08:01 260639 /lib/ld-2.12.1.so
0012d000-0012e000 rw-p 0001c000 08:01 260639 /lib/ld-2.12.1.so
0012e000-0012f000 r-xp 00000000 00:00 0 [vdso]
0012f000-00286000 r-xp 00000000 08:01 260663 /lib/libc-2.12.1.so
00286000-00287000 ---p 00157000 08:01 260663 /lib/libc-2.12.1.so
00287000-00289000 r--p 00157000 08:01 260663 /lib/libc-2.12.1.so
00289000-0028a000 rw-p 00159000 08:01 260663 /lib/libc-2.12.1.so
0028a000-0028d000 rw-p 00000000 00:00 0
08048000-08051000 r-xp 00000000 08:01 130326 /bin/cat
08051000-08052000 r--p 00008000 08:01 130326 /bin/cat
08052000-08053000 rw-p 00009000 08:01 130326 /bin/cat
08053000-08074000 rw-p 00000000 00:00 0 [heap]
b7df0000-b7ff0000 r--p 00000000 08:01 660864 /usr/lib/locale/locale-archive
b7ff0000-b7ff1000 rw-p 00000000 00:00 0
b7ffd000-b7ffe000 r--p 002a1000 08:01 660864 /usr/lib/locale/locale-archive
b7ffe000-b8000000 rw-p 00000000 00:00 0
bffdf000-c0000000 rw-p 00000000 00:00 0 [stack]
hex108@ubuntu:~/program$ dd if=/proc/self/mem of=gate.so bs=4096 skip=$[0x12e] count=1
dd: `/proc/self/mem': cannot skip to specified offset
1+0 records in
1+0 records out
4096 bytes (4.1 kB) copied, 0.00176447 s, 2.3 MB/s
hex108@ubuntu:~/program$ file gate.so
gate.so: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked, stripped
hex108@ubuntu:~/program$ objdump -d gate.so
gate.so: file format elf32-i386
Disassembly of section .text:
ffffe400 <__kernel_sigreturn>:
ffffe400: 58 pop %eax
ffffe401: b8 77 00 00 00 mov $0x77,%eax
ffffe406: cd 80 int $0x80
ffffe408: 90 nop
ffffe409: 8d 76 00 lea 0x0(%esi),%esi
ffffe40c <__kernel_rt_sigreturn>:
ffffe40c: b8 ad 00 00 00 mov $0xad,%eax
ffffe411: cd 80 int $0x80
ffffe413: 90 nop
ffffe414 <__kernel_vsyscall>:
ffffe414: cd 80 int $0x80
ffffe416: c3 ret
syscall 才是最后的贏家?
x86 64位從AMD引進了syscall指令(我在x86 64的機器上,看到的結果是syscall取代了sysenter/sysexit(所有的系統調用用的都是syscall)),但是vdso,vsyscall的機制依舊未變,只是kernel決定只在遇到以下幾個系統調用gettimeofday,time和getcpu(通過內核里vsyscall.h中enum vsyscall_num的聲明看出來,或者在glibc源代碼中搜索“VSYSCALL_ADDR_”(
#define VSYSCALL_ADDR_vgettimeofday 0xffffffffff600000
#define VSYSCALL_ADDR_vtime 0xffffffffff600400
#define VSYSCALL_ADDR_vgetcpu 0xffffffffff600800
