轉(zhuǎn)自:http://blog.csdn.net/yangliuy/article/details/7316496
SVM入門(mén)(一)至(三)Refresh
按:之前的文章重新匯編一下,修改了一些錯(cuò)誤和不當(dāng)?shù)恼f(shuō)法,一起復(fù)習(xí),然后繼續(xù)SVM之旅.
(一)SVM的簡(jiǎn)介
支持向量機(jī)(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解決小樣本、非線性及高維模式識(shí)別中表現(xiàn)出許多特有的優(yōu)勢(shì),并能夠推廣應(yīng)用到函數(shù)擬合等其他機(jī)器學(xué)習(xí)問(wèn)題中[10]。
支持向量機(jī)方法是建立在統(tǒng)計(jì)學(xué)習(xí)理論的VC 維理論和結(jié)構(gòu)風(fēng)險(xiǎn)最小原理基礎(chǔ)上的,根據(jù)有限的樣本信息在模型的復(fù)雜性(即對(duì)特定訓(xùn)練樣本的學(xué)習(xí)精度,Accuracy)和學(xué)習(xí)能力(即無(wú)錯(cuò)誤地識(shí)別任意樣本的能力)之間尋求最佳折衷,以期獲得最好的推廣能力[14](或稱泛化能力)。
以上是經(jīng)常被有關(guān)SVM 的學(xué)術(shù)文獻(xiàn)引用的介紹,我來(lái)逐一分解并解釋一下。
Vapnik是統(tǒng)計(jì)機(jī)器學(xué)習(xí)的大牛,這想必都不用說(shuō),他出版的《Statistical Learning Theory》是一本完整闡述統(tǒng)計(jì)機(jī)器學(xué)習(xí)思想的名著。在該書(shū)中詳細(xì)的論證了統(tǒng)計(jì)機(jī)器學(xué)習(xí)之所以區(qū)別于傳統(tǒng)機(jī)器學(xué)習(xí)的本質(zhì),就在于統(tǒng)計(jì)機(jī)器學(xué)習(xí)能夠精確的給出學(xué)習(xí)效果,能夠解答需要的樣本數(shù)等等一系列問(wèn)題。與統(tǒng)計(jì)機(jī)器學(xué)習(xí)的精密思維相比,傳統(tǒng)的機(jī)器學(xué)習(xí)基本上屬于摸著石頭過(guò)河,用傳統(tǒng)的機(jī)器學(xué)習(xí)方法構(gòu)造分類(lèi)系統(tǒng)完全成了一種技巧,一個(gè)人做的結(jié)果可能很好,另一個(gè)人差不多的方法做出來(lái)卻很差,缺乏指導(dǎo)和原則。
所謂VC維是對(duì)函數(shù)類(lèi)的一種度量,可以簡(jiǎn)單的理解為問(wèn)題的復(fù)雜程度,VC維越高,一個(gè)問(wèn)題就越復(fù)雜。正是因?yàn)镾VM關(guān)注的是VC維,后面我們可以看到,SVM解決問(wèn)題的時(shí)候,和樣本的維數(shù)是無(wú)關(guān)的(甚至樣本是上萬(wàn)維的都可以,這使得SVM很適合用來(lái)解決文本分類(lèi)的問(wèn)題,當(dāng)然,有這樣的能力也因?yàn)橐肓撕撕瘮?shù))。
結(jié)構(gòu)風(fēng)險(xiǎn)最小聽(tīng)上去文縐縐,其實(shí)說(shuō)的也無(wú)非是下面這回事。
機(jī)器學(xué)習(xí)本質(zhì)上就是一種對(duì)問(wèn)題真實(shí)模型的逼近(我們選擇一個(gè)我們認(rèn)為比較好的近似模型,這個(gè)近似模型就叫做一個(gè)假設(shè)),但毫無(wú)疑問(wèn),真實(shí)模型一定是不知道的(如果知道了,我們干嗎還要機(jī)器學(xué)習(xí)?直接用真實(shí)模型解決問(wèn)題不就可以了?對(duì)吧,哈哈)既然真實(shí)模型不知道,那么我們選擇的假設(shè)與問(wèn)題真實(shí)解之間究竟有多大差距,我們就沒(méi)法得知。比如說(shuō)我們認(rèn)為宇宙誕生于150億年前的一場(chǎng)大爆炸,這個(gè)假設(shè)能夠描述很多我們觀察到的現(xiàn)象,但它與真實(shí)的宇宙模型之間還相差多少?誰(shuí)也說(shuō)不清,因?yàn)槲覀儔焊筒恢勒鎸?shí)的宇宙模型到底是什么。
這個(gè)與問(wèn)題真實(shí)解之間的誤差,就叫做風(fēng)險(xiǎn)(更嚴(yán)格的說(shuō),誤差的累積叫做風(fēng)險(xiǎn))。我們選擇了一個(gè)假設(shè)之后(更直觀點(diǎn)說(shuō),我們得到了一個(gè)分類(lèi)器以后),真實(shí)誤差無(wú)從得知,但我們可以用某些可以掌握的量來(lái)逼近它。最直觀的想法就是使用分類(lèi)器在樣本數(shù)據(jù)上的分類(lèi)的結(jié)果與真實(shí)結(jié)果(因?yàn)闃颖臼且呀?jīng)標(biāo)注過(guò)的數(shù)據(jù),是準(zhǔn)確的數(shù)據(jù))之間的差值來(lái)表示。這個(gè)差值叫做經(jīng)驗(yàn)風(fēng)險(xiǎn)Remp(w)。以前的機(jī)器學(xué)習(xí)方法都把經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化作為努力的目標(biāo),但后來(lái)發(fā)現(xiàn)很多分類(lèi)函數(shù)能夠在樣本集上輕易達(dá)到100%的正確率,在真實(shí)分類(lèi)時(shí)卻一塌糊涂(即所謂的推廣能力差,或泛化能力差)。此時(shí)的情況便是選擇了一個(gè)足夠復(fù)雜的分類(lèi)函數(shù)(它的VC維很高),能夠精確的記住每一個(gè)樣本,但對(duì)樣本之外的數(shù)據(jù)一律分類(lèi)錯(cuò)誤。回頭看看經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化原則我們就會(huì)發(fā)現(xiàn),此原則適用的大前提是經(jīng)驗(yàn)風(fēng)險(xiǎn)要確實(shí)能夠逼近真實(shí)風(fēng)險(xiǎn)才行(行話叫一致),但實(shí)際上能逼近么?答案是不能,因?yàn)闃颖緮?shù)相對(duì)于現(xiàn)實(shí)世界要分類(lèi)的文本數(shù)來(lái)說(shuō)簡(jiǎn)直九牛一毛,經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化原則只在這占很小比例的樣本上做到?jīng)]有誤差,當(dāng)然不能保證在更大比例的真實(shí)文本上也沒(méi)有誤差。
統(tǒng)計(jì)學(xué)習(xí)因此而引入了泛化誤差界的概念,就是指真實(shí)風(fēng)險(xiǎn)應(yīng)該由兩部分內(nèi)容刻畫(huà),一是經(jīng)驗(yàn)風(fēng)險(xiǎn),代表了分類(lèi)器在給定樣本上的誤差;二是置信風(fēng)險(xiǎn),代表了我們?cè)诙啻蟪潭壬峡梢孕湃畏诸?lèi)器在未知文本上分類(lèi)的結(jié)果。很顯然,第二部分是沒(méi)有辦法精確計(jì)算的,因此只能給出一個(gè)估計(jì)的區(qū)間,也使得整個(gè)誤差只能計(jì)算上界,而無(wú)法計(jì)算準(zhǔn)確的值(所以叫做泛化誤差界,而不叫泛化誤差)。
置信風(fēng)險(xiǎn)與兩個(gè)量有關(guān),一是樣本數(shù)量,顯然給定的樣本數(shù)量越大,我們的學(xué)習(xí)結(jié)果越有可能正確,此時(shí)置信風(fēng)險(xiǎn)越小;二是分類(lèi)函數(shù)的VC維,顯然VC維越大,推廣能力越差,置信風(fēng)險(xiǎn)會(huì)變大。
泛化誤差界的公式為:
R(w)≤Remp(w)+Ф(n/h)
公式中R(w)就是真實(shí)風(fēng)險(xiǎn),Remp(w)就是經(jīng)驗(yàn)風(fēng)險(xiǎn),Ф(n/h)就是置信風(fēng)險(xiǎn)。統(tǒng)計(jì)學(xué)習(xí)的目標(biāo)從經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化變?yōu)榱藢で蠼?jīng)驗(yàn)風(fēng)險(xiǎn)與置信風(fēng)險(xiǎn)的和最小,即結(jié)構(gòu)風(fēng)險(xiǎn)最小。
SVM正是這樣一種努力最小化結(jié)構(gòu)風(fēng)險(xiǎn)的算法。
SVM其他的特點(diǎn)就比較容易理解了。
小樣本,并不是說(shuō)樣本的絕對(duì)數(shù)量少(實(shí)際上,對(duì)任何算法來(lái)說(shuō),更多的樣本幾乎總是能帶來(lái)更好的效果),而是說(shuō)與問(wèn)題的復(fù)雜度比起來(lái),SVM算法要求的樣本數(shù)是相對(duì)比較少的。
非線性,是指SVM擅長(zhǎng)應(yīng)付樣本數(shù)據(jù)線性不可分的情況,主要通過(guò)松弛變量(也有人叫懲罰變量)和核函數(shù)技術(shù)來(lái)實(shí)現(xiàn),這一部分是SVM的精髓,以后會(huì)詳細(xì)討論。多說(shuō)一句,關(guān)于文本分類(lèi)這個(gè)問(wèn)題究竟是不是線性可分的,尚沒(méi)有定論,因此不能簡(jiǎn)單的認(rèn)為它是線性可分的而作簡(jiǎn)化處理,在水落石出之前,只好先當(dāng)它是線性不可分的(反正線性可分也不過(guò)是線性不可分的一種特例而已,我們向來(lái)不怕方法過(guò)于通用)。
高維模式識(shí)別是指樣本維數(shù)很高,例如文本的向量表示,如果沒(méi)有經(jīng)過(guò)另一系列文章(《文本分類(lèi)入門(mén)》)中提到過(guò)的降維處理,出現(xiàn)幾萬(wàn)維的情況很正常,其他算法基本就沒(méi)有能力應(yīng)付了,SVM卻可以,主要是因?yàn)镾VM 產(chǎn)生的分類(lèi)器很簡(jiǎn)潔,用到的樣本信息很少(僅僅用到那些稱之為“支持向量”的樣本,此為后話),使得即使樣本維數(shù)很高,也不會(huì)給存儲(chǔ)和計(jì)算帶來(lái)大麻煩(相對(duì)照而言,kNN算法在分類(lèi)時(shí)就要用到所有樣本,樣本數(shù)巨大,每個(gè)樣本維數(shù)再一高,這日子就沒(méi)法過(guò)了……)。
下一節(jié)開(kāi)始正式討論SVM。別嫌我說(shuō)得太詳細(xì)哦。
SVM入門(mén)(二)線性分類(lèi)器Part 1
線性分類(lèi)器(一定意義上,也可以叫做感知機(jī)) 是最簡(jiǎn)單也很有效的分類(lèi)器形式.在一個(gè)線性分類(lèi)器中,可以看到SVM形成的思路,并接觸很多SVM的核心概念.
