初探C++ Builder 2009的UnicodeString
作者:Tuuzed(土仔) 發表于:2009年6月25日23:39:34
版權聲明:可以任意轉載,轉載時請務必以超鏈接形式標明文章原始出處和作者信息及本聲明。
http://www.shnenglu.com/tuuzed/archive/2009/06/26/88538.html
下面兩個問題一直困擾著我這個處于第1層的菜鳥:1、為什么卡巴斯基KIS2009簡體中文版安裝在繁體XP下能正常顯示簡體中文,而瑞星、金山等則是亂碼?2、為什么簡體的MS Word或Firefox能顯示繁體中文(特指Big5編碼)的內容?處于1層以上的程序員(見《程序員》6月雜志周偉明的《程序員的十層樓》)肯定已經笑出來了,請略過剩下的內容。。。
這么說吧,如果想實現一個可以在簡體中文系統中顯示繁體中文的“記事本”,C++ Builder2009中如何實現?很多人(包括我)在沒有了解各種字符編碼以前,想當然地覺得既然支持Unicode了,那么直接使用TMemo的LoadFromFile方法直接load一個繁體中文的文檔就能顯示了。因為支持Unicode了嘛,Unicode就是在任何系統都能顯示正常。好像很對,先試一下,初探嘛。
一、不變的“簡體中文”版
既然支持Unicode,搞一個Form,放一個Button在上面,
Caption先不要去動,用程序去修改:
Form1->Caption = "簡體中文";
Button1->Caption = "漢字";
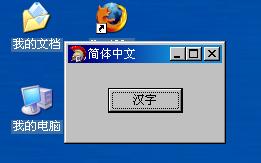
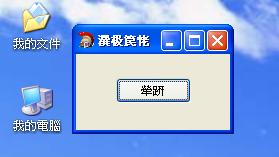
簡體XP下顯示正常,可繁體XP下就顯示亂碼了。不是說支持Unicode了嗎?跟蹤調試一下:
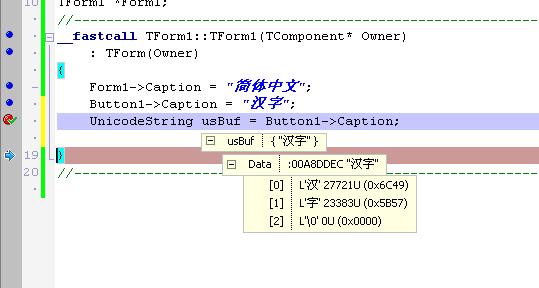
簡體XP下,“漢字”的“漢”編碼是0x6C49,而繁體XP下,“漢”的編碼變成了0x7296。我們知道“漢”在Uunicode編碼中是0x6C49,說明簡體XP下是正確的,而繁體XP下就不正確了。為什么會有這樣的情況發生?把斷點設置在“Button1->Caption = "漢字";”這一句,再用F7一直跟蹤。原來是CB2009在把“漢字”賦值給Button1->Caption前,先進行了Ansi到Unicode的轉換,恰恰問題就在CB2009使用的這個函數:InternalUStrFromPCharLen(Dest, Source, Length, DefaultSystemCodePage);函數在實現過程中獲取了系統默認的CodePage(http://www.shnenglu.com/shenhuafeng/archive/2007/04/05/21336.html),而簡體XP和繁體XP的CodePage不一樣(一個為936,一個為950)導致在轉換到UNICODE的時候結果不一致,也就導致到繁體XP下顯示為亂碼。如何解決呢?在CB2009的幫助“Unicode in RAD Studio”一章中的“Issues(問題)”節中提到:運用“U”這個標量(一個宏,與VC++中的“L”類似)將ANSI字符常量強制識別為Unicode。這個過程是在編譯時就已經完成,編譯的時候是在簡體XP下,所以程序運行時內存中存儲的“漢字”Unicode是正確的。為了證實,將代碼變為Button1->Caption = U"漢字";,再用F7跟蹤。結果是程序一運行到這,就馬上用UnicodeSetLength(var dst: UnicodeString; len: Integer);(注意dst的數據類型)來初始化一個UnicodeString類,等著給TButton賦值(TControl.SetText)了。

