This article is for reading of
C++ Templates The Complete Guide.
1 Define a function template:
template <typename T>
inline T const& max (T const& a, T const& b)
{
return a<b?b:a;
}
As seen in this example, template parameters must be announced with syntax of the following form:
template < comma-separated-list-of-parameters >, the keyword typename introduces a so-called type parameter.
2 Calling to a function template:
int i = 42;
std::cout << "max(7,i): " << ::max(7,i) << std::endl;
double f1 = 3.4;
double f2 = -6.7;
std::cout << "max(f1,f2): " << ::max(f1,f2) << std::endl;
std::string s1 = "mathematics";
std::string s2 = "math";
std::cout << "max(s1,s2): " << ::max(s1,s2) << std::endl;
Normally, templates aren't compiled into single entities that can handle any type. Instead, different entities are generated from the template for every type for which the template is used.
3 Note that no automatic type conversion is allowed here. Each must match exactly. For example:
template <typename T>
inline T const& max (T const& a, T const& b);
…
max(4,7) // OK: T is int for both arguments
max(4,4.2) // ERROR: first T is int, second T is double
There are three ways to handle such an error:
Cast the arguments so that they both match: max(static_cast<double>(4),4.2) // OK
Specify (or qualify) explicitly the type of T: max<double>(4,4.2) // OK
4 Class template usage:
template <typenameTarget>
class Singleton
{
public:
static Target* Instance() //Static template member function should be impleted in the define of template
{ //notes: it is not a thread safe
if (m_pInstance==NULL)
m_pInstance = new Target();
return m_pInstance;
}
protected: //!!set the constructor and destructor to be protected to avoid unnecessary intance
Singleton(); // constructor
~Singleton(); // destructor
private:
static Target* m_pInstance;
};
//static class member initialisation should be global
template <typename Target>
Target* Singleton<Target>::m_pInstance = NULL;
int main(int argc, _TCHAR* argv[])
{
int* testSingle = Singleton<int>::Instance();
std::cout<<*testSingle<<std::endl;
}
4.1 Nontype Class Template Parameters
Notype parameter provides a special way to define the property of template. But you cannot use floating-point numbers, class-type objects, and objects with internal linkage (such as string
literals) as arguments for nontype template parameterstemplate <typename T,
int MAXSIZE>
class Stack {
private:
T elems[
MAXSIZE]; // elements
int numElems; // current number of elements
}
Stack<int,20> int20Stack; // stack of up to 20 ints
6.1 The way that including declare and implemention of template in the header file is inclusion model. This kind of model is popular in the development.
7.1 The process of creating a regular class, function, or member function from a template by substituting actual values for its arguments is called template instantiation. This resulting entity (class, function, or member function) is generically called a specialization.
posted @
2012-06-08 18:42 鷹擊長空 閱讀(229) |
評論 (0) |
編輯 收藏
All objects that inherit from NSObject know these three methods:
isKindOfClass: returns whether an object is that kind of class (inheritance included)
isMemberOfClass: returns whether an object is that kind of class (no inheritance)
respondsToSelector: returns whether an object responds to a given method
Class testing methods take a Class
You get a Class by sending the class method class to a class :)
if ([obj isKindOfClass:[NSString class]]) {
NSString *s = [(NSString *)obj stringByAppendingString:@”xyzzy”];
}
Method testing methods take a selector (SEL)
Special @selector() directive turns the name of a method into a selector
if ([obj respondsToSelector:@selector(shoot)]) {
[obj shoot];
} else if ([obj respondsToSelector:@selector(shootAt:)]) {
[obj shootAt:target];
}
SEL is the Objective-C “type” for a selector
SEL shootSelector = @selector(shoot);
SEL shootAtSelector = @selector(shootAt:);
SEL moveToSelector = @selector(moveTo:withPenColor:);
posted @
2012-06-04 19:43 鷹擊長空 閱讀(160) |
評論 (0) |
編輯 收藏
摘要: Objective-C,is a reflective, object-oriented programming language that adds Smalltalk-style messaging to the C programming language.Today, it is used primarily on Apple's Mac OS X and iOS: two environ...
