接上一篇:lua源碼剖析(一)
詞法分析
lua對與每一個文件(chunk)建立一個LexState來做詞法分析的context數據���,此結構定義在llex.h中。詞法分析根據語法分析的需求有當前token��,有lookahead token��,LexState結構如圖:
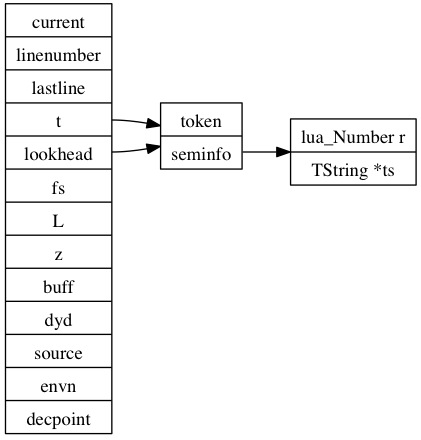
其中token結構中用int存儲實際token值���,此token值對于單字符token(+ - * /之類)就表示自身���,對于多字符(關鍵字等)token是起始值為257的枚舉值�����,在llex.h文件中定義:
#define FIRST_RESERVED 257
/*
* WARNING: if you change the order of this enumeration,
* grep "ORDER RESERVED"
*/enum RESERVED {
/* terminal symbols denoted by reserved words */ TK_AND = FIRST_RESERVED, TK_BREAK,
TK_DO, TK_ELSE, TK_ELSEIF, TK_END, TK_FALSE, TK_FOR, TK_FUNCTION,
TK_GOTO, TK_IF, TK_IN, TK_LOCAL, TK_NIL, TK_NOT, TK_OR, TK_REPEAT,
TK_RETURN, TK_THEN, TK_TRUE, TK_UNTIL, TK_WHILE,
/* other terminal symbols */ TK_CONCAT, TK_DOTS, TK_EQ, TK_GE, TK_LE, TK_NE, TK_DBCOLON, TK_EOS,
TK_NUMBER, TK_NAME, TK_STRING
};
token結構中還有一個成員seminfo,這個表示語義信息���,根據token的類型,可以表示數值或者字符串��。
lex提供函數luaX_next和luaX_lookahead分別lex下一個token和lookahead token���,在內部是通過llex函數來完成詞法分析���。
語法分析
lua語法分析是從lparser.c中的luaY_parser開始:
Closure *luaY_parser (lua_State *L, ZIO *z, Mbuffer *buff,
Dyndata *dyd, const char *name, int firstchar) {
LexState lexstate;
FuncState funcstate;
Closure *cl = luaF_newLclosure(L, 1); /* create main closure */
/* anchor closure (to avoid being collected) */
setclLvalue(L, L->top, cl);
incr_top(L);
funcstate.f = cl->l.p = luaF_newproto(L);
funcstate.f->source = luaS_new(L, name); /* create and anchor TString */
lexstate.buff = buff;
lexstate.dyd = dyd;
dyd->actvar.n = dyd->gt.n = dyd->label.n = 0;
luaX_setinput(L, &lexstate, z, funcstate.f->source, firstchar);
mainfunc(&lexstate, &funcstate);
lua_assert(!funcstate.prev && funcstate.nups == 1 && !lexstate.fs);
/* all scopes should be correctly finished */
lua_assert(dyd->actvar.n == 0 && dyd->gt.n == 0 && dyd->label.n == 0);
return cl; /* it's on the stack too */
}
此函數創建一個closure并把LexState和FuncState初始化后調用mainfunc開始parse���,其中FuncState表示parse時函數狀態信息的�����,如圖:
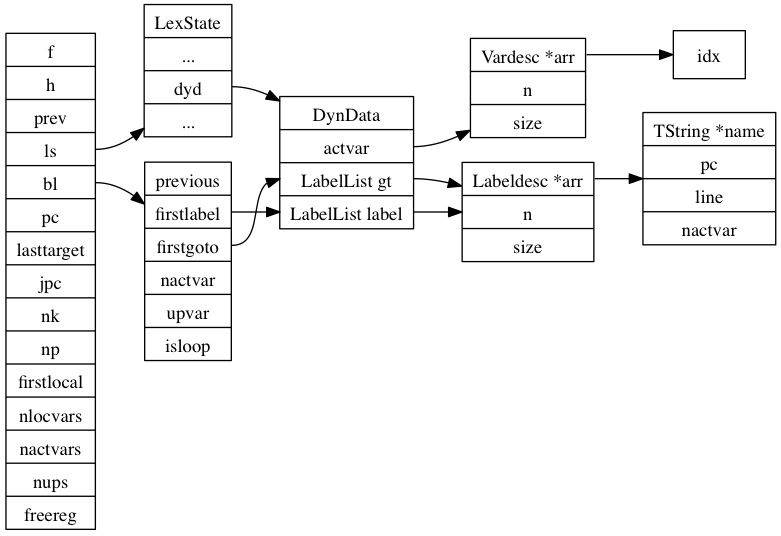
每當parse到一個function的時候都會建立一個FuncState結構,并將它與所嵌套的函數通過prev指針串聯起來,body函數就是完成嵌套函數parse。
static void body (LexState *ls, exposed *e, int ismethod, int line) {
/* body -> `(' parlist `)' block END */
FuncState new_fs;
BlockCnt bl;
new_fs.f = addprototype(ls);
