這幾天研究了一下CUDA,發(fā)現(xiàn)其并行的思想和普通的CPU多線程思想不太一致,但還是挺不錯(cuò)。主要是將任務(wù)劃分成一個(gè)個(gè)block,然后每個(gè)block里面再劃分成細(xì)的線程。然后每個(gè)線程做自己做的
事情。這種并行思想很適用于像矩陣運(yùn)算這些元素與元素之間的運(yùn)算并不耦合得很厲害,但整體數(shù)據(jù)很大的情況,這只是我對CUDA的初步感覺。
矩陣相乘的CPU程序如下:
//C = A*B
void MatrixMulCPU(float* _C,const float *_A,const float *_B,int _wa,int _ha,int _wb)
{
float sum = 0;
for (int i = 0; i < _ha; ++i)
{
for (int j = 0; j < _wb; ++j)
{
sum = 0;
for (int k = 0; k < _wa; ++k)
{
sum += (float)_A[i*_wa+k]*(float)_B[k*_wb+ j];
}
_C[i*_wb+j] = (float)sum;
}
}
}
從上面可以看出,C(i,j) = sum { A(i,k)*B(k,j) } 0<=k < _wa;耦合程度很小,所以我們可以通過劃分區(qū)域的方法,讓每個(gè)線程負(fù)責(zé)一個(gè)區(qū)域。
怎么劃分呢?首先最初的想法是讓每一個(gè)線程計(jì)算一個(gè)C(i,j),那么估算一下,應(yīng)該需要height_c*width_c,也就是ha*wb個(gè)線程。進(jìn)一步,我們將矩陣按一個(gè)大方格Grid劃分,如果一個(gè)
方格Grid大小是16*16,那么矩陣80*48的可以表示為5(*16) * 3(*16),即16*16個(gè)大格子(block),每一個(gè)格子內(nèi),自然就是(height_c/16) *(width_c/16)個(gè)線程了。
好了,劃分完后,內(nèi)核代碼如下:
計(jì)算版本0:
__global__ void matrix_kernel_0(float* _C,const float* _A,const float *_B,int _wa,int _wb)
{
float sum = 0;
//找出該線程所在的行列
int row = blockIdx.y*blockDim.y + threadIdx.y;
int col = blockIdx.x*blockDim.x + threadIdx.x;
//線程Thread(row,col)負(fù)責(zé)計(jì)算C(row,col)
for (int i = 0; i < _wa; ++i)
{
sum += _A[row*_wa + i]*_B[i*_wb + col];
}
_C[row*_wb + col] = sum;
}
另外一種思路,我們不讓每一個(gè)線程完整計(jì)算一個(gè)C(i,j),通過C(i,j) = sum { A(i,k)*B(k,j) }發(fā)現(xiàn),我們還可以再細(xì)度劃分:
Csub(i,j) = sum{A(i,ksub+offsetA)*B(ksub+offsetB,j)} 0<=ksub < blockSize
C(i,j) = sum{Csub(i,j)}
就是把矩陣分成n*n個(gè)大的子塊,然后每一個(gè)block負(fù)責(zé)計(jì)算子塊i 和 子塊j的子乘積,計(jì)算完畢后加起來則可。這里主要使用了共享顯存作優(yōu)化。
計(jì)算版本1:
__global__ void matrix_kernel_1(float* _C,const float* _A,const float *_B,int _wa,int _wb)
{
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
//該block要處理的A
int aBegin = _wa*(by*BLOCK_SIZE);//A(0,by)
int aEnd = aBegin + _wa - 1;
int aStep = BLOCK_SIZE;//offsetA
int bBegin = BLOCK_SIZE*bx;//B(bx,0)
int bStep = BLOCK_SIZE*_wb;//offsetB
float cSub = 0;
for (int a = aBegin,b = bBegin; a <= aEnd; a += aStep,b += bStep)
{
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
//每個(gè)線程負(fù)責(zé)一個(gè)元素拷貝
As[ty][tx] = _A[a + _wa*ty + tx];
Bs[ty][tx] = _B[b + _wb*ty + tx];
__syncthreads();
//每個(gè)線程負(fù)責(zé)計(jì)算一個(gè)子塊i 和 子塊j的子乘積
for (int k = 0; k < BLOCK_SIZE; ++k)
{
cSub += As[ty][k]*Bs[k][tx];
}
__syncthreads();
}
//全局地址,向全局寄存器寫回去
//一個(gè)線程負(fù)責(zé)一個(gè)元素,一個(gè)block負(fù)責(zé)一個(gè)子塊