閱讀全文
posted @
2012-05-18 14:31 鷹擊長空 閱讀(298) |
評論 (0) |
編輯 收藏This week, I got a task to add a Target into a Mac OSX project, after several failure, I finally make it. And here is the steps:
1、Open the project, click the top left item which named after the project, you will see the project setting in the right tab,
2、click the Add Target button,you will see this, choose the type you like, and type into the Target name:
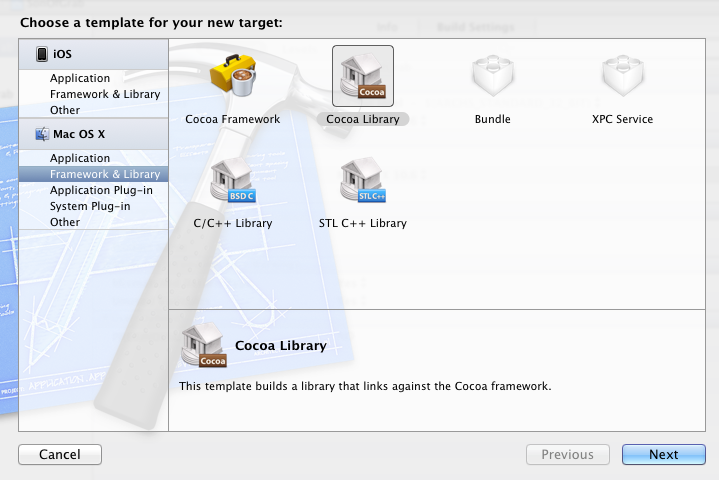
3、create a xconfig file to config the information of the taget, and select the xconfig file as the relative file:
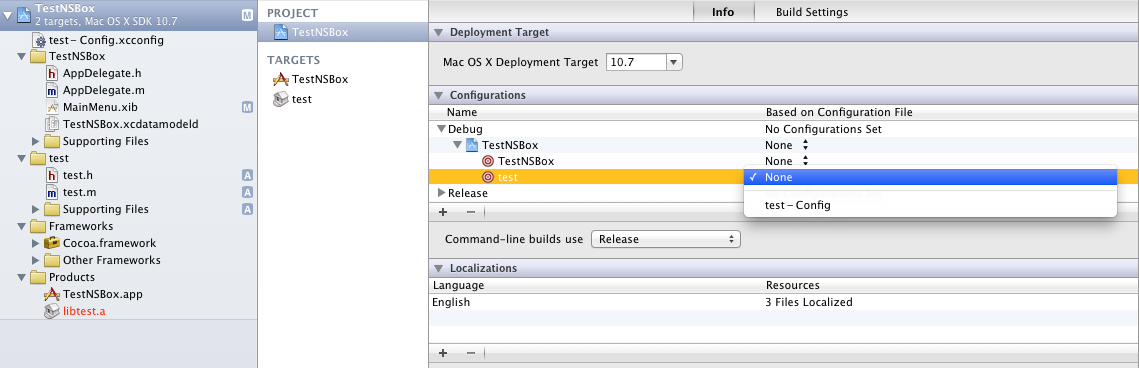
4、edit the xconfig file to set the value;
Note: the regular of xconfig is special, new value will cove all the old value, make sure that value could cover all the including path;
posted @
2012-04-28 16:10 鷹擊長空 閱讀(678) |
評論 (0) |
編輯 收藏Dynamic programming is similar to divide-and-conquer, it divide the original problem into small part, but they have different directions, Dynamic programming is bottom-up, while divide-and-conquer is a top-down approach. In this approach, we solve the small instance and store the result in a table, when we need the result, we just search in the table, and thus save large amount of time to re-calculation.
The steps in the development of a dynamic programming
algorithm are as follows:
-
Establish a recursive property that gives the solution to an instance of the problem.
-
Solve an instance of the problem in a bottom-up fashion by solving smaller instances first.
A famous applications of dynamic programming is Floyd's Algorithm for Shortest Paths.
Using dynamic programming, we create a cubic-time algorithm for the Shortest Paths problem. First we develop an algorithm that determines only the lengths of the shortest paths. After that we modify it to produce shortest paths as well. We represent a weighted graph containing n vertices by an array W where
The array D in Figure 3.3 contains the lengths of the shortest paths in the graph. For example, D[3][5] is 7 because 7 is the length of a shortest path from v3 to v5. If we can develop a way to calculate the values in D from those in W, we will have an algorithm for the Shortest Paths problem. We accomplish this by creating a sequence of n + 1 arrays D(k), where 0 ≤ k ≤ n and where
 Figure 3.3: W represents the graph in Figure 3.2 and D contains the lengths of the shortest paths. Our algorithm for the Shortest Paths problem computes the values in D from those in W.
Figure 3.3: W represents the graph in Figure 3.2 and D contains the lengths of the shortest paths. Our algorithm for the Shortest Paths problem computes the values in D from those in W. -
D(k)[i][j] = length of a shortest path from vi to vj using only vertices in the set {v1, v2, …, vk} as intermediate vertices.
Therefore, to determine D from W we need only find a way to obtain D(n) from D(0). The steps for using dynamic programming to accomplish this are as follows:
-
Establish a recursive property (process) with which we can compute D(k) from D(k-1).
-
Solve an instance of the problem in a bottom-up fashion by repeating the process (established in Step 1) for k = 1 to n. This creates the sequence
Dynamic programming algorithm provides a solution for an optimization problem, and the steps in the development of such an algorithm are as follows:
-
Establish a recursive property that gives the optimal solution to an instance of the problem.
-
Compute the value of an optimal solution in a bottom-up fashion.
-
Construct an optimal solution in a bottom-up fashion.
Steps 2 and 3 are ordinarily accomplished at about the same point in the algorithm.
The principle of optimality is said to apply in a problem if an optimal solution to an instance of a problem always contains optimal solutions to all substances.
posted @
2012-03-27 18:48 鷹擊長空 閱讀(204) |
評論 (0) |
編輯 收藏Should we write portable code?
