之前因為時間匆忙,大區里產生唯一ID只是簡單寫了一個方法,今天趁著有時間,把里面一些過程寫出來,也算是個總結。 首先說說需求,現在游戲里數據庫為了分散熱點,都采用分表方式,以前那種一張表AUTO_INCREMENT的方式顯然不行了,那么將唯一ID放到業務進程里可行嗎?這個也不好,因為現在后臺都是多個部署,每個進程可以保證ID唯一,但是存到數據庫的時候就可能重復,所以我們還是得在DB上做文章。 因此就有了上篇文章的解決方案,單獨一張表,這張表的作用就是專門產生唯一ID,而且為多個業務提供唯一ID,多進程情況下也不需要鎖表,效率比較高,是不是很像設計模式里的工廠。接著我來分析下這張表。我們再來看看表結構和用法
create table SeqTab (
iSeqNo bigint(20) not null default 0, //表示唯一ID
iSeqType int(11) not null default 0, //表示業務ID
primary key(iSeqNo,iSeqType));
insert into SeqTab values(0,1); //初始化,假設一個業務編號為1
update SeqTab set iSeqNo=last_insert_id(iSeqNo+1) where iSeqType=1;
select last_insert_id(); //這兩句是獲取一個業務的唯一ID,供業務進程使用。 其實說到這張表,關鍵是說LAST_INSERT_ID()這個方法。它有兩種形式LAST_INSERT_ID(),LAST_INSERT_ID(expr)。 這個東西的特點是,1.屬于每個CONNECTION,CONNECTION之間相互不會影響 2.不屬于某個具體的表 3.返回最后一次INSERT AUTO_INCREMENT的值 4.假如以此使用INSERT插入 多行數據,只返回第一行數據產生的值 5.如果你UPDATE某個AUTO_INCREMENT的值,不會影響LAST_INSERT_ID()返回值 LAST_INSERT_ID(expr)與LAST_INSERT_ID()稍有不同,首先它返回expr的值,其次它的返回值會記錄在LAST_INSERT_ID()。 我們這里主要使用到了第一和第二個特點,每個進程并發執行update SeqTab set iSeqNo=last_insert_id(iSeqNo+1) where iSeqType=1;,就獲取屬于進程自己的iSeqNo并且記錄在 LAST_INSERT_ID中,通過第二句取出該值。 接著我們在比較下其他一些辦法。 第一種是直接一張表,里面有一個ID字段,設置成AUTO_INCREMENT。這個的問題是每個業務ID不是連續的,是離散的。 第二種是使用GUID或者UUID,但是這個問題我個人覺得是效率上的差異,字符串沒有數字的效率好,另外數字ID今后也可以拼接一些區信息,之后跨區的時候可以方便獲取對象是哪個區的.
posted @
2012-12-06 23:01 梨樹陽光 閱讀(2253) |
評論 (2) |
編輯 收藏
Mysql中除了使用auto_increment字段作為自增序號以外 還有另外一種辦法 可以提供唯一序列號并且可以由一張表完成對多個序列
要求的滿足。
大致如下:
1.創建一個簡單表
create table SeqTab
( iSeqNo int not null default 0,
iSeqType int not null default 0);
2.插入一調記錄
insert into SeqTab values(0,13); // 0表示SeqNo初始值,13為SeqType,同一張表可對多個應用提供Seq序列服務
3.不管多進程 or 單進程對SeqTab表同時進行訪問,使用一下方法獲取序列號
1st->update SeqTab set iSeqNo=last_insert_id(iSeqNo+1) where iSeqType=13;
2nd->select last_insert_id();
4.因多進程對SeqTab同時訪問,進行update SeqTab set iSeqNo=last_insert_id(iSeqNo+1);時,數據庫保證了update的事務
完整性,且last_insert_id()是與當前mysql連接相關的,所以多進程同時使用時,也不會沖突。
posted @
2012-12-05 11:54 梨樹陽光 閱讀(1738) |
評論 (2) |
編輯 收藏
相信大家在開發后臺的過程中都遇到過中文亂碼的問題,今天我就來講講其中的原因。 我這建了3張表,test_latin1,test_utf8,test_gbk,表結構如下 +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| name | char(32) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
我的前端是gbk的編碼
執行下面的語句
set names 'latin1'
insert into test_latin1 set name='王';('王'字是GBK編碼)
select name from test_latin1;
結果是否為亂碼?
