一.
簡(jiǎn)介 該正則表達(dá)式暫時(shí)能識(shí)別 *,|,(,)等特殊符號(hào),如(a|b)*abc。不過(guò)擴(kuò)展到其他符號(hào)(如?)也相對(duì)比較容易,修改NFA中的構(gòu)建規(guī)則即可。
二.
引擎的構(gòu)建 該正則表達(dá)式引擎的構(gòu)建以《Compilers Principles,Techniques & Tools》3.7節(jié)為依據(jù),暫時(shí)只能識(shí)別*,|,(,)這幾個(gè)特殊的字符,其工作過(guò)程為:構(gòu)建NFA -> 根據(jù)NFA構(gòu)建DFA -> 用DFA匹配。
1. 構(gòu)建NFA
該NFA的構(gòu)建以2條基本規(guī)則和3條組合規(guī)則為基礎(chǔ),采用歸納的思想構(gòu)建而成。
1)2條基本的規(guī)則是:
a. 以一個(gè)空值ε構(gòu)建一個(gè)NFA
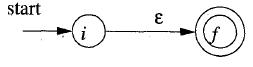
b. 以一個(gè)字符a構(gòu)建一個(gè)NFA
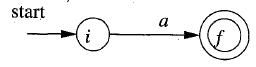
2) 3條組合規(guī)則是:
a. r = s | t (其中s和t都是NFA)
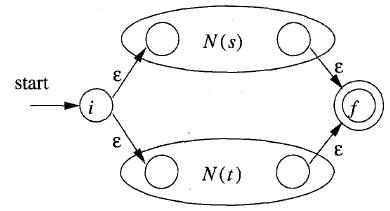
b. r = s t(其中s和t都是NFA)

c. r = s *(其中s為NFA)
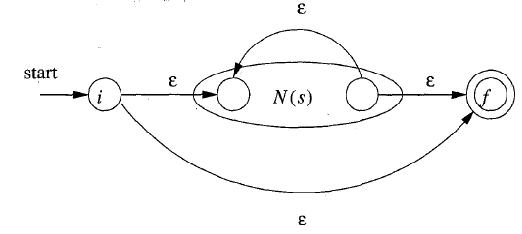
3) 如果需要識(shí)別如”?”等特殊符號(hào),則可再加一些組合規(guī)則。
在具體的程序中,可以以下面的BNF為結(jié)構(gòu)來(lái)實(shí)現(xiàn)。(具體見(jiàn)源程序regexp.cpp)
r -> r '|' s | r
s -> s t | s
t -> a '*' | a
a -> token | '(' r ')' | ε
2. 構(gòu)建DFA
主要是求ε閉包的過(guò)程,從一個(gè)集合的ε閉包轉(zhuǎn)移到一個(gè)集合的ε閉包。
以a*c為例,其NFA圖如下所示(用dot畫(huà)的)
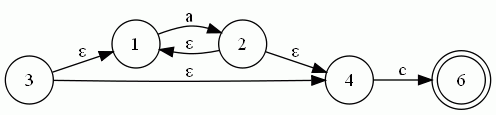
為例:
起始結(jié)點(diǎn)3的ε閉包集為 A = {3,1,4}
A遇上字母a的轉(zhuǎn)移為MOV(A,a) = { 2 },其ε閉包集為B = { 2,1,4 }
A遇上字母c的轉(zhuǎn)移為MOV(A,c) = { 6 },其ε閉包集為B = { 6 }
同理可求出其他轉(zhuǎn)移集合,最后得到的DFA如下所示:
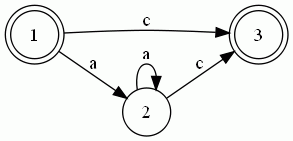
3. 匹配
每匹配成功一個(gè)字符則DFA移動(dòng)到下個(gè)相應(yīng)的結(jié)點(diǎn)。
三.
改進(jìn)1. 如龍書(shū)中所說(shuō),有時(shí)候模擬NFA而不是直接構(gòu)建DFA可能達(dá)到更好的效果。
2. 每次匹配不成功都需要回溯,這個(gè)地方也可以借鑒KMP算法(不過(guò)KMP對(duì)此好像有點(diǎn)不適用)
3. 其他改進(jìn)方法可以看看《柔性字符串匹配》和龍書(shū)《Compilers Principles,Techniques & Tools》3.7節(jié)。
四. 代碼下載
svn checkout http://regexp.googlecode.com/svn/trunk/ regexp-read-only
或
regexp.rar
posted on 2010-06-17 20:50
hex108 閱讀(732)
評(píng)論(2) 編輯 收藏 引用 所屬分類:
Program