Lots of software companies try to write portable code, apparently, this method could save a amount of time and energy to re-design code in different platforms.
However, with the development of mobile platform, mobile devices became more and more important, and the gap between these platforms is huge. One portable code has to consider more and become larger to meet the different devices. What is more, comparing with the PC platform, the resources such as memory and storage in mobile device is very small. So porting the code from PC to mobile device is not a good idea. What is more, the demand of customer of different platforms is different, it is not necessary to provide the same experience
Do you encounter such situations in your work? how do you deal with such issue?
posted @
2012-03-07 09:58 鷹擊長空 閱讀(129) |
評論 (0) |
編輯 收藏Recently, I have read Inside COM, it is not my first time to read it. But still I got some useful information from it.
First of all, rather than inheriting, Containment and Aggregation are the two methods COM used to achieve reusability.
Aggregation is the specialized form of Containment, in which the programmer doesn’t have to implement code in the outer component to forward/delegate a call to the inner component and hence makes the life of a programmer easier. In Aggregation, the outer component hands over the control of the interface, which is being implemented by the inner component, to the client directly and the outer component gets out of the picture. In Aggregation, the interface to the inner component is exposed directly to the client, which is in contrast with the Containment. The outer IUnknown and the Inner IUnknown will be having the different implementation of the QueryInterface and hence it violates the basic QueryInterface rules. To forward/delegate calls to the outer IUnknown, the inner component needs the outer component’s IUnknown interface pointer. The outer component passes its IUnknown interface pointer at the time of creating the inner component. The outer component calls CoCreateInstance and passes its IUnknown pointer in the second argument of CoCreateInstance. If this parameter is non-NULL, then the component is being aggregated, otherwise the component is not aggregated.
Secondly, The IDispatch interface was initially designed to support Automation. It provides a late-binding mechanism to access and retrieve information about an object's methods and properties.In addition to the methods inherited from IUnknown, server developers must implement the following methods within the class definition of each object that is exposed:
- GetTypeInfoCount returns the number of type descriptions for the object. For objects that support IDispatch, the type information count is always one.
- GetTypeInfo retrieves a description of the object's programmable interface.
- GetIDsOfNames maps the name of a method or property to a DISPID, which is later used to invoke the method or property.
- Invoke calls one of the object's methods, or gets or sets one of its properties.
When the client need to call the method provide by the server, and the code is like this:
1 HRESULT hret=CoInitialize(NULL); assert(SUCCEEDED(hret));
HRESULT hret=CoInitialize(NULL); assert(SUCCEEDED(hret));
2 CComPtr<IDispatch> ptr;
3
4 ptr.CoCreateInstance(L"InternetExplorer.Application");
5 if(ptr==0) { wprintf(L"Unable to create Application\n"); return 1; }
6
7 wchar_t *array=L"GoHome";
9 long id;
10 hret=ptr->GetIDsOfNames(IID_NULL,&array,1,LOCALE_SYSTEM_DEFAULT,&id);
11 assert(SUCCEEDED(hret));
12
13 DISPPARAMS noparams; memset(&noparams,0,sizeof(noparams));
14
15 hret=ptr->Invoke(id,IID_NULL,LOCALE_SYSTEM_DEFAULT,DISPATCH_METHOD,&noparams,NULL,NULL,NULL);
18 CoUninitialize(); return 0;
19
Third, Connection Points, Com’s Observer Pattern
-Based on Callbacks
-COM-Object can have one or more event sources
-Per event source may be one or more subscribed event sink
-asynchronous communication between a server and its clients
//Client
class myEventSink : public EventSink
{
void handleEvent(int arg)
{ cout << “myEventHandler” << arg << endl; }
};
//Server
[ object, uuid(…) }
interface IEventSource : IUnknown
{
HRESULT Attach( [in] IEventSink* PEveSink);
};
Protocol
IConnectionPointContainer::FindConnectionPoint
IConnectionPoint::Advise //passing sink interface pointer, receiving cookie
IConnectionPoint::Unadvice //terminates notification
posted @
2012-03-04 22:08 鷹擊長空 閱讀(1256) |
評論 (0) |
編輯 收藏賺錢最快的方式是什么?壟斷
AT&T就是憑著壟斷發的財,又由于被反壟斷和貪婪而日薄西山。當一個公司沒有人對它有控制時,它的長期發展就會有問題
IBM 成功的秘訣是保守經營,它基本上是不見兔子不撒鷹。如果蘋果公司失敗了, IBM 不需要做任何事情。如果前者成功了,IBM 依靠它強大的技術儲備完全可以后發制人。保守的好處是不容易輕易出錯,因為像 IBM 這樣服務于美國乃至世界各國核心部門的公司,產品上出一點錯就會造成不可彌補的損失。
但是IBM在技術上是極富創新的,深藍還有沃森就是代表。強練內功,慢踏腳步。
硅谷一位最成功的CEO 講,凡是和微軟合作的公司,最后都沒有好結果。IBM 也許是其中第一個吃虧者。蘋果估計會是下一個吧!