用一個(gè)二維空間里僅有兩類(lèi)樣本的分類(lèi)問(wèn)題來(lái)舉個(gè)小例子。如圖所示

C1和C2是要區(qū)分的兩個(gè)類(lèi)別,在二維平面中它們的樣本如上圖所示。中間的直線就是一個(gè)分類(lèi)函數(shù),它可以將兩類(lèi)樣本完全分開(kāi)。一般的,如果一個(gè)線性函數(shù)能夠?qū)颖就耆_的分開(kāi),就稱這些數(shù)據(jù)是線性可分的,否則稱為非線性可分的。
什么叫線性函數(shù)呢?在一維空間里就是一個(gè)點(diǎn),在二維空間里就是一條直線,三維空間里就是一個(gè)平面,可以如此想象下去,如果不關(guān)注空間的維數(shù),這種線性函數(shù)還有一個(gè)統(tǒng)一的名稱——超平面(Hyper Plane)!
實(shí)際上,一個(gè)線性函數(shù)是一個(gè)實(shí)值函數(shù)(即函數(shù)的值是連續(xù)的實(shí)數(shù)),而我們的分類(lèi)問(wèn)題(例如這里的二元分類(lèi)問(wèn)題——回答一個(gè)樣本屬于還是不屬于一個(gè)類(lèi)別的問(wèn)題)需要離散的輸出值,例如用1表示某個(gè)樣本屬于類(lèi)別C1,而用0表示不屬于(不屬于C1也就意味著屬于C2),這時(shí)候只需要簡(jiǎn)單的在實(shí)值函數(shù)的基礎(chǔ)上附加一個(gè)閾值即可,通過(guò)分類(lèi)函數(shù)執(zhí)行時(shí)得到的值大于還是小于這個(gè)閾值來(lái)確定類(lèi)別歸屬。 例如我們有一個(gè)線性函數(shù)
g(x)=wx+b
【看到好多人都在問(wèn)g(x)=0 和 g(x)的問(wèn)題,我在這里幫樓主補(bǔ)充一下:g(x)實(shí)際是以w為法向量的一簇超平面,在二維空間表示為一簇直線(就是一簇平行線,他們的法向量都是w),而g(x)=0只是這么多平行線中的一條。】
我們可以取閾值為0,這樣當(dāng)有一個(gè)樣本xi需要判別的時(shí)候,我們就看g(xi)的值。若g(xi)>0,就判別為類(lèi)別C1,若g(xi)<0,則判別為類(lèi)別C2(等于的時(shí)候我們就拒絕判斷,呵呵)。此時(shí)也等價(jià)于給函數(shù)g(x)附加一個(gè)符號(hào)函數(shù)sgn(),即f(x)=sgn [g(x)]是我們真正的判別函數(shù)。
關(guān)于g(x)=wx+b這個(gè)表達(dá)式要注意三點(diǎn):一,式中的x不是二維坐標(biāo)系中的橫軸,而是樣本的向量表示,例如一個(gè)樣本點(diǎn)的坐標(biāo)是(3,8),則xT=(3,8) ,而不是x=3(一般說(shuō)向量都是說(shuō)列向量,因此以行向量形式來(lái)表示時(shí),就加上轉(zhuǎn)置)。二,這個(gè)形式并不局限于二維的情況,在n維空間中仍然可以使用這個(gè)表達(dá)式,只是式中的w成為了n維向量(在二維的這個(gè)例子中,w是二維向量,為了表示起來(lái)方便簡(jiǎn)潔,以下均不區(qū)別列向量和它的轉(zhuǎn)置,聰明的讀者一看便知);三,g(x)不是中間那條直線的表達(dá)式,中間那條直線的表達(dá)式是g(x)=0,即wx+b=0,我們也把這個(gè)函數(shù)叫做分類(lèi)面。
實(shí)際上很容易看出來(lái),中間那條分界線并不是唯一的,我們把它稍微旋轉(zhuǎn)一下,只要不把兩類(lèi)數(shù)據(jù)分錯(cuò),仍然可以達(dá)到上面說(shuō)的效果,稍微平移一下,也可以。此時(shí)就牽涉到一個(gè)問(wèn)題,對(duì)同一個(gè)問(wèn)題存在多個(gè)分類(lèi)函數(shù)的時(shí)候,哪一個(gè)函數(shù)更好呢?顯然必須要先找一個(gè)指標(biāo)來(lái)量化“好”的程度,通常使用的都是叫做“分類(lèi)間隔”的指標(biāo)。下一節(jié)我們就仔細(xì)說(shuō)說(shuō)分類(lèi)間隔,也補(bǔ)一補(bǔ)相關(guān)的數(shù)學(xué)知識(shí)。
SVM入門(mén)(三)線性分類(lèi)器Part 2
上回說(shuō)到對(duì)于文本分類(lèi)這樣的不適定問(wèn)題(有一個(gè)以上解的問(wèn)題稱為不適定問(wèn)題),需要有一個(gè)指標(biāo)來(lái)衡量解決方案(即我們通過(guò)訓(xùn)練建立的分類(lèi)模型)的好壞,而分類(lèi)間隔是一個(gè)比較好的指標(biāo)。
在進(jìn)行文本分類(lèi)的時(shí)候,我們可以讓計(jì)算機(jī)這樣來(lái)看待我們提供給它的訓(xùn)練樣本,每一個(gè)樣本由一個(gè)向量(就是那些文本特征所組成的向量)和一個(gè)標(biāo)記(標(biāo)示出這個(gè)樣本屬于哪個(gè)類(lèi)別)組成。如下:
Di=(xi,yi)
xi就是文本向量(維數(shù)很高),yi就是分類(lèi)標(biāo)記。
在二元的線性分類(lèi)中,這個(gè)表示分類(lèi)的標(biāo)記只有兩個(gè)值,1和-1(用來(lái)表示屬于還是不屬于這個(gè)類(lèi))。有了這種表示法,我們就可以定義一個(gè)樣本點(diǎn)到某個(gè)超平面的間隔:
δi=yi(wxi+b)
這個(gè)公式乍一看沒(méi)什么神秘的,也說(shuō)不出什么道理,只是個(gè)定義而已,但我們做做變換,就能看出一些有意思的東西。
首先注意到如果某個(gè)樣本屬于該類(lèi)別的話,那么wxi+b>0(記得么?這是因?yàn)槲覀兯x的g(x)=wx+b就通過(guò)大于0還是小于0來(lái)判斷分類(lèi)),而yi也大于0;若不屬于該類(lèi)別的話,那么wxi+b<0,而yi也小于0,這意味著yi(wxi+b)總是大于0的,而且它的值就等于|wxi+b|!(也就是|g(xi)|)
現(xiàn)在把w和b進(jìn)行一下歸一化,即用w/||w||和b/||w||分別代替原來(lái)的w和b,那么間隔就可以寫(xiě)成
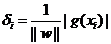
【點(diǎn)到直線的距離,做解析幾何中為:
D = (Ax + By + c) /sqrt(A^2+B^2)
sqrt(A^2+B^2)就相當(dāng)于||W||, 其中向量W=[A, B];
(Ax + By + c)就相當(dāng)于g(X), 其中向量X=[x,y]。】
這個(gè)公式是不是看上去有點(diǎn)眼熟?沒(méi)錯(cuò),這不就是解析幾何中點(diǎn)xi到直線g(x)=0的距離公式嘛!(推廣一下,是到超平面g(x)=0的距離, g(x)=0就是上節(jié)中提到的分類(lèi)超平面)
小Tips:||w||是什么符號(hào)?||w||叫做向量w的范數(shù),范數(shù)是對(duì)向量長(zhǎng)度的一種度量。我們常說(shuō)的向量長(zhǎng)度其實(shí)指的是它的2-范數(shù),范數(shù)最一般的表示形式為p-范數(shù),可以寫(xiě)成如下表達(dá)式
向量w=(w1, w2, w3,…… wn)
它的p-范數(shù)為

看看把p換成2的時(shí)候,不就是傳統(tǒng)的向量長(zhǎng)度么?當(dāng)我們不指明p的時(shí)候,就像||w||這樣使用時(shí),就意味著我們不關(guān)心p的值,用幾范數(shù)都可以;或者上文已經(jīng)提到了p的值,為了敘述方便不再重復(fù)指明。
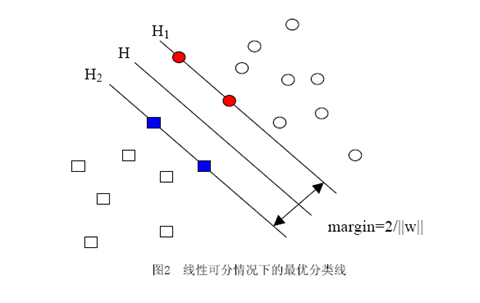
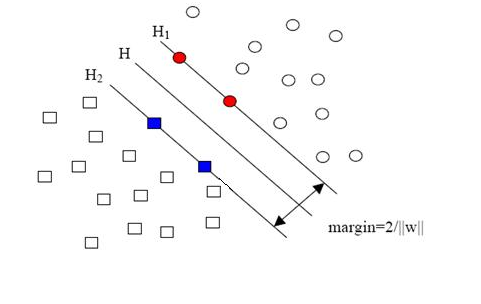
當(dāng)用歸一化的w和b代替原值之后的間隔有一個(gè)專門(mén)的名稱,叫做幾何間隔,幾何間隔所表示的正是點(diǎn)到超平面的歐氏距離,我們下面就簡(jiǎn)稱幾何間隔為“距離”。以上是單個(gè)點(diǎn)到某個(gè)超平面的距離(就是間隔,后面不再區(qū)別這兩個(gè)詞)定義,同樣可以定義一個(gè)點(diǎn)的集合(就是一組樣本)到某個(gè)超平面的距離為此集合中離超平面最近的點(diǎn)的距離。下面這張圖更加直觀的展示出了幾何間隔的現(xiàn)實(shí)含義:
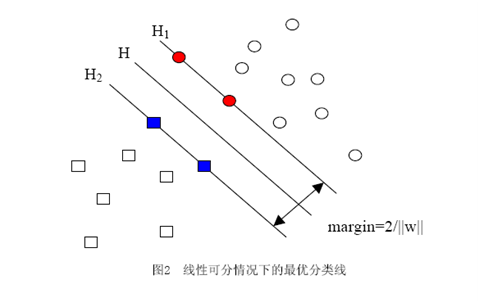
H是分類(lèi)面,而H1和H2是平行于H,且過(guò)離H最近的兩類(lèi)樣本的直線,H1與H,H2與H之間的距離就是幾何間隔。
之所以如此關(guān)心幾何間隔這個(gè)東西,是因?yàn)閹缀伍g隔與樣本的誤分次數(shù)間存在關(guān)系:

其中的δ是樣本集合到分類(lèi)面的間隔,R=max ||xi|| i=1,...,n,即R是所有樣本中(xi是以向量表示的第i個(gè)樣本)向量長(zhǎng)度最長(zhǎng)的值(也就是說(shuō)代表樣本的分布有多么廣)。先不必追究誤分次數(shù)的具體定義和推導(dǎo)過(guò)程,只要記得這個(gè)誤分次數(shù)一定程度上代表分類(lèi)器的誤差。而從上式可以看出,誤分次數(shù)的上界由幾何間隔決定!(當(dāng)然,是樣本已知的時(shí)候)
至此我們就明白為何要選擇幾何間隔來(lái)作為評(píng)價(jià)一個(gè)解優(yōu)劣的指標(biāo)了,原來(lái)幾何間隔越大的解,它的誤差上界越小。因此最大化幾何間隔成了我們訓(xùn)練階段的目標(biāo),而且,與二把刀作者所寫(xiě)的不同,最大化分類(lèi)間隔并不是SVM的專利,而是早在線性分類(lèi)時(shí)期就已有的思想。
SVM入門(mén)(四)線性分類(lèi)器的求解——問(wèn)題的描述Part1
上節(jié)說(shuō)到我們有了一個(gè)線性分類(lèi)函數(shù),也有了判斷解優(yōu)劣的標(biāo)準(zhǔn)——即有了優(yōu)化的目標(biāo),這個(gè)目標(biāo)就是最大化幾何間隔,但是看過(guò)一些關(guān)于SVM的論文的人一定記得什么優(yōu)化的目標(biāo)是要最小化||w||這樣的說(shuō)法,這是怎么回事呢?回頭再看看我們對(duì)間隔和幾何間隔的定義:
間隔:δ=y(wx+b)=|g(x)|
幾何間隔:
可以看出δ=||w||δ幾何。注意到幾何間隔與||w||是成反比的,因此最大化幾何間隔與最小化||w||完全是一回事。而我們常用的方法并不是固定||w||的大小而尋求最大幾何間隔,而是固定間隔(例如固定為1),尋找最小的||w||。
而凡是求一個(gè)函數(shù)的最小值(或最大值)的問(wèn)題都可以稱為尋優(yōu)問(wèn)題(也叫作一個(gè)規(guī)劃問(wèn)題),又由于找最大值的問(wèn)題總可以通過(guò)加一個(gè)負(fù)號(hào)變?yōu)檎易钚≈档膯?wèn)題,因此我們下面討論的時(shí)候都針對(duì)找最小值的過(guò)程來(lái)進(jìn)行。一個(gè)尋優(yōu)問(wèn)題最重要的部分是目標(biāo)函數(shù),顧名思義,就是指尋優(yōu)的目標(biāo)。例如我們想尋找最小的||w||這件事,就可以用下面的式子表示:

但實(shí)際上對(duì)于這個(gè)目標(biāo),我們常常使用另一個(gè)完全等價(jià)的目標(biāo)函數(shù)來(lái)代替,那就是:
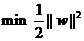 (式1)
(式1)
不難看出當(dāng)||w||2達(dá)到最小時(shí),||w||也達(dá)到最小,反之亦然(前提當(dāng)然是||w||描述的是向量的長(zhǎng)度,因而是非負(fù)的)。之所以采用這種形式,是因?yàn)楹竺娴那蠼膺^(guò)程會(huì)對(duì)目標(biāo)函數(shù)作一系列變換,而式(1)的形式會(huì)使變換后的形式更為簡(jiǎn)潔(正如聰明的讀者所料,添加的系數(shù)二分之一和平方,皆是為求導(dǎo)數(shù)所需)。
接下來(lái)我們自然會(huì)問(wèn)的就是,這個(gè)式子是否就描述了我們的問(wèn)題呢?(回想一下,我們的問(wèn)題是有一堆點(diǎn),可以被分成兩類(lèi),我們要找出最好的分類(lèi)面)
如果直接來(lái)解這個(gè)求最小值問(wèn)題,很容易看出當(dāng)||w||=0的時(shí)候就得到了目標(biāo)函數(shù)的最小值。但是你也會(huì)發(fā)現(xiàn),無(wú)論你給什么樣的數(shù)據(jù),都是這個(gè)解!反映在圖中,就是H1與H2兩條直線間的距離無(wú)限大,這個(gè)時(shí)候,所有的樣本點(diǎn)(無(wú)論正樣本還是負(fù)樣本)都跑到了H1和H2中間,而我們?cè)镜囊鈭D是,H1右側(cè)的被分為正類(lèi),H2 左側(cè)的被分為負(fù)類(lèi),位于兩類(lèi)中間的樣本則拒絕分類(lèi)(拒絕分類(lèi)的另一種理解是分給哪一類(lèi)都有道理,因而分給哪一類(lèi)也都沒(méi)有道理)。這下可好,所有樣本點(diǎn)都進(jìn)入了無(wú)法分類(lèi)的灰色地帶。

造成這種結(jié)果的原因是在描述問(wèn)題的時(shí)候只考慮了目標(biāo),而沒(méi)有加入約束條件,約束條件就是在求解過(guò)程中必須滿足的條件,體現(xiàn)在我們的問(wèn)題中就是樣本點(diǎn)必須在H1或H2的某一側(cè)(或者至少在H1和H2上),而不能跑到兩者中間。我們前文提到過(guò)把間隔固定為1,這是指把所有樣本點(diǎn)中間隔最小的那一點(diǎn)的間隔定為1(這也是集合的間隔的定義,有點(diǎn)繞嘴),也就意味著集合中的其他點(diǎn)間隔都不會(huì)小于1,按照間隔的定義,滿足這些條件就相當(dāng)于讓下面的式子總是成立:
yi[(w·xi)+b]≥1 (i=1,2,…,l) (l是總的樣本數(shù))
但我們常常習(xí)慣讓式子的值和0比較,因而經(jīng)常用變換過(guò)的形式:
yi[(w·xi)+b]-1≥0 (i=1,2,…,l) (l是總的樣本數(shù))
因此我們的兩類(lèi)分類(lèi)問(wèn)題也被我們轉(zhuǎn)化成了它的數(shù)學(xué)形式,一個(gè)帶約束的最小值的問(wèn)題:
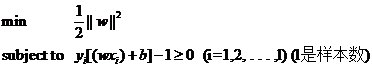
下一節(jié)我們從最一般的意義上看看一個(gè)求最小值的問(wèn)題有何特征,以及如何來(lái)解。
SVM入門(mén)(五)線性分類(lèi)器的求解——問(wèn)題的描述Part2
從最一般的定義上說(shuō),一個(gè)求最小值的問(wèn)題就是一個(gè)優(yōu)化問(wèn)題(也叫尋優(yōu)問(wèn)題,更文縐縐的叫法是規(guī)劃——Programming),它同樣由兩部分組成,目標(biāo)函數(shù)和約束條件,可以用下面的式子表示:
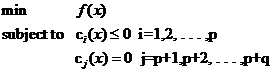 (式1)
(式1)
約束條件用函數(shù)c來(lái)表示,就是constrain的意思啦。你可以看出一共有p+q個(gè)約束條件,其中p個(gè)是不等式約束,q個(gè)等式約束。
關(guān)于這個(gè)式子可以這樣來(lái)理解:式中的x是自變量,但不限定它的維數(shù)必須為1(視乎你解決的問(wèn)題空間維數(shù),對(duì)我們的文本分類(lèi)來(lái)說(shuō),那可是成千上萬(wàn)啊)。要求f(x)在哪一點(diǎn)上取得最小值(反倒不太關(guān)心這個(gè)最小值到底是多少,關(guān)鍵是哪一點(diǎn)),但不是在整個(gè)空間里找,而是在約束條件所劃定的一個(gè)有限的空間里找,這個(gè)有限的空間就是優(yōu)化理論里所說(shuō)的可行域。注意可行域中的每一個(gè)點(diǎn)都要求滿足所有p+q個(gè)條件,而不是滿足其中一條或幾條就可以(切記,要滿足每個(gè)約束),同時(shí)可行域邊界上的點(diǎn)有一個(gè)額外好的特性,它們可以使不等式約束取得等號(hào)!而邊界內(nèi)的點(diǎn)不行。
關(guān)于可行域還有個(gè)概念不得不提,那就是凸集,凸集是指有這么一個(gè)點(diǎn)的集合,其中任取兩個(gè)點(diǎn)連一條直線,這條線上的點(diǎn)仍然在這個(gè)集合內(nèi)部,因此說(shuō)“凸”是很形象的(一個(gè)反例是,二維平面上,一個(gè)月牙形的區(qū)域就不是凸集,你隨便就可以找到兩個(gè)點(diǎn)違反了剛才的規(guī)定)。
回頭再來(lái)看我們線性分類(lèi)器問(wèn)題的描述,可以看出更多的東西。
 (式2)
(式2)
在這個(gè)問(wèn)題中,自變量就是w,而目標(biāo)函數(shù)是w的二次函數(shù),所有的約束條件都是w的線性函數(shù)(哎,千萬(wàn)不要把xi當(dāng)成變量,它代表樣本,是已知的),這種規(guī)劃問(wèn)題有個(gè)很有名氣的稱呼——二次規(guī)劃(Quadratic Programming,QP),而且可以更進(jìn)一步的說(shuō),由于它的可行域是一個(gè)凸集,因此它是一個(gè)凸二次規(guī)劃。
一下子提了這么多術(shù)語(yǔ),實(shí)在不是為了讓大家以后能向別人炫耀學(xué)識(shí)的淵博,這其實(shí)是我們繼續(xù)下去的一個(gè)重要前提,因?yàn)樵趧?dòng)手求一個(gè)問(wèn)題的解之前(好吧,我承認(rèn),是動(dòng)計(jì)算機(jī)求……),我們必須先問(wèn)自己:這個(gè)問(wèn)題是不是有解?如果有解,是否能找到?