執行下面的語句
set names 'gbk' insert into test_latin1 set name='王';('王'字是GBK編碼) select name from test_latin1; 結果是否為亂碼? 執行下面的語句 set names 'latin1' insert into test_utf8 set name='王';('王'字是GBK編碼) select name from test_utf8 ; 結果是否為亂碼? 我們舉個例子,假設一個漢字的字符編碼為0xFFFF,它在屏幕上能夠正常顯示,如果漢字存入數據庫的時候和從數據庫中取出的時候,編碼一致,那么它肯定不是亂碼。反過來,如果輸出的時候是亂碼,那么它肯定被轉碼了,至于為什么被轉碼了,我們得看看mysql里面做了什么(mysql難道會把無碼片變成了有碼片?) 首先mysql里面有2個概念,一個叫character set,一個叫collation。我們先說說character set。字符集就是數字,英文字符,漢字等編碼格式,我們常見的是utf8,gbk,gb2312。mysql里面比較復雜,有4個東西跟它有關,分別是character_set_client,character_set_connection,character_set_database,character_set_results。set names (latin1)其實就是character_set_client=latin1,character_set_connection=latin1,character_set_results=latin1,它的流程是character_set_client ==> character_set_connection ==> Table Character ==> character_set_results。 我們按照上面的流程,來分析第一個問題。 set names 'latin1'----執行了character_set_client=latin1,character_set_connection=latin1,character_set_results=latin1; insert into test_latin1 set name='王';這句話,mysql做了什么事呢?首先,character_set_client,它會把王字的編碼當成latin1的編碼傳遞給character_set_connection(此時不會轉碼),character_set_connection會把編碼傳遞給Table Character,因為表本身是latin1,所以此時也不需要轉碼,select name from test_latin1;mysql會把test_latin1中的編碼傳遞給前端,此時也不需要轉碼,所以,走個流程下來,我們輸入的是什么編碼,輸出的還是相同的編碼,因此,第一個問題的答案是不會是亂碼。我畫個流程圖latin1==>latin1==>latin1==>latin1,沒有轉碼的過程 我們在來看第二個問題。 set names 'test_gbk'----執行了character_set_client=gbk,character_set_connection=gbk,character_set_results=gbk; insert into test_latin1 set name='王';character_set_client,它會把王字的編碼當成gbk的編碼傳遞給character_set_connection(此時不會轉碼),character_set_connection會把編碼傳遞給Table Character,因為表是lanti1的編碼格式,這個過程的時候就會進行轉碼,但是latin1的字符集小于gbk的字符集,所以它會找不到對應字符的編碼,此時會以?代替。select name from test_latin1,此時會從latin1轉碼成gbk,但是此時latin1已經是錯誤的數據了,所以得到的gbk編碼也是錯誤的了。流程gbk==>gbk==>latin1==>gbk,其中gbk==>latin1出了問題,我們select出來的數據也就不可能是輸入時候的數據了。因此,這個問題的答案是亂碼。 第三個。 set names 'test_latin1' insert into test_utf8 set name='王';character_set_client,它會把王字的編碼當成latin1的編碼傳遞給character_set_connection(此時不會轉碼),character_set_connection會把編碼傳遞給Table Character,此時表是utf8的格式,因此會進行轉碼,latin1==>utf8,因為utf8的字符集>latin1字符集,因此,轉碼正常。select name from test_utf8;會從utf8轉碼成latin1,此時可以轉碼成功,因此我們最終得到的和輸入的時候是一致的,因此答案不是亂碼。流程latin1==>latin1==>utf8==>latin1,從小的字符集到大的字符集再到小的字符集,轉碼是不會有問題的。 屁話了這么多,無非想告訴大家一個萬精油方法,表創建的字符集和set names都設置成同一個字符集,就基本可以滿足輸入數據不會在轉換過程中失真,也就是說輸入是什么,輸出就是什么。建議有中文的都設置成utf8字符集,一勞永逸。
posted @
2012-11-26 19:56 梨樹陽光 閱讀(2566) |
評論 (2) |
編輯 收藏
這是Riot的Design Director Tom Cadwell專門為中國玩家寫的講解匹配系統工作原理的帖子。
同時為了讓大家更好的理解匹配系統,如果您覺得您遇到了特別不公平的匹配,請回復游戲開始時間和比賽結束截圖,我們會調查該局匹配是如何完成的,坑爹的玩家是為何加入到這一局的。
很多人抱怨看不懂,我來個精簡比喻版的:
有個籃球聯盟,有無數個球員和大概20個等級的聯賽。
所有球員都是10級聯賽的成員,他們自由組合互相比賽,贏的人,升級到11級聯賽,輸的人降到9級聯賽。
然后每個等級聯賽再次開賽,又有的人升級有的人降級,最終這20級的聯賽都有球員參加。
我們的大量的數據證明,一個球員的水平,會讓其穩定在大約3個聯賽之間,也就是科比是參加20級聯賽的,且當他和4個17級聯賽的人組隊,基本不會輸給17級聯賽的人。且,把科比降到10級聯賽,他會輕松的在20局之內回到20級。
理想情況下,球員都是在跟自己同樣經歷的球員玩,一個中等水平玩家完全不會匹配到科比,科比也不會匹配到剛玩游戲的玩家。
事實上匹配系統的分級會比這個更復雜更智能,采用的是國際象棋所采用的elo系統。
再增加個FAQ:
Q:系統為了保持勝率50%,是否會在我連勝后故意塞給我一些菜隊友讓我輸?
A:系統的目的不是為了保持你的勝率,而是讓水平差不多的玩家一起玩。當你和水平差不多的玩家一起玩時勝率會趨近50%,所以,系統是不會故意坑你的。
Q:我才100勝,為什么系統老匹配600勝的玩家給我?
A:勝場并不能反應一個人的水平。如果把匹配系統比作跑步,練習了3年才能跑進11秒的和第一次就跑進11秒的人我們是同等看待的。匹配系統基于水平而不是基于經驗。
Q:我勝率60%,為什么匹配40%勝率的隊友、60%勝率的對手給我?
