作為一個軟件開發者,你一定會對網絡應用如何工作有一個完整的層次化的認知,同樣這里也包括這些應用所用到的技術:像瀏覽器,HTTP,HTML,網絡服務器,需求處理等等。
本文將更深入的研究當你輸入一個網址的時候,后臺到底發生了一件件什么樣的事~
1. 首先嘛,你得在瀏覽器里輸入要網址:

2. 瀏覽器查找域名的IP地址

導航的第一步是通過訪問的域名找出其IP地址。DNS查找過程如下:
- 瀏覽器緩存 – 瀏覽器會緩存DNS記錄一段時間。 有趣的是,操作系統沒有告訴瀏覽器儲存DNS記錄的時間,這樣不同瀏覽器會儲存個自固定的一個時間(2分鐘到30分鐘不等)。
- 系統緩存 – 如果在瀏覽器緩存里沒有找到需要的記錄,瀏覽器會做一個系統調用(windows里是gethostbyname)。這樣便可獲得系統緩存中的記錄。
- 路由器緩存 – 接著,前面的查詢請求發向路由器,它一般會有自己的DNS緩存。
- ISP DNS 緩存 – 接下來要check的就是ISP緩存DNS的服務器。在這一般都能找到相應的緩存記錄。
- 遞歸搜索 – 你的ISP的DNS服務器從跟域名服務器開始進行遞歸搜索,從.com頂級域名服務器到Facebook的域名服務器。一般DNS服務器的緩存中會有.com域名服務器中的域名,所以到頂級服務器的匹配過程不是那么必要了。
DNS遞歸查找如下圖所示:

DNS有一點令人擔憂,這就是像wikipedia.org 或者 facebook.com這樣的整個域名看上去只是對應一個單獨的IP地址。還好,有幾種方法可以消除這個瓶頸:
大多數DNS服務器使用Anycast來獲得高效低延遲的DNS查找。
3. 瀏覽器給web服務器發送一個HTTP請求

因為像Facebook主頁這樣的動態頁面,打開后在瀏覽器緩存中很快甚至馬上就會過期,毫無疑問他們不能從中讀取。
所以,瀏覽器將把一下請求發送到Facebook所在的服務器:
GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]
GET 這個請求定義了要讀取的URL: “http://facebook.com/”。 瀏覽器自身定義 (User-Agent 頭), 和它希望接受什么類型的相應 (Accept and Accept-Encoding 頭). Connection頭要求服務器為了后邊的請求不要關閉TCP連接。
請求中也包含瀏覽器存儲的該域名的cookies。可能你已經知道,在不同頁面請求當中,cookies是與跟蹤一個網站狀態相匹配的鍵值。這樣cookies會存儲登錄用戶名,服務器分配的密碼和一些用戶設置等。Cookies會以文本文檔形式存儲在客戶機里,每次請求時發送給服務器。
用來看原始HTTP請求及其相應的工具很多。作者比較喜歡使用fiddler,當然也有像FireBug這樣其他的工具。這些軟件在網站優化時會幫上很大忙。
像“http://facebook.com/”中的斜杠是至關重要的。這種情況下,瀏覽器能安全的添加斜杠。而像“http://example.com/folderOrFile”這樣的地址,因為瀏覽器不清楚folderOrFile到底是文件夾還是文件,所以不能自動添加斜杠。這時,瀏覽器就不加斜杠直接訪問地址,服務器會響應一個重定向,結果造成一次不必要的握手。
4. facebook服務的永久重定向響應

圖中所示為Facebook服務器發回給瀏覽器的響應:
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP="DSP LAW"
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
服務器給瀏覽器響應一個301永久重定向響應,這樣瀏覽器就會訪問“http://www.facebook.com/” 而非“http://facebook.com/”。
為什么服務器一定要重定向而不是直接發會用戶想看的網頁內容呢?這個問題有好多有意思的答案。
其中一個原因跟搜索引擎排名有關。你看,如果一個頁面有兩個地址,就像http://www.igoro.com/ 和http://igoro.com/,搜索引擎會認為它們是兩個網站,結果造成每一個的搜索鏈接都減少從而降低排名。而搜索引擎知道301永久重定向是什么意思,這樣就會把訪問帶www的和不帶www的地址歸到同一個網站排名下。
還有一個是用不同的地址會造成緩存友好性變差。當一個頁面有好幾個名字時,它可能會在緩存里出現好幾次。
5. 瀏覽器跟蹤重定向地址

現在,瀏覽器知道了“http://www.facebook.com/”才是要訪問的正確地址,所以它會發送另一個獲取請求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
頭信息以之前請求中的意義相同。
6. 服務器“處理”請求

服務器接收到獲取請求,然后處理并返回一個響應。
這表面上看起來是一個順向的任務,但其實這中間發生了很多有意思的東西- 就像作者博客這樣簡單的網站,何況像facebook那樣訪問量大的網站呢!