對(duì)于一般意義上的規(guī)劃問(wèn)題,兩個(gè)問(wèn)題的答案都是不一定,但凸二次規(guī)劃讓人喜歡的地方就在于,它有解(教科書(shū)里面為了嚴(yán)謹(jǐn),常常加限定成分,說(shuō)它有全局最優(yōu)解,由于我們想找的本來(lái)就是全局最優(yōu)的解,所以不加也罷),而且可以找到!(當(dāng)然,依據(jù)你使用的算法不同,找到這個(gè)解的速度,行話叫收斂速度,會(huì)有所不同)
對(duì)比(式2)和(式1)還可以發(fā)現(xiàn),我們的線性分類(lèi)器問(wèn)題只有不等式約束,因此形式上看似乎比一般意義上的規(guī)劃問(wèn)題要簡(jiǎn)單,但解起來(lái)卻并非如此。
因?yàn)槲覀儗?shí)際上并不知道該怎么解一個(gè)帶約束的優(yōu)化問(wèn)題。如果你仔細(xì)回憶一下高等數(shù)學(xué)的知識(shí),會(huì)記得我們可以輕松的解一個(gè)不帶任何約束的優(yōu)化問(wèn)題(實(shí)際上就是當(dāng)年背得爛熟的函數(shù)求極值嘛,求導(dǎo)再找0點(diǎn)唄,誰(shuí)不會(huì)啊?笑),我們甚至還會(huì)解一個(gè)只帶等式約束的優(yōu)化問(wèn)題,也是背得爛熟的,求條件極值,記得么,通過(guò)添加拉格朗日乘子,構(gòu)造拉格朗日函數(shù),來(lái)把這個(gè)問(wèn)題轉(zhuǎn)化為無(wú)約束的優(yōu)化問(wèn)題云云(如果你一時(shí)沒(méi)想通,我提醒一下,構(gòu)造出的拉格朗日函數(shù)就是轉(zhuǎn)化之后的問(wèn)題形式,它顯然沒(méi)有帶任何條件)。
讀者問(wèn):如果只帶等式約束的問(wèn)題可以轉(zhuǎn)化為無(wú)約束的問(wèn)題而得以求解,那么可不可以把帶不等式約束的問(wèn)題向只帶等式約束的問(wèn)題轉(zhuǎn)化一下而得以求解呢?
聰明,可以,實(shí)際上我們也正是這么做的。下一節(jié)就來(lái)說(shuō)說(shuō)如何做這個(gè)轉(zhuǎn)化,一旦轉(zhuǎn)化完成,求解對(duì)任何學(xué)過(guò)高等數(shù)學(xué)的人來(lái)說(shuō),都是小菜一碟啦。
SVM入門(mén)(六)線性分類(lèi)器的求解——問(wèn)題的轉(zhuǎn)化,直觀角度
讓我再一次比較完整的重復(fù)一下我們要解決的問(wèn)題:我們有屬于兩個(gè)類(lèi)別的樣本點(diǎn)(并不限定這些點(diǎn)在二維空間中)若干,如圖,
圓形的樣本點(diǎn)定為正樣本(連帶著,我們可以把正樣本所屬的類(lèi)叫做正類(lèi)),方形的點(diǎn)定為負(fù)例。我們想求得這樣一個(gè)線性函數(shù)(在n維空間中的線性函數(shù)):
g(x)=wx+b
使得所有屬于正類(lèi)的點(diǎn)![]() +代入以后有g(shù)(x+)≥1,而所有屬于負(fù)類(lèi)的點(diǎn)x-代入后有g(shù)(x-)≤-1(之所以總跟1比較,無(wú)論正一還是負(fù)一,都是因?yàn)槲覀児潭碎g隔為1,注意間隔和幾何間隔的區(qū)別)。代入g(x)后的值如果在1和-1之間,我們就拒絕判斷。
+代入以后有g(shù)(x+)≥1,而所有屬于負(fù)類(lèi)的點(diǎn)x-代入后有g(shù)(x-)≤-1(之所以總跟1比較,無(wú)論正一還是負(fù)一,都是因?yàn)槲覀児潭碎g隔為1,注意間隔和幾何間隔的區(qū)別)。代入g(x)后的值如果在1和-1之間,我們就拒絕判斷。
求這樣的g(x)的過(guò)程就是求w(一個(gè)n維向量)和b(一個(gè)實(shí)數(shù))兩個(gè)參數(shù)的過(guò)程(但實(shí)際上只需要求w,求得以后找某些樣本點(diǎn)代入就可以求得b)。因此在求g(x)的時(shí)候,w才是變量。
你肯定能看出來(lái),一旦求出了w(也就求出了b),那么中間的直線H就知道了(因?yàn)樗褪莣x+b=0嘛,哈哈),那么H1和H2也就知道了(因?yàn)槿呤瞧叫械模蚁喔舻木嚯x還是||w||決定的)。那么w是誰(shuí)決定的?顯然是你給的樣本決定的,一旦你在空間中給出了那些個(gè)樣本點(diǎn),三條直線的位置實(shí)際上就唯一確定了(因?yàn)槲覀兦蟮氖亲顑?yōu)的那三條,當(dāng)然是唯一的),我們解優(yōu)化問(wèn)題的過(guò)程也只不過(guò)是把這個(gè)確定了的東西算出來(lái)而已。
樣本確定了w,用數(shù)學(xué)的語(yǔ)言描述,就是w可以表示為樣本的某種組合:
w=α1x1+α2x2+…+αnxn
式子中的αi是一個(gè)一個(gè)的數(shù)(在嚴(yán)格的證明過(guò)程中,這些α被稱為拉格朗日乘子),而xi是樣本點(diǎn),因而是向量,n就是總樣本點(diǎn)的個(gè)數(shù)。為了方便描述,以下開(kāi)始嚴(yán)格區(qū)別數(shù)字與向量的乘積和向量間的乘積,我會(huì)用α1x1表示數(shù)字和向量的乘積,而用<x1,x2>表示向量x1,x2的內(nèi)積(也叫點(diǎn)積,注意與向量叉積的區(qū)別)。因此g(x)的表達(dá)式嚴(yán)格的形式應(yīng)該是:
g(x)=<w,x>+b
但是上面的式子還不夠好,你回頭看看圖中正樣本和負(fù)樣本的位置,想像一下,我不動(dòng)所有點(diǎn)的位置,而只是把其中一個(gè)正樣本點(diǎn)定為負(fù)樣本點(diǎn)(也就是把一個(gè)點(diǎn)的形狀從圓形變?yōu)榉叫危Y(jié)果怎么樣?三條直線都必須移動(dòng)(因?yàn)閷?duì)這三條直線的要求是必須把方形和圓形的點(diǎn)正確分開(kāi))!這說(shuō)明w不僅跟樣本點(diǎn)的位置有關(guān),還跟樣本的類(lèi)別有關(guān)(也就是和樣本的“標(biāo)簽”有關(guān))。因此用下面這個(gè)式子表示才算完整:
w=α1y1x1+α2y2x2+…+αnynxn (式1)
其中的yi就是第i個(gè)樣本的標(biāo)簽,它等于1或者-1。其實(shí)以上式子的那一堆拉格朗日乘子中,只有很少的一部分不等于0(不等于0才對(duì)w起決定作用),這部分不等于0的拉格朗日乘子后面所乘的樣本點(diǎn),其實(shí)都落在H1和H2上,也正是這部分樣本(而不需要全部樣本)唯一的確定了分類(lèi)函數(shù),當(dāng)然,更嚴(yán)格的說(shuō),這些樣本的一部分就可以確定,因?yàn)槔绱_定一條直線,只需要兩個(gè)點(diǎn)就可以,即便有三五個(gè)都落在上面,我們也不是全都需要。這部分我們真正需要的樣本點(diǎn),就叫做支持(撐)向量!(名字還挺形象吧,他們“撐”起了分界線)
式子也可以用求和符號(hào)簡(jiǎn)寫(xiě)一下:
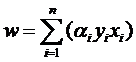
因此原來(lái)的g(x)表達(dá)式可以寫(xiě)為:
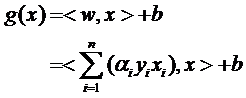
注意式子中x才是變量,也就是你要分類(lèi)哪篇文檔,就把該文檔的向量表示代入到 x的位置,而所有的xi統(tǒng)統(tǒng)都是已知的樣本。還注意到式子中只有xi和x是向量,因此一部分可以從內(nèi)積符號(hào)中拿出來(lái),得到g(x)的式子為:
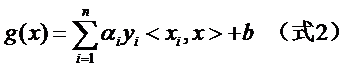
發(fā)現(xiàn)了什么?w不見(jiàn)啦!從求w變成了求α。
但肯定有人會(huì)說(shuō),這并沒(méi)有把原問(wèn)題簡(jiǎn)化呀。嘿嘿,其實(shí)簡(jiǎn)化了,只不過(guò)在你看不見(jiàn)的地方,以這樣的形式描述問(wèn)題以后,我們的優(yōu)化問(wèn)題少了很大一部分不等式約束(記得這是我們解不了極值問(wèn)題的萬(wàn)惡之源)。但是接下來(lái)先跳過(guò)線性分類(lèi)器求解的部分,來(lái)看看 SVM在線性分類(lèi)器上所做的重大改進(jìn)——核函數(shù)。
SVM入門(mén)(七)為何需要核函數(shù)
生存?還是毀滅?——哈姆雷特
可分?還是不可分?——支持向量機(jī)
之前一直在討論的線性分類(lèi)器,器如其名(汗,這是什么說(shuō)法啊),只能對(duì)線性可分的樣本做處理。如果提供的樣本線性不可分,結(jié)果很簡(jiǎn)單,線性分類(lèi)器的求解程序會(huì)無(wú)限循環(huán),永遠(yuǎn)也解不出來(lái)。這必然使得它的適用范圍大大縮小,而它的很多優(yōu)點(diǎn)我們實(shí)在不原意放棄,怎么辦呢?是否有某種方法,讓線性不可分的數(shù)據(jù)變得線性可分呢?