))時才采用vdso機制(間接調用syscall,具體可以參看資料2),其他系統調用直接用指令syscall,原因是:
"快速系統調用指令"比起中斷指令來說,其消耗時間必然會少一些,但是隨著 CPU 設計的發展,將來應該不會再出現類似 Intel Pentium4 這樣懸殊的差距。而"快速系統調用指令"比起中斷方式的系統調用方式,還存在一定局限,例如無法在一個系統調用處理過程中再通過"快速系統調用指令"調用別的系統調用。因此,并不一定每個系統調用都需要通過"快速系統調用指令"來實現。比如,對于復雜的系統調用例如 fork,兩種系統調用方式的時間差和系統調用本身運行消耗的時間來比,可以忽略不計,此處采取"快速系統調用指令"方式沒有什么必要。而真正應該使用"快速系統調用指令"方式的,是那些本身運行時間很短,對時間精確性要求高的系統調用,例如 getuid、gettimeofday 等等。因此,采取靈活的手段,針對不同的系統調用采取不同的方式,才能得到最優化的性能和實現最完美的功能。 ----引自參考資料1
ps:文中的內核版本為2.6.36,glibc版本為2.11
參考資料:
1. Linux 2.6 對新型 CPU 快速系統調用的支持: http://www.ibm.com/developerworks/cn/linux/kernel/l-k26ncpu/index.html (這篇我覺得最好)
2. System Calls : http://www.win.tue.nl/~aeb/linux/lk/lk-4.html(里面有程序可以用來搜索vsyscall等的地址,很直接)
3. What is linux-gate.so.1 : http://www.trilithium.com/johan/2005/08/linux-gate/
4. Intel手冊,里面有各種資料,手冊還是很重要的,也是最基本的
posted @
2010-11-22 21:19 hex108 閱讀(12392) |
評論 (0) |
編輯 收藏
摘要: lisp的功能還是挺強大的,簡單的幾行代碼就搞定了一個小的“數據庫”(經驗:調試macro的時候可以用macroexpand-1展開該macro,看是否與設想的一樣。)。
閱讀全文
posted @
2010-10-01 22:23 hex108 閱讀(1024) |
評論 (0) |
編輯 收藏最近《hackers & painters》學到的印象最深的一點是:lisp比你想像中的還強大,用lisp吧!
1. 安裝運行環境
a. 下載emacs,解壓即可。
b. 下載slime,解壓即可
c. 下載sbcl,安裝
d. 配置emacs
首先需要確定emacs會加載哪里的.emacs配置文件(即emacs的HOME目錄為什么),可以通過改注冊表(新添注冊表項HKEY_CURRENT_USER\Software\GNU\Emacs(新建一個GNU項,然后在GNU項下新建一個子項Emacs),新增一個項HOME,設置其字符串值為emacs解壓后的目錄)
在emacs解壓后的目錄中,新建一個.emacs文件,添加如下幾行:
;for lisp mode
(add-to-list 'load-path "D:\\slime\\") ; 注:在windows下路徑分隔符為\\而不是\,否則會被解釋為 D:slime, 或者改成另外一種寫法 D:/slime
(setq inferior-lisp-program "D:\\SteelBankCommonLisp\\sbcl.exe") ;注:如果此處路徑有空格,在M-x slime時會出現問題:apply: Spawning child process: invalid argument
;(setq inferior-lisp-program "D:\\clisp-2.49\\clisp.exe")
(require 'slime-autoloads) ;注意這里加載的是 slime-autoloads,而不是 slime,要不然C-c C-c等很多功能都沒有
(slime-setup '(slime-fancy))
;(slime-setup)
2. 編譯運行
如果要進入用戶交互界面,輸入 M-x slime即可
如果要編譯lisp文件里的函數:a. 只編譯某個函數,可以將光標放在該函數上,然后按C-c C-c
The easiest is to type C-c C-c with the cursor anywhere in or immediately after the DEFUN form, which runs the command slime-compile-defun, which in turn sends the definition to Lisp to be evaluated and compiled.