秦有六國,兢兢以強;六國既除,訑訑乃亡
現在,一個酷睿處理器如果晝夜不停使用,一年的耗電量已經等同于它的價格。因此,今后處理器設計必須考慮能耗
互聯網這個行業的游戲規則——開放、免費和盈利
在商業史上,類似的事情時常發生,兩個在競爭中處于劣勢的公司合并后,不僅沒有得到累加的市場份額,而且只達到兩者合并前少的那份。原因很簡單,在競爭中處于劣勢的公司必定有它經營管理的問題。如果這些問題得不到解決,合并后問題會翻倍,在競爭中會更加處于劣勢,從而進一步丟失市場份額。這就好比幾塊煤放在一起是一堆煤,而不是能發亮的鉆石
posted @
2012-01-08 23:59 鷹擊長空 閱讀(580) |
評論 (0) |
編輯 收藏白楊
http://baiy.cn
在我幾年前開始寫《C++編碼規范與指導》一文時,就已經規劃著要加入這樣一篇討論 C++ 異常機制的文章了。沒想到時隔幾年以后才有機會把這個尾巴補完 :-)。
還是那句開場白:“在恰當的場合使用恰當的特性” 對每個稱職的 C++ 程序員來說都是一個基本標準。想要做到這點,就必須要了解語言中每個特性的實現方式及其時空開銷。異常處理由于涉及大量底層內容,向來是 C++ 各種高級機制中較難理解和透徹掌握的部分。本文將在盡量少引入底層細節的前提下,討論 C++ 中這一嶄新特性,并分析其實現開銷:
進程和線程的概念相信各位看官早已耳熟能詳。在這里,我只想帶大家回憶幾點重要概念:
- 一個進程中可以同時包含多個線程。
- 我們通常認為線程是操作系統可識別的最小并發執行和調度單位(不要跟俺說還有 Green Thread 或者 Fiber,OS Kernel 不認識也不參與這些物件的調度)。
- 同一進程中的多個線程共享代碼段(代碼和常量)、數據段(靜態和全局變量)和擴展段(堆存儲),但是每個線程有自己的棧段。棧段又叫運行時棧,用來存放所有局部變量和臨時變量(參數、返回值、臨時構造的變量等)。這一條對下文中的某些概念來說是非常重要的 。但是請注意,這里提到的各個“段”都是邏輯上的說法,在物理上某些硬件架構或者操作系統可能不使用段式存儲。不過沒關系,編譯器會保證這些邏輯概念和假設的前提條件對每個 C/C++ 程序員來說始終是成立的。
- 由于共享了除棧以外的所有內存地址段,線程不可以有自己的“靜態”或“全局”變量,為了彌補這一缺憾,操作系統通常會提供一種稱為 TLS(Thread Local Storage,即:“線程本地存儲”)的機制。通過該機制可以實現類似的功能。TLS 通常是線程控制塊(TCB)中的某個指針所指向的一個指針數組,數組中的每個元素稱為一個槽(Slot),每個槽中的指針由使用者定義,可以指向任意位置(但通常是指向堆存儲中的某個偏移)。
|
接著我們來回顧下一個預備知識:編譯器如何實現函數的調用和返回。一般來說,編譯器會為當前調用棧里的每個函數建立一個棧框架(Stack Frame)。“棧框架”擔負著以下重要任務:
- 傳遞參數:通常,函數的調用參數總是在這個函數棧框架的最頂端。
- 傳遞返回地址:告訴被調用者的 return 語句應該 return 到哪里去,通常指向該函數調用的下一條語句(代碼段中的偏移)。
- 存放調用者的當前棧指針:便于清理被調用者的所有局部變量、并恢復調用者的現場。
- 存放當前函數內的所有局部變量:記得嗎?剛才說過所有局部和臨時變量都是存儲在棧上的。
最后再復習一點:棧是一種“后進先出”(LIFO)的數據結構,不過實際上大部分棧的實現都支持隨機訪問。
下面我們來看個具體例子:
假設有 FuncA、FuncB 和 FuncC 三個函數,每個函數均接收兩個整形值作為其參數。在某線程上的某一時間段內,FuncA 調用了 FuncB,而 FuncB 又調用了 FuncC。則,它們的棧框架看起來應該像這樣:

圖1 函數調用棧框架示例
正如上圖所示的那樣,隨著函數被逐級調用,編譯器會為每一個函數建立自己的棧框架,棧空間逐漸消耗。隨著函數的逐級返回,該函數的棧框架也將被逐級銷毀,棧空間得以逐步釋放。順便說一句,遞歸函數的嵌套調用深度通常也是取決于運行時棧空間的剩余尺寸。
這里順便解釋另一個術語:調用約定(calling convention)。調用約定通常指:調用者將參數壓入棧中(或放入寄存器中)的順序,以及返回時由誰(調用者還是被調用者)來清理這些參數等細節規程方面的約定。
最后再說一句,這里所展示的函數調用乃是最“經典”的方式。實際情況是:在開啟了優化選項后,編譯器可能不會為一個內聯甚至非內聯的函數生成棧框架,編譯器可能使用很多優化技術消除這個構造。不過對于一個 C/C++ 程序員來說,達到這樣的理解程度通常就足夠了。 |
首先澄清一點,這里說的 “C++ 函數”是指:
- 該函數可能會直接或間接地拋出一個異常:即該函數的定義存放在一個 C++ 編譯(而不是傳統 C)單元內,并且該函數沒有使用“throw()”異常過濾器。
- 或者該函數的定義內使用了 try 塊。
以上兩者滿足其一即可。為了能夠成功地捕獲異常和正確地完成棧回退(stack unwind),編譯器必須要引入一些額外的數據結構和相應的處理機制。我們首先來看看引入了異常處理機制的棧框架大概是什么樣子:

圖2 C++函數調用棧框架示例
由圖2可見,在每個 C++ 函數的棧框架中都多了一些東西。仔細觀察的話,你會發現,多出來的東西正好是一個 EXP 類型的結構體。進一步分析就會發現,這是一個典型的單向鏈表式結構:
-