- Web 服務器軟件
web服務器軟件(像IIS和阿帕奇)接收到HTTP請求,然后確定執行什么請求處理來處理它。請求處理就是一個能夠讀懂請求并且能生成HTML來進行響應的程序(像ASP.NET,PHP,RUBY...)。舉個最簡單的例子,需求處理可以以映射網站地址結構的文件層次存儲。像http://example.com/folder1/page1.aspx這個地址會映射/httpdocs/folder1/page1.aspx這個文件。web服務器軟件可以設置成為地址人工的對應請求處理,這樣page1.aspx的發布地址就可以是http://example.com/folder1/page1。
- 請求處理
請求處理閱讀請求及它的參數和cookies。它會讀取也可能更新一些數據,并講數據存儲在服務器上。然后,需求處理會生成一個HTML響應。
所有動態網站都面臨一個有意思的難點 -如何存儲數據。小網站一半都會有一個SQL數據庫來存儲數據,存儲大量數據和/或訪問量大的網站不得不找一些辦法把數據庫分配到多臺機器上。解決方案有:sharding (基于主鍵值講數據表分散到多個數據庫中),復制,利用弱語義一致性的簡化數據庫。
委托工作給批處理是一個廉價保持數據更新的技術。舉例來講,Fackbook得及時更新新聞feed,但數據支持下的“你可能認識的人”功能只需要每晚更新(作者猜測是這樣的,改功能如何完善不得而知)。批處理作業更新會導致一些不太重要的數據陳舊,但能使數據更新耕作更快更簡潔。
7. 服務器發回一個HTML響應

圖中為服務器生成并返回的響應:
HTTP/1.1 200 OK
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
P3P: CP="DSP LAW"
Pragma: no-cache
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
X-Cnection: close
Transfer-Encoding: chunked
Date: Fri, 12 Feb 2010 09:05:55 GMT
2b3????????T?n?@????[...]
整個響應大小為35kB,其中大部分在整理后以blob類型傳輸。
內容編碼頭告訴瀏覽器整個響應體用gzip算法進行壓縮。解壓blob塊后,你可以看到如下期望的HTML:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"
lang="en" id="facebook" class=" no_js">
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-language" content="en" />
...
關于壓縮,頭信息說明了是否緩存這個頁面,如果緩存的話如何去做,有什么cookies要去設置(前面這個響應里沒有這點)和隱私信息等等。
請注意報頭中把Content-type設置為“text/html”。報頭讓瀏覽器將該響應內容以HTML形式呈現,而不是以文件形式下載它。瀏覽器會根據報頭信息決定如何解釋該響應,不過同時也會考慮像URL擴展內容等其他因素。
8. 瀏覽器開始顯示HTML
在瀏覽器沒有完整接受全部HTML文檔時,它就已經開始顯示這個頁面了:

9. 瀏覽器發送獲取嵌入在HTML中的對象

在瀏覽器顯示HTML時,它會注意到需要獲取其他地址內容的標簽。這時,瀏覽器會發送一個獲取請求來重新獲得這些文件。
下面是幾個我們訪問facebook.com時需要重獲取的幾個URL:
- 圖片
http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
http://static.ak.fbcdn.net/rsrc.php/zBS5C/hash/7hwy7at6.gif
… - CSS 式樣表
http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
… - JavaScript 文件
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
…
這些地址都要經歷一個和HTML讀取類似的過程。所以瀏覽器會在DNS中查找這些域名,發送請求,重定向等等...