b. C-c C-c只能編譯單個函數,如果文件內一些函數有關聯,則這種方式就不好用了,此時可以編譯整個文件
(load “lisp_file”)
c. load 某個文件后,如果又修改了該文件中的某個函數,則可以再用C-c C-c編譯該函數而不需要重新load該文件
posted @
2010-10-01 22:03 hex108 閱讀(8004) |
評論 (4) |
編輯 收藏
一個內存地址存著一個對應的值,這是比較容易理解的。
如果程序員必須清楚地知道某塊內存存著什么內容和某個內容存在哪個內存地址里了,那他們的負擔可想而知。
匯編語法對“一個內存地址存著一個對應的數”,作了簡單的“抽象”:
把內存地址用變量名代替了,對內存地址的取值和賦值方式不變。
c語言對此進行了進一步的抽象:變量 <==> (一個內存地址,對應的值)(這里忽略類型等信息)。
把C語言中的基本類型(int,long,float等),指針,數組等還原為(一個內存地址,對應的值)后,就能更清淅地理解它們了。
內存就相當于(addr,val)的大hash表,c語句的語義基本就是改變hash值。
為了下文的方便,特定義如下語義(遵循C的標準語義):
var <==> (addr, val) (var為一個變量名,addr為var在內存中的首地址,val為var 的值)
&var <==> addr
var <==> var作為左值出現(即等式左邊)時,var等價于 addr;
var作為右值出現(即等式左邊)時,var等價于 val;
*var <==> val
注:符號"<==>" 右邊出的等式 x = y(x是一個內存地址,y是一個值); 表示將內存地址為x的內容置為值y,如addr = 3表示置內存addr里的值為3
現在利用上面的語義解釋一下這些例子:
int i = 3;
假設 i的內存地址為 0x8049320 ,那么這句話的語義是0x8049320 = 3,經過i = 3后,i為(0x8049320,3)
int b = i;
假設 b的內存地址為 0x8049324 ,那么這句話的語義是0x8049324 = i對應的val = 3,此時b為(0x8049324,3)
int *p = &b
指針p也是一個變量,int **p,int *p[8],在這些申明中p都只是一個指針變量,它和其他的變量的不同之處在于它的大小是定的,它的類型信息只是編譯器用來進行類型檢查和其他一些作用的(如果沒有類型檢查,你可以用任何的方式對一個變量進行操作如int i; ****i = 3)。假設p的地址為0x8049328,則根據p = &b的語義p.addr = b.addr,p為(0x8049328,0x8049324)
*p = 5;
語義為 0x8049324 = 5,此時只改變了內存地址為0x8049324的值,即改變了b的值(0x8049324,5),而p的值并未改變
int **q = &p; //如果寫為int **q = &&i; gcc編譯不通過
假設q的內存地址為0x8049330,語義為 0x8049330 = addr(p) = 0x8049328;所以q為(0x8049330, 0x8049328)
(int **q = &&i, 要是編譯過了則q應該表示為(0x8049330, x),內存地址為x的地方表示為(x,0x8049320),那么地址x為多少呢? )
**q = 6
語義為 val(val(q)) = val(0x8049328) = 0x8049324 = 6,將內存地址為0x8049324的內容置為6,即將b的值置為6,b為(0x8049324,6)
對于結構,這些語義也適用,因為結構里的成員也是有對應地址的,也能表示為(addr,val)的形式。
對“一個內存地址存著一個對應的值”的抽象程度越高,越不用關心底層,如java。
Haskell已經沒有副作用之說了,更不用關心這些了。
就這些。
posted @
2010-08-21 23:20 hex108 閱讀(5934) |
評論 (7) |
編輯 收藏有作者之一Dave Thomas在敏捷2009大會上關于此書的演講(http://www.infoq.com/cn/presentations/dt-pragmatic-programmer)
這本書的成書方式很有意思。作者非常喜歡program,以至于將這本書的寫作當成了軟件工程,全書用plain text寫成,以soruce code(應 該是他們自己發明的領域語言DSL~)的方式組織而成,用他們自己寫成的工具build一下后就成了此書,相信他們也以某種版本管理工具對此進行了管理(方便查看版本之間的變化等),并對書中的code進行了單元測試。
想像一下他們怎么寫書的(借用HTML的格式猜想一下):
<Title>程序員修煉之道</Title>
<Body>
shell游戲
<Code>/home/Dave/game.sh</Code>
</Body>
Test時會自動測試書中的程序,如:game.sh;Build之后本書便完成了(書中的code文件會自動讀入)。
這真是一個很成功的“項目”:
*
Automate Everything.