有!其思想說(shuō)來(lái)也簡(jiǎn)單,來(lái)用一個(gè)二維平面中的分類(lèi)問(wèn)題作例子,你一看就會(huì)明白。事先聲明,下面這個(gè)例子是網(wǎng)絡(luò)早就有的,我一時(shí)找不到原作者的正確信息,在此借用,并加進(jìn)了我自己的解說(shuō)而已。
例子是下面這張圖:
/
我們把橫軸上端點(diǎn)a和b之間紅色部分里的所有點(diǎn)定為正類(lèi),兩邊的黑色部分里的點(diǎn)定為負(fù)類(lèi)。試問(wèn)能找到一個(gè)線性函數(shù)把兩類(lèi)正確分開(kāi)么?不能,因?yàn)槎S空間里的線性函數(shù)就是指直線,顯然找不到符合條件的直線。
但我們可以找到一條曲線,例如下面這一條:

顯然通過(guò)點(diǎn)在這條曲線的上方還是下方就可以判斷點(diǎn)所屬的類(lèi)別(你在橫軸上隨便找一點(diǎn),算算這一點(diǎn)的函數(shù)值,會(huì)發(fā)現(xiàn)負(fù)類(lèi)的點(diǎn)函數(shù)值一定比0大,而正類(lèi)的一定比0小)。這條曲線就是我們熟知的二次曲線,它的函數(shù)表達(dá)式可以寫(xiě)為:
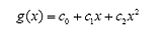
問(wèn)題只是它不是一個(gè)線性函數(shù),但是,下面要注意看了,新建一個(gè)向量y和a:
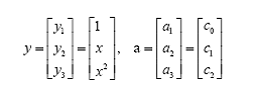
這樣g(x)就可以轉(zhuǎn)化為f(y)=<a,y>,你可以把y和a分別回帶一下,看看等不等于原來(lái)的g(x)。用內(nèi)積的形式寫(xiě)你可能看不太清楚,實(shí)際上f(y)的形式就是:
g(x)=f(y)=ay
在任意維度的空間中,這種形式的函數(shù)都是一個(gè)線性函數(shù)(只不過(guò)其中的a和y都是多維向量罷了),因?yàn)樽宰兞縴的次數(shù)不大于1。
看出妙在哪了么?原來(lái)在二維空間中一個(gè)線性不可分的問(wèn)題,映射到四維空間后,變成了線性可分的!因此這也形成了我們最初想解決線性不可分問(wèn)題的基本思路——向高維空間轉(zhuǎn)化,使其變得線性可分。
而轉(zhuǎn)化最關(guān)鍵的部分就在于找到x到y(tǒng)的映射方法。遺憾的是,如何找到這個(gè)映射,沒(méi)有系統(tǒng)性的方法(也就是說(shuō),純靠猜和湊)。具體到我們的文本分類(lèi)問(wèn)題,文本被表示為上千維的向量,即使維數(shù)已經(jīng)如此之高,也常常是線性不可分的,還要向更高的空間轉(zhuǎn)化。其中的難度可想而知。
小Tips:為什么說(shuō)f(y)=ay是四維空間里的函數(shù)?
大家可能一時(shí)沒(méi)看明白。回想一下我們二維空間里的函數(shù)定義
g(x)=ax+b
變量x是一維的,為什么說(shuō)它是二維空間里的函數(shù)呢?因?yàn)檫€有一個(gè)變量我們沒(méi)寫(xiě)出來(lái),它的完整形式其實(shí)是
y=g(x)=ax+b
即
y=ax+b
看看,有幾個(gè)變量??jī)蓚€(gè)。那是幾維空間的函數(shù)?(作者五歲的弟弟答:五維的。作者:……)
再看看
f(y)=ay
里面的y是三維的變量,那f(y)是幾維空間里的函數(shù)?(作者五歲的弟弟答:還是五維的。作者:……)
用一個(gè)具體文本分類(lèi)的例子來(lái)看看這種向高維空間映射從而分類(lèi)的方法如何運(yùn)作,想象一下,我們文本分類(lèi)問(wèn)題的原始空間是1000維的(即每個(gè)要被分類(lèi)的文檔被表示為一個(gè)1000維的向量),在這個(gè)維度上問(wèn)題是線性不可分的。現(xiàn)在我們有一個(gè)2000維空間里的線性函數(shù)
f(x’)=<w’,x’>+b
注意向量的右上角有個(gè) ’哦。它能夠?qū)⒃瓎?wèn)題變得可分。式中的 w’和x’都是2000維的向量,只不過(guò)w’是定值,而x’是變量(好吧,嚴(yán)格說(shuō)來(lái)這個(gè)函數(shù)是2001維的,哈哈),現(xiàn)在我們的輸入呢,是一個(gè)1000維的向量x,分類(lèi)的過(guò)程是先把x變換為2000維的向量x’,然后求這個(gè)變換后的向量x’與向量w’的內(nèi)積,再把這個(gè)內(nèi)積的值和b相加,就得到了結(jié)果,看結(jié)果大于閾值還是小于閾值就得到了分類(lèi)結(jié)果。
你發(fā)現(xiàn)了什么?我們其實(shí)只關(guān)心那個(gè)高維空間里內(nèi)積的值,那個(gè)值算出來(lái)了,分類(lèi)結(jié)果就算出來(lái)了。而從理論上說(shuō), x’是經(jīng)由x變換來(lái)的,因此廣義上可以把它叫做x的函數(shù)(有一個(gè)x,就確定了一個(gè)x’,對(duì)吧,確定不出第二個(gè)),而w’是常量,它是一個(gè)低維空間里的常量w經(jīng)過(guò)變換得到的,所以給了一個(gè)w 和x的值,就有一個(gè)確定的f(x’)值與其對(duì)應(yīng)。這讓我們幻想,是否能有這樣一種函數(shù)K(w,x),他接受低維空間的輸入值,卻能算出高維空間的內(nèi)積值<w’,x’>?
如果有這樣的函數(shù),那么當(dāng)給了一個(gè)低維空間的輸入x以后,
g(x)=K(w,x)+b
f(x’)=<w’,x’>+b
這兩個(gè)函數(shù)的計(jì)算結(jié)果就完全一樣,我們也就用不著費(fèi)力找那個(gè)映射關(guān)系,直接拿低維的輸入往g(x)里面代就可以了(再次提醒,這回的g(x)就不是線性函數(shù)啦,因?yàn)槟悴荒鼙WCK(w,x)這個(gè)表達(dá)式里的x次數(shù)不高于1哦)。
萬(wàn)幸的是,這樣的K(w,x)確實(shí)存在(發(fā)現(xiàn)凡是我們?nèi)祟?lèi)能解決的問(wèn)題,大都是巧得不能再巧,特殊得不能再特殊的問(wèn)題,總是恰好有些能投機(jī)取巧的地方才能解決,由此感到人類(lèi)的渺小),它被稱作核函數(shù)(核,kernel),而且還不止一個(gè),事實(shí)上,只要是滿足了Mercer條件的函數(shù),都可以作為核函數(shù)。核函數(shù)的基本作用就是接受兩個(gè)低維空間里的向量,能夠計(jì)算出經(jīng)過(guò)某個(gè)變換后在高維空間里的向量?jī)?nèi)積值。幾個(gè)比較常用的核函數(shù),俄,教課書(shū)里都列過(guò),我就不敲了(懶!)。
回想我們上節(jié)說(shuō)的求一個(gè)線性分類(lèi)器,它的形式應(yīng)該是:
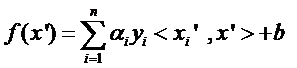
現(xiàn)在這個(gè)就是高維空間里的線性函數(shù)(為了區(qū)別低維和高維空間里的函數(shù)和向量,我改了函數(shù)的名字,并且給w和x都加上了 ’),我們就可以用一個(gè)低維空間里的函數(shù)(再一次的,這個(gè)低維空間里的函數(shù)就不再是線性的啦)來(lái)代替,

又發(fā)現(xiàn)什么了?f(x’) 和g(x)里的α,y,b全都是一樣一樣的!這就是說(shuō),盡管給的問(wèn)題是線性不可分的,但是我們就硬當(dāng)它是線性問(wèn)題來(lái)求解,只不過(guò)求解過(guò)程中,凡是要求內(nèi)積的時(shí)候就用你選定的核函數(shù)來(lái)算。這樣求出來(lái)的α再和你選定的核函數(shù)一組合,就得到分類(lèi)器啦!
明白了以上這些,會(huì)自然的問(wèn)接下來(lái)兩個(gè)問(wèn)題:
1. 既然有很多的核函數(shù),針對(duì)具體問(wèn)題該怎么選擇?
2. 如果使用核函數(shù)向高維空間映射后,問(wèn)題仍然是線性不可分的,那怎么辦?
第一個(gè)問(wèn)題現(xiàn)在就可以回答你:對(duì)核函數(shù)的選擇,現(xiàn)在還缺乏指導(dǎo)原則!各種實(shí)驗(yàn)的觀察結(jié)果(不光是文本分類(lèi))的確表明,某些問(wèn)題用某些核函數(shù)效果很好,用另一些就很差,但是一般來(lái)講,徑向基核函數(shù)是不會(huì)出太大偏差的一種,首選。(我做文本分類(lèi)系統(tǒng)的時(shí)候,使用徑向基核函數(shù),沒(méi)有參數(shù)調(diào)優(yōu)的情況下,絕大部分類(lèi)別的準(zhǔn)確和召回都在85%以上,可見(jiàn)。雖然libSVM的作者林智仁認(rèn)為文本分類(lèi)用線性核函數(shù)效果更佳,待考證)
對(duì)第二個(gè)問(wèn)題的解決則引出了我們下一節(jié)的主題:松弛變量。
SVM入門(mén)(八)松弛變量
現(xiàn)在我們已經(jīng)把一個(gè)本來(lái)線性不可分的文本分類(lèi)問(wèn)題,通過(guò)映射到高維空間而變成了線性可分的。就像下圖這樣:
圓形和方形的點(diǎn)各有成千上萬(wàn)個(gè)(畢竟,這就是我們訓(xùn)練集中文檔的數(shù)量嘛,當(dāng)然很大了)。現(xiàn)在想象我們有另一個(gè)訓(xùn)練集,只比原先這個(gè)訓(xùn)練集多了一篇文章,映射到高維空間以后(當(dāng)然,也使用了相同的核函數(shù)),也就多了一個(gè)樣本點(diǎn),但是這個(gè)樣本的位置是這樣的:
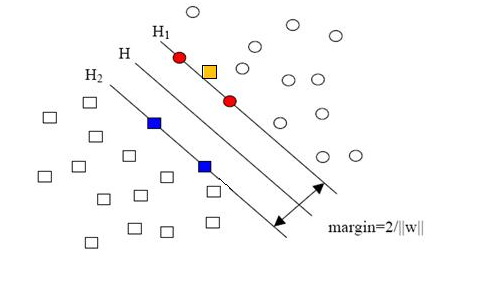
就是圖中黃色那個(gè)點(diǎn),它是方形的,因而它是負(fù)類(lèi)的一個(gè)樣本,這單獨(dú)的一個(gè)樣本,使得原本線性可分的問(wèn)題變成了線性不可分的。這樣類(lèi)似的問(wèn)題(僅有少數(shù)點(diǎn)線性不可分)叫做“近似線性可分”的問(wèn)題。
以我們?nèi)祟?lèi)的常識(shí)來(lái)判斷,說(shuō)有一萬(wàn)個(gè)點(diǎn)都符合某種規(guī)律(因而線性可分),有一個(gè)點(diǎn)不符合,那這一個(gè)點(diǎn)是否就代表了分類(lèi)規(guī)則中我們沒(méi)有考慮到的方面呢(因而規(guī)則應(yīng)該為它而做出修改)?
