轉自:http://blog.csdn.net/yangliuy/article/details/7316496
SVM入門(一)至(三)Refresh
按:之前的文章重新匯編一下,修改了一些錯誤和不當的說法,一起復習,然后繼續SVM之旅.
(一)SVM的簡介
支持向量機(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解決小樣本、非線性及高維模式識別中表現出許多特有的優勢,并能夠推廣應用到函數擬合等其他機器學習問題中[10]。
支持向量機方法是建立在統計學習理論的VC 維理論和結構風險最小原理基礎上的,根據有限的樣本信息在模型的復雜性(即對特定訓練樣本的學習精度,Accuracy)和學習能力(即無錯誤地識別任意樣本的能力)之間尋求最佳折衷,以期獲得最好的推廣能力[14](或稱泛化能力)。
以上是經常被有關SVM 的學術文獻引用的介紹,我來逐一分解并解釋一下。
Vapnik是統計機器學習的大牛,這想必都不用說,他出版的《Statistical Learning Theory》是一本完整闡述統計機器學習思想的名著。在該書中詳細的論證了統計機器學習之所以區別于傳統機器學習的本質,就在于統計機器學習能夠精確的給出學習效果,能夠解答需要的樣本數等等一系列問題。與統計機器學習的精密思維相比,傳統的機器學習基本上屬于摸著石頭過河,用傳統的機器學習方法構造分類系統完全成了一種技巧,一個人做的結果可能很好,另一個人差不多的方法做出來卻很差,缺乏指導和原則。
所謂VC維是對函數類的一種度量,可以簡單的理解為問題的復雜程度,VC維越高,一個問題就越復雜。正是因為SVM關注的是VC維,后面我們可以看到,SVM解決問題的時候,和樣本的維數是無關的(甚至樣本是上萬維的都可以,這使得SVM很適合用來解決文本分類的問題,當然,有這樣的能力也因為引入了核函數)。
結構風險最小聽上去文縐縐,其實說的也無非是下面這回事。
機器學習本質上就是一種對問題真實模型的逼近(我們選擇一個我們認為比較好的近似模型,這個近似模型就叫做一個假設),但毫無疑問,真實模型一定是不知道的(如果知道了,我們干嗎還要機器學習?直接用真實模型解決問題不就可以了?對吧,哈哈)既然真實模型不知道,那么我們選擇的假設與問題真實解之間究竟有多大差距,我們就沒法得知。比如說我們認為宇宙誕生于150億年前的一場大爆炸,這個假設能夠描述很多我們觀察到的現象,但它與真實的宇宙模型之間還相差多少?誰也說不清,因為我們壓根就不知道真實的宇宙模型到底是什么。
這個與問題真實解之間的誤差,就叫做風險(更嚴格的說,誤差的累積叫做風險)。我們選擇了一個假設之后(更直觀點說,我們得到了一個分類器以后),真實誤差無從得知,但我們可以用某些可以掌握的量來逼近它。最直觀的想法就是使用分類器在樣本數據上的分類的結果與真實結果(因為樣本是已經標注過的數據,是準確的數據)之間的差值來表示。這個差值叫做經驗風險Remp(w)。以前的機器學習方法都把經驗風險最小化作為努力的目標,但后來發現很多分類函數能夠在樣本集上輕易達到100%的正確率,在真實分類時卻一塌糊涂(即所謂的推廣能力差,或泛化能力差)。此時的情況便是選擇了一個足夠復雜的分類函數(它的VC維很高),能夠精確的記住每一個樣本,但對樣本之外的數據一律分類錯誤。回頭看看經驗風險最小化原則我們就會發現,此原則適用的大前提是經驗風險要確實能夠逼近真實風險才行(行話叫一致),但實際上能逼近么?答案是不能,因為樣本數相對于現實世界要分類的文本數來說簡直九牛一毛,經驗風險最小化原則只在這占很小比例的樣本上做到沒有誤差,當然不能保證在更大比例的真實文本上也沒有誤差。
統計學習因此而引入了泛化誤差界的概念,就是指真實風險應該由兩部分內容刻畫,一是經驗風險,代表了分類器在給定樣本上的誤差;二是置信風險,代表了我們在多大程度上可以信任分類器在未知文本上分類的結果。很顯然,第二部分是沒有辦法精確計算的,因此只能給出一個估計的區間,也使得整個誤差只能計算上界,而無法計算準確的值(所以叫做泛化誤差界,而不叫泛化誤差)。
置信風險與兩個量有關,一是樣本數量,顯然給定的樣本數量越大,我們的學習結果越有可能正確,此時置信風險越小;二是分類函數的VC維,顯然VC維越大,推廣能力越差,置信風險會變大。
泛化誤差界的公式為:
R(w)≤Remp(w)+Ф(n/h)
公式中R(w)就是真實風險,Remp(w)就是經驗風險,Ф(n/h)就是置信風險。統計學習的目標從經驗風險最小化變為了尋求經驗風險與置信風險的和最小,即結構風險最小。
SVM正是這樣一種努力最小化結構風險的算法。
SVM其他的特點就比較容易理解了。
小樣本,并不是說樣本的絕對數量少(實際上,對任何算法來說,更多的樣本幾乎總是能帶來更好的效果),而是說與問題的復雜度比起來,SVM算法要求的樣本數是相對比較少的。
非線性,是指SVM擅長應付樣本數據線性不可分的情況,主要通過松弛變量(也有人叫懲罰變量)和核函數技術來實現,這一部分是SVM的精髓,以后會詳細討論。多說一句,關于文本分類這個問題究竟是不是線性可分的,尚沒有定論,因此不能簡單的認為它是線性可分的而作簡化處理,在水落石出之前,只好先當它是線性不可分的(反正線性可分也不過是線性不可分的一種特例而已,我們向來不怕方法過于通用)。
高維模式識別是指樣本維數很高,例如文本的向量表示,如果沒有經過另一系列文章(《文本分類入門》)中提到過的降維處理,出現幾萬維的情況很正常,其他算法基本就沒有能力應付了,SVM卻可以,主要是因為SVM 產生的分類器很簡潔,用到的樣本信息很少(僅僅用到那些稱之為“支持向量”的樣本,此為后話),使得即使樣本維數很高,也不會給存儲和計算帶來大麻煩(相對照而言,kNN算法在分類時就要用到所有樣本,樣本數巨大,每個樣本維數再一高,這日子就沒法過了……)。
下一節開始正式討論SVM。別嫌我說得太詳細哦。
SVM入門(二)線性分類器Part 1
線性分類器(一定意義上,也可以叫做感知機) 是最簡單也很有效的分類器形式.在一個線性分類器中,可以看到SVM形成的思路,并接觸很多SVM的核心概念.
用一個二維空間里僅有兩類樣本的分類問題來舉個小例子。如圖所示

C1和C2是要區分的兩個類別,在二維平面中它們的樣本如上圖所示。中間的直線就是一個分類函數,它可以將兩類樣本完全分開。一般的,如果一個線性函數能夠將樣本完全正確的分開,就稱這些數據是線性可分的,否則稱為非線性可分的。
什么叫線性函數呢?在一維空間里就是一個點,在二維空間里就是一條直線,三維空間里就是一個平面,可以如此想象下去,如果不關注空間的維數,這種線性函數還有一個統一的名稱——超平面(Hyper Plane)!
