C語言中的結構是有實現位段的能力的,噢!你問它到底是什么形式是吧?這個問題呆會給你答案。讓我們先看看位段的作用:位段是在字段的聲明后面加一個冒號以及一個表示字段位長的整數來實現的。這種用法又被就叫作“深入邏輯元件的編程”,如果你對系統編程感興趣,那么這篇文章你就不應該錯過!
我把使用位段的幾個理由告訴大家:1、它能把長度為奇數的數據包裝在一起,從而節省存儲的空間;2、它可以很方便地訪問一個整型值的部分內容。
首先我要提醒大家注意幾點:1、位段成員只有三種類型:int ,unsigned int 和signed int這三種(當然了,int型位段是不是可以取負數不是我說了算的,因為這是和你的編譯器來決定的。位段,位段,它是用來表示字段位長(bit)的,它只有整型值,不會有7.2這種float類型的,如果你說有,那你就等于承認了有7.2個人這個概念,當然也沒有char這個類型的);2、成員名后面的一個冒號和一個整數,這個整數指定該位段的位長(bit);3、許多編譯器把位段成員的字長限制在一個int的長度范圍之內;4、位段成員在內存的實現是從左到右還是從右到左是由編譯器來決定的,但二者皆對。
下面我們就來看看,它到底是什么東西(我先假定大家的機器字長為32位):
Struct WORD
{
unsigned int chara: 6:
unsigned int font : 7;
unsigned int maxsize : 19;
};
Struct WORD chone;
這一段是從我編寫的一個文字格式化軟件摘下來的,它最多可以容納64(既我說的unsigned int chara :6; 它總共是6位)個不同的字符值,可以處理128(既unsigned int font : 7 ;既2的7次方)種不同的字體,和2的19次方的單位長度的字。大家都可以看到maxsize是19位,它是無法被一個short int 類型的值所容納的,我們又可以看到其余的成員的長度比char還小,這就讓我們想起讓他們共享32位機器字長,這就避免用一個32位的整數來表示maxsize的位段。怎么樣?還要注意的是剛才的那一段代碼在16位字長的機器上是無法實現的,為什么?提醒你一下,看看上面提醒的第3點,你會明白的!
你是不是發現這個東西沒有用啊?如果你點頭了,那你就錯了!這么偉大的創造怎么會沒有用呢(你對系統編程不感興趣,相信你會改變這么一個觀點的)?磁盤控制器大家應該知道吧?軟驅與它的通信我們來看看是怎么實現的下面是一個磁盤控制器的寄存器:
│←5→│←5→│←9→│←8→│←1→│←1→∣←1→∣←1→∣←1→∣
上面位段從左到右依次代表的含義為:5位的命令,5位的扇區,9位的磁道,8位的錯誤代碼,1位的HEAD LOADED,1位的寫保護,1位的DISK SPINNING,1位的錯誤判斷符,還有1位的READY位。它要怎么來實現呢?你先自己寫寫看:
struct DISK_FORMAT
{
unsigned int command : 5;
unsigned sector : 5;
unsigned track : 9 ;
unsigned err_code : 8;
unsigned ishead_loaded : 1;
unsigned iswrit_protect : 1;
unsigned isdisk_spinning : 1;
unsigned iserr_ocur : 1;
undigned isready :1 ;
};
注:代碼中除了第一行使用了unsigned int 來聲明位段后就省去了int ,這是可行的,詳見ANCI C標準。
如果我們要對044c18bfH的地址進行訪問的話,那就這樣:
#define DISK ((struct DISK_FORMAT *)0x044c18bf)
DISK->sector=fst_sector;
DISK->track=fst_track;
DISK->command=WRITE;
當然那些都是要宏定義的哦!
我們用位段來實現這一目的是很方便的,其實這也可以用移位或屏蔽來實現,你嘗試過就知道哪個更方便了!
我們今天的話題就到這兒,如果諸位還有疑問,可e-mail給我:arhuwen@163.com;
特別聲明哦:不要把以上內容用于不法行為,否則后果自負。另外本文不可用于任何謀取商業利益的舉動,否則同上!