A:勝率也不能反映水平。匹配系統不但要看你是否贏了,也要看你贏了誰。就像war3的sky在職業圈勝率其實并不高,但是虐一般的玩家勝率是100%。同樣水平的玩家,會因為隨機匹配到對手的關系,勝率會40%~60%不等。
Q:你說水平差不多,為什么我覺得他們這么菜?
A:匹配系統提供的是公平的機會,而未必是你理想的結果。我們能追求系統公正,但是無法預測玩家單局內的表現。
系統100%匹配曼聯對陣皇馬,但是不能保證某一次曼聯不會4:0碾壓皇馬,且在這局中,C羅表現yts,完全就在拖后腿。或者曼聯也可能連勝皇馬3次之類的。但是,系統只會把曼聯去匹配皇馬而不會出現曼聯對陣中超深圳隊。具體到某一局是皇馬贏還是曼聯贏取決于那一場的排兵布陣,臨場發揮,以及戰術意圖。
如果這個坑爹玩家真的不在你的水平等級,他就會一直坑隊友,一直輸,等級一直降低,這樣會讓他離開你的匹配范圍,讓他不再可以和你匹配到。根據我們的數據,玩家的elo基本是穩定在較小范圍內的。這也就是深圳隊和皇馬的差距,也是中國國家隊能贏法國隊,確永遠打不進世界杯的理由。
系統沒辦法給你完美隊友,玩家會因為很多原因發揮不好:使用不會的英雄、打了不想打的位置、玩法風格和隊友不夠搭配,前期不利想掛機等等。但是你和對方玩家遇到這種情況的概率是相同的,系統并不會偏袒任何一方。所以想要完美隊友,請和朋友組隊,不過那樣你也會碰見更厲害的對手。
如果大家在如何鑒定玩家水平上有好的想法歡迎提,但是如果想要通過抱怨玩家游戲內表現來證明匹配系統不公平,就是在和風車決斗了。每個人的看法都不一樣的,系統判斷他和你在遇到同樣的隊友和對手時候,勝率差不多,這也是我們目前能做到最好的了。
以下是文章的正文。
概述:
匹配系統的目的如下,優先級從高到低:
1、 保護新手不被有經驗的玩家虐;讓高手局中沒有新手。
2、 創造競技和公平的游戲對局,使玩家的游戲樂趣最大化。
3、 無需等待太久就能找到對手進入游戲。
匹配系統盡其所能的匹配水平接近的玩家,玩家的水平是來自他們在此之前贏了誰以及他們對手的水平。當你戰勝對手,系統會認為你更強,當你輸給對手,系統會認為你更弱。雖然這對于某一局游戲并不是那么的公平,但是長期來看,對于多局游戲是相當的公平:因為好的玩家總會對游戲結果造成正面的、積極的影響。我們使用了這樣一個方法測試:給水平高的玩家一個新帳號,然后看他們游戲數局后的結果。我們通過大量的測試來證明了我們的想法。
并且,匹配系統知道預先組隊的玩家有一些優勢,如果你是預先組隊,會給你一些更強的玩家。我們用一些非常巧妙的數學方法來解決預先組隊的玩家VS solo玩家的匹配公平問題。我甚至讓兩個數學博士來驗證,他們都說給力!
匹配是怎么完成的?
首先,系統將你放進適當的匹配池里——根據游戲模式(匹配模式、排位solo/雙人、排位5人、其他模式等等)
然后,系統會嘗試將匹配池里的人分到更細的匹配池里——5人組隊 VS 5人組隊,低等級新手 vs 其他一些低等級新手,如此這般。
當你在匹配池中,系統會開始嘗試找到合適的配對,目標是撮合一個雙方獲勝機會都為50%的游戲。
第1步:確定你的實力:
*如果你是solo,就直接使用你的個人匹配分(也就是elo值,匹配模式和排位賽有不同的匹配分)
*如果你是預先組隊的,你的匹配分是你隊伍的平均分,并且會根據你組隊的規模稍微提高一些,這樣才能保證你匹配到更強的對手來抵消你組隊的優勢。我和一個計算機生物學的博士(Computational Biology Ph.D)通過研究成百上千的游戲結果,計算出了預先組隊到底有多大的優勢。我們還在幕后做了一些其他調整,比如新手和高玩組隊,比如某地圖上藍隊和紫隊的玩家哪個更有優勢,諸如此類。
第2步:確定你合適的對手:
*首先,系統會基于你的elo值,給你匹配跟你非常相近的玩家。最終,系統會放寬匹配的條件,給你一些不是那么完美的匹配,因為你肯定也不想永遠匹配不到人。
*新手會得到一些特殊的保護,通常新手只會匹配到其他新手(在成熟的服務器里,這個比例達到了99%+。除非這個新手和一個高級玩家朋友預先組隊)
第3步:確定匹配:
*最終,系統會匹配10個大體上同水平、同等級的玩家,促成一個游戲。
*系統會嘗試平衡這個隊伍,盡量使雙方的獲勝機會都為50%。在絕大多數時間,誤差會在3%之內——類似50/50,49/51,48/52。實際上的獲勝機會會有一點點差別(會在Q&A里面回答這個問題),但是我們的研究標明,在絕大多數情況下,這實際上是一個非常精確的預測。
長期來講,我的匹配分(Elo值)是如何被測量的?