實際上,一個線性函數是一個實值函數(即函數的值是連續的實數),而我們的分類問題(例如這里的二元分類問題——回答一個樣本屬于還是不屬于一個類別的問題)需要離散的輸出值,例如用1表示某個樣本屬于類別C1,而用0表示不屬于(不屬于C1也就意味著屬于C2),這時候只需要簡單的在實值函數的基礎上附加一個閾值即可,通過分類函數執行時得到的值大于還是小于這個閾值來確定類別歸屬。 例如我們有一個線性函數
g(x)=wx+b
【看到好多人都在問g(x)=0 和 g(x)的問題,我在這里幫樓主補充一下:g(x)實際是以w為法向量的一簇超平面,在二維空間表示為一簇直線(就是一簇平行線,他們的法向量都是w),而g(x)=0只是這么多平行線中的一條。】
我們可以取閾值為0,這樣當有一個樣本xi需要判別的時候,我們就看g(xi)的值。若g(xi)>0,就判別為類別C1,若g(xi)<0,則判別為類別C2(等于的時候我們就拒絕判斷,呵呵)。此時也等價于給函數g(x)附加一個符號函數sgn(),即f(x)=sgn [g(x)]是我們真正的判別函數。
關于g(x)=wx+b這個表達式要注意三點:一,式中的x不是二維坐標系中的橫軸,而是樣本的向量表示,例如一個樣本點的坐標是(3,8),則xT=(3,8) ,而不是x=3(一般說向量都是說列向量,因此以行向量形式來表示時,就加上轉置)。二,這個形式并不局限于二維的情況,在n維空間中仍然可以使用這個表達式,只是式中的w成為了n維向量(在二維的這個例子中,w是二維向量,為了表示起來方便簡潔,以下均不區別列向量和它的轉置,聰明的讀者一看便知);三,g(x)不是中間那條直線的表達式,中間那條直線的表達式是g(x)=0,即wx+b=0,我們也把這個函數叫做分類面。
實際上很容易看出來,中間那條分界線并不是唯一的,我們把它稍微旋轉一下,只要不把兩類數據分錯,仍然可以達到上面說的效果,稍微平移一下,也可以。此時就牽涉到一個問題,對同一個問題存在多個分類函數的時候,哪一個函數更好呢?顯然必須要先找一個指標來量化“好”的程度,通常使用的都是叫做“分類間隔”的指標。下一節我們就仔細說說分類間隔,也補一補相關的數學知識。
SVM入門(三)線性分類器Part 2
上回說到對于文本分類這樣的不適定問題(有一個以上解的問題稱為不適定問題),需要有一個指標來衡量解決方案(即我們通過訓練建立的分類模型)的好壞,而分類間隔是一個比較好的指標。
在進行文本分類的時候,我們可以讓計算機這樣來看待我們提供給它的訓練樣本,每一個樣本由一個向量(就是那些文本特征所組成的向量)和一個標記(標示出這個樣本屬于哪個類別)組成。如下:
Di=(xi,yi)
xi就是文本向量(維數很高),yi就是分類標記。
在二元的線性分類中,這個表示分類的標記只有兩個值,1和-1(用來表示屬于還是不屬于這個類)。有了這種表示法,我們就可以定義一個樣本點到某個超平面的間隔:
δi=yi(wxi+b)
這個公式乍一看沒什么神秘的,也說不出什么道理,只是個定義而已,但我們做做變換,就能看出一些有意思的東西。
首先注意到如果某個樣本屬于該類別的話,那么wxi+b>0(記得么?這是因為我們所選的g(x)=wx+b就通過大于0還是小于0來判斷分類),而yi也大于0;若不屬于該類別的話,那么wxi+b<0,而yi也小于0,這意味著yi(wxi+b)總是大于0的,而且它的值就等于|wxi+b|!(也就是|g(xi)|)
現在把w和b進行一下歸一化,即用w/||w||和b/||w||分別代替原來的w和b,那么間隔就可以寫成
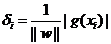
【點到直線的距離,做解析幾何中為:
D = (Ax + By + c) /sqrt(A^2+B^2)
sqrt(A^2+B^2)就相當于||W||, 其中向量W=[A, B];
(Ax + By + c)就相當于g(X), 其中向量X=[x,y]。】
這個公式是不是看上去有點眼熟?沒錯,這不就是解析幾何中點xi到直線g(x)=0的距離公式嘛!(推廣一下,是到超平面g(x)=0的距離, g(x)=0就是上節中提到的分類超平面)
小Tips:||w||是什么符號?||w||叫做向量w的范數,范數是對向量長度的一種度量。我們常說的向量長度其實指的是它的2-范數,范數最一般的表示形式為p-范數,可以寫成如下表達式
向量w=(w1, w2, w3,…… wn)
它的p-范數為

看看把p換成2的時候,不就是傳統的向量長度么?當我們不指明p的時候,就像||w||這樣使用時,就意味著我們不關心p的值,用幾范數都可以;或者上文已經提到了p的值,為了敘述方便不再重復指明。
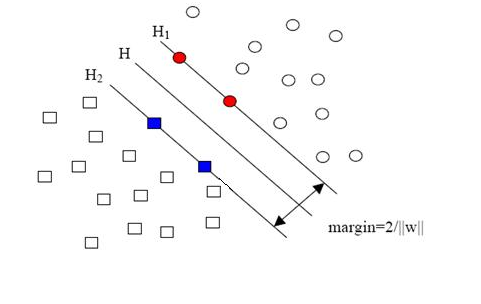
當用歸一化的w和b代替原值之后的間隔有一個專門的名稱,叫做幾何間隔,幾何間隔所表示的正是點到超平面的歐氏距離,我們下面就簡稱幾何間隔為“距離”。以上是單個點到某個超平面的距離(就是間隔,后面不再區別這兩個詞)定義,同樣可以定義一個點的集合(就是一組樣本)到某個超平面的距離為此集合中離超平面最近的點的距離。下面這張圖更加直觀的展示出了幾何間隔的現實含義:
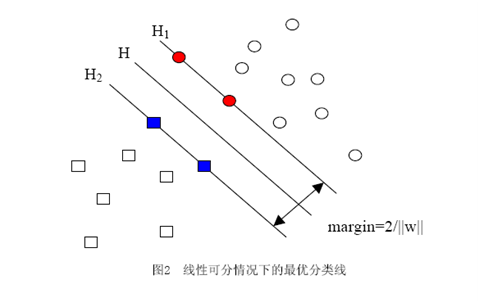
H是分類面,而H1和H2是平行于H,且過離H最近的兩類樣本的直線,H1與H,H2與H之間的距離就是幾何間隔。
之所以如此關心幾何間隔這個東西,是因為幾何間隔與樣本的誤分次數間存在關系:

其中的δ是樣本集合到分類面的間隔,R=max ||xi|| i=1,...,n,即R是所有樣本中(xi是以向量表示的第i個樣本)向量長度最長的值(也就是說代表樣本的分布有多么廣)。先不必追究誤分次數的具體定義和推導過程,只要記得這個誤分次數一定程度上代表分類器的誤差。而從上式可以看出,誤分次數的上界由幾何間隔決定!(當然,是樣本已知的時候)