我們已經了解什么是位段了, 現在我們繼續討論位段的使用方法。
先看一個例子: 我們需要用到五個變量。 假定, 其中三個用作標志, 稱為 f1, f2 和 f3。
第四個稱為 type, 取值范圍為 1 至 12。 最后一個變量稱為 index, 值的范圍為 0 至 500。
通常, 我們用下面的語句來說明這些變量:
char f1,f2,f3;
unsigned int type;
unsigned int index;
但是, 實際上標志 f1, f2, f3 分別只需要 1 位。變量 type 只需要 4 位, 而變量 index 只需要 9 位。 總共是 16位 ---- 2 個字節。我們用兩個字節就夠了。
我們可這樣來做:
struct packed_struct
{
unsigned int f1 :1;
unsigned int f2 :1;
unsigned int f3 :1;
unsigned int type :4;
unsigned int index :9;
};
該例中, 我們定義了一個結構 packed_struct。該結構定義了五個成員
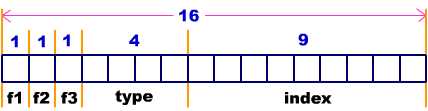
。第一個成員叫做 f1, 是 unsigned int 類型的。緊跟在該成員名之后的 :1 規定了它以 1 位存放。類似地, 標志 f2 和 f3 被定義為長度只有 1 位的。定義成員 type 占有 4 位。定義成員 index 占有 9 位。C 編譯器自動地把上面的位段定義壓縮在一起。位段的劃分如圖所示。packed_struct 總共使用了 16 位。
這種方法的好處是, 定義成 packed_struct 類型的變量的位段, 可以如引用一般的結構成員一樣方便地引用。同時, 使用了更少的內存單元數。
我們已經定義了一個稱作為 packed_struct 的包含著位段的結構。現在, 我們象下面那樣定義一個稱作為 packet_data 的變量: struct packed_struct packed_data; 于是, 我們就可以用簡單的語句, 把 packed_data 的 type 位段設置為 7:
packed_data.type = 7; 類似地, 我們可以用下面的語句把這個位段的值設為 n:
packed_data.type = n; 我們不必擔心 n 的值太長, 以致不能放入 type 位段中, C 編譯器會自動地僅取出 n 的低四位, 把它賦值給 packed_data.type。取出位段的值也自動地處理的, 因此語句 n = packed_data.type; 將從 packed_data 中取出 type 位段, 并把它的值賦給 n。
在一般的表達式中可以使用位段, 此時, 位段自動地轉換成整數。因此, 表達式
i = packed_data.index/5+1; 是完全有效的。
在包含位段的結構中, 也可以包括 "通常的" 數據類型。因此, 如果我們想定義一個結構, 它包含一個 int, 一個 char, 和二個 1 位的標志, 那么, 下面的定義是有效的:
struct table_entry
{
int count ;
char c;
unsigned int f1 :1;
unsigned int f2 :1;
};
當位段出現在結構定義中時, 它們就被壓縮成字。如果某個位段無法放入一個字中, 那么該字的剩余部分跳過不用, 該位段被放入下一個字中。
使用位段時, 必須注意下列事項:
- 在某些機器上, 位段總是作為 unsigned 處理, 而不管它們是否被說明成 unsigned 的。
- 大多數C 編譯器都不支持超過一個字長的位段。
- 位段不可標明維數; 即, 不能說明位段數組, 例如 flag:l[2]。
- 最后, 不可以取位段地址。原因是, 在這種情況不, 顯然沒有稱作為 "位段指針" 類型的變量。

這里, 我們再深入討論一下位段。如果使用下面的結構定義:
struct bits
{
unsigned int f1:1;
int word;
unsigned int f3:1;
};
那么, 位段是怎樣壓縮的呢? 由于成員 word 出現于其間, 故 f1, f3 不會壓縮在同一個字內。C 編譯器不會重新安排位段定義來試圖優化存儲空間。
可以指定無名位段, 使得一個字中的某些位被 "跳過"。因此, 定義:
struct x_entry
{
unsigned int type :4;
unsigned int :3;
unsigned int count :9;
};
將定義一個結構 x_entry, 它包含兩個位段變量 type 和 count, 而無名位段規定了 type 和 count 間隔三位。
來自:http://its.nbtvu.net.cn/xhyu/cai_c/c_web/c/c8/c83.htm
http://www.cnblogs.com/jincwfly/archive/2007/09/14/892341.html
關于結構體內存對齊
內存對齊”應該是編譯器的“管轄范圍”。編譯器為程序中的每個“數據單元”安排在適當的位置上。但是C語言的一個特點就是太靈活,太強大,它允許你干預“內存對齊”。如果你想了解更加底層的秘密,“內存對齊”對你就不應該再透明了。
一、內存對齊的原因
大部分的參考資料都是如是說的:
1、平臺原因(移植原因):不是所有的硬件平臺都能訪問任意地址上的任意數據的;某些硬件平臺只能在某些地址處取某些特定類型的數據,否則拋出硬件異常。
2、性能原因:數據結構(尤其是棧)應該盡可能地在自然邊界上對齊。原因在于,為了訪問未對齊的內存,處理器需要作兩次內存訪問;而對齊的內存訪問僅需要一次訪問。
二、對齊規則
每個特定平臺上的編譯器都有自己的默認“對齊系數”(也叫對齊模數)。程序員可以通過預編譯命令#pragma pack(n),n=1,2,4,8,16來改變這一系數,其中的n就是你要指定的“對齊系數”。
對齊步驟:
1、數據成員對齊規則:結構(struct)(或聯合(union))的數據成員,第一個數據成員放在offset為0的地方,以后每個數據成員的對齊按照#pragma pack指定的數值和這個數據成員自身長度中,比較小的那個進行。
2、結構(或聯合)的整體對齊規則:在數據成員完成各自對齊之后,結構(或聯合)本身也要進行對齊,對齊將按照#pragma pack指定的數值和結構(或聯合)最大數據成員長度中,比較小的那個進行。
3、結合1、2顆推斷:當#pragma pack的n值等于或超過所有數據成員長度的時候,這個n值的大小將不產生任何效果。
備注:數組成員按長度按數組類型長度計算,如char t[9],在第1步中數據自身長度按1算,累加結構體時長度為9;第2步中,找最大數據長度時,如果結構體T有復雜類型成員A的,該A成員的長度為該復雜類型成員A的最大成員長度。
三、試驗
我們通過一系列例子的詳細說明來證明這個規則吧!
我試驗用的編譯器包括GCC 3.4.2和VC6.0的C編譯器,平臺為Windows XP + Sp2。
我們將用典型的struct對齊來說明。首先我們定義一個struct:
#pragma pack(n) /* n = 1, 2, 4, 8, 16 */
struct test_t {
int a;
char b;
short c;
char d;
};
#pragma pack(n)
首先我們首先確認在試驗平臺上的各個類型的size,經驗證兩個編譯器的輸出均為:
sizeof(char) = 1
sizeof(short) = 2
sizeof(int) = 4
我們的試驗過程如下:通過#pragma pack(n)改變“對齊系數”,然后察看sizeof(struct test_t)的值。
1、1字節對齊(#pragma pack(1))
輸出結果:sizeof(struct test_t) = 8 [兩個編譯器輸出一致]
分析過程:
1) 成員數據對齊
#pragma pack(1)
struct test_t {
int a; /* 長度4 < 1 按1對齊;起始offset=0 0%1=0;存放位置區間[0,3] */
char b; /* 長度1 = 1 按1對齊;起始offset=4 4%1=0;存放位置區間[4] */
short c; /* 長度2 > 1 按1對齊;起始offset=5 5%1=0;存放位置區間[5,6] */
char d; /* 長度1 = 1 按1對齊;起始offset=7 7%1=0;存放位置區間[7] */
};
#pragma pack()
成員總大小=8
2) 整體對齊
整體對齊系數 = min((max(int,short,char), 1) = 1
整體大小(size)=$(成員總大小) 按 $(整體對齊系數) 圓整 = 8 /* 8%1=0 */ [注1]