但不像動態頁面那樣,靜態文件會允許瀏覽器對其進行緩存。有的文件可能會不需要與服務器通訊,而從緩存中直接讀取。服務器的響應中包含了靜態文件保存的期限信息,所以瀏覽器知道要把它們緩存多長時間。還有,每個響應都可能包含像版本號一樣工作的ETag頭(被請求變量的實體值),如果瀏覽器觀察到文件的版本ETag信息已經存在,就馬上停止這個文件的傳輸。
試著猜猜看“fbcdn.net”在地址中代表什么?聰明的答案是"Facebook內容分發網絡"。Facebook利用內容分發網絡(CDN)分發像圖片,CSS表和JavaScript文件這些靜態文件。所以,這些文件會在全球很多CDN的數據中心中留下備份。
靜態內容往往代表站點的帶寬大小,也能通過CDN輕松的復制。通常網站會使用第三方的CDN。例如,Facebook的靜態文件由最大的CDN提供商Akamai來托管。
舉例來講,當你試著ping static.ak.fbcdn.net的時候,可能會從某個akamai.net服務器上獲得響應。有意思的是,當你同樣再ping一次的時候,響應的服務器可能就不一樣,這說明幕后的負載平衡開始起作用了。
10. 瀏覽器發送異步(AJAX)請求

在Web 2.0偉大精神的指引下,頁面顯示完成后客戶端仍與服務器端保持著聯系。
以Facebook聊天功能為例,它會持續與服務器保持聯系來及時更新你那些亮亮灰灰的好友狀態。為了更新這些頭像亮著的好友狀態,在瀏覽器中執行的JavaScript代碼會給服務器發送異步請求。這個異步請求發送給特定的地址,它是一個按照程式構造的獲取或發送請求。還是在Facebook這個例子中,客戶端發送給http://www.facebook.com/ajax/chat/buddy_list.php一個發布請求來獲取你好友里哪個在線的狀態信息。
提起這個模式,就必須要講講"AJAX"-- “異步JavaScript 和 XML”,雖然服務器為什么用XML格式來進行響應也沒有個一清二白的原因。再舉個例子吧,對于異步請求,Facebook會返回一些JavaScript的代碼片段。
除了其他,fiddler這個工具能夠讓你看到瀏覽器發送的異步請求。事實上,你不僅可以被動的做為這些請求的看客,還能主動出擊修改和重新發送它們。AJAX請求這么容易被蒙,可著實讓那些計分的在線游戲開發者們郁悶的了。(當然,可別那樣騙人家~)
Facebook聊天功能提供了關于AJAX一個有意思的問題案例:把數據從服務器端推送到客戶端。因為HTTP是一個請求-響應協議,所以聊天服務器不能把新消息發給客戶。取而代之的是客戶端不得不隔幾秒就輪詢下服務器端看自己有沒有新消息。
這些情況發生時長輪詢是個減輕服務器負載挺有趣的技術。如果當被輪詢時服務器沒有新消息,它就不理這個客戶端。而當尚未超時的情況下收到了該客戶的新消息,服務器就會找到未完成的請求,把新消息做為響應返回給客戶端。
總結一下
希望看了本文,你能明白不同的網絡模塊是如何協同工作的
]]>
StateQueue.reserve(m_psz.GetLength());
StateQueue.push_back(SyllState(_T(""), iEndCharIdx));
BOOL bExit = FALSE;
INT iBegin = 0;
while(iBegin < (INT)StateQueue.size() && !bExit)
{
INT& iIndex = StateQueue[iBegin].iIndex;
CString& strSyll = StateQueue[iBegin].strSyll;
iBegin++;
INT& nNumOfPres = m_pNumOfPre[iIndex];
for(INT i = 0; i < nNumOfPres; ++i)
{
INT& nPre = m_pPre[iIndex][i];
if(nPre < iBegCharIdx) continue;
if(nPre == iBegCharIdx)
{
CString strSyllFound = m_psz.Mid(nPre, iIndex - nPre) + _T("\'") + strSyll;
vecSubSyllable.Add(strSyllFound.Left(strSyllFound.GetLength()-1));
if(vecSubSyllable.GetCount() >= MAX_SYLLABLE_NUM)
{
bExit = TRUE;
break;
}
}
else
{
StateQueue.push_back(SyllState(
m_psz.Mid(nPre, iIndex - nPre) + _T("\'") + strSyll,
nPre));
}
}
}
上述代碼有問題嗎?