我們使用了一個修改過的ELO系統。ELO系統的基本要點通過使用數學比較兩個人的積分,來預測兩人的比賽結果——類似“A和B比賽數局,A會贏掉75%的局”。
然后,比賽結果出來了。如果你贏了,你會加分,如果你輸了,你會被扣分。如果你是“出人意料”的贏了(系統認為你輸的可能性更大),你會贏得更多的分數。額外的,如果你是一個新玩家,你會加分減分更快,以便于你可以快速的進入到你的水平等級。長期來看,這意味著好的玩家會得到高的匹配分,因為他們總是超過系統的預期,他們會不斷加分直到系統可以正確的預測他們的勝率。
我們修改這個系統給團隊比賽使用,基本概念是:基于該團隊的所有玩家,得到一個團隊ELO值。如果你的隊伍勝利,系統會假設該隊伍的所有玩家都要比系統猜測的“更強”,并且加分。雖然有一些問題,但是總體上來講是有效的,特別是玩家預先組隊的時候。
舉例,本人在北美的服務器上有2000的普通匹配模式elo。如果我建一個小號,就算沒有天賦和符文,我打到8級的時候就已經有1800elo了。這個系統并不完美,但是確實能夠讓玩家快速的接近自己水平所在的位置。
當你才開始玩的時候,我們也對ELO做一些微調,讓你更快的進入你水平所在的位置。
*我們有大量的,有優先級的方法來鑒定一個玩家,相比一個標準的新玩家是否更有技巧,更猛。如果發現是的,我們會在幕后提高他的elo一個檔次。
*我們同樣也會分辨真的菜鳥新手。
*提升等級也會極大的提高你的elo值。這個也將幫助系統將30級滿級的召喚師和低等級的召喚師區分開來
如果你想知道ELO系統的理論,以及更多細節,你可以看看這:
http://en.wikipedia.org/wiki/Elo_rating_system
http://zh.wikipedia.org/wiki/ELO
呃,等等,你是怎么處理組隊玩家 vs solo(單排)玩家的?
我們大多數情況下,會通過將5人組隊的隊伍匹配給另外一個5人組隊的隊伍來避免這種情況的發生(幾乎是所有情況下)。
對于“部分”組隊,我們進行了大量的研究,發現優勢并沒有想象的那么大,所以我們也會把他們混到solo(單排)的玩家里。我們發現有大量的因素會影響到組隊優勢的大小:從預先組隊的規模(比如2、3、4、5組隊),到組隊玩家的水平,到高玩帶菜鳥的組合,到玩家水平不同而導致的情況不同,以及其他的一些必須考慮到的微妙因素。這個要比一些我們曾見過的點對點算法-將任意的統計數據雜糅在一起猜測分數-要可靠的多
發現這些優勢,我們就知道對于預先組隊的隊伍,需要提高多少elo值,來達成一個公平的匹配,確定一個適當的,在數學上合理的調整。結果在有些情況下非常令人驚訝(同時會校正統計數據)。
雖然我們不會給出精確的數值,因為這是商業機密,但是我們可以告訴您:
*5人組隊只是比5個路人稍強。
*部分組隊只是比5個路人略強。
*菜鳥5人組隊并不會帶來太大的優勢,但是高玩組隊會有很大的優勢。
*團隊實力方差高的隊伍,會比方差低的隊伍更強。(方差簡單來說,是在平均值相同的情況下反應各個元素的大小差異,方差大表示差異大,高方差的隊伍類似高玩帶低玩,低方差的隊伍各個隊員實力接近。)
*這說明了大體上,高水平玩家的Carry作用(可以理解為帶領或者大腿),比低水平玩家的送人頭作用(feeder)要強力。
好吧…那為什么要把預先組隊的玩家和非組隊玩家匹配到一起?
這是一些原因:
*這會幫助系統更快的找到適合你的匹配分,讓系統更快的給你公平的匹配。這個的工作原理是,如果你組隊,會減低運氣所帶來的成分,如果你單排,你的隊友的好壞將對你輸贏的影響更大。如果你預先組隊,你會和你水平差不多的玩家組成隊伍,你隨機遇到猛男/坑爹隊友幾率會更小。因為游戲的結果更多來自你和水平相近的朋友的表現,而不是隨機因素,所以你的匹配分會更快的到達精確的值。
*我們希望玩家可以和自己的朋友一起玩,因為這樣會讓他們玩的更有樂趣。你也不可能為5v5的游戲設置單獨的2人匹配池或者3人匹配池,你需要組合他們來讓系統工作。我們選擇包含5人組隊,因為這非常有樂趣。如果我們以后有足夠大的匹配池,我們可能會將5人組隊和部分組隊區分開來,但是數據告訴我們,這基本不會提升匹配的公平程度,兩者的效果基本相同。
其他一些常見的問題:
Q:為什么不加入一些其他的細節,類似擊殺數等等來確定我的匹配分?