2、2字節對齊(#pragma pack(2))
輸出結果:sizeof(struct test_t) = 10 [兩個編譯器輸出一致]
分析過程:
1) 成員數據對齊
#pragma pack(2)
struct test_t {
int a; /* 長度4 > 2 按2對齊;起始offset=0 0%2=0;存放位置區間[0,3] */
char b; /* 長度1 < 2 按1對齊;起始offset=4 4%1=0;存放位置區間[4] */
short c; /* 長度2 = 2 按2對齊;起始offset=6 6%2=0;存放位置區間[6,7] */
char d; /* 長度1 < 2 按1對齊;起始offset=8 8%1=0;存放位置區間[8] */
};
#pragma pack()
成員總大小=9
2) 整體對齊
整體對齊系數 = min((max(int,short,char), 2) = 2
整體大小(size)=$(成員總大小) 按 $(整體對齊系數) 圓整 = 10 /* 10%2=0 */
3、4字節對齊(#pragma pack(4))
輸出結果:sizeof(struct test_t) = 12 [兩個編譯器輸出一致]
分析過程:
1) 成員數據對齊
#pragma pack(4)
struct test_t {
int a; /* 長度4 = 4 按4對齊;起始offset=0 0%4=0;存放位置區間[0,3] */
char b; /* 長度1 < 4 按1對齊;起始offset=4 4%1=0;存放位置區間[4] */
short c; /* 長度2 < 4 按2對齊;起始offset=6 6%2=0;存放位置區間[6,7] */
char d; /* 長度1 < 4 按1對齊;起始offset=8 8%1=0;存放位置區間[8] */
};
#pragma pack()
成員總大小=9
2) 整體對齊
整體對齊系數 = min((max(int,short,char), 4) = 4
整體大小(size)=$(成員總大小) 按 $(整體對齊系數) 圓整 = 12 /* 12%4=0 */
4、8字節對齊(#pragma pack(8))
輸出結果:sizeof(struct test_t) = 12 [兩個編譯器輸出一致]
分析過程:
1) 成員數據對齊
#pragma pack(8)
struct test_t {
int a; /* 長度4 < 8 按4對齊;起始offset=0 0%4=0;存放位置區間[0,3] */
char b; /* 長度1 < 8 按1對齊;起始offset=4 4%1=0;存放位置區間[4] */
short c; /* 長度2 < 8 按2對齊;起始offset=6 6%2=0;存放位置區間[6,7] */
char d; /* 長度1 < 8 按1對齊;起始offset=8 8%1=0;存放位置區間[8] */
};
#pragma pack()
成員總大小=9
2) 整體對齊
整體對齊系數 = min((max(int,short,char), 8) = 4
整體大小(size)=$(成員總大小) 按 $(整體對齊系數) 圓整 = 12 /* 12%4=0 */
5、16字節對齊(#pragma pack(16))
輸出結果:sizeof(struct test_t) = 12 [兩個編譯器輸出一致]
分析過程:
1) 成員數據對齊
#pragma pack(16)
struct test_t {
int a; /* 長度4 < 16 按4對齊;起始offset=0 0%4=0;存放位置區間[0,3] */
char b; /* 長度1 < 16 按1對齊;起始offset=4 4%1=0;存放位置區間[4] */
short c; /* 長度2 < 16 按2對齊;起始offset=6 6%2=0;存放位置區間[6,7] */
char d; /* 長度1 < 16 按1對齊;起始offset=8 8%1=0;存放位置區間[8] */
};
#pragma pack()
成員總大小=9
2) 整體對齊
整體對齊系數 = min((max(int,short,char), 16) = 4
整體大小(size)=$(成員總大小) 按 $(整體對齊系數) 圓整 = 12 /* 12%4=0 */