其實(shí)我們會(huì)覺(jué)得,更有可能的是,這個(gè)樣本點(diǎn)壓根就是錯(cuò)誤,是噪聲,是提供訓(xùn)練集的同學(xué)人工分類(lèi)時(shí)一打瞌睡錯(cuò)放進(jìn)去的。所以我們會(huì)簡(jiǎn)單的忽略這個(gè)樣本點(diǎn),仍然使用原來(lái)的分類(lèi)器,其效果絲毫不受影響。
但這種對(duì)噪聲的容錯(cuò)性是人的思維帶來(lái)的,我們的程序可沒(méi)有。由于我們?cè)镜膬?yōu)化問(wèn)題的表達(dá)式中,確實(shí)要考慮所有的樣本點(diǎn)(不能忽略某一個(gè),因?yàn)槌绦蛩趺粗涝摵雎阅囊粋€(gè)呢?),在此基礎(chǔ)上尋找正負(fù)類(lèi)之間的最大幾何間隔,而幾何間隔本身代表的是距離,是非負(fù)的,像上面這種有噪聲的情況會(huì)使得整個(gè)問(wèn)題無(wú)解。這種解法其實(shí)也叫做“硬間隔”分類(lèi)法,因?yàn)樗残缘囊笏袠颖军c(diǎn)都滿足和分類(lèi)平面間的距離必須大于某個(gè)值。
因此由上面的例子中也可以看出,硬間隔的分類(lèi)法其結(jié)果容易受少數(shù)點(diǎn)的控制,這是很危險(xiǎn)的(盡管有句話說(shuō)真理總是掌握在少數(shù)人手中,但那不過(guò)是那一小撮人聊以自慰的詞句罷了,咱還是得民主)。
但解決方法也很明顯,就是仿照人的思路,允許一些點(diǎn)到分類(lèi)平面的距離不滿足原先的要求。由于不同的訓(xùn)練集各點(diǎn)的間距尺度不太一樣,因此用間隔(而不是幾何間隔)來(lái)衡量有利于我們表達(dá)形式的簡(jiǎn)潔。我們?cè)葘?duì)樣本點(diǎn)的要求是:

意思是說(shuō)離分類(lèi)面最近的樣本點(diǎn)函數(shù)間隔也要比1大。如果要引入容錯(cuò)性,就給1這個(gè)硬性的閾值加一個(gè)松弛變量,即允許
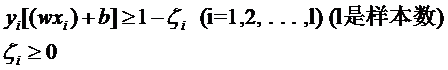
因?yàn)樗沙谧兞渴欠秦?fù)的,因此最終的結(jié)果是要求間隔可以比1小。但是當(dāng)某些點(diǎn)出現(xiàn)這種間隔比1小的情況時(shí)(這些點(diǎn)也叫離群點(diǎn)),意味著我們放棄了對(duì)這些點(diǎn)的精確分類(lèi),而這對(duì)我們的分類(lèi)器來(lái)說(shuō)是種損失。但是放棄這些點(diǎn)也帶來(lái)了好處,那就是使分類(lèi)面不必向這些點(diǎn)的方向移動(dòng),因而可以得到更大的幾何間隔(在低維空間看來(lái),分類(lèi)邊界也更平滑)。顯然我們必須權(quán)衡這種損失和好處。好處很明顯,我們得到的分類(lèi)間隔越大,好處就越多。回顧我們?cè)嫉挠查g隔分類(lèi)對(duì)應(yīng)的優(yōu)化問(wèn)題:

||w||2就是我們的目標(biāo)函數(shù)(當(dāng)然系數(shù)可有可無(wú)),希望它越小越好,因而損失就必然是一個(gè)能使之變大的量(能使它變小就不叫損失了,我們本來(lái)就希望目標(biāo)函數(shù)值越小越好)。那如何來(lái)衡量損失,有兩種常用的方式,有人喜歡用
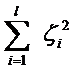
而有人喜歡用
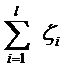
其中l(wèi)都是樣本的數(shù)目。兩種方法沒(méi)有大的區(qū)別。如果選擇了第一種,得到的方法的就叫做二階軟間隔分類(lèi)器,第二種就叫做一階軟間隔分類(lèi)器。把損失加入到目標(biāo)函數(shù)里的時(shí)候,就需要一個(gè)懲罰因子(cost,也就是libSVM的諸多參數(shù)中的C),原來(lái)的優(yōu)化問(wèn)題就變成了下面這樣:
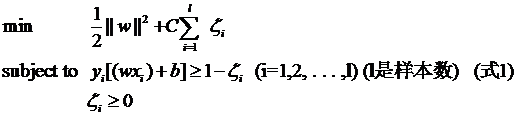
這個(gè)式子有這么幾點(diǎn)要注意:
一是并非所有的樣本點(diǎn)都有一個(gè)松弛變量與其對(duì)應(yīng)。實(shí)際上只有“離群點(diǎn)”才有,或者也可以這么看,所有沒(méi)離群的點(diǎn)松弛變量都等于0(對(duì)負(fù)類(lèi)來(lái)說(shuō),離群點(diǎn)就是在前面圖中,跑到H2右側(cè)的那些負(fù)樣本點(diǎn),對(duì)正類(lèi)來(lái)說(shuō),就是跑到H1左側(cè)的那些正樣本點(diǎn))。
【在迭代求w的時(shí)候如何樣本點(diǎn)非離群點(diǎn),即分類(lèi)正確,那么就設(shè)它的松弛變量為0了。。。】
二是松弛變量的值實(shí)際上標(biāo)示出了對(duì)應(yīng)的點(diǎn)到底離群有多遠(yuǎn),值越大,點(diǎn)就越遠(yuǎn)。
三是懲罰因子C決定了你有多重視離群點(diǎn)帶來(lái)的損失,顯然當(dāng)所有離群點(diǎn)的松弛變量的和一定時(shí),你定的C越大,對(duì)目標(biāo)函數(shù)的損失也越大,此時(shí)就暗示著你非常不愿意放棄這些離群點(diǎn),最極端的情況是你把C定為無(wú)限大,這樣只要稍有一個(gè)點(diǎn)離群,目標(biāo)函數(shù)的值馬上變成無(wú)限大,馬上讓問(wèn)題變成無(wú)解,這就退化成了硬間隔問(wèn)題。
四是懲罰因子C不是一個(gè)變量,整個(gè)優(yōu)化問(wèn)題在解的時(shí)候,C是一個(gè)你必須事先指定的值,指定這個(gè)值以后,解一下,得到一個(gè)分類(lèi)器,然后用測(cè)試數(shù)據(jù)看看結(jié)果怎么樣,如果不夠好,換一個(gè)C的值,再解一次優(yōu)化問(wèn)題,得到另一個(gè)分類(lèi)器,再看看效果,如此就是一個(gè)參數(shù)尋優(yōu)的過(guò)程,但這和優(yōu)化問(wèn)題本身決不是一回事,優(yōu)化問(wèn)題在解的過(guò)程中,C一直是定值,要記住。
五是盡管加了松弛變量這么一說(shuō),但這個(gè)優(yōu)化問(wèn)題仍然是一個(gè)優(yōu)化問(wèn)題(汗,這不廢話么),解它的過(guò)程比起原始的硬間隔問(wèn)題來(lái)說(shuō),沒(méi)有任何更加特殊的地方。
從大的方面說(shuō)優(yōu)化問(wèn)題解的過(guò)程,就是先試著確定一下w,也就是確定了前面圖中的三條直線,這時(shí)看看間隔有多大,又有多少點(diǎn)離群,把目標(biāo)函數(shù)的值算一算,再換一組三條直線(你可以看到,分類(lèi)的直線位置如果移動(dòng)了,有些原來(lái)離群的點(diǎn)會(huì)變得不再離群,而有的本來(lái)不離群的點(diǎn)會(huì)變成離群點(diǎn)),再把目標(biāo)函數(shù)的值算一算,如此往復(fù)(迭代),直到最終找到目標(biāo)函數(shù)最小時(shí)的w。
啰嗦了這么多,讀者一定可以馬上自己總結(jié)出來(lái),松弛變量也就是個(gè)解決線性不可分問(wèn)題的方法罷了,但是回想一下,核函數(shù)的引入不也是為了解決線性不可分的問(wèn)題么?為什么要為了一個(gè)問(wèn)題使用兩種方法呢?