A:因為這是有偏差的,并且因為非常難以給擊殺數這個數值來評分,你使用一個gank英雄的時候(類似老鼠和易大師),要殺多少人才能算是好的呢?而且這會讓好的輔助玩家非常吃虧,因為他們的目的就不是拿人頭,甚至會為了自己的Carry擋死。最后,玩家會為了刷數據,故意拖長游戲時間,然后拿大量farm對方的人頭,而不是為了贏得比賽。我們盡量把測量玩家水平和激勵玩家的機制放到努力取勝上面,我們避免了一些不必要的周邊行為,而這些行為既沒樂趣,還會擾亂匹配系統。
Q:我非常憤怒,因為匹配系統老給我坑爹隊友(feeders,送人頭的)。為什么不阻止這種情況發生?
A:我們的確有試圖阻止這種情況發生,但是如果你被匹配到一個明顯很弱的玩家,這也說明匹配系統同時匹配給你了一個或者多個強力的玩家。根據我們的研究,我們發現Carry(大腿)對隊伍的帶領作用要比feeder(送人頭,坑爹)的坑爹作用更強。原因是在LOL里,多次擊殺同一個玩家的收益是會遞減的,并不像其他的同類游戲。我們的分析標明,在平均elo相同的情況下,提高或者降低這個隊伍的某個玩家的elo值100(其他玩家相應降低/提高以保持平均分相同),整個隊伍的實力會提高約7點elo值。這也表明,LOL中Carry的作用要比feeder的作用更給力一些。確實,有時候你會因為匹配到feeder而輸掉這一局比賽,但是那是因為你們隊的Carry不夠給力。
Q:這樣的話,如果我連勝了數盤,我是不是會被匹配到一些完全不可戰勝的對手?
A:不全是。連勝導致你的匹配分會提高,你會不斷遇到更強的對手——但是我們并不是故意的讓你的勝率保持在50%的,我們的目的只是為了系統能夠正確的預測游戲結果。最終,你會達到你的極限,你將會大致保持50%的勝率。比平均水平高的玩家,往往勝率會比50%略高,因為比他們弱的玩家更多,比他們強的玩家更少。所以匹配時,往往會略微“向下匹配”。對于排位頂尖的高端玩家,他們經常會有90%的勝率。
Q:你們會如何設計固定的隊伍?類似WOW的競技場隊伍?
A:這是一個非常好的想法,并且讓我們有機會設計出更好的匹配系統。我們遲早會做這個,并且使用我們開發的新方法。我們需要檢驗并且搞清楚你大體上有多強力(例如你的個人積分),同時允許你創建/解散隊伍。這是個非常大的工程,但是我們對此非常有激情~
Q:如果匹配系統真的那么公平,那為何我老遇見那種一邊倒的比賽?
A:有兩個原因。第一,LOL有時候“雪球效應”會非常明顯。前期太差的表現會導致游戲讓人感覺非常一邊倒。特別是某些隊伍,如果他們開始很順風,就會一直很順風。我們遇到過同樣的隊伍,第一局25-5取勝,第2局確以類似的比分輸掉。第二個原因是,玩家發揮的并不好,隊伍選取陣容也不好。要進行一局勢均力敵的比賽,你需要平衡玩家水平和平衡陣容的選取。有時候玩家選了一個比較渣的陣容,比如5個近戰dps,或者3坦克2法師之類的,或者沒選打野英雄而對面有。這樣的話,盡管你的隊伍實力也很不錯,但是情況往往慘不忍睹。
Q:為什么我作為一個高等級玩家,有時候會匹配到一些低等級玩家?他們看上去都是來送人頭的。
A:當一個高等級玩家和一個低等級玩家組隊,這是一個非常令人頭疼的問題。我們希望玩家可以和自己的朋友一起玩,并且希望這是一種愉快的體驗。但是我們并不希望將一部分人的快樂建立在另一部分人的痛苦之上,所以我們往往將這種組合評分更高,保護新玩家不會被高等級玩家虐待。非常不幸的是,不管我們怎么做,我們把這樣的組合匹配到任何的游戲中,都有可能造成不愉快的體驗。因此,我們計劃將實施一個“不平衡組隊”的隊列,類似我們盡量將5人組隊匹配給5人組隊。
Q:我20級了,然后我被匹配到了一些10級的和一些29級的,怎么回事?
A:當不同等級的玩家組隊,我們會使用他們的平均等級來作為匹配的參考。等級并不是匹配系統的主導參數——匹配系統通常是使用實力來匹配——但是我們也會盡量將等級相近的玩家匹配到一起。在預先組隊的情況下,我們沒法替玩家選擇,所以我們盡我們所能,使用平均等級。我們會在這個計算系統里把30級的玩家看作36級,所以我們通常能讓中等級玩家的游戲沒有30級玩家,然而有時候呢,29級玩家能插進來。
posted @
2012-11-09 14:20 梨樹陽光 閱讀(1636) |
評論 (1) |
編輯 收藏
記錄下這個小問題。root下可以顯示路徑但是切換到其他用戶時沒有路徑顯示,很不方便。在/etc/profile中加入export PS1='\u@\h:\w>',其中\u顯示當前用戶賬號,\h顯示當前主機名,\W顯示當前路徑。然后source一下就搞定了
posted @
2012-11-08 11:49 梨樹陽光 閱讀(1406) |
評論 (0) |
編輯 收藏
開門見山,我先提出幾個問題,大家可以先想想,然后我再說出我的方法
1.如何判斷一個數M是否為2的N次方?