至此我們就明白為何要選擇幾何間隔來作為評價一個解優劣的指標了,原來幾何間隔越大的解,它的誤差上界越小。因此最大化幾何間隔成了我們訓練階段的目標,而且,與二把刀作者所寫的不同,最大化分類間隔并不是SVM的專利,而是早在線性分類時期就已有的思想。
SVM入門(四)線性分類器的求解——問題的描述Part1
上節說到我們有了一個線性分類函數,也有了判斷解優劣的標準——即有了優化的目標,這個目標就是最大化幾何間隔,但是看過一些關于SVM的論文的人一定記得什么優化的目標是要最小化||w||這樣的說法,這是怎么回事呢?回頭再看看我們對間隔和幾何間隔的定義:
間隔:δ=y(wx+b)=|g(x)|
幾何間隔:
可以看出δ=||w||δ幾何。注意到幾何間隔與||w||是成反比的,因此最大化幾何間隔與最小化||w||完全是一回事。而我們常用的方法并不是固定||w||的大小而尋求最大幾何間隔,而是固定間隔(例如固定為1),尋找最小的||w||。
而凡是求一個函數的最小值(或最大值)的問題都可以稱為尋優問題(也叫作一個規劃問題),又由于找最大值的問題總可以通過加一個負號變為找最小值的問題,因此我們下面討論的時候都針對找最小值的過程來進行。一個尋優問題最重要的部分是目標函數,顧名思義,就是指尋優的目標。例如我們想尋找最小的||w||這件事,就可以用下面的式子表示:

但實際上對于這個目標,我們常常使用另一個完全等價的目標函數來代替,那就是:
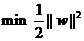 (式1)
(式1)
不難看出當||w||2達到最小時,||w||也達到最小,反之亦然(前提當然是||w||描述的是向量的長度,因而是非負的)。之所以采用這種形式,是因為后面的求解過程會對目標函數作一系列變換,而式(1)的形式會使變換后的形式更為簡潔(正如聰明的讀者所料,添加的系數二分之一和平方,皆是為求導數所需)。
接下來我們自然會問的就是,這個式子是否就描述了我們的問題呢?(回想一下,我們的問題是有一堆點,可以被分成兩類,我們要找出最好的分類面)
如果直接來解這個求最小值問題,很容易看出當||w||=0的時候就得到了目標函數的最小值。但是你也會發現,無論你給什么樣的數據,都是這個解!反映在圖中,就是H1與H2兩條直線間的距離無限大,這個時候,所有的樣本點(無論正樣本還是負樣本)都跑到了H1和H2中間,而我們原本的意圖是,H1右側的被分為正類,H2 左側的被分為負類,位于兩類中間的樣本則拒絕分類(拒絕分類的另一種理解是分給哪一類都有道理,因而分給哪一類也都沒有道理)。這下可好,所有樣本點都進入了無法分類的灰色地帶。

造成這種結果的原因是在描述問題的時候只考慮了目標,而沒有加入約束條件,約束條件就是在求解過程中必須滿足的條件,體現在我們的問題中就是樣本點必須在H1或H2的某一側(或者至少在H1和H2上),而不能跑到兩者中間。我們前文提到過把間隔固定為1,這是指把所有樣本點中間隔最小的那一點的間隔定為1(這也是集合的間隔的定義,有點繞嘴),也就意味著集合中的其他點間隔都不會小于1,按照間隔的定義,滿足這些條件就相當于讓下面的式子總是成立:
yi[(w·xi)+b]≥1 (i=1,2,…,l) (l是總的樣本數)
但我們常常習慣讓式子的值和0比較,因而經常用變換過的形式:
yi[(w·xi)+b]-1≥0 (i=1,2,…,l) (l是總的樣本數)
因此我們的兩類分類問題也被我們轉化成了它的數學形式,一個帶約束的最小值的問題:
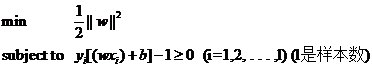
下一節我們從最一般的意義上看看一個求最小值的問題有何特征,以及如何來解。
SVM入門(五)線性分類器的求解——問題的描述Part2
從最一般的定義上說,一個求最小值的問題就是一個優化問題(也叫尋優問題,更文縐縐的叫法是規劃——Programming),它同樣由兩部分組成,目標函數和約束條件,可以用下面的式子表示:
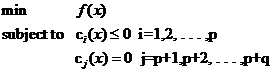 (式1)
(式1)
約束條件用函數c來表示,就是constrain的意思啦。你可以看出一共有p+q個約束條件,其中p個是不等式約束,q個等式約束。
關于這個式子可以這樣來理解:式中的x是自變量,但不限定它的維數必須為1(視乎你解決的問題空間維數,對我們的文本分類來說,那可是成千上萬啊)。要求f(x)在哪一點上取得最小值(反倒不太關心這個最小值到底是多少,關鍵是哪一點),但不是在整個空間里找,而是在約束條件所劃定的一個有限的空間里找,這個有限的空間就是優化理論里所說的可行域。注意可行域中的每一個點都要求滿足所有p+q個條件,而不是滿足其中一條或幾條就可以(切記,要滿足每個約束),同時可行域邊界上的點有一個額外好的特性,它們可以使不等式約束取得等號!而邊界內的點不行。
關于可行域還有個概念不得不提,那就是凸集,凸集是指有這么一個點的集合,其中任取兩個點連一條直線,這條線上的點仍然在這個集合內部,因此說“凸”是很形象的(一個反例是,二維平面上,一個月牙形的區域就不是凸集,你隨便就可以找到兩個點違反了剛才的規定)。
回頭再來看我們線性分類器問題的描述,可以看出更多的東西。
 (式2)
(式2)
在這個問題中,自變量就是w,而目標函數是w的二次函數,所有的約束條件都是w的線性函數(哎,千萬不要把xi當成變量,它代表樣本,是已知的),這種規劃問題有個很有名氣的稱呼——二次規劃(Quadratic Programming,QP),而且可以更進一步的說,由于它的可行域是一個凸集,因此它是一個凸二次規劃。
一下子提了這么多術語,實在不是為了讓大家以后能向別人炫耀學識的淵博,這其實是我們繼續下去的一個重要前提,因為在動手求一個問題的解之前(好吧,我承認,是動計算機求……),我們必須先問自己:這個問題是不是有解?如果有解,是否能找到?