其實(shí)兩者還有微妙的不同。一般的過(guò)程應(yīng)該是這樣,還以文本分類(lèi)為例。在原始的低維空間中,樣本相當(dāng)?shù)牟豢煞郑瑹o(wú)論你怎么找分類(lèi)平面,總會(huì)有大量的離群點(diǎn),此時(shí)用核函數(shù)向高維空間映射一下,雖然結(jié)果仍然是不可分的,但比原始空間里的要更加接近線性可分的狀態(tài)(就是達(dá)到了近似線性可分的狀態(tài)),此時(shí)再用松弛變量處理那些少數(shù)“冥頑不化”的離群點(diǎn),就簡(jiǎn)單有效得多啦。
本節(jié)中的(式1)也確實(shí)是支持向量機(jī)最最常用的形式。至此一個(gè)比較完整的支持向量機(jī)框架就有了,簡(jiǎn)單說(shuō)來(lái),支持向量機(jī)就是使用了核函數(shù)的軟間隔線性分類(lèi)法。
下一節(jié)會(huì)說(shuō)說(shuō)松弛變量剩下的一點(diǎn)點(diǎn)東西,順便搞個(gè)讀者調(diào)查,看看大家還想侃侃SVM的哪些方面。
SVM入門(mén)(九)松弛變量(續(xù))
接下來(lái)要說(shuō)的東西其實(shí)不是松弛變量本身,但由于是為了使用松弛變量才引入的,因此放在這里也算合適,那就是懲罰因子C。回頭看一眼引入了松弛變量以后的優(yōu)化問(wèn)題:
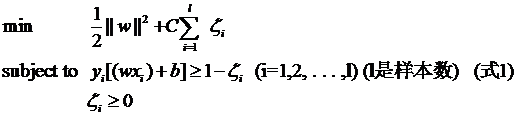
注意其中C的位置,也可以回想一下C所起的作用(表征你有多么重視離群點(diǎn),C越大越重視,越不想丟掉它們)。這個(gè)式子是以前做SVM的人寫(xiě)的,大家也就這么用,但沒(méi)有任何規(guī)定說(shuō)必須對(duì)所有的松弛變量都使用同一個(gè)懲罰因子,我們完全可以給每一個(gè)離群點(diǎn)都使用不同的C,這時(shí)就意味著你對(duì)每個(gè)樣本的重視程度都不一樣,有些樣本丟了也就丟了,錯(cuò)了也就錯(cuò)了,這些就給一個(gè)比較小的C;而有些樣本很重要,決不能分類(lèi)錯(cuò)誤(比如中央下達(dá)的文件啥的,笑),就給一個(gè)很大的C。
當(dāng)然實(shí)際使用的時(shí)候并沒(méi)有這么極端,但一種很常用的變形可以用來(lái)解決分類(lèi)問(wèn)題中樣本的“偏斜”問(wèn)題。
先來(lái)說(shuō)說(shuō)樣本的偏斜問(wèn)題,也叫數(shù)據(jù)集偏斜(unbalanced),它指的是參與分類(lèi)的兩個(gè)類(lèi)別(也可以指多個(gè)類(lèi)別)樣本數(shù)量差異很大。比如說(shuō)正類(lèi)有10,000個(gè)樣本,而負(fù)類(lèi)只給了100個(gè),這會(huì)引起的問(wèn)題顯而易見(jiàn),可以看看下面的圖:
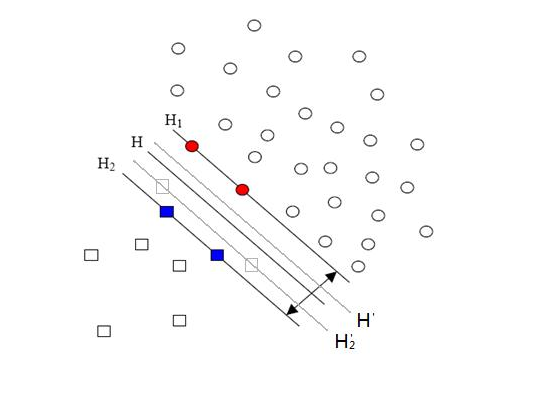
方形的點(diǎn)是負(fù)類(lèi)。H,H1,H2是根據(jù)給的樣本算出來(lái)的分類(lèi)面,由于負(fù)類(lèi)的樣本很少很少,所以有一些本來(lái)是負(fù)類(lèi)的樣本點(diǎn)沒(méi)有提供,比如圖中兩個(gè)灰色的方形點(diǎn),如果這兩個(gè)點(diǎn)有提供的話,那算出來(lái)的分類(lèi)面應(yīng)該是H’,H2’和H1,他們顯然和之前的結(jié)果有出入,實(shí)際上負(fù)類(lèi)給的樣本點(diǎn)越多,就越容易出現(xiàn)在灰色點(diǎn)附近的點(diǎn),我們算出的結(jié)果也就越接近于真實(shí)的分類(lèi)面。但現(xiàn)在由于偏斜的現(xiàn)象存在,使得數(shù)量多的正類(lèi)可以把分類(lèi)面向負(fù)類(lèi)的方向“推”,因而影響了結(jié)果的準(zhǔn)確性。
對(duì)付數(shù)據(jù)集偏斜問(wèn)題的方法之一就是在懲罰因子上作文章,想必大家也猜到了,那就是給樣本數(shù)量少的負(fù)類(lèi)更大的懲罰因子,表示我們重視這部分樣本(本來(lái)數(shù)量就少,再拋棄一些,那人家負(fù)類(lèi)還活不活了),因此我們的目標(biāo)函數(shù)中因松弛變量而損失的部分就變成了:

其中i=1…p都是正樣本,j=p+1…p+q都是負(fù)樣本。libSVM這個(gè)算法包在解決偏斜問(wèn)題的時(shí)候用的就是這種方法。
那C+和C-怎么確定呢?它們的大小是試出來(lái)的(參數(shù)調(diào)優(yōu)),但是他們的比例可以有些方法來(lái)確定。咱們先假定說(shuō)C+是5這么大,那確定C-的一個(gè)很直觀的方法就是使用兩類(lèi)樣本數(shù)的比來(lái)算,對(duì)應(yīng)到剛才舉的例子,C-就可以定為500這么大(因?yàn)?0,000:100=100:1嘛)。
但是這樣并不夠好,回看剛才的圖,你會(huì)發(fā)現(xiàn)正類(lèi)之所以可以“欺負(fù)”負(fù)類(lèi),其實(shí)并不是因?yàn)樨?fù)類(lèi)樣本少,真實(shí)的原因是負(fù)類(lèi)的樣本分布的不夠廣(沒(méi)擴(kuò)充到負(fù)類(lèi)本應(yīng)該有的區(qū)域)。說(shuō)一個(gè)具體點(diǎn)的例子,現(xiàn)在想給政治類(lèi)和體育類(lèi)的文章做分類(lèi),政治類(lèi)文章很多,而體育類(lèi)只提供了幾篇關(guān)于籃球的文章,這時(shí)分類(lèi)會(huì)明顯偏向于政治類(lèi),如果要給體育類(lèi)文章增加樣本,但增加的樣本仍然全都是關(guān)于籃球的(也就是說(shuō),沒(méi)有足球,排球,賽車(chē),游泳等等),那結(jié)果會(huì)怎樣呢?雖然體育類(lèi)文章在數(shù)量上可以達(dá)到與政治類(lèi)一樣多,但過(guò)于集中了,結(jié)果仍會(huì)偏向于政治類(lèi)!所以給C+和C-確定比例更好的方法應(yīng)該是衡量他們分布的程度。比如可以算算他們?cè)诳臻g中占據(jù)了多大的體積,例如給負(fù)類(lèi)找一個(gè)超球——就是高維空間里的球啦——它可以包含所有負(fù)類(lèi)的樣本,再給正類(lèi)找一個(gè),比比兩個(gè)球的半徑,就可以大致確定分布的情況。顯然半徑大的分布就比較廣,就給小一點(diǎn)的懲罰因子。
但是這樣還不夠好,因?yàn)橛械念?lèi)別樣本確實(shí)很集中,這不是提供的樣本數(shù)量多少的問(wèn)題,這是類(lèi)別本身的特征(就是某些話題涉及的面很窄,例如計(jì)算機(jī)類(lèi)的文章就明顯不如文化類(lèi)的文章那么“天馬行空”),這個(gè)時(shí)候即便超球的半徑差異很大,也不應(yīng)該賦予兩個(gè)類(lèi)別不同的懲罰因子。
看到這里讀者一定瘋了,因?yàn)檎f(shuō)來(lái)說(shuō)去,這豈不成了一個(gè)解決不了的問(wèn)題?然而事實(shí)如此,完全的方法是沒(méi)有的,根據(jù)需要,選擇實(shí)現(xiàn)簡(jiǎn)單又合用的就好(例如libSVM就直接使用樣本數(shù)量的比)。
SVM入門(mén)(十)將SVM用于多類(lèi)分類(lèi)
從 SVM的那幾張圖可以看出來(lái),SVM是一種典型的兩類(lèi)分類(lèi)器,即它只回答屬于正類(lèi)還是負(fù)類(lèi)的問(wèn)題。而現(xiàn)實(shí)中要解決的問(wèn)題,往往是多類(lèi)的問(wèn)題(少部分例外,例如垃圾郵件過(guò)濾,就只需要確定“是”還是“不是”垃圾郵件),比如文本分類(lèi),比如數(shù)字識(shí)別。如何由兩類(lèi)分類(lèi)器得到多類(lèi)分類(lèi)器,就是一個(gè)值得研究的問(wèn)題。
還以文本分類(lèi)為例,現(xiàn)成的方法有很多,其中一種一勞永逸的方法,就是真的一次性考慮所有樣本,并求解一個(gè)多目標(biāo)函數(shù)的優(yōu)化問(wèn)題,一次性得到多個(gè)分類(lèi)面,就像下圖這樣:
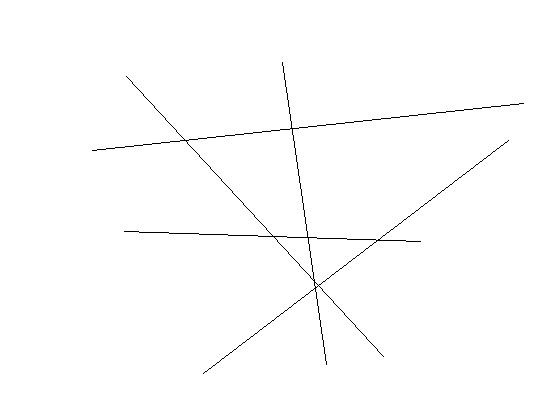
多個(gè)超平面把空間劃分為多個(gè)區(qū)域,每個(gè)區(qū)域?qū)?yīng)一個(gè)類(lèi)別,給一篇文章,看它落在哪個(gè)區(qū)域就知道了它的分類(lèi)。
看起來(lái)很美對(duì)不對(duì)?只可惜這種算法還基本停留在紙面上,因?yàn)橐淮涡郧蠼獾姆椒ㄓ?jì)算量實(shí)在太大,大到無(wú)法實(shí)用的地步。
稍稍退一步,我們就會(huì)想到所謂“一類(lèi)對(duì)其余”的方法,就是每次仍然解一個(gè)兩類(lèi)分類(lèi)的問(wèn)題。比如我們有5個(gè)類(lèi)別,第一次就把類(lèi)別1的樣本定為正樣本,其余2,3,4,5的樣本合起來(lái)定為負(fù)樣本,這樣得到一個(gè)兩類(lèi)分類(lèi)器,它能夠指出一篇文章是還是不是第1類(lèi)的;第二次我們把類(lèi)別2 的樣本定為正樣本,把1,3,4,5的樣本合起來(lái)定為負(fù)樣本,得到一個(gè)分類(lèi)器,如此下去,我們可以得到5個(gè)這樣的兩類(lèi)分類(lèi)器(總是和類(lèi)別的數(shù)目一致)。到了有文章需要分類(lèi)的時(shí)候,我們就拿著這篇文章挨個(gè)分類(lèi)器的問(wèn):是屬于你的么?是屬于你的么?哪個(gè)分類(lèi)器點(diǎn)頭說(shuō)是了,文章的類(lèi)別就確定了。這種方法的好處是每個(gè)優(yōu)化問(wèn)題的規(guī)模比較小,而且分類(lèi)的時(shí)候速度很快(只需要調(diào)用5個(gè)分類(lèi)器就知道了結(jié)果)。但有時(shí)也會(huì)出現(xiàn)兩種很尷尬的情況,例如拿一篇文章問(wèn)了一圈,每一個(gè)分類(lèi)器都說(shuō)它是屬于它那一類(lèi)的,或者每一個(gè)分類(lèi)器都說(shuō)它不是它那一類(lèi)的,前者叫分類(lèi)重疊現(xiàn)象,后者叫不可分類(lèi)現(xiàn)象。分類(lèi)重疊倒還好辦,隨便選一個(gè)結(jié)果都不至于太離譜,或者看看這篇文章到各個(gè)超平面的距離,哪個(gè)遠(yuǎn)就判給哪個(gè)。不可分類(lèi)現(xiàn)象就著實(shí)難辦了,只能把它分給第6個(gè)類(lèi)別了……更要命的是,本來(lái)各個(gè)類(lèi)別的樣本數(shù)目是差不多的,但“其余”的那一類(lèi)樣本數(shù)總是要數(shù)倍于正類(lèi)(因?yàn)樗浅?lèi)以外其他類(lèi)別的樣本之和嘛),這就人為的造成了上一節(jié)所說(shuō)的“數(shù)據(jù)集偏斜”問(wèn)題。