2.一個數N,如何得到一個數是M,M是不小于N的最小2的K次方
先說第一個問題,我有兩個思路
第一,可以通過判斷M的二進制中1的個數。而判斷M中1的個數可以通過下面方法獲得
int GetOneCnt(int m)
{
if ( m == 0 )
return 0;
int cnt = 1;
while(m & (m-1))
{
cnt++;
m--;
}
return cnt;
}
很明顯M中1的個數為1和M是2的N次方互為沖要條件
第二個思路,我們可以這樣,還是利用M的二進制表示,從最高位開始,以變量high_pos表示第一個1的下標,接著從最低位開始,變量low_pos表示第一個1的下標,如果high_pos=low_pos,則M為2的N次方
int HighestBitSet(int input)
{
register int result;
if (input == 0)
{
return -1;
}
#ifdef WIN32
_asm bsr eax, input
_asm mov result, eax
#else
asm("bsr %1, %%eax;"
"movl %%eax, %0"
:"=r"(result)
:"r"(input)
:"%eax");
#endif
return result;
}
int LowestBitSet(int input)
{
register int result;
if (input == 0)
{
return -1;
}
#ifdef WIN32
_asm bsf eax, input
_asm mov result, eax
#else
asm("bsf %1, %%eax;"
"movl %%eax, %0"
:"=r"(result)
:"r"(input)
:"%eax");
#endif
return result;
}
再說第二個問題
其實有了第一個問題的思路,這個問題就更好解決了,先判斷一個數是否為2^N,如果是,直接返回,否則返回2^(N+1)
代碼如下
int CeilingPowerOfTwo(int iInput)
{
if (iInput <= 1)
return 1;
int32_t highestBit = HighestBitSet(iInput);
int32_t mask = iInput & ((1 << highestBit) - 1); // 相當于input對2^highestBit求余
highestBit += ( mask > 0 );
return (1<<highestBit);
}
posted @
2012-10-01 15:53 梨樹陽光 閱讀(1404) |
評論 (4) |
編輯 收藏
如果你對能很快回答出unicode和utf-8的關系,你可以直接跳過這篇文章。下面我來說說兩者的關系和轉換。(本文使用符號2字代表所有的漢字,英文,數字等)
首先明確一點,UTF-8是UNICODE一種實現方式。
UNICODE:代表一種符號集合,它規定了一種符合的二進制表示,沒有指明存儲方式。(
http://www.unicode.org/)
UTF-8:實現了UNICODE,使用多字節的存儲方式。
我們先來考慮幾個問題。
第一,如果使用單字節表示符號,很明顯,完全不夠用
第二,如果使用多字節表示符號,那么,機器在讀取的時候,它怎么知道3個字節表示一個符號,還是表示3個符號
第三,如果使用2個字節表示一個符號,首先,最多能表示65535個字符還是會不夠用,就算夠用,比如ASCII碼這類僅需1個字節就可以表示的符號,用2個字節表示,浪費空間了。
因此,UTF-8孕育而生。
首先UTF-8使用變長表示符號,簡單的說,有的時候用1個字節表示符號,有的時候用2個字節表示符號,這樣解決了浪費空間的問題。那么,如何解決第二個問題的呢,我們得了解下UFT-8的編碼規則。
1.對于單字節的符號,字節第一個為0,后面7為為這個符號的unicode碼
2.對于N字節的符號(N>1),第一個字節前N位為1,第N+1位為0,后面字節的前兩位設為10,剩下可編碼的位,為該符號的UNICODE編碼。
這里我從網上找了一副圖
Unicode符號范圍 | UTF-8編碼方式 (十六進制) | (二進制)0000 0000-0000 007F | 0xxxxxxx0000 0080-0000 07FF | 110xxxxx 10xxxxxx0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面我具體解釋下這幅圖。
首先看第一行,它的意思是00000000到0000007F的UNICODE編碼,對應的UTF-8的編碼方式為0XXXXXXX(X表示可編碼位,不足的補0)。
第二行表示00000080到000007FF的UNICODE編碼,對應的UTF-8的編碼方式為110XXXXX 10XXXXXX。以此類推
那么,問題是,這個范圍是怎么定的?