對于一般意義上的規劃問題,兩個問題的答案都是不一定,但凸二次規劃讓人喜歡的地方就在于,它有解(教科書里面為了嚴謹,常常加限定成分,說它有全局最優解,由于我們想找的本來就是全局最優的解,所以不加也罷),而且可以找到!(當然,依據你使用的算法不同,找到這個解的速度,行話叫收斂速度,會有所不同)
對比(式2)和(式1)還可以發現,我們的線性分類器問題只有不等式約束,因此形式上看似乎比一般意義上的規劃問題要簡單,但解起來卻并非如此。
因為我們實際上并不知道該怎么解一個帶約束的優化問題。如果你仔細回憶一下高等數學的知識,會記得我們可以輕松的解一個不帶任何約束的優化問題(實際上就是當年背得爛熟的函數求極值嘛,求導再找0點唄,誰不會啊?笑),我們甚至還會解一個只帶等式約束的優化問題,也是背得爛熟的,求條件極值,記得么,通過添加拉格朗日乘子,構造拉格朗日函數,來把這個問題轉化為無約束的優化問題云云(如果你一時沒想通,我提醒一下,構造出的拉格朗日函數就是轉化之后的問題形式,它顯然沒有帶任何條件)。
讀者問:如果只帶等式約束的問題可以轉化為無約束的問題而得以求解,那么可不可以把帶不等式約束的問題向只帶等式約束的問題轉化一下而得以求解呢?
聰明,可以,實際上我們也正是這么做的。下一節就來說說如何做這個轉化,一旦轉化完成,求解對任何學過高等數學的人來說,都是小菜一碟啦。
SVM入門(六)線性分類器的求解——問題的轉化,直觀角度
讓我再一次比較完整的重復一下我們要解決的問題:我們有屬于兩個類別的樣本點(并不限定這些點在二維空間中)若干,如圖,
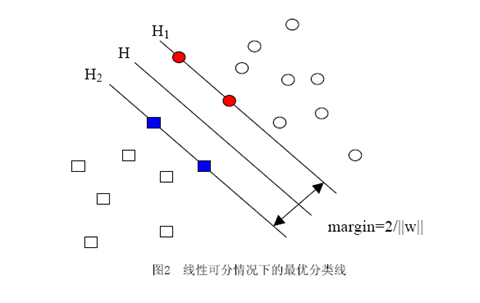
圓形的樣本點定為正樣本(連帶著,我們可以把正樣本所屬的類叫做正類),方形的點定為負例。我們想求得這樣一個線性函數(在n維空間中的線性函數):
g(x)=wx+b
使得所有屬于正類的點![]() +代入以后有g(x+)≥1,而所有屬于負類的點x-代入后有g(x-)≤-1(之所以總跟1比較,無論正一還是負一,都是因為我們固定了間隔為1,注意間隔和幾何間隔的區別)。代入g(x)后的值如果在1和-1之間,我們就拒絕判斷。
+代入以后有g(x+)≥1,而所有屬于負類的點x-代入后有g(x-)≤-1(之所以總跟1比較,無論正一還是負一,都是因為我們固定了間隔為1,注意間隔和幾何間隔的區別)。代入g(x)后的值如果在1和-1之間,我們就拒絕判斷。
求這樣的g(x)的過程就是求w(一個n維向量)和b(一個實數)兩個參數的過程(但實際上只需要求w,求得以后找某些樣本點代入就可以求得b)。因此在求g(x)的時候,w才是變量。
你肯定能看出來,一旦求出了w(也就求出了b),那么中間的直線H就知道了(因為它就是wx+b=0嘛,哈哈),那么H1和H2也就知道了(因為三者是平行的,而且相隔的距離還是||w||決定的)。那么w是誰決定的?顯然是你給的樣本決定的,一旦你在空間中給出了那些個樣本點,三條直線的位置實際上就唯一確定了(因為我們求的是最優的那三條,當然是唯一的),我們解優化問題的過程也只不過是把這個確定了的東西算出來而已。
樣本確定了w,用數學的語言描述,就是w可以表示為樣本的某種組合:
w=α1x1+α2x2+…+αnxn
式子中的αi是一個一個的數(在嚴格的證明過程中,這些α被稱為拉格朗日乘子),而xi是樣本點,因而是向量,n就是總樣本點的個數。為了方便描述,以下開始嚴格區別數字與向量的乘積和向量間的乘積,我會用α1x1表示數字和向量的乘積,而用<x1,x2>表示向量x1,x2的內積(也叫點積,注意與向量叉積的區別)。因此g(x)的表達式嚴格的形式應該是:
g(x)=<w,x>+b
但是上面的式子還不夠好,你回頭看看圖中正樣本和負樣本的位置,想像一下,我不動所有點的位置,而只是把其中一個正樣本點定為負樣本點(也就是把一個點的形狀從圓形變為方形),結果怎么樣?三條直線都必須移動(因為對這三條直線的要求是必須把方形和圓形的點正確分開)!這說明w不僅跟樣本點的位置有關,還跟樣本的類別有關(也就是和樣本的“標簽”有關)。因此用下面這個式子表示才算完整:
w=α1y1x1+α2y2x2+…+αnynxn (式1)
其中的yi就是第i個樣本的標簽,它等于1或者-1。其實以上式子的那一堆拉格朗日乘子中,只有很少的一部分不等于0(不等于0才對w起決定作用),這部分不等于0的拉格朗日乘子后面所乘的樣本點,其實都落在H1和H2上,也正是這部分樣本(而不需要全部樣本)唯一的確定了分類函數,當然,更嚴格的說,這些樣本的一部分就可以確定,因為例如確定一條直線,只需要兩個點就可以,即便有三五個都落在上面,我們也不是全都需要。這部分我們真正需要的樣本點,就叫做支持(撐)向量!(名字還挺形象吧,他們“撐”起了分界線)
式子也可以用求和符號簡寫一下:
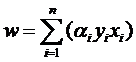
因此原來的g(x)表達式可以寫為:
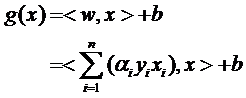
注意式子中x才是變量,也就是你要分類哪篇文檔,就把該文檔的向量表示代入到 x的位置,而所有的xi統統都是已知的樣本。還注意到式子中只有xi和x是向量,因此一部分可以從內積符號中拿出來,得到g(x)的式子為:
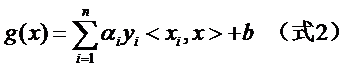
發現了什么?w不見啦!從求w變成了求α。
但肯定有人會說,這并沒有把原問題簡化呀。嘿嘿,其實簡化了,只不過在你看不見的地方,以這樣的形式描述問題以后,我們的優化問題少了很大一部分不等式約束(記得這是我們解不了極值問題的萬惡之源)。但是接下來先跳過線性分類器求解的部分,來看看 SVM在線性分類器上所做的重大改進——核函數。
SVM入門(七)為何需要核函數
生存?還是毀滅?——哈姆雷特
可分?還是不可分?——支持向量機
之前一直在討論的線性分類器,器如其名(汗,這是什么說法啊),只能對線性可分的樣本做處理。如果提供的樣本線性不可分,結果很簡單,線性分類器的求解程序會無限循環,永遠也解不出來。這必然使得它的適用范圍大大縮小,而它的很多優點我們實在不原意放棄,怎么辦呢?是否有某種方法,讓線性不可分的數據變得線性可分呢?