有。拿的是vector的引用,但是vector自動擴容去了,結果導致引用位置內存被重寫,引起錯誤。
]]>
Debug通常稱為調試版本,它包含調試信息,并且不作任何優化,便于程序員調試程序。Release稱為發布版本,它往往是進行了各種優化,使得程序在代碼大小和運行速度上都是最優的,以便用戶很好地使用。
Debug 和 Release 的真正秘密,在于一組編譯選項。下面列出了分別針對二者的選項(當然除此之外還有其他一些,如/Fd /Fo,但區別并不重要,通常他們也不會引起 Release 版錯誤,在此不討論)
Debug 版本
參數 含義
/MDd /MLd 或 /MTd 使用 Debug runtime library (調試版本的運行時刻函數庫)
/Od 關閉優化開關
/D "_DEBUG" 相當于 #define _DEBUG,打開編譯調試代碼開關 (主要針對assert函數)
/ZI 創建 Edit and continue(編輯繼續)數據庫,這樣在調試過程中如果修改了源代碼不需重新編譯
/GZ 可以幫助捕獲內存錯誤
/Gm 打開最小化重鏈接開關, 減少鏈接時間
Release 版本
參數 含義
/MD /ML 或 /MT 使用發布版本的運行時刻函數庫
/O1 或 /O2 優化開關,使程序最小或最快
/D "NDEBUG" 關閉條件編譯調試代碼開關 (即不編譯assert函數)
/GF 合并重復的字符串, 并將字符串常量放到只讀內存, 防止被修改
實際上,Debug 和 Release 并沒有本質的界限,他們只是一組編譯選項的集合,編譯器只是按照預定的選項行動。事實上,我們甚至可以修改這些選項,從而得到優化過的調試版本或是帶跟蹤語句的發布版本。
哪些情況下 Release 版會出錯
有了上面的介紹,我們再來逐個對照這些選項看看 Release 版錯誤是怎樣產生的
1、Runtime Library:鏈接哪種運行時刻函數庫通常只對程序的性能產生影響。調試版本的 Runtime Library 包含了調試信息,并采用了一些保護機制以幫助發現錯誤,因此性能不如發布版本。編譯器提供的 Runtime Library 通常很穩定,不會造成 Release 版錯誤;倒是由于 Debug 的 Runtime Library 加強了對錯誤的檢測,如堆內存分配,有時會出現 Debug 有錯但 Release 正常的現象。應當指出的是,如果 Debug 有錯,即使 Release 正常,程序肯定是有 Bug 的,只不過可能是 Release 版的某次運行沒有表現出來而已。
2、優化:這是造成錯誤的主要原因,因為關閉優化時源程序基本上是直接翻譯的,而打開優化后編譯器會作出一系列假設。這類錯誤主要有以下幾種:
1. 幀指針(Frame Pointer)省略(簡稱FPO):在函數調用過程中,所有調用信息(返回地址、參數)以及自動變量都是放在棧中的。若函數的聲明與實現不同(參數、返 回值、調用方式),就會產生錯誤,但 Debug 方式下,棧的訪問通過 EBP 寄存器保存的地址實現,如果沒有發生數組越界之類的錯誤(或是越界“不多”),函數通常能正常執行;Release 方式下,優化會省略 EBP 棧基址指針,這樣通過一個全局指針訪問棧就會造成返回地址錯誤是程序崩潰。
C++ 的強類型特性能檢查出大多數這樣的錯誤,但如果用了強制類型轉換,就不行了。你可以在 Release 版本中強制加入/Oy-編譯選項來關掉幀指針省略,以確定是否此類錯誤。此類錯誤通常有:MFC 消息響應函數書寫錯誤。正確的應為:
afx_msg LRESULT OnMessageOwn
(WPARAM wparam, LPARAM lparam);
ON_MESSAGE 宏包含強制類型轉換。防止這種錯誤的方法之一是重定義 ON_MESSAGE 宏,把下列代碼加到 stdafx.h 中(在#include "afxwin.h"之后),函數原形錯誤時編譯會報錯。
#undef ON_MESSAGE
#define ON_MESSAGE(message, memberFxn) \
{
message, 0, 0, 0, AfxSig_lwl, \