很簡單,我們還是從第一行說起。007F,實際有效位只有7位,所以,0xxxxxxx就足矣。但是0800開始,有效位至少為8位,我們得增加一個字節,按照UTF-8的規定,2字節的表示方式為110XXXXX 10XXXXXX,我們的編碼位為11位(X的個數),所以,我們最多可以表示UNICODE編碼位11位的字符,也就是07FF。07FF過了就是0800,有效位至少為12位,我們得用3字節來表示,按照UTF-8的規定,1110XXXX 10XXXXXX 10XXXXXX,最大編碼位為16位,也就是FFFF,最后一行我就不再解釋了。
通過上面這個過程我們了解了,UNICODE轉UTF-8的過程,當然,逆過來就是UTF-8轉換成UNICODE。
我們通過一個例子來演示上面的過程。漢字“楊”,UNICODE的編碼位0x6768,二進制形式為0110011101101000,根據上面的圖,我們知道它屬于第三行,因此,它應該放入1110XXXX 10XXXXXX 10XXXXXX的模板中,結果是11100110 10011101 10101000,十六進制表示為E69DA8。
另外設計編碼問題,我們繞不開另一個問題,就是大端小端的問題,不過這個問題,網上資料很多,也很好實踐,這里我就不多啰嗦了。
posted @
2012-09-23 22:56 梨樹陽光 閱讀(1815) |
評論 (1) |
編輯 收藏
進程間通信方式包括了管道,消息隊列,FIFO,共享內存,而共享內存是其中效率最高的。下圖解釋了其效率最高的原因(圖片截取自《UNIX網絡編程》)
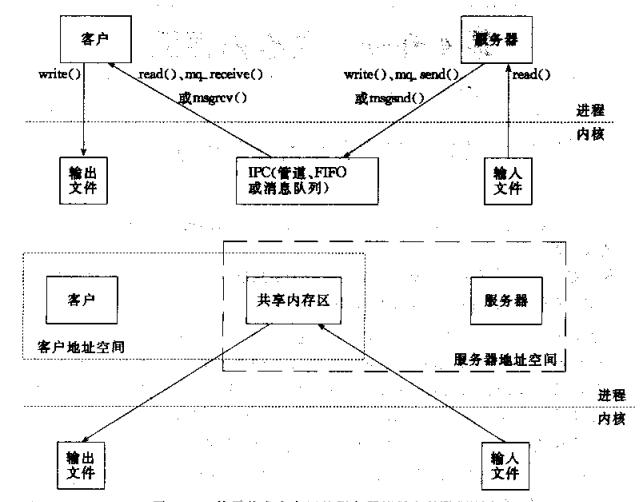
我們可以看到上面的拷貝次數是4次,下面則是2次。
接下來我們看看使用,其實網上和書上都有了很多資料,API就是那么幾個。
int shmget(key_t key,size_t size,int shmflag)。
key:可以指定IPC_PRIVATE,那么系統會為你創建一個key,并且返回一個id號。也可以通過ftok函數生成一個key(不了解ftok的童鞋可以動手man一下)。那么為什么要一個IPC既要一個key又有一個ID呢。這里我覺得是為了方便其他進程訪問。進程A創建了一個共享內存,內核為其分配一個ID,這個時候進程B想要訪問,他怎么獲取這個ID(難道需要A把ID發送給B??)。但是我們用一個key就很方便了。事先A,B進程都知道這個key,那么A創建了,B就可以通過事先知道key找到這塊內存。
size:共享內存的大小。如果是獲得一塊內存,則該值應該為0。
shmflag:讀寫權限的組合,可以與IPC_CREAT和IPC_EXCL按位或。當指定一個key時,IPC_CREAT和IPC_EXCL配合使用可以在存在該key的共享內存時返回-1。
當該函數調用成功后,返回一個系統分配的共享內存,并且size大小的字節被初始化為0
void *shmat(int shmid, const void *shmaddr, int shmflg)
有了一塊共享內存后,進程需要映射該內存到進程的地址空間。這個函數就是作用。
shmid就是之前獲得ID,shmaddr如果指定了,就會配合shmflg確定映射地址,不過一般都不這么干的。返回值就是獲得的地址,你可以往里面寫你或者讀你需要的數據了。同時調用了該函數,系統會修改shmid_ds數據。
int shmdt(const void *shmaddr)
解除綁定關系,參數就是我們之前獲取的那個返回地址。(其實我覺得這里參數如果為ID貌似更統一些吧)
int shmctl(int shmid, int cmd, struct shmid_ds *buf)
這個函數主要做一些修改和查詢。比如設置鎖,解鎖,移除一塊共享內存。
簡單介紹了API,還要說一下一些注意的東西
1.共享內存不會把數據寫入磁盤文件中,這個區別于mmap
2.即使沒有進程綁定在共享內存,共享內存也不會消失的。必須通過shmctl或者ipcrm刪除(或者更暴力的方式關掉電腦)
另外我們可能會考慮,系統最多創建多少個共享內存,一個進程最多可以綁定多少個內存,一個共享內存創建的size最大最小值是多少。其實這些設置在/proc/sys/kernel下面,我們也可以自己寫程序來讀取。貼一段代碼用來獲取上面的信息
#define MAX_SHMIDS 8196
int main(int argc,char *argv[])
{
int i,j;
int shmid[MAX_SHMIDS] = {0};
void *addr[MAX_SHMIDS] = {0};
//測試可以創建多少個共享內存
for ( i = 0;i < MAX_SHMIDS;++i )
{
shmid[i] = shmget(IPC_PRIVATE,1024,0666|IPC_CREAT);
if ( shmid[i] == -1 )
{
printf("create shared memory failed,max create num[%d],%s\r\n",i,strerror(errno));
break;
}
}
for ( int j = 0;j < i;++j )
{
shmctl(shmid[j],IPC_RMID,NULL);
}
//測試每個進程可以attach的最大數
for ( i = 0;i < MAX_SHMIDS;++i )
{
shmid[i] = shmget(IPC_PRIVATE,1024,0666|IPC_CREAT);
if ( shmid[i] != -1 )
{
addr[i] = shmat(shmid[i],0,0);
if ( addr[i] == (void *)-1 )
{
printf("process attach shared memory failed,max num[%d],%s\r\n",i,strerror(errno));
shmctl(shmid[i],IPC_RMID,NULL);
break;
}
}
else
{
printf("max num of process attach shared memory is[%d]\r\n",i-1);
break;
}
}
for ( j = 0;j < i;++j )
{
shmdt(addr[j]);
shmctl(shmid[j],IPC_RMID,NULL);
}
//測試一個共享內存創建最小的size
size_t size = 0;
for ( ;;size++ )