piPrev 成員指向鏈表的上一個節點,它主要用于在函數調用棧中逐級向上尋找匹配的 catch 塊,并完成棧回退工作。 -
piHandler 成員指向完成異常捕獲和棧回退所必須的數據結構(主要是兩張記載著關鍵數據的表:“try”塊表:tblTryBlocks 及“棧回退表”:tblUnwind)。 -
nStep 成員用來定位 try 塊,以及在棧回退表中尋找正確的入口。
需要說明的是:編譯器會為每一個“C++ 函數”定義一個 EHDL 結構,不過只會為包含了“try”塊的函數定義 tblTryBlocks 成員。此外,異常處理器還會為每個線程維護一個指向當前異常處理框架的指針。該指針指向異常處理器鏈表的鏈尾,通常存放在某個 TLS 槽或能起到類似作用的地方。
最后,請再看一遍圖2,并至少對其中的數據結構留下一個大體印象。我們會在后面多個小節中詳細討論它們。
注意:為了簡化起見,本文中描述的數據結構內,大多省略了一些與話題無關的成員。 |
| “棧回退”是伴隨異常處理機制引入 C++ 中的一個新概念,主要用來確保在異常被拋出、捕獲并處理后,所有生命期已結束的對象都會被正確地析構,它們所占用的空間會被正確地回收。
受益于棧回退機制的引入,以及 C++ 類所支持的“資源申請即初始化”語意,使得我們終于能夠徹底告別既不優雅也不安全的 setjmp/longjmp 調用,簡便又安全地實現遠程跳轉了。我想這也是 C++ 異常處理機制在錯誤處理以外唯一一種合理的應用方式了。
下面我們就來具體看看編譯器是如何實現棧回退機制的:

圖3 C++ 棧回退機制
圖3中的“FuncUnWind”函數內,所有真實代碼均以黑色和藍色字體標示,編譯器生成的代碼則由灰色和橙色字體標明。此時,在圖2里給出的 nStep 變量和 tblUnwind 成員作用就十分明顯了。
nStep 變量用于跟蹤函數內局部對象的構造、析構階段。再配合編譯器為每個函數生成的 tblUnwind 表,就可以完成退棧機制。表中的 pfnDestroyer 字段記錄了對應階段應當執行的析構操作(析構函數指針);pObj 字段則記錄了與之相對應的對象 this 指針偏移。將 pObj 所指的偏移值加上當前棧框架基址(EBP),就是要代入 pfnDestroyer 所指析構函數的 this 指針,這樣即可完成對該對象的析構工作。而 nNextIdx 字段則指向下一個需要析構對象所在的行(下標)。
在發生異常時,異常處理器首先檢查當前函數棧框架內的 nStep 值,并通過 piHandler 取得 tblUnwind[] 表。然后將 nStep 作為下標帶入表中,執行該行定義的析構操作,然后轉向由 nNextIdx 指向的下一行,直到 nNextIdx 為 -1 為止。在當前函數的棧回退工作結束后,異常處理器可沿當前函數棧框架內 piPrev 的值回溯到異常處理鏈中的上一節點重復上述操作,直到所有回退工作完成為止。
值得一提的是,nStep 的值完全在編譯時決定,運行時僅需執行若干次簡單的整形立即數賦值(通常是直接賦值給CPU里的某個寄存器)。此外,對于所有內部類型以及使用了默認構造、析構方法(并且它的所有成員和基類也使用了默認方法)的類型,其創建和銷毀均不影響 nStep 的值。
注意:如果在棧回退的過程中,由于析構函數的調用而再次引發了異常(異常中的異常),則被認為是一次異常處理機制的嚴重失敗。此時進程將被強行禁止。為防止出現這種情況,應在所有可能拋出異常的析構函數中使用“std::uncaught_exception()”方法判斷當前是否正在進行棧回退(即:存在一個未捕獲或未完全處理完畢的異常)。如是,則應抑制異常的再次拋出。 |
| 一個異常被拋出時,就會立即引發 C++ 的異常捕獲機制:

圖4 C++ 異常捕獲機制
在上一小節中,我們已經看到了 nStep 變量在跟蹤對象構造、析構方面的作用。實際上 nStep 除了能夠跟蹤對象創建、銷毀階段以外,還能夠標識當前執行點是否在 try 塊中,以及(如果當前函數有多個 try 塊的話)究竟在哪個 try 塊中。這是通過在每一個 try 塊的入口和出口各為 nStep 賦予一個唯一 ID 值,并確保 nStep 在對應 try 塊內的變化恰在此范圍之內來實現的。
在具體實現異常捕獲時,首先,C++ 異常處理器檢查發生異常的位置是否在當前函數的某個 try 塊之內。這項工作可以通過將當前函數的 nStep 值依次在 piHandler 指向 tblTryBlocks[] 表的條目中進行范圍為 [nBeginStep, nEndStep) 的比對來完成。
例如:若圖4 中的 FuncB 在 nStep == 2 時發生了異常,則通過比對 FuncB 的 tblTryBlocks[] 表發現 2∈[1, 3),故該異常發生在 FuncB 內的第一個 try 塊中。
其次,如果異常發生的位置在當前函數中的某個 try 塊內,則嘗試匹配該 tblTryBlocks[] 相應條目中的 tblCatchBlocks[] 表。tblCatchBlocks[] 表中記錄了與指定 try 塊配套出現的所有 catch 塊相關信息,包括這個 catch 塊所能捕獲的異常類型及其起始地址等信息。
若找到了一個匹配的 catch 塊,則復制當前異常對象到此 catch 塊,然后跳轉到其入口地址執行塊內代碼。