* 如果需要,則設計自己的小語言
Perl有一個作解釋器的包
http://search.cpan.org/~dconway/Parse-RecDescent-1.965001/lib/Parse/RecDescent.pm * Fix Broken Windows
--Fix small thing,Then big thing will not happen.
*
Don't repeat yourself(DRY)
-- code duplication
解決方法: 做成函數,模塊,類;采用code generators;采用元程序設計(The art of metaprogramming:
http://www.ibm.com /developerworks/linux/library/l-metaprog1.html);采用設計模式(作者覺得采用模式有可能把問題弄復雜);convertions;metaphors;
-- Project Duplication
Fix by producing procduts; Fix with data-driven designs.
* Do one thing better.
簡單,低耦合。
* Do Nothing Twice.
* 代碼之前,測試先行。
* 選擇好的編碼工具能有效地提高效率,避免編碼中的小錯誤。
posted @
2010-08-13 20:34 hex108 閱讀(349) |
評論 (0) |
編輯 收藏,有一些覺得比較有用的觀點,再加些自己的所看到的所學到的。
1. 只在學習區學習
不要對未知的事物感到本能性的恐懼,相信自己能行的。
“心理學家把人的知識和技能分為層層嵌套的三個圓形區域:最內一層是“舒適區”,是我們已經熟練掌握的各種技能;最外一層是“恐慌區”,是我們暫時無法學會
的技能,二者中間則是“學習區”。只有在學習區里面練習,一個人才可能進步。有效的練習任務必須精確的在受訓者的“學習區”內進行,具有高度的針對性。在
很多情況下這要求必須要有一個好的老師或者教練,從旁觀者的角度更能發現我們最需要改進的地方。”
2. 學到的東西只有
多用,多實踐才能化為己用。
紙上得來終覺淺。
3. 多寫下自己的所得。
寫下的東西可能比在大腦中記下的更有條理,在寫的過程中可能會觸發新的思路,且有助于理清思路 (這就是為什么一個問題在自言語中為什么有時候會出現答案自己跑出來的情況)所以要多寫。
最近發現Vimwiki是個好東西。
4. 優秀是一種習慣。
好習慣的養成很重要(eg:
今日事今日畢就是很重要的)
5. 多看經典之作,不要把時間浪費在無用的東西上。
6. 堅持是最重要的,這樣才會有柳暗花明的一天
。
7. 有什么想做的事就大膽去做吧,誰保證以后還會有機會?