現在終于明白,不變的“簡體中文”其實是不變的Unicode編碼,已經不是我們的GB了。那么CB2009中的UnicodeString默認的CodePage是啥?調用UnicodeString.CodePage()就知道了——1200。
二、正確顯示“繁體中文”
簡體XP下顯示繁體好像都很容易:用IE、Firefox瀏覽繁體網站,用MS Word打開繁體內容doc文檔等。如何用CB2009也實現相應功能?先試試用Memo控件來Load一個繁體文本看看:
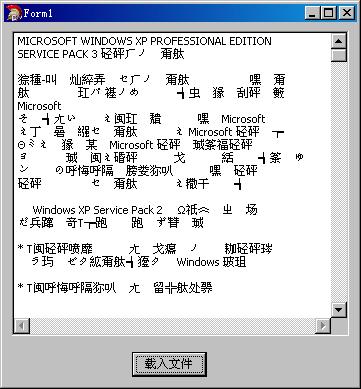
結果肯定是亂碼,繁體XP下運行這個程序是能正常顯示的。Memo控件中的每一行其實都是UnicodeString(屬性Lines是TStrings類的對象),而繁體內容的TXT文本按ANSI保存,在Memo載入文件的時候做了一個ANSI到Unicode的轉換。有了之前的跟蹤結果,可以想象CB2009是獲取了系統的默認CodePage(936)而導致繁體不能正確轉換為UTF-16。那么我們讓CB2009重新進行CodePage950的轉換就應該可以正確顯示了。
有個函數在前面跟蹤源碼的時候出現過——MultiByteToWideChar,看名字很容易理解它的作用是把多字節轉為寬字符,CB2009應該是利用了這個函數將ANSI進行了轉換,當然CB2009是用的簡體系統默認的CodePage。轉換應該可逆,那么應該有WideCharToMultiByte。實現它看看:
1 UnicodeString __fastcall BIG5ToUnicode(UnicodeString usString)
2 {
3 if (GetOEMCP() == 950)
4 {
5 //如果為繁體系統,不用轉換
6 return usString;
7 }
8 //預分配空間
9 int length = usString.Length() * 2;
10 char *chBuffer = new char[length+1];
11 //按系統默認的codepage轉回去
12 int iReturn = WideCharToMultiByte(GetOEMCP(), 0, usString.w_str(), -1, chBuffer, length+1, NULL, NULL);
13 wchar_t *wcBuffer = new wchar_t[iReturn+1];
14 //按Big5編碼轉換回來
15 iReturn = MultiByteToWideChar(950, 0, chBuffer, -1, wcBuffer, iReturn+1 );
16 usString = UnicodeString(wcBuffer);
17 delete chBuffer;
18 delete wcBuffer;
19 return usString;
20 }
“載入文件”的Click事件實現如下:
1 void __fastcall TForm1::btn1Click(TObject *Sender)
2 {
3 TStringList *slBuf = new TStringList();
4 slBuf->LoadFromFile("d:\\eula.txt");
5 int iCount = slBuf->Count;
6 for (int i = 0; i < iCount; i++)
7 {
8 mmo1->Lines->Add(BIG5ToUnicode(slBuf->Strings[i]));
9 Application->ProcessMessages();
10 }
11 }
運行一下看看:
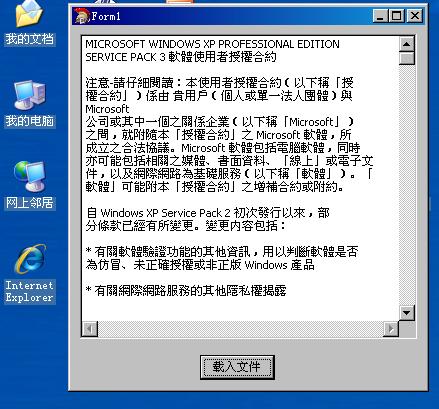
好像自己的兩個問題有了答案,但是總覺得第二個問題的方法效率低下,畢竟又轉了一道。肯定還有更好的方法,當然,在沒有找到好的辦法前,我們這些菜鳥用用這種方法也是可以的。畢竟成長的過程是痛苦的。