(AFX_PMSG)(AFX_PMSGW)
(static_cast< LRESULT (AFX_MSG_CALL \
CWnd::*)(WPARAM, LPARAM) > (&memberFxn)
},
2. volatile 型變量:volatile
告訴編譯器該變量可能被程序之外的未知方式修改(如系統、其他進程和線程)。優化程序為了使程序性能提高,常把一些變量放在寄存器中(類似于
register 關鍵字),而其他進程只能對該變量所在的內存進行修改,而寄存器中的值沒變。
如果你的程序是多線程的,或者你發現某個變量的值與預期的不符而你確信已正確的設置了,則很可能遇到這樣的問題。這種錯誤有時會表現為程序在最快優化出錯而最小優化正常。把你認為可疑的變量加上 volatile 試試。
3. 變量優化:優化程序會根據變量的使用情況優化變量。例如,函數中有一個未被使用的變量,在 Debug 版中它有可能掩蓋一個數組越界,而在 Release 版中,這個變量很可能被優化調,此時數組越界會破壞棧中有用的數據。當然,實際的情況會比這復雜得多。與此有關的錯誤有非法訪問,包括數組越界、指針錯誤 等。例如:
void fn(void)
{
int i;
i = 1;
int a[4];
{
int j;
j = 1;
}
a[-1] = 1;
//當然錯誤不會這么明顯,例如下標是變量
a[4] = 1;
}
j 雖然在數組越界時已出了作用域,但其空間并未收回,因而 i 和 j 就會掩蓋越界。而 Release 版由于 i、j 并未其很大作用可能會被優化掉,從而使棧被破壞。
3. DEBUG 與 NDEBUG :當定義了 _DEBUG 時,assert() 函數會被編譯,而 NDEBUG 時不被編譯。此外,TRACE() 宏的編譯也受 _DEBUG 控制。
所有這些斷言都只在 Debug版中才被編譯,而在 Release 版中被忽略。唯一的例外是 VERIFY()。事實上,這些宏都是調用了assert()函數,只不過附加了一些與庫有關的調試代碼。如果你在這些宏中加入了任何程序代碼,而不只是 布爾表達式(例如賦值、能改變變量值的函數調用等),那么Release版都不會執行這些操作,從而造成錯誤。初學者很容易犯這類錯誤,查找的方法也很簡 單,因為這些宏都已在上面列出,只要利用 VC++ 的 Find in Files 功能在工程所有文件中找到用這些宏的地方再一一檢查即可。另外,有些高手可能還會加入 #ifdef _DEBUG 之類的條件編譯,也要注意一下。
順便值得一提的是VERIFY()宏,這個宏允許你將程序代碼放在布爾表達式里。這個宏通常用來檢查 Windows API的返回值。有些人可能為這個原因而濫用VERIFY(),事實上這是危險的,因為VERIFY()違反了斷言的思想,不能使程序代碼和調試代碼完全 分離,最終可能會帶來很多麻煩。因此,專家們建議盡量少用這個宏。
4. /GZ 選項:這個選項會做以下這些事:
1. 初始化內存和變量。包括用 0xCC 初始化所有自動變量,0xCD ( Cleared Data ) 初始化堆中分配的內存(即動態分配的內存,例如 new ),0xDD ( Dead Data ) 填充已被釋放的堆內存(例如 delete ),0xFD( deFencde Data ) 初始化受保護的內存(debug 版在動態分配內存的前后加入保護內存以防止越界訪問),其中括號中的詞是微軟建議的助記詞。這樣做的好處是這些值都很大,作為指針是不可能的(而且 32 位系統中指針很少是奇數值,在有些系統中奇數的指針會產生運行時錯誤),作為數值也很少遇到,而且這些值也很容易辨認,因此這很有利于在 Debug 版中發現 Release 版才會遇到的錯誤。要特別注意的是,很多人認為編譯器會用0來初始化變量,這是錯誤的(而且這樣很不利于查找錯誤)。
2. 通過函數指針調用函數時,會通過檢查棧指針驗證函數調用的匹配性。(防止原形不匹配)