new_fs.f->linedefined = line;
open_func(ls, &new_fs, &bl);
checknext(ls, '(');
if (ismethod) {
new_localvarliteral(ls, "self"); /* create 'self' parameter */
adjustlocalvars(ls, 1);
}
parlist(ls);
checknext(ls, ')');
statlist(ls);
new_fs.f->lastlinedefined = ls->linenumber;
check_match(ls, TK_END, TK_FUNCTION, line);
codeclosure(ls, e);
close_func(ls);
}
FuncState中的f指向這個函數的Proto,Proto中保存著函數的指令�����、變量信息�����、upvalue信息等其它信息�����,Proto的結構如圖:

k指向一個這個Proto中使用到的常量,code指向這個Proto的指令數組��,Proto **p指向這個Proto內部的Proto列表���,locvars存儲local變量信息�����,upvalues存儲upvalue的信息�����,cache指向最后創建的closure,source指向這個Proto所屬的文件名���,后面的size*分別表示前面各個指針指向的數組的大小,numparams表示固定的參數的個數,is_vararg表示這個Proto是否是一個變參函數,maxstacksize表示最大stack大小��。
FuncState中的ls指向LexState��,在LexState中有一個Dyndata的結構,這個結構用于保存在parse一個chunk的時候所存儲的gt label list和label list以及所有active變量列表�����,其中gt label list存儲的是未匹配的goto語句和break語句的label信息���,而label list存儲的是已聲明的label���。待出現一個gt label的時候就在label list中查找是否有匹配的label,若出現一個label也將在gt label list中查找是否有匹配的gt�����。
LuaY_parser調用mainfunc開始parse一個chunk:
static void mainfunc (LexState *ls, FuncState *fs) {
BlockCnt bl;
expdesc v;
open_func(ls, fs, &bl);
fs->f->is_vararg = 1;
/* main function is always vararg */ init_exp(&v, VLOCAL, 0);
/* create and */
*/ newupvalue(fs, ls->envn, &v);
/* set environment upvalue */ luaX_next(ls);
/* read first token */ statlist(ls);
/* parse main body */ check(ls, TK_EOS);
close_func(ls);
}
在mainfunc中通過open_func函數完成對進入某個函數進行parse之前的初始化操作��,每parse進一個block的時候���,將建立一個BlockCnt的結構并與上一個BlockCnt連接起來���,當parse完一個block的時候就回彈出最后一個BlockCnt結構��。BlockCnt結構中的其它變量的意思是:nactvar表示這個block之前的active var的個數,upval表示這個block是否有upvalue被其它block訪問��,isloop表示這個block是否是循環block��。mainfunc中調用statlist���,statlist調用statement開始parse語句和表達式��。
statement分析語句采用的是LL(2)的遞歸下降語法分析法。在statement里面通過case語句處理各個帶關鍵字的語句�����,在default語句中處理賦值和函數調用的分析���。語句中的表達式通過expr函數處理���,其處理的BNF如下:
exp ::= nil | false | true | Number | String | ‘...’ | functiondef |
prefixexp | tableconstructor | exp binop exp | unop exp
expr函數調用subexpr函數完成處理���。
static BinOpr subexpr (LexState *ls, expdesc *v, int limit) {
BinOpr op;
UnOpr uop;
enterlevel(ls);
uop = getunopr(ls->t.token);
if (uop != OPR_NOUNOPR) {
int line = ls->linenumber;
luaX_next(ls);
subexpr(ls, v, UNARY_PRIORITY);