否則,則說明異常發生位置不在當前函數的 try 塊內,或者這個 try 塊中沒有與當前異常相匹配的 catch 塊,此時則沿著函數棧框架中 piPrev 所指地址(即:異常處理鏈中的上一個節點)逐級重復以上過程,直至找到一個匹配的 catch 塊或到達異常處理鏈的首節點。對于后者,我們稱為發生了未捕獲的異常,對于 C++ 異常處理器而言,未捕獲的異常是一個嚴重錯誤,將導致當前進程被強制結束。
注意:雖然在圖4示例中的 tblTryBlocks[] 只有一個條目,這個條目中的 tblCatchBlocks[] 也只有一行。但是在實際情況中,這兩個表中都允許有多條記錄。意即:一個函數中可以有多個 try 塊,每個 try 塊后均可跟隨多個與之配套的 catch 塊。
注意:按照標準意義上的理解,異常時的棧回退是伴隨著異常捕獲過程沿著異常處理鏈逐層向上進行的。但是有些編譯器是在先完成異常捕獲后再一次性進行棧回退的。無論具體實現使用了哪種方式,除非正在開發一個內存嚴格受限的嵌入式應用,通常我們按照標準語意來理解都不會產生什么問題。
備注:實際上 tblCatchBlocks 中還有一些較為關鍵但被故意省略的字段。比如指明該 catch 塊異常對象復制方式(傳值(拷貝構造)或傳址(引用或指針))的字段,以及在何處存放被復制的異常對象(相對于入口地址的偏移位置)等信息。 |
| 接下來討論整個 C++ 異常處理機制中的最后一個環節,異常的拋出:

圖5 C++ 異常拋出
在編譯一段 C++ 代碼時,編譯器會將所有 throw 語句替換為其 C++ 運行時庫中的某一指定函數,這里我們叫它 __CxxRTThrowExp(與本文提到的所有其它數據結構和屬性名一樣,在實際應用中它可以是任意名稱)。該函數接收一個編譯器認可的內部結構(我們叫它 EXCEPTION 結構)。這個結構中包含了待拋出異常對象的起始地址、用于銷毀它的析構函數,以及它的 type_info 信息。對于沒有啟用 RTTI 機制(編譯器禁用了 RTTI 機制或沒有在類層次結構中使用虛表)的異常類層次結構,可能還要包含其所有基類的 type_info 信息,以便與相應的 catch 塊進行匹配。
在圖5中的深灰色框圖內,我們使用 C++ 偽代碼展示了函數 FuncA 中的 “throw myExp(1);” 語句將被編譯器最終翻譯成的樣子。實際上在多數情況下,__CxxRTThrowExp 函數即我們前面曾多次提到的“異常處理器”,異常捕獲和棧回退等各項重要工作都由它來完成。
__CxxRTThrowExp 首先接收(并保存)EXCEPTION 對象;然后從 TLS:Current ExpHdl 處找到與當前函數對應的 piHandler、nStep 等異常處理相關數據;并按照前文所述的機制完成異常捕獲和棧回退。由此完成了包括“拋出”->“捕獲”->“回退”等步驟的整套異常處理機制。 |
Microsoft Windows 帶有一種名為“結構化異常處理”的機制,非常著名的“內存訪問違例”出錯對話框就是該機制的一種體現。Windows 結構化異常處理與前文討論的 C++ 異常處理機制有驚人的相似之處,同樣使用類似的鏈式結構實現。對于 Windows 下的應用程序,只需使用 SetUnhandledExceptionFilter API 注冊異常處理器;用 FS:[0] 替代前文所述的 TLS: Current ExpHdl 等很少的改動,即可將此兩種錯誤處理機制合而為一。這樣做的優勢十分明顯:
- 由于可直接借助操作系統提供的機制,所以簡化了 C++ 異常處理器的實現。
- 使“catch (...)” 塊得以捕獲操作系統產生的異常(如:“內存訪問違例”等等)。
- 使操作系統的異常處理機制能夠捕獲所有 C++ 異常。
實際上,大多數 Windows 下的 C++ 編譯器的異常機制均使用這種方式實現。 |
至此,我們已完整地闡述了整套 C++ 異常處理機制的實現原理。我在本文的開頭曾提到,作為一名 C++ 程序員,了解其某一特性的實現原理主要是為了避免錯誤地使用該特性。要達到這個目的,還要在了解實現原理的基礎上進行一些額外的開銷分析工作:
| 特性 |
時間開銷 |
空間開銷 |
| EHDL |
無運行時開銷 |
每“C++函數”一個 EHDL 對象,其中的 tblTryBlocks[] 成員僅在函數中包含至少一個 try 塊時使用。典型情況下小于 64 字節。
|
| C++棧框架 |
極高的 O(1) 效率,每次調用時進行3次額外的整形賦值和一次 TLS 訪問。 |
每 調用兩個指針和一個整形開銷。典型情況下小于 16 字節。
|
| step 跟蹤 |
極高的 O(1) 效率每次進出 try 塊或對象構造/析構一次整形立即數賦值。 |
無(已記入 C++ 棧框架中的相應項目)。
|
| 異常的拋出、捕獲和棧回退 |
異常的拋出是一次 O(1) 級操作。在單個函數中進行捕獲和棧回退也均為 O(1) 操作。
但異常捕獲的總體成本為 O(m),其中 m 等于當前函數調用棧中,從拋出異常的位置到達匹配 catch 塊之間所經過的函數調用中,包含 try 塊(即:定義了有效 tblTryBlocks[])的函數個數。
棧回退的總成本為 O(n),其中 n 等于當前函數調用棧中,從拋出異常的位置到達匹配 catch 塊之間所經過的函數調用數。 |
在異常處理結束前,需保存異常對象及其析構函數指針和相應的 type_info 信息。
具體根據對象尺寸、編譯器選項(是否開啟 RTTI)及異常捕獲器的參數傳遞方式(傳值或傳址)等因素有較大變化。典型情況下小于 256 字節。