有!其思想說來也簡單,來用一個二維平面中的分類問題作例子,你一看就會明白。事先聲明,下面這個例子是網絡早就有的,我一時找不到原作者的正確信息,在此借用,并加進了我自己的解說而已。
例子是下面這張圖:
/
我們把橫軸上端點a和b之間紅色部分里的所有點定為正類,兩邊的黑色部分里的點定為負類。試問能找到一個線性函數把兩類正確分開么?不能,因為二維空間里的線性函數就是指直線,顯然找不到符合條件的直線。
但我們可以找到一條曲線,例如下面這一條:

顯然通過點在這條曲線的上方還是下方就可以判斷點所屬的類別(你在橫軸上隨便找一點,算算這一點的函數值,會發現負類的點函數值一定比0大,而正類的一定比0小)。這條曲線就是我們熟知的二次曲線,它的函數表達式可以寫為:
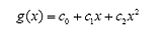
問題只是它不是一個線性函數,但是,下面要注意看了,新建一個向量y和a:
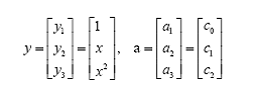
這樣g(x)就可以轉化為f(y)=<a,y>,你可以把y和a分別回帶一下,看看等不等于原來的g(x)。用內積的形式寫你可能看不太清楚,實際上f(y)的形式就是:
g(x)=f(y)=ay
在任意維度的空間中,這種形式的函數都是一個線性函數(只不過其中的a和y都是多維向量罷了),因為自變量y的次數不大于1。
看出妙在哪了么?原來在二維空間中一個線性不可分的問題,映射到四維空間后,變成了線性可分的!因此這也形成了我們最初想解決線性不可分問題的基本思路——向高維空間轉化,使其變得線性可分。
而轉化最關鍵的部分就在于找到x到y的映射方法。遺憾的是,如何找到這個映射,沒有系統性的方法(也就是說,純靠猜和湊)。具體到我們的文本分類問題,文本被表示為上千維的向量,即使維數已經如此之高,也常常是線性不可分的,還要向更高的空間轉化。其中的難度可想而知。
小Tips:為什么說f(y)=ay是四維空間里的函數?
大家可能一時沒看明白。回想一下我們二維空間里的函數定義
g(x)=ax+b
變量x是一維的,為什么說它是二維空間里的函數呢?因為還有一個變量我們沒寫出來,它的完整形式其實是
y=g(x)=ax+b
即
y=ax+b
看看,有幾個變量?兩個。那是幾維空間的函數?(作者五歲的弟弟答:五維的。作者:……)
再看看
f(y)=ay
里面的y是三維的變量,那f(y)是幾維空間里的函數?(作者五歲的弟弟答:還是五維的。作者:……)
用一個具體文本分類的例子來看看這種向高維空間映射從而分類的方法如何運作,想象一下,我們文本分類問題的原始空間是1000維的(即每個要被分類的文檔被表示為一個1000維的向量),在這個維度上問題是線性不可分的。現在我們有一個2000維空間里的線性函數
f(x’)=<w’,x’>+b
注意向量的右上角有個 ’哦。它能夠將原問題變得可分。式中的 w’和x’都是2000維的向量,只不過w’是定值,而x’是變量(好吧,嚴格說來這個函數是2001維的,哈哈),現在我們的輸入呢,是一個1000維的向量x,分類的過程是先把x變換為2000維的向量x’,然后求這個變換后的向量x’與向量w’的內積,再把這個內積的值和b相加,就得到了結果,看結果大于閾值還是小于閾值就得到了分類結果。
你發現了什么?我們其實只關心那個高維空間里內積的值,那個值算出來了,分類結果就算出來了。而從理論上說, x’是經由x變換來的,因此廣義上可以把它叫做x的函數(有一個x,就確定了一個x’,對吧,確定不出第二個),而w’是常量,它是一個低維空間里的常量w經過變換得到的,所以給了一個w 和x的值,就有一個確定的f(x’)值與其對應。這讓我們幻想,是否能有這樣一種函數K(w,x),他接受低維空間的輸入值,卻能算出高維空間的內積值<w’,x’>?
如果有這樣的函數,那么當給了一個低維空間的輸入x以后,
g(x)=K(w,x)+b
f(x’)=<w’,x’>+b
這兩個函數的計算結果就完全一樣,我們也就用不著費力找那個映射關系,直接拿低維的輸入往g(x)里面代就可以了(再次提醒,這回的g(x)就不是線性函數啦,因為你不能保證K(w,x)這個表達式里的x次數不高于1哦)。
萬幸的是,這樣的K(w,x)確實存在(發現凡是我們人類能解決的問題,大都是巧得不能再巧,特殊得不能再特殊的問題,總是恰好有些能投機取巧的地方才能解決,由此感到人類的渺小),它被稱作核函數(核,kernel),而且還不止一個,事實上,只要是滿足了Mercer條件的函數,都可以作為核函數。核函數的基本作用就是接受兩個低維空間里的向量,能夠計算出經過某個變換后在高維空間里的向量內積值。幾個比較常用的核函數,俄,教課書里都列過,我就不敲了(懶!)。
回想我們上節說的求一個線性分類器,它的形式應該是:
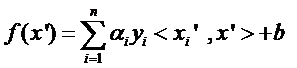
現在這個就是高維空間里的線性函數(為了區別低維和高維空間里的函數和向量,我改了函數的名字,并且給w和x都加上了 ’),我們就可以用一個低維空間里的函數(再一次的,這個低維空間里的函數就不再是線性的啦)來代替,

又發現什么了?f(x’) 和g(x)里的α,y,b全都是一樣一樣的!這就是說,盡管給的問題是線性不可分的,但是我們就硬當它是線性問題來求解,只不過求解過程中,凡是要求內積的時候就用你選定的核函數來算。這樣求出來的α再和你選定的核函數一組合,就得到分類器啦!
明白了以上這些,會自然的問接下來兩個問題:
1. 既然有很多的核函數,針對具體問題該怎么選擇?
2. 如果使用核函數向高維空間映射后,問題仍然是線性不可分的,那怎么辦?
第一個問題現在就可以回答你:對核函數的選擇,現在還缺乏指導原則!各種實驗的觀察結果(不光是文本分類)的確表明,某些問題用某些核函數效果很好,用另一些就很差,但是一般來講,徑向基核函數是不會出太大偏差的一種,首選。(我做文本分類系統的時候,使用徑向基核函數,沒有參數調優的情況下,絕大部分類別的準確和召回都在85%以上,可見。雖然libSVM的作者林智仁認為文本分類用線性核函數效果更佳,待考證)
對第二個問題的解決則引出了我們下一節的主題:松弛變量。
SVM入門(八)松弛變量
現在我們已經把一個本來線性不可分的文本分類問題,通過映射到高維空間而變成了線性可分的。就像下圖這樣:
圓形和方形的點各有成千上萬個(畢竟,這就是我們訓練集中文檔的數量嘛,當然很大了)。現在想象我們有另一個訓練集,只比原先這個訓練集多了一篇文章,映射到高維空間以后(當然,也使用了相同的核函數),也就多了一個樣本點,但是這個樣本的位置是這樣的:
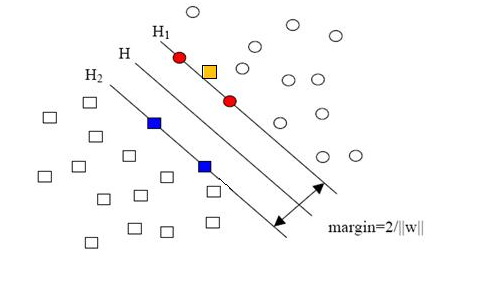
就是圖中黃色那個點,它是方形的,因而它是負類的一個樣本,這單獨的一個樣本,使得原本線性可分的問題變成了線性不可分的。這樣類似的問題(僅有少數點線性不可分)叫做“近似線性可分”的問題。
以我們人類的常識來判斷,說有一萬個點都符合某種規律(因而線性可分),有一個點不符合,那這一個點是否就代表了分類規則中我們沒有考慮到的方面呢(因而規則應該為它而做出修改)?