luaK_prefix(ls->fs, uop, v, line);
}
else simpleexp(ls, v);
/* expand while operators have priorities higher than `limit' */
op = getbinopr(ls->t.token);
while (op != OPR_NOBINOPR && priority[op].left > limit) {
expdesc v2;
BinOpr nextop;
int line = ls->linenumber;
luaX_next(ls);
luaK_infix(ls->fs, op, v);
/* read sub-expression with higher priority */
nextop = subexpr(ls, &v2, priority[op].right);
luaK_posfix(ls->fs, op, v, &v2, line);
op = nextop;
}
leavelevel(ls);
return op; /* return first untreated operator */
}
當分析exp binop exp | unop exp的時候lua采用的是算符優先分析�����,其各個運算符的優先級定義如下:
static const struct {
lu_byte left; /* left priority for each binary operator */
lu_byte right; /* right priority */
} priority[] = { /* ORDER OPR */
{6, 6}, {6, 6}, {7, 7}, {7, 7}, {7, 7}, /* `+' `-' `*' `/' `%' */
{10, 9}, {5, 4}, /* ^, .. (right associative) */
{3, 3}, {3, 3}, {3, 3}, /* ==, <, <= */
{3, 3}, {3, 3}, {3, 3}, /* ~=, >, >= */
{2, 2}, {1, 1} /* and, or */
};
#define UNARY_PRIORITY 8 /* priority for unary operators */
代碼生成
lua代碼生成是伴隨著語法分析進行的,指令類型Instruction定義在llimits.h中:
/*
** type for virtual-machine instructions
** must be an unsigned with (at least) 4 bytes (see details in lopcodes.h)
*/
typedef lu_int32 Instruction;

Instruction是一個32位的整形數據��,其中0~5 bits表示optype���,6~13 bits參數A�����,14~22 bits表示參數B�����,23~31 bits表示參數C,14~31 bits表示參數Bx或sBx��,6~31 bits表示參數Ax���。
代碼生成的函數聲明在lcode.h中�����,以luaK開頭,這一系列的函數大多都有expdesc *v的參數,expdesc的結構定義在lparser.h,如下:
typedef struct expdesc {
expkind k;
union {
struct { /* for indexed variables (VINDEXED) */
short idx; /* index (R/K) */
lu_byte t; /* table (register or upvalue) */
lu_byte vt; /* whether 't' is register (VLOCAL) or upvalue (VUPVAL) */
} ind;
int info; /* for generic use */
lua_Number nval; /* for VKNUM */
} u;
int t; /* patch list of `exit when true' */
int f; /* patch list of `exit when false' */
} expdesc;
expdesc中的t和f分別表示表達式為true和false時�����,待回填跳轉指令的下標�����。k表示表達式的類型���,u表示對應類型的數據���。
代碼生成過程中根據表達式類型做相應的代碼生成操作���,lua中每個函數最大有250個寄存器�����,表達式的計算就是選擇這些寄存器存放并生成數據��,而寄存器的下標是在代碼生成階段選擇好的,寄存器的釋放是根據變量和表達式的生命周期結束的時候釋放��。代碼生成過程會將變量的生命周期的起始pc和結束指令pc分別存放在Proto中的LocVar的startpc和endpc里面�����,供調試使用��。
posted on 2012-08-12 17:28
airtrack 閱讀(8622)
評論(0) 編輯 收藏 引用