因此我們還得再退一步,還是解兩類(lèi)分類(lèi)問(wèn)題,還是每次選一個(gè)類(lèi)的樣本作正類(lèi)樣本,而負(fù)類(lèi)樣本則變成只選一個(gè)類(lèi)(稱為“一對(duì)一單挑”的方法,哦,不對(duì),沒(méi)有單挑,就是“一對(duì)一”的方法,呵呵),這就避免了偏斜。因此過(guò)程就是算出這樣一些分類(lèi)器,第一個(gè)只回答“是第1類(lèi)還是第2類(lèi)”,第二個(gè)只回答“是第1類(lèi)還是第3類(lèi)”,第三個(gè)只回答“是第1類(lèi)還是第4類(lèi)”,如此下去,你也可以馬上得出,這樣的分類(lèi)器應(yīng)該有5 X 4/2=10個(gè)(通式是,如果有k個(gè)類(lèi)別,則總的兩類(lèi)分類(lèi)器數(shù)目為k(k-1)/2)。雖然分類(lèi)器的數(shù)目多了,但是在訓(xùn)練階段(也就是算出這些分類(lèi)器的分類(lèi)平面時(shí))所用的總時(shí)間卻比“一類(lèi)對(duì)其余”方法少很多,在真正用來(lái)分類(lèi)的時(shí)候,把一篇文章扔給所有分類(lèi)器,第一個(gè)分類(lèi)器會(huì)投票說(shuō)它是“1”或者“2”,第二個(gè)會(huì)說(shuō)它是“1”或者“3”,讓每一個(gè)都投上自己的一票,最后統(tǒng)計(jì)票數(shù),如果類(lèi)別“1”得票最多,就判這篇文章屬于第1類(lèi)。這種方法顯然也會(huì)有分類(lèi)重疊的現(xiàn)象,但不會(huì)有不可分類(lèi)現(xiàn)象,因?yàn)榭偛豢赡芩蓄?lèi)別的票數(shù)都是0。看起來(lái)夠好么?其實(shí)不然,想想分類(lèi)一篇文章,我們調(diào)用了多少個(gè)分類(lèi)器?10個(gè),這還是類(lèi)別數(shù)為5的時(shí)候,類(lèi)別數(shù)如果是1000,要調(diào)用的分類(lèi)器數(shù)目會(huì)上升至約500,000個(gè)(類(lèi)別數(shù)的平方量級(jí))。這如何是好?
看來(lái)我們必須再退一步,在分類(lèi)的時(shí)候下功夫,我們還是像一對(duì)一方法那樣來(lái)訓(xùn)練,只是在對(duì)一篇文章進(jìn)行分類(lèi)之前,我們先按照下面圖的樣子來(lái)組織分類(lèi)器(如你所見(jiàn),這是一個(gè)有向無(wú)環(huán)圖,因此這種方法也叫做DAG SVM)

這樣在分類(lèi)時(shí),我們就可以先問(wèn)分類(lèi)器“1對(duì)5”(意思是它能夠回答“是第1類(lèi)還是第5類(lèi)”),如果它回答5,我們就往左走,再問(wèn)“2對(duì)5”這個(gè)分類(lèi)器,如果它還說(shuō)是“5”,我們就繼續(xù)往左走,這樣一直問(wèn)下去,就可以得到分類(lèi)結(jié)果。好處在哪?我們其實(shí)只調(diào)用了4個(gè)分類(lèi)器(如果類(lèi)別數(shù)是k,則只調(diào)用k-1個(gè)),分類(lèi)速度飛快,且沒(méi)有分類(lèi)重疊和不可分類(lèi)現(xiàn)象!缺點(diǎn)在哪?假如最一開(kāi)始的分類(lèi)器回答錯(cuò)誤(明明是類(lèi)別1的文章,它說(shuō)成了5),那么后面的分類(lèi)器是無(wú)論如何也無(wú)法糾正它的錯(cuò)誤的(因?yàn)楹竺娴姆诸?lèi)器壓根沒(méi)有出現(xiàn)“1”這個(gè)類(lèi)別標(biāo)簽),其實(shí)對(duì)下面每一層的分類(lèi)器都存在這種錯(cuò)誤向下累積的現(xiàn)象。。
不過(guò)不要被DAG方法的錯(cuò)誤累積嚇倒,錯(cuò)誤累積在一對(duì)其余和一對(duì)一方法中也都存在,DAG方法好于它們的地方就在于,累積的上限,不管是大是小,總是有定論的,有理論證明。而一對(duì)其余和一對(duì)一方法中,盡管每一個(gè)兩類(lèi)分類(lèi)器的泛化誤差限是知道的,但是合起來(lái)做多類(lèi)分類(lèi)的時(shí)候,誤差上界是多少,沒(méi)人知道,這意味著準(zhǔn)確率低到0也是有可能的,這多讓人郁悶。
而且現(xiàn)在DAG方法根節(jié)點(diǎn)的選取(也就是如何選第一個(gè)參與分類(lèi)的分類(lèi)器),也有一些方法可以改善整體效果,我們總希望根節(jié)點(diǎn)少犯錯(cuò)誤為好,因此參與第一次分類(lèi)的兩個(gè)類(lèi)別,最好是差別特別特別大,大到以至于不太可能把他們分錯(cuò);或者我們就總?cè)≡趦深?lèi)分類(lèi)中正確率最高的那個(gè)分類(lèi)器作根節(jié)點(diǎn),或者我們讓兩類(lèi)分類(lèi)器在分類(lèi)的時(shí)候,不光輸出類(lèi)別的標(biāo)簽,還輸出一個(gè)類(lèi)似“置信度”的東東,當(dāng)它對(duì)自己的結(jié)果不太自信的時(shí)候,我們就不光按照它的輸出走,把它旁邊的那條路也走一走,等等。
大Tips:SVM的計(jì)算復(fù)雜度
使用SVM進(jìn)行分類(lèi)的時(shí)候,實(shí)際上是訓(xùn)練和分類(lèi)兩個(gè)完全不同的過(guò)程,因而討論復(fù)雜度就不能一概而論,我們這里所說(shuō)的主要是訓(xùn)練階段的復(fù)雜度,即解那個(gè)二次規(guī)劃問(wèn)題的復(fù)雜度。對(duì)這個(gè)問(wèn)題的解,基本上要?jiǎng)澐譃閮纱髩K,解析解和數(shù)值解。
解析解就是理論上的解,它的形式是表達(dá)式,因此它是精確的,一個(gè)問(wèn)題只要有解(無(wú)解的問(wèn)題還跟著摻和什么呀,哈哈),那它的解析解是一定存在的。當(dāng)然存在是一回事,能夠解出來(lái),或者可以在可以承受的時(shí)間范圍內(nèi)解出來(lái),就是另一回事了。對(duì)SVM來(lái)說(shuō),求得解析解的時(shí)間復(fù)雜度最壞可以達(dá)到O(Nsv3),其中Nsv是支持向量的個(gè)數(shù),而雖然沒(méi)有固定的比例,但支持向量的個(gè)數(shù)多少也和訓(xùn)練集的大小有關(guān)。
數(shù)值解就是可以使用的解,是一個(gè)一個(gè)的數(shù),往往都是近似解。求數(shù)值解的過(guò)程非常像窮舉法,從一個(gè)數(shù)開(kāi)始,試一試它當(dāng)解效果怎樣,不滿足一定條件(叫做停機(jī)條件,就是滿足這個(gè)以后就認(rèn)為解足夠精確了,不需要繼續(xù)算下去了)就試下一個(gè),當(dāng)然下一個(gè)數(shù)不是亂選的,也有一定章法可循。有的算法,每次只嘗試一個(gè)數(shù),有的就嘗試多個(gè),而且找下一個(gè)數(shù)字(或下一組數(shù))的方法也各不相同,停機(jī)條件也各不相同,最終得到的解精度也各不相同,可見(jiàn)對(duì)求數(shù)值解的復(fù)雜度的討論不能脫開(kāi)具體的算法。
一個(gè)具體的算法,Bunch-Kaufman訓(xùn)練算法,典型的時(shí)間復(fù)雜度在O(Nsv3+LNsv2+dLNsv)和O(dL2)之間,其中Nsv是支持向量的個(gè)數(shù),L是訓(xùn)練集樣本的個(gè)數(shù),d是每個(gè)樣本的維數(shù)(原始的維數(shù),沒(méi)有經(jīng)過(guò)向高維空間映射之前的維數(shù))。復(fù)雜度會(huì)有變化,是因?yàn)樗还飧斎雴?wèn)題的規(guī)模有關(guān)(不光和樣本的數(shù)量,維數(shù)有關(guān)),也和問(wèn)題最終的解有關(guān)(即支持向量有關(guān)),如果支持向量比較少,過(guò)程會(huì)快很多,如果支持向量很多,接近于樣本的數(shù)量,就會(huì)產(chǎn)生O(dL2)這個(gè)十分糟糕的結(jié)果(給10,000個(gè)樣本,每個(gè)樣本1000維,基本就不用算了,算不出來(lái),呵呵,而這種輸入規(guī)模對(duì)文本分類(lèi)來(lái)說(shuō)太正常了)。
這樣再回頭看就會(huì)明白為什么一對(duì)一方法盡管要訓(xùn)練的兩類(lèi)分類(lèi)器數(shù)量多,但總時(shí)間實(shí)際上比一對(duì)其余方法要少了,因?yàn)橐粚?duì)其余方法每次訓(xùn)練都考慮了所有樣本(只是每次把不同的部分劃分為正類(lèi)或者負(fù)類(lèi)而已),自然慢上很多。