其實我們會覺得,更有可能的是,這個樣本點壓根就是錯誤,是噪聲,是提供訓練集的同學人工分類時一打瞌睡錯放進去的。所以我們會簡單的忽略這個樣本點,仍然使用原來的分類器,其效果絲毫不受影響。
但這種對噪聲的容錯性是人的思維帶來的,我們的程序可沒有。由于我們原本的優化問題的表達式中,確實要考慮所有的樣本點(不能忽略某一個,因為程序它怎么知道該忽略哪一個呢?),在此基礎上尋找正負類之間的最大幾何間隔,而幾何間隔本身代表的是距離,是非負的,像上面這種有噪聲的情況會使得整個問題無解。這種解法其實也叫做“硬間隔”分類法,因為他硬性的要求所有樣本點都滿足和分類平面間的距離必須大于某個值。
因此由上面的例子中也可以看出,硬間隔的分類法其結果容易受少數點的控制,這是很危險的(盡管有句話說真理總是掌握在少數人手中,但那不過是那一小撮人聊以自慰的詞句罷了,咱還是得民主)。
但解決方法也很明顯,就是仿照人的思路,允許一些點到分類平面的距離不滿足原先的要求。由于不同的訓練集各點的間距尺度不太一樣,因此用間隔(而不是幾何間隔)來衡量有利于我們表達形式的簡潔。我們原先對樣本點的要求是:

意思是說離分類面最近的樣本點函數間隔也要比1大。如果要引入容錯性,就給1這個硬性的閾值加一個松弛變量,即允許
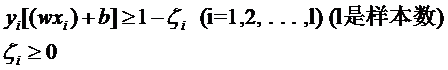
因為松弛變量是非負的,因此最終的結果是要求間隔可以比1小。但是當某些點出現這種間隔比1小的情況時(這些點也叫離群點),意味著我們放棄了對這些點的精確分類,而這對我們的分類器來說是種損失。但是放棄這些點也帶來了好處,那就是使分類面不必向這些點的方向移動,因而可以得到更大的幾何間隔(在低維空間看來,分類邊界也更平滑)。顯然我們必須權衡這種損失和好處。好處很明顯,我們得到的分類間隔越大,好處就越多。回顧我們原始的硬間隔分類對應的優化問題:

||w||2就是我們的目標函數(當然系數可有可無),希望它越小越好,因而損失就必然是一個能使之變大的量(能使它變小就不叫損失了,我們本來就希望目標函數值越小越好)。那如何來衡量損失,有兩種常用的方式,有人喜歡用
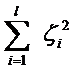
而有人喜歡用
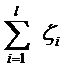
其中l都是樣本的數目。兩種方法沒有大的區別。如果選擇了第一種,得到的方法的就叫做二階軟間隔分類器,第二種就叫做一階軟間隔分類器。把損失加入到目標函數里的時候,就需要一個懲罰因子(cost,也就是libSVM的諸多參數中的C),原來的優化問題就變成了下面這樣:
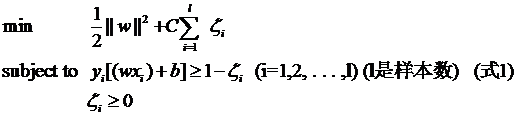
這個式子有這么幾點要注意:
一是并非所有的樣本點都有一個松弛變量與其對應。實際上只有“離群點”才有,或者也可以這么看,所有沒離群的點松弛變量都等于0(對負類來說,離群點就是在前面圖中,跑到H2右側的那些負樣本點,對正類來說,就是跑到H1左側的那些正樣本點)。
【在迭代求w的時候如何樣本點非離群點,即分類正確,那么就設它的松弛變量為0了。。。】
二是松弛變量的值實際上標示出了對應的點到底離群有多遠,值越大,點就越遠。
三是懲罰因子C決定了你有多重視離群點帶來的損失,顯然當所有離群點的松弛變量的和一定時,你定的C越大,對目標函數的損失也越大,此時就暗示著你非常不愿意放棄這些離群點,最極端的情況是你把C定為無限大,這樣只要稍有一個點離群,目標函數的值馬上變成無限大,馬上讓問題變成無解,這就退化成了硬間隔問題。
四是懲罰因子C不是一個變量,整個優化問題在解的時候,C是一個你必須事先指定的值,指定這個值以后,解一下,得到一個分類器,然后用測試數據看看結果怎么樣,如果不夠好,換一個C的值,再解一次優化問題,得到另一個分類器,再看看效果,如此就是一個參數尋優的過程,但這和優化問題本身決不是一回事,優化問題在解的過程中,C一直是定值,要記住。
五是盡管加了松弛變量這么一說,但這個優化問題仍然是一個優化問題(汗,這不廢話么),解它的過程比起原始的硬間隔問題來說,沒有任何更加特殊的地方。
從大的方面說優化問題解的過程,就是先試著確定一下w,也就是確定了前面圖中的三條直線,這時看看間隔有多大,又有多少點離群,把目標函數的值算一算,再換一組三條直線(你可以看到,分類的直線位置如果移動了,有些原來離群的點會變得不再離群,而有的本來不離群的點會變成離群點),再把目標函數的值算一算,如此往復(迭代),直到最終找到目標函數最小時的w。
啰嗦了這么多,讀者一定可以馬上自己總結出來,松弛變量也就是個解決線性不可分問題的方法罷了,但是回想一下,核函數的引入不也是為了解決線性不可分的問題么?為什么要為了一個問題使用兩種方法呢?