3. 函數返回前檢查棧指針,確認未被修改。(防止越界訪問和原形不匹配,與第二項合在一起可大致模擬幀指針省略 FPO )通常 /GZ 選項會造成 Debug 版出錯而 Release 版正常的現象,因為 Release 版中未初始化的變量是隨機的,這有可能使指針指向一個有效地址而掩蓋了非法訪問。除此之外,/Gm/GF等選項造成錯誤的情況比較少,而且他們的效果顯而 易見,比較容易發現。
怎樣“調試” Release 版的程序
遇到Debug成功但Release失敗,顯然是一件很沮喪的事,而且往往無從下手。如果你看了以上的分析,結合錯誤的具體表現,很快找出了錯誤,固然很好。但如果一時找不出,以下給出了一些在這種情況下的策略。
1. 前面已經提過,Debug和Release只是一組編譯選項的差別,實際上并沒有什么定義能區分二者。我們可以修改Release版的編譯選項來縮小錯誤 范圍。如上所述,可以把Release 的選項逐個改為與之相對的Debug選項,如/MD改為/MDd、/O1改為/Od,或運行時間優化改為程序大小優化。注意,一次只改一個選項,看改哪個 選項時錯誤消失,再對應該選項相關的錯誤,針對性地查找。這些選項在Project\Settings...中都可以直接通過列表選取,通常不要手動修 改。由于以上的分析已相當全面,這個方法是最有效的。
2. 在編程過程中就要時常注意測試 Release 版本,以免最后代碼太多,時間又很緊。
3. 在 Debug 版中使用 /W4 警告級別,這樣可以從編譯器獲得最大限度的錯誤信息,比如 if( i =0 )就會引起 /W4 警告。不要忽略這些警告,通常這是你程序中的 Bug 引起的。但有時 /W4 會帶來很多冗余信息,如 未使用的函數參數 警告,而很多消息處理函數都會忽略某些參數。我們可以用:
#progma warning(disable: 4702)
//禁止
//...
#progma warning(default: 4702)
//重新允許來暫時禁止某個警告,或使用
#progma warning(push, 3)
//設置警告級別為 /W3
//...
#progma warning(pop)
//重設為 /W4
來暫時改變警告級別,有時你可以只在認為可疑的那一部分代碼使用 /W4。
4. 你也可以像Debug一樣調試你的Release版,只要加入調試符號。在Project/Settings... 中,選中 Settings for "Win32 Release",選中 C/C++ 標簽,Category 選 General,Debug Info 選 Program Database。再在 Link 標簽 Project options 最后加上 "/OPT:REF" (引號不要輸)。這樣調試器就能使用 pdb 文件中的調試符號。
但調試時你會發現斷點很難設置,變量也很難找到??這些都被優化過了。不過令人慶幸的是,Call Stack窗口仍然工作正常,即使幀指針被優化,棧信息(特別是返回地址)仍然能找到。這對定位錯誤很有幫助。
]]>
Problem Statement
You want to perform a sequence of folds on the paper, where you may fold anywhere along an axis that is in between two rows or columns of the paper. After performing a fold, we wish to model the folded paper as a new, flat piece of paper. We will do this by considering two overlapping cells as a single cell, with a value that is the sum of the individual cells.
You wish to perform a sequence of folds such that the value of some single cell in the resulting piece of paper is as large as possible. Return this value.