{
shmid[0] = shmget(IPC_PRIVATE,size,0666|IPC_CREAT);
if ( shmid[0] != -1 )
{
printf("create shared memory succeed,min size[%d]\r\n",size);
shmctl(shmid[0],IPC_RMID,NULL);
break;
}
}
//測試共享內存創建最大的size
for ( size = 65536;;size += 1024 )
{
shmid[0] = shmget(IPC_PRIVATE,size,0666|IPC_CREAT);
if ( shmid[0] == -1 )
{
printf("create shared memory failed,max size[%ld],%s\r\n",size,strerror(errno));
break;
}
shmctl(shmid[0],IPC_RMID,NULL);
}
exit(0);
}
好了,下篇開始介紹如何控制讀寫。
posted @
2012-09-06 19:26 梨樹陽光 閱讀(2256) |
評論 (0) |
編輯 收藏
1.拷貝構造函數的形式
對于類X,如果它的函數形式如下
a) X&
b) const X&
c) volatile X&
d) const volatile X&
且沒有其他參數或其他參數都有默認值,那么這個函數是拷貝構造函數
X::X(const X&);是拷貝構造函數
X::X(const X&,int val = 10);是拷貝構造函數
2.一個類中可以存在超過一個拷貝構造函數
class X {
public:
X(const X&);
X(X&); // OK
};
編譯器根據實際情況調用const拷貝構造函數或非const的拷貝構造函數
3.默認的拷貝構造函數行為
a)先調用父類的拷貝構造函數
b)如果數據成員為一個類的實例,則調用該類的拷貝構造函數
c)其他成員按位拷貝
4.默認的賦值構造函數行為
a)先調用父類的賦值構造函數
b)如果數據成員為一個類的實例,則調用該類的賦值構造函數
c)其他成員按位拷貝
5.提供顯示的拷貝和賦值構造函數
基本的原則是子類一定要調用父類的相應函數,參考方式
Derive(const Derive& obj):Base(obj)
{
…...
}
Derive& operator =(const Derive &obj)
{
if ( this == &obj )
return *this;
//方式一
Base::operator =(obj);
//方式二
static_cast<Base&>(*this) = obj;
return *this;
}
另外當你的成員變量有const或者引用,系統無法為你提供默認的拷貝和賦值構造函數,我們必須自己處理這些特殊的情況
posted @
2012-08-31 17:13 梨樹陽光 閱讀(1743) |
評論 (0) |
編輯 收藏
我們在類里面會定義成員函數,同時我們也希望定義成員函數指針。因此需要解決3個問題,第一怎么定義類的函數指針,第二賦值,第三使用。
我定義一個類,
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
};
int A::add(int a,int b)
{
return a + b;
}
int A::mul(int a,int b)
{
return a * b;
}
int A::div(int a,int b)
{
return (b !=0 ? a/b : a);
}
我現在想要定義一個指針,指向A類型中返回值為int,參數為兩個int的函數指針。熟悉C的同學馬上會寫出typedef int (*oper)(int,int)。但是這個用到C++里就有問題了,
因為我們知道,類的非static成員方法實際上還有this指針的參數。比如add方法,它實際的定義可能會這樣int add(A* this,int a,int b);因此,我們不能簡單把C語言里的那套東西搬過來,我們需要重新定義這種類型的指針。正確做法是加上類型,typedef int (A::*Action)(int,int)
typedef int (A::* Action)(int,int);
int main()
{
A a;
Action p = &A::add;
cout << (a.*p)(1,2) << endl;
return 0;
}
Action p = &A::add;這個就是賦值語句
調用的時候注意,直接這樣(*p)(1,2)是不行的,它必須綁定到一個對象上(a.*p)(1,2);我們也可以把類的函數指針定義在類的聲明里。
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
int (A::*oper)(int,int);
};
上面這種方式是針對非static成員函數的,那么static成員函數的函數指針應該怎么定義呢,還能用上面這種方式嗎?我們知道static成員函數是沒有this指針的,所以不會加上的類的限定,它的函數指針定義方式和C里面的函數指針定義方式一樣的。
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
static int sub(int,int);
};
int A::sub(int a,int b)
{
return a - b;
}
int main()
{
int (*pp)(int,int) = &A::sub;
cout << (*pp)(10,5) << endl;
return 0;
}
總結起來,非static成員函數的函數指針需要加上類名,而static的成員函數的函數指針和普通的函數指針一樣,沒有什么區別。
另外注意一點的是
如果函數指針定義在類中,調用的時候有點區別。
class A
{
public:
int add(int,int);
int mul(int,int);
int div(int,int);
int (A::*pfunc)(int,int);
};
int main()
{
A a;
a.pfunc = &A::add;
cout << (a.*(a.pfunc))(1,2) << endl;
return 0;
}
posted @
2012-08-14 17:17 梨樹陽光 閱讀(1428) |
評論 (0) |
編輯 收藏