int cIndex = (by*BLOCK_SIZE + ty)*_wb + (bx*BLOCK_SIZE + tx);
_C[cIndex] = cSub;
}
最后寫一個(gè)面向Host的接口函數(shù):
void matrixMulGPU(float* _C,const float *_A,const float *_B,int _wa,int _ha,int _wb)
{
float* d_a = myNewOnGPU<float>(_wa*_ha);
float* d_b = myNewOnGPU<float>(_wb*_wa);
float* d_c = myNewOnGPU<float>(_wb*_ha);
copyFromCPUToGPU(_A,d_a,_wa*_ha);
copyFromCPUToGPU(_B,d_b,_wb*_wa);
dim3 threads(BLOCK_SIZE,BLOCK_SIZE);
dim3 blocks(WC/BLOCK_SIZE,HC/BLOCK_SIZE);
matrix_kernel_0<<<blocks,threads>>>(d_c,d_a,d_b,_wa,_wb);
cudaThreadSynchronize();
copyFromGPUToCPU(d_c,_C,_wb*_ha);
myDeleteOnGPU(d_a);
myDeleteOnGPU(d_b);
myDeleteOnGPU(d_c);
}
調(diào)用的主函數(shù)如下:
#include <stdio.h>
#include <cuda_runtime.h>
#include <cutil.h>
#include <cutil_inline.h>
#include <stdlib.h>
#include <time.h>
#include <math.h>
#include <string.h>
#include <Windows.h>
#include "CUDACommon.h"
#include "MatrixMulCPU.h"
#include "MatrixMulGPU.h"
void randomInit(float* _data,int _size)
{
for (int i = 0; i < _size; ++i)
{
_data[i] = rand()/(float)RAND_MAX;
}
}
bool checkError(const float* _A,const float* _B,int _size)
{
for (int i = 0 ; i < _size; ++i)
{
if (fabs(_A[i] - _B[i]) > 1.0e-3)
{
printf("%f \t %f\n",_A[i],_B[i]);
return false;
}
}
return true;
}
int main(int argc, char* argv[])
{
srand(13);
if(!InitCUDA()) {
return 0;
}
float* A = myNewOnCPU<float>(WA*HA);
float* B = myNewOnCPU<float>(WB*HB);
randomInit(A,WA*HA);
randomInit(B,WB*HB);
float* C = myNewOnCPU<float>(WC*HC);
memset(C,0,sizeof(float)*WC*HC);
float* C2 = myNewOnCPU<float>(WC*HC);
memset(C2,0,sizeof(float)*WC*HC);
unsigned int tick1 = GetTickCount();
MatrixMulCPU(C2,A,B,WA,HA,WB);
printf("CPU use Time : %dms\n",GetTickCount() - tick1);
unsigned int timer = 0;
cutilCheckError(cutCreateTimer(&timer));
cutilCheckError(cutStartTimer(timer));
{
matrixMulGPU(C,A,B,WA,HA,WB);
}
cutilCheckError(cutStopTimer(timer));
printf("GPU use time: %f (ms) \n", cutGetTimerValue(timer));
cutilCheckError(cutDeleteTimer(timer));
if (checkError(C,C2,WC*HC))
{
printf("Accept\n");
}
else
{
printf("Worng Answer\n");
}
myDeleteOnCPU(A);
myDeleteOnCPU(B);
myDeleteOnCPU(C);
myDeleteOnCPU(C2);
return 0;
}
運(yùn)算結(jié)果如下:
版本0:
版本1:
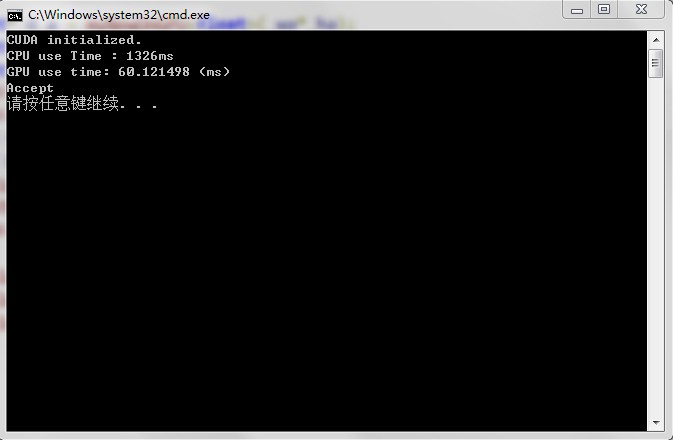
可以看出,GPU并行性能比CPU好很多,而且版本1優(yōu)于版本0
整個(gè)工程下載:
/Files/bennycen/CUDAMatrixMul.rar
posted on 2011-07-26 17:01
bennycen 閱讀(4648)
評論(1) 編輯 收藏 引用 所屬分類:
CUDA