其實兩者還有微妙的不同。一般的過程應該是這樣,還以文本分類為例。在原始的低維空間中,樣本相當的不可分,無論你怎么找分類平面,總會有大量的離群點,此時用核函數向高維空間映射一下,雖然結果仍然是不可分的,但比原始空間里的要更加接近線性可分的狀態(就是達到了近似線性可分的狀態),此時再用松弛變量處理那些少數“冥頑不化”的離群點,就簡單有效得多啦。
本節中的(式1)也確實是支持向量機最最常用的形式。至此一個比較完整的支持向量機框架就有了,簡單說來,支持向量機就是使用了核函數的軟間隔線性分類法。
下一節會說說松弛變量剩下的一點點東西,順便搞個讀者調查,看看大家還想侃侃SVM的哪些方面。
SVM入門(九)松弛變量(續)
接下來要說的東西其實不是松弛變量本身,但由于是為了使用松弛變量才引入的,因此放在這里也算合適,那就是懲罰因子C。回頭看一眼引入了松弛變量以后的優化問題:
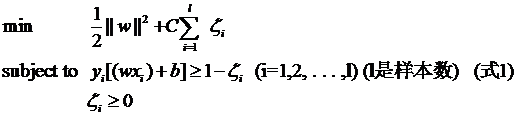
注意其中C的位置,也可以回想一下C所起的作用(表征你有多么重視離群點,C越大越重視,越不想丟掉它們)。這個式子是以前做SVM的人寫的,大家也就這么用,但沒有任何規定說必須對所有的松弛變量都使用同一個懲罰因子,我們完全可以給每一個離群點都使用不同的C,這時就意味著你對每個樣本的重視程度都不一樣,有些樣本丟了也就丟了,錯了也就錯了,這些就給一個比較小的C;而有些樣本很重要,決不能分類錯誤(比如中央下達的文件啥的,笑),就給一個很大的C。
當然實際使用的時候并沒有這么極端,但一種很常用的變形可以用來解決分類問題中樣本的“偏斜”問題。
先來說說樣本的偏斜問題,也叫數據集偏斜(unbalanced),它指的是參與分類的兩個類別(也可以指多個類別)樣本數量差異很大。比如說正類有10,000個樣本,而負類只給了100個,這會引起的問題顯而易見,可以看看下面的圖:
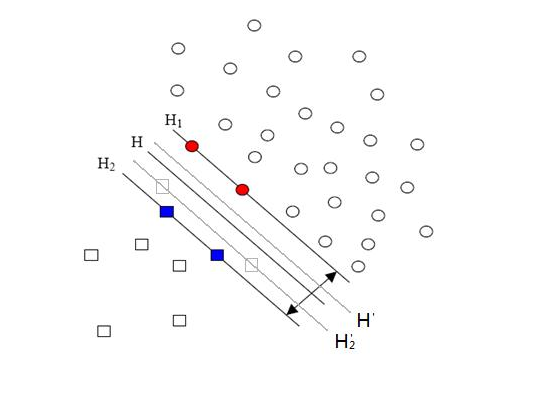
方形的點是負類。H,H1,H2是根據給的樣本算出來的分類面,由于負類的樣本很少很少,所以有一些本來是負類的樣本點沒有提供,比如圖中兩個灰色的方形點,如果這兩個點有提供的話,那算出來的分類面應該是H’,H2’和H1,他們顯然和之前的結果有出入,實際上負類給的樣本點越多,就越容易出現在灰色點附近的點,我們算出的結果也就越接近于真實的分類面。但現在由于偏斜的現象存在,使得數量多的正類可以把分類面向負類的方向“推”,因而影響了結果的準確性。
對付數據集偏斜問題的方法之一就是在懲罰因子上作文章,想必大家也猜到了,那就是給樣本數量少的負類更大的懲罰因子,表示我們重視這部分樣本(本來數量就少,再拋棄一些,那人家負類還活不活了),因此我們的目標函數中因松弛變量而損失的部分就變成了:

其中i=1…p都是正樣本,j=p+1…p+q都是負樣本。libSVM這個算法包在解決偏斜問題的時候用的就是這種方法。
那C+和C-怎么確定呢?它們的大小是試出來的(參數調優),但是他們的比例可以有些方法來確定。咱們先假定說C+是5這么大,那確定C-的一個很直觀的方法就是使用兩類樣本數的比來算,對應到剛才舉的例子,C-就可以定為500這么大(因為10,000:100=100:1嘛)。
但是這樣并不夠好,回看剛才的圖,你會發現正類之所以可以“欺負”負類,其實并不是因為負類樣本少,真實的原因是負類的樣本分布的不夠廣(沒擴充到負類本應該有的區域)。說一個具體點的例子,現在想給政治類和體育類的文章做分類,政治類文章很多,而體育類只提供了幾篇關于籃球的文章,這時分類會明顯偏向于政治類,如果要給體育類文章增加樣本,但增加的樣本仍然全都是關于籃球的(也就是說,沒有足球,排球,賽車,游泳等等),那結果會怎樣呢?雖然體育類文章在數量上可以達到與政治類一樣多,但過于集中了,結果仍會偏向于政治類!所以給C+和C-確定比例更好的方法應該是衡量他們分布的程度。比如可以算算他們在空間中占據了多大的體積,例如給負類找一個超球——就是高維空間里的球啦——它可以包含所有負類的樣本,再給正類找一個,比比兩個球的半徑,就可以大致確定分布的情況。顯然半徑大的分布就比較廣,就給小一點的懲罰因子。
但是這樣還不夠好,因為有的類別樣本確實很集中,這不是提供的樣本數量多少的問題,這是類別本身的特征(就是某些話題涉及的面很窄,例如計算機類的文章就明顯不如文化類的文章那么“天馬行空”),這個時候即便超球的半徑差異很大,也不應該賦予兩個類別不同的懲罰因子。
看到這里讀者一定瘋了,因為說來說去,這豈不成了一個解決不了的問題?然而事實如此,完全的方法是沒有的,根據需要,選擇實現簡單又合用的就好(例如libSVM就直接使用樣本數量的比)。
SVM入門(十)將SVM用于多類分類
從 SVM的那幾張圖可以看出來,SVM是一種典型的兩類分類器,即它只回答屬于正類還是負類的問題。而現實中要解決的問題,往往是多類的問題(少部分例外,例如垃圾郵件過濾,就只需要確定“是”還是“不是”垃圾郵件),比如文本分類,比如數字識別。如何由兩類分類器得到多類分類器,就是一個值得研究的問題。
還以文本分類為例,現成的方法有很多,其中一種一勞永逸的方法,就是真的一次性考慮所有樣本,并求解一個多目標函數的優化問題,一次性得到多個分類面,就像下圖這樣:
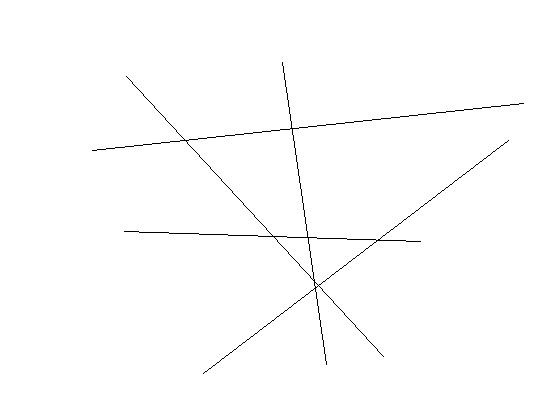
多個超平面把空間劃分為多個區域,每個區域對應一個類別,給一篇文章,看它落在哪個區域就知道了它的分類。
看起來很美對不對?只可惜這種算法還基本停留在紙面上,因為一次性求解的方法計算量實在太大,大到無法實用的地步。