|
可以看出,在沒有拋出異常時,C++ 的異常處理機制是十分有效的。在有異常被拋出后,可能會依當前函數調用棧的情形進行若干次整形比較(try塊表匹配)操作,但這通常不會超過幾十次。對于大多數 15 年前的 CPU 來說,整形比較也只需 1 時鐘周期,所以異常捕獲的效率還是很高的。棧回退的效率則與 return 語句基本相當。
考慮到即使是傳統的函數調用、錯誤處理和逐級返回機制也不是沒有代價的。這些開銷在絕大多數情形下仍可以接受。空間開銷方面,每“C++ 函數”一個 EHDL 結構體的引入在某些極端情形下會明顯增加目標文件尺寸和內存開銷。但是典型情況下,它們的影響并不大,但也沒有小到可以完全忽略的程度。如果正在為一個資源嚴格受限的環境開發應用程序,你可能需要考慮關閉異常處理和 RTTI 機制以節約存儲空間。
以上討論的是一種典型的異常機制的實現方式,各具體編譯器廠商可能有自己的優化和改進方案,但總體的出入不會很大。 |
| 異常處理是 C++ 中十分有用的嶄新特性之一。在絕大多數情況下,它們都有著優異的表現和令人滿意的時空效率。異常處理本質上是另一種返回機制。但無論從軟件工程、模塊設計、編碼習慣還是時空效率等角度來說,除了在有充分文檔說明的前提下,偶爾可用來替代替代傳統的 setjmp/longjmp 功能外,應保證只將其用于程序的錯誤處理機制中。
此外,由于長跳轉的使用既易于出錯,又難于理解和維護。在編碼過程中也應當盡量避免使用。關于異常的一般性使用說明,請參考:代碼風格與版式:異常。 |
posted @
2011-12-13 18:23 鷹擊長空 閱讀(279) |
評論 (0) |
編輯 收藏 =============================================================
int pthread_create(
pthread_t *tid,
const pthread_attr_t *attr,
void*(*start_routine)(void*),
void *arg
);
//參數tid 用于返回新創建線程的線程號;
//start_routine 是線程函數指針,線程從這個函數開始獨立地運行;
//arg 是傳遞給線程函數的參數。由于start_routine 是一個指向參數類型為void*,返回值為void*的指針,所以如果需要傳遞或返回多個參數時,可以使用強制類型轉化。
=============================================================
void pthread_exit(
void* value_ptr
);
// 參數value_ptr 是一個指向返回狀態值的指針。
=============================================================
int pthread_join(
pthread_t tid ,
void **status
);
// 參數tid 是希望等待的線程的線程號,status 是指向線程返回值的指針,線程的返回值就是pthread_exit 中的value_ptr 參數,或者是return語句中的返回值。該函數可用于線程間的同步。
=============================================================
int pthread_mutex_init(
pthread_mutex_t *mutex,
const pthread_mutex_attr_t* attr
);
//該函數初始化一個互斥體變量,如果參數attr 為NULL,則互斥
//體變量mutex 使用默認的屬性。
=============================================================
int pthread_mutex_lock(
pthread_mutex_t *mutex
);
// 該函數用來鎖住互斥體變量。如果參數mutex 所指的互斥體已經
//被鎖住了,那么發出調用的線程將被阻塞直到其他線程對mutex 解鎖。
=============================================================
int pthread_mutex_trylock(
pthread_t *mutex
);
//該函數用來鎖住mutex 所指定的互斥體,但不阻塞。如果該互斥
//體已經被上鎖,該調用不會阻塞等待,而會返回一個錯誤代碼。
=============================================================
int pthread_mutex_unlock(
pthread_mutex_t *mutex
);
//該函數用來對一個互斥體解鎖。如果當前線程擁有參數mutex 所
//指定的互斥體,該調用將該互斥體解鎖。
=============================================================
int pthread_mutex_destroy (
pthread_mutex_t *mutex
);
//該函數用來釋放分配給參數mutex 的資源。調用成功時返回值為
//0, 否則返回一個非0 的錯誤代碼。
