LingosHook第十八版(v1.2.001)主要圍繞提高HTML數據詞典識別率和識別速度做了大幅度的修改,可以這里下載了。修改內容如下:
1. 定義三種詞典解析類型,并以此為據重新設計實現HTML數據分析算法;
2. 增加對詞典解析配置,包括指定詞典解析類型和是否解析;
描述的有些暈,還是上圖說明吧。
如下圖所示,在配置界面中新增了一個按鈕,用于配置詞典的解析參數;
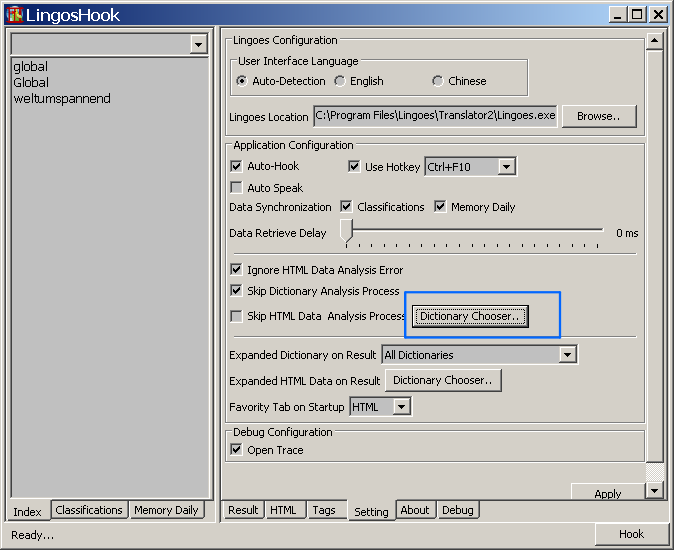
點擊此按鈕,將彈出如下對話框,用于設置詞典解析參數;
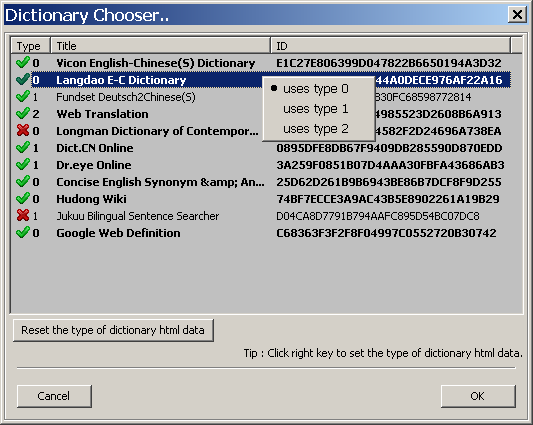
(對,是的,我終于把圖標變小了,用的是歪門邪道,不說也罷。。。)
對話框中羅列了曾經使用過的詞典。
1. 點擊其圖標可以設置指定詞典的HTML數據是否被解析,‘X’為不解析;
2. 通過右鍵菜單可以看出,程序當前在支持三種HTML數據解析類型:0,1,2;
3. 右鍵菜單中前端標記有‘黑點’的類型表示此類型為程序默認類型;默認類型也可配置,請看下圖;
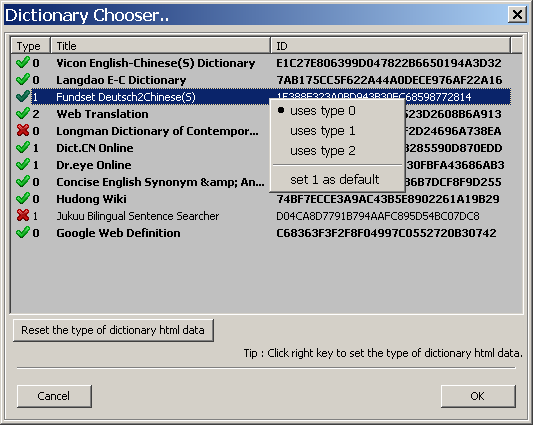
4. 當當前使用類型不為默認類型時,可設置其為默認類型;
5. 標記為粗體的詞典表示當前使用的類型為默認類型;
6. 點擊'Reset the type of dictionary html data'按鈕,可以將類型設置為其默認類型,如果存在的話;
上圖中所列詞典為我當前測試的詞典,除了‘Jukuu’詞典結果暫時無法歸類外,其它詞典都可以歸為以上三類。因此當使用的詞典不再以上列表中時,可先嘗試依次設置不同解析類型,以檢測是否可以分解其HTML數據。
從我的分析看,結果的外層格式是由Lingoes定死的,但各結果數據格式來自詞典自定義,這也是結果不同于的根本所在,所以無法預知Lingoes的HTML數據結果格式到底有多少種。有興趣的可以自己添加解析類型,源碼在這里;當然你也可以發來詞典名稱和所查單詞,由我來分析(這個請別太認真,我就說說,不能保證的。。。。)。
 HtmlDictParser::TDictDefAttr g_stSysDictDefAttr[SIZE_DICTDEFATTR] =
HtmlDictParser::TDictDefAttr g_stSysDictDefAttr[SIZE_DICTDEFATTR] =


 {
{

 {L"E1C27E806399D047822B6650194A3D32", HtmlDictParser::HTMLDATATYPE_1},//Vicon EC
{L"E1C27E806399D047822B6650194A3D32", HtmlDictParser::HTMLDATATYPE_1},//Vicon EC
{L"7AB175CC5F622A44A0DECE976AF22A16", HtmlDictParser::HTMLDATATYPE_1},//Langdao EC
{L"1E388F323A0BD943B30FC68598772814", HtmlDictParser::HTMLDATATYPE_1},//Fundset DC
{L"0895DFE8DB67F9409DB285590D870EDD", HtmlDictParser::HTMLDATATYPE_2},//Dict.CN online
{L"D4722835273E184582F2D24696A738EA", HtmlDictParser::HTMLDATATYPE_1},//Longman Dictionary of Contemporary English
{L"25D62D261B9B6943BE86B7DCF8F9D255", HtmlDictParser::HTMLDATATYPE_1},//Concise English Synonym & Antonym Dictionary
{L"74BF7ECCE3A9AC43B5E8902261A19B29", HtmlDictParser::HTMLDATATYPE_1},//Hudong Wiki
{L"C68363F3F2F8F04997C0552720B30742", HtmlDictParser::HTMLDATATYPE_1},//Google Web Definition
{L"3A259F0851B07D4AAA30FBFA43686AB3", HtmlDictParser::HTMLDATATYPE_2},//Dr.eye Online
{L"9455286C1F1BC84985523D2608B6A913", HtmlDictParser::HTMLDATATYPE_3},//Web Translation
 };
};
<---- 疲憊的分割線 ---->
經過這次修改,LingosHook設計期的功能都實現了,應該可以收工,休息了。。。。