稍稍退一步,我們就會想到所謂“一類對其余”的方法,就是每次仍然解一個兩類分類的問題。比如我們有5個類別,第一次就把類別1的樣本定為正樣本,其余2,3,4,5的樣本合起來定為負樣本,這樣得到一個兩類分類器,它能夠指出一篇文章是還是不是第1類的;第二次我們把類別2 的樣本定為正樣本,把1,3,4,5的樣本合起來定為負樣本,得到一個分類器,如此下去,我們可以得到5個這樣的兩類分類器(總是和類別的數目一致)。到了有文章需要分類的時候,我們就拿著這篇文章挨個分類器的問:是屬于你的么?是屬于你的么?哪個分類器點頭說是了,文章的類別就確定了。這種方法的好處是每個優化問題的規模比較小,而且分類的時候速度很快(只需要調用5個分類器就知道了結果)。但有時也會出現兩種很尷尬的情況,例如拿一篇文章問了一圈,每一個分類器都說它是屬于它那一類的,或者每一個分類器都說它不是它那一類的,前者叫分類重疊現象,后者叫不可分類現象。分類重疊倒還好辦,隨便選一個結果都不至于太離譜,或者看看這篇文章到各個超平面的距離,哪個遠就判給哪個。不可分類現象就著實難辦了,只能把它分給第6個類別了……更要命的是,本來各個類別的樣本數目是差不多的,但“其余”的那一類樣本數總是要數倍于正類(因為它是除正類以外其他類別的樣本之和嘛),這就人為的造成了上一節所說的“數據集偏斜”問題。
因此我們還得再退一步,還是解兩類分類問題,還是每次選一個類的樣本作正類樣本,而負類樣本則變成只選一個類(稱為“一對一單挑”的方法,哦,不對,沒有單挑,就是“一對一”的方法,呵呵),這就避免了偏斜。因此過程就是算出這樣一些分類器,第一個只回答“是第1類還是第2類”,第二個只回答“是第1類還是第3類”,第三個只回答“是第1類還是第4類”,如此下去,你也可以馬上得出,這樣的分類器應該有5 X 4/2=10個(通式是,如果有k個類別,則總的兩類分類器數目為k(k-1)/2)。雖然分類器的數目多了,但是在訓練階段(也就是算出這些分類器的分類平面時)所用的總時間卻比“一類對其余”方法少很多,在真正用來分類的時候,把一篇文章扔給所有分類器,第一個分類器會投票說它是“1”或者“2”,第二個會說它是“1”或者“3”,讓每一個都投上自己的一票,最后統計票數,如果類別“1”得票最多,就判這篇文章屬于第1類。這種方法顯然也會有分類重疊的現象,但不會有不可分類現象,因為總不可能所有類別的票數都是0。看起來夠好么?其實不然,想想分類一篇文章,我們調用了多少個分類器?10個,這還是類別數為5的時候,類別數如果是1000,要調用的分類器數目會上升至約500,000個(類別數的平方量級)。這如何是好?
看來我們必須再退一步,在分類的時候下功夫,我們還是像一對一方法那樣來訓練,只是在對一篇文章進行分類之前,我們先按照下面圖的樣子來組織分類器(如你所見,這是一個有向無環圖,因此這種方法也叫做DAG SVM)

這樣在分類時,我們就可以先問分類器“1對5”(意思是它能夠回答“是第1類還是第5類”),如果它回答5,我們就往左走,再問“2對5”這個分類器,如果它還說是“5”,我們就繼續往左走,這樣一直問下去,就可以得到分類結果。好處在哪?我們其實只調用了4個分類器(如果類別數是k,則只調用k-1個),分類速度飛快,且沒有分類重疊和不可分類現象!缺點在哪?假如最一開始的分類器回答錯誤(明明是類別1的文章,它說成了5),那么后面的分類器是無論如何也無法糾正它的錯誤的(因為后面的分類器壓根沒有出現“1”這個類別標簽),其實對下面每一層的分類器都存在這種錯誤向下累積的現象。。
不過不要被DAG方法的錯誤累積嚇倒,錯誤累積在一對其余和一對一方法中也都存在,DAG方法好于它們的地方就在于,累積的上限,不管是大是小,總是有定論的,有理論證明。而一對其余和一對一方法中,盡管每一個兩類分類器的泛化誤差限是知道的,但是合起來做多類分類的時候,誤差上界是多少,沒人知道,這意味著準確率低到0也是有可能的,這多讓人郁悶。
而且現在DAG方法根節點的選取(也就是如何選第一個參與分類的分類器),也有一些方法可以改善整體效果,我們總希望根節點少犯錯誤為好,因此參與第一次分類的兩個類別,最好是差別特別特別大,大到以至于不太可能把他們分錯;或者我們就總取在兩類分類中正確率最高的那個分類器作根節點,或者我們讓兩類分類器在分類的時候,不光輸出類別的標簽,還輸出一個類似“置信度”的東東,當它對自己的結果不太自信的時候,我們就不光按照它的輸出走,把它旁邊的那條路也走一走,等等。
大Tips:SVM的計算復雜度
使用SVM進行分類的時候,實際上是訓練和分類兩個完全不同的過程,因而討論復雜度就不能一概而論,我們這里所說的主要是訓練階段的復雜度,即解那個二次規劃問題的復雜度。對這個問題的解,基本上要劃分為兩大塊,解析解和數值解。
解析解就是理論上的解,它的形式是表達式,因此它是精確的,一個問題只要有解(無解的問題還跟著摻和什么呀,哈哈),那它的解析解是一定存在的。當然存在是一回事,能夠解出來,或者可以在可以承受的時間范圍內解出來,就是另一回事了。對SVM來說,求得解析解的時間復雜度最壞可以達到O(Nsv3),其中Nsv是支持向量的個數,而雖然沒有固定的比例,但支持向量的個數多少也和訓練集的大小有關。
數值解就是可以使用的解,是一個一個的數,往往都是近似解。求數值解的過程非常像窮舉法,從一個數開始,試一試它當解效果怎樣,不滿足一定條件(叫做停機條件,就是滿足這個以后就認為解足夠精確了,不需要繼續算下去了)就試下一個,當然下一個數不是亂選的,也有一定章法可循。有的算法,每次只嘗試一個數,有的就嘗試多個,而且找下一個數字(或下一組數)的方法也各不相同,停機條件也各不相同,最終得到的解精度也各不相同,可見對求數值解的復雜度的討論不能脫開具體的算法。
一個具體的算法,Bunch-Kaufman訓練算法,典型的時間復雜度在O(Nsv3+LNsv2+dLNsv)和O(dL2)之間,其中Nsv是支持向量的個數,L是訓練集樣本的個數,d是每個樣本的維數(原始的維數,沒有經過向高維空間映射之前的維數)。復雜度會有變化,是因為它不光跟輸入問題的規模有關(不光和樣本的數量,維數有關),也和問題最終的解有關(即支持向量有關),如果支持向量比較少,過程會快很多,如果支持向量很多,接近于樣本的數量,就會產生O(dL2)這個十分糟糕的結果(給10,000個樣本,每個樣本1000維,基本就不用算了,算不出來,呵呵,而這種輸入規模對文本分類來說太正常了)。
這樣再回頭看就會明白為什么一對一方法盡管要訓練的兩類分類器數量多,但總時間實際上比一對其余方法要少了,因為一對其余方法每次訓練都考慮了所有樣本(只是每次把不同的部分劃分為正類或者負類而已),自然慢上很多。