借用《明朝那些事》里的一句話“按照自己的方式去活才是最大的成功”。
posted @
2010-08-10 20:37 hex108 閱讀(534) |
評論 (0) |
編輯 收藏 計算機原本就該從事簡單重復的工作。只要把任務指派給它們,它們就可以一遍又一遍毫不走樣地重復執行,而且速度很快。但卻經常看見一種奇怪的現象:人們在計算機上手工做一些簡單重復的工作,計算機則在大半夜里扎堆閑聊取笑這些可憐的用戶。
我們應該利用作為程序員的優勢,看到普通用戶無法看到的東西,培養larry所說的“懶惰,急躁和傲慢”讓計算機高效地為我們工作:命令行是如此地高效,腳本是如此地方便,銜接兩個小工具能達到如此神奇的效果。。。
古代哲人1. 亞里斯多德的“事物本質性質和附屬性質”理論:致力本質復雜性,去除附屬復雜性。你現在想解決問題A,在解決A的問題中遇到了問題B,接著你去解決問題B,戲劇性的是你遇到了很多接二連三的問題C,D,E,或者在很多年后,程序才出現問題C,D,E,可是你的最初問題是A,不是嗎?B,C,D等等都是附屬性質,當這些附屬性質越來越多,越來越復雜的時候,也是開始思考另一個解決A的辦法的時候了。(如果作為學習,可以試著去解決那些附屬性質)
2. 笛米特法則:任何一個對象或者方法,它應該只能調用下列對象:該對象本身,作為參數傳遞進來的對象,在方法內創建的對象。這么做的主要目的是信息隱藏,同時使類的耦合更加松散。
3. “古老”的軟件傳說。了解歷史才能更好地創造歷史。讀讀那些“古老”的“寶典”(如《程序員修煉之道》《人月神話》《Smalltalk Best Practice Patterns》),會學到很多有用的東西,或許你會發出一生驚嘆。“當你的老板要求你使用一個低質量的代碼庫時,不需要在崩潰中咬牙切齒,告訴他:你正“站在侏儒的肩膀”上的陷阱中,然后他就會明白不僅僅只有你才覺得那是個壞主意。”
擁抱多語言編程 “每個語言都有自己擅長的地方”(我的想法)。比如perl特別適合文本處理,用來處理網頁也很好(畢竟有些從服務器上返回的數據就是用perl返回的,所以用perl也會比較合適)。
計算機語言就像鯊魚,要是保持靜止就會死。
Java的創造都們實際上創造了兩樣東西:Java語言和Java平臺。后者就是我們擺脫歷史包袱的途徑(Java語言的特性包含了一些它本該可以忽略的東西,如Java程序初始化的順序和從0開始的數組)。讀到本文我才開始理解平臺的深刻意義。
舉兩個例子(Groovy和Jaskell)說明。
Groovy是一種開源的編程語言,它給Java帶來了動態語言的語法和功能,它會生成Java字節碼,因此可以在Java平臺上運行。在Java之后十多年里浮現出來的各種語言很大程序上影響著Groovy的語法:Groovy支持裝飾,較松散的類型系統,“理解”迭代的集合,以及很多現代編程語言的改進特性。而且它可以編譯成純正的Java字節碼。用Groovy寫成的代碼簡潔且并不比用Java寫的代碼效率低多少,而且能充分借用Java平臺的優勢。
Jaskell是運行在Java平臺上的Haskell版本。Jaskell擁有函數式程序設計語言的優勢:函數不改變外界的狀態,純粹的函數式語言壓根沒有“變量”概念;函數式語言對多線程的支持比命令式語言要強得多,用函數式語言更容易寫出強壯的線程安全的代碼,對并發支持也比較好(我想這是Erlang流行的原因)。同時Jaskell也能借用Java平臺的優勢。
Java平臺借用這些多語言特性,一定會走得更好,走得更遠。不過,在帶來好處的同時,也帶來了一個問題:多語言應用程序更難高度,解決這個問題最簡單的辦法也跟現在一樣:靠嚴格的單元測試來避免在調試器上浪費時間。
多語言開發風格會把我們帶向領域特定語言(Domain-specific Language,DSL)。我們會以一些專門的語言為基礎,創造出非常有針對性的,非常專注某一問題域的DSL。抱定一種通用語言不放的年代就快結束了,我們正在進入一個專業細分的新時代。大學時代的Haskell教材還在書架頂上蒙塵嗎?該給它撣撣灰了。
ps: 我們也可以以C++為基礎,來創造一種DSL,思考。
鏈接: 卓有成效的程序員
posted @
2010-07-10 12:40 hex108 閱讀(883) |
評論 (4) |
編輯 收藏"A useful way to get some insight into what linkers and loaders do is to look at their part in the development of computer programming systems."
一. 目標1. 理解Linker和Loader的大致工作過程。
2. 寫一個關于elf的小loader。
3. 會感染ELF和PE文件。
二. 有用的鏈接1. 本書《Linkers and Loaders
》的網址:
http://linker.iecc.com/
posted @
2010-07-06 20:51 hex108 閱讀(413) |
評論 (0) |
編輯 收藏
一.