=============================================================
int pthread_cond_init(
pthread_cond_t *cond,
const pthread_cond_attr_t*attr
);
//該函數按參數attr指定的屬性創建一個條件變量。調用成功返回,
//并將條件變量ID 賦值給參數cond,否則返回錯誤代碼。
=============================================================
int pthread_cond_wait (
pthread_cond_t *cond ,
pthread_mutex_t*mutex
);
// 該函數調用為參數mutex 指定的互斥體解鎖,等待一個事件(由
//參數cond 指定的條件變量)發生。調用該函數的線程被阻塞直到有其他
//線程調用pthread_cond_signal 或pthread_cond_broadcast 函數置相應的條
//件變量,而且獲得mutex 互斥體時才解除阻塞。
=============================================================
int pthread_cond_timewait(
pthread_cond_t *cond ,
pthread_mutex_t*mutex ,
const struct timespec *abstime
);
// 該函數與pthread_cond_wait 不同的是當系統時間到達abstime 參數指定的時間時,被阻塞線程也可以被喚起繼續執行。
=============================================================
int pthread_cond_broadcast(
pthread_cond_t *cond
);
// 該函數用來對所有等待參數cond所指定的條件變量的線程解除阻塞,調用成功返回0,否則返回錯誤代碼。
=============================================================
int pthread_cond_signal(
pthread_cond_t *cond
);
// 該函數的作用是解除一個等待參數cond所指定的條件變量的線程的阻塞狀態。當有多個線程掛起等待該條件變量,也只喚醒一個線程。
=============================================================
int pthread_cond_destroy(
pthread_cond_t *cond
);
// 該函數的作用是釋放一個條件變量。釋放為條件變量cond 所分配的資源。調用成功返回值為0,否則返回錯誤代碼。
=============================================================
int pthread_key_create(
pthread_key_t key ,
void(*destructor(void*))
);
// 該函數創建一個鍵值,該鍵值映射到一個專有數據結構體上。如果第二個參數不是NULL,這個鍵值被刪除時將調用這個函數指針來釋放數據空間。
=============================================================
int pthread_key_delete(
pthread_key_t *key
);
// 該函數用于刪除一個由pthread_key_create 函數調用創建的TSD鍵。調用成功返回值為0,否則返回錯誤代碼。
=============================================================
int pthread_setspecific(
pthread_key_t key ,
const void(value)
);
// 該函數設置一個線程專有數據的值,賦給由pthread_key_create 創建的TSD 鍵,調用成功返回值為0,否則返回錯誤代碼。
=============================================================
void *pthread_getspecific(
pthread_key_t *key
);
// 該函數獲得綁定到指定TSD 鍵上的值。調用成功,返回給定參數key 所對應的數據。如果沒有數據連接到該TSD 鍵,則返回NULL。
=============================================================
int pthread_once(
pthread_once_t* once_control,
void(*init_routine)(void)
);
//該函數的作用是確保init_routine 指向的函數,在調用pthread_once的線程中只被運行一次。once_control 指向一個靜態或全局的變量。
=============================================================
posted @
2011-12-05 07:45 鷹擊長空 閱讀(265) |
評論 (0) |
編輯 收藏