簡介 該正則表達式暫時能識別 *,|,(,)等特殊符號,如(a|b)*abc。不過擴展到其他符號(如?)也相對比較容易,修改NFA中的構建規則即可。
二.
引擎的構建 該正則表達式引擎的構建以《Compilers Principles,Techniques & Tools》3.7節為依據,暫時只能識別*,|,(,)這幾個特殊的字符,其工作過程為:構建NFA -> 根據NFA構建DFA -> 用DFA匹配。
1. 構建NFA
該NFA的構建以2條基本規則和3條組合規則為基礎,采用歸納的思想構建而成。
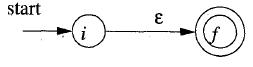
1)2條基本的規則是:
a. 以一個空值ε構建一個NFA
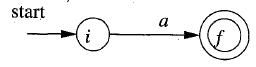
b. 以一個字符a構建一個NFA
2) 3條組合規則是:
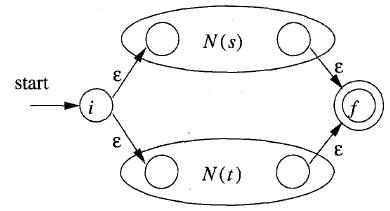
a. r = s | t (其中s和t都是NFA)
b. r = s t(其中s和t都是NFA)

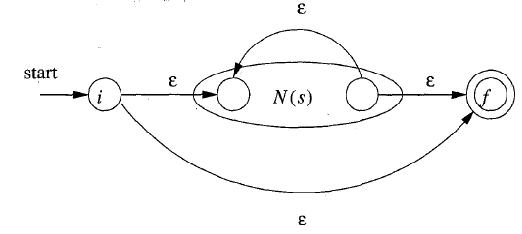
c. r = s *(其中s為NFA)
3) 如果需要識別如”?”等特殊符號,則可再加一些組合規則。
在具體的程序中,可以以下面的BNF為結構來實現。(具體見源程序regexp.cpp)
r -> r '|' s | r
s -> s t | s
t -> a '*' | a
a -> token | '(' r ')' | ε
2. 構建DFA
主要是求ε閉包的過程,從一個集合的ε閉包轉移到一個集合的ε閉包。
以a*c為例,其NFA圖如下所示(用dot畫的)
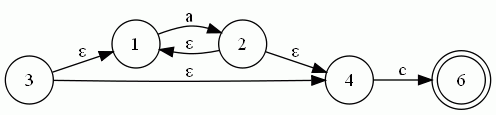
為例:
起始結點3的ε閉包集為 A = {3,1,4}
A遇上字母a的轉移為MOV(A,a) = { 2 },其ε閉包集為B = { 2,1,4 }
A遇上字母c的轉移為MOV(A,c) = { 6 },其ε閉包集為B = { 6 }
同理可求出其他轉移集合,最后得到的DFA如下所示:
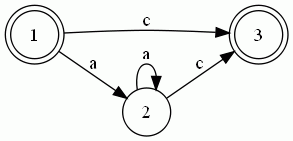
3. 匹配
每匹配成功一個字符則DFA移動到下個相應的結點。
三.
改進1. 如龍書中所說,有時候模擬NFA而不是直接構建DFA可能達到更好的效果。
2. 每次匹配不成功都需要回溯,這個地方也可以借鑒KMP算法(不過KMP對此好像有點不適用)
3. 其他改進方法可以看看《柔性字符串匹配》和龍書《Compilers Principles,Techniques & Tools》3.7節。
四. 代碼下載
svn checkout http://regexp.googlecode.com/svn/trunk/ regexp-read-only
或
regexp.rar
posted @
2010-06-17 20:50 hex108 閱讀(722) |
評論 (2) |
編輯 收藏