Definition
| Class: | FoldThePaper |
| Method: | getValue |
| Parameters: | vector <string> |
| Returns: | int |
| Method signature: | int getValue(vector <string> paper) |
| (be sure your method is public) | |
Constraints
Examples
|
||
Returns: 6 |
||
|
||
|
||
Returns: 2 |
||
|
||
|
||
Returns: 4 |
||
|
||
|
||
Returns: 131 |
||
|
|
||
|
||
Returns: 0 |
||
|
|
||
This problem statement is the exclusive and proprietary property of TopCoder, Inc. Any unauthorized use or reproduction of this information without the prior written consent of TopCoder, Inc. is strictly prohibited. (c)2003, TopCoder, Inc. All rights reserved.
題目大意是有一個12*12的矩陣,現在可以對這個矩陣橫向或縱向折疊,出在重疊位置的數相加。
求折疊過程中任意位置產生的最大數。
很多大牛fail了,我一個DFS+剪枝也超時了,一共32人pass sys test,1000pts無人ac,此套題難度還是很大的。
基本思路是狀態壓縮DP,橫向(1<<12)*縱向(1<<12)*加和。
但是這樣會超時。關鍵是沒有利用到折疊的信息。
預先生成某個位置的狀態(由那些位置疊加而來),就可以減少檢查量,就可以ac了。
如何生成這些狀態呢?沒錯,又是一個DP. 呵呵。]]>
文件的編碼和瀏覽器要顯示的編碼不一致。
1) 檢查文件原始的編碼, 可以用記事本打開, 然后選擇另存為來看;
2) 給當前頁面加入一個指令來建議瀏覽器用指定的編碼來顯示文件字符內容.
<meta http-equiv="content-type" content="text/html; charset=GBK">
3) 如果系統是英文XP,沒裝東亞字符集支持, 也會顯示亂碼.
2. JSP 頁面的亂碼問題
1) page 指令有個 pageEncoding="GBK" 這個會指定當前頁面保存的編碼, 如果寫成
ISO8859-1 就不能保存漢字;
2) page 指令的 contentType="text/html; charset=ISO8859-1" 也會像靜態頁面一樣讓
瀏覽器來優先選擇一種編碼.
如果JSP 亂碼的話,一般就顯示成?,而且不管你給瀏覽器選什么樣的編碼,它都不能正
確顯示
3. 表單提交的亂碼問題(Tomcat 特有)
1). POST 的亂碼
MyEclipse 6 Java 開發中文教程
157 劉長炯著
a. 首先瀏覽器提交表單的編碼是根據表單所在頁面來決定的, 而不是根據提交后的
JSP 頁面的編碼來決定的. 把所有的頁面的編碼都設置成一樣的,例如 GBK.
b. 處理方式就是在獲取參數之前設置編碼:
request.setCharacterEncoding("GBK");
c. 可以用過濾器的方式來解決, Tomcat 已經帶了一個現成的:
apache-tomcat-5.5.23\webapps\jsp-examples\WEB-INF\classes\filters\SetCharacter
EncodingFilter.java
web.xml
<filter>
<filter-name>Set Character Encoding</filter-name>
<filter-class>filters.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>GBK</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>Set Character Encoding</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
2) GET 方式的亂碼
用 setCharacterEncoding() 不能解決. TOMCAT 的一個BUG, GET 方式傳送的表單參
數總是用的 ISO8859-1 編碼. 我們要把它轉成 GBK 方式.
String username = request.getParameter("username");
System.out.println(username);
// 轉碼, 先取得原始的二進制字節數組
byte[] data = username.getBytes("ISO8859-1");
// 根據新的字符集再構造新的字符串
username = new String(data, "GBK");
小結:
所有的頁面(除了最后的 GET 的亂碼問題)都用統一的編碼(GBK 或者UTF-8), 就不會出現
亂碼問題
以上內容為【轉】
下面是一個完整的過濾器例子:
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
public class TomcatFormFilter implements Filter {
/**
* Request.java 對 HttpServletRequestWrapper 進行擴充, 不影響原來的功能并能提供所 有的
* HttpServletRequest 接口中的功能. 它可以統一的對 Tomcat 默認設置下的中文問題進行解決而只 需要用新的 Request
* 對象替換頁面中的 request 對象即可.
*/
class Request extends HttpServletRequestWrapper {
public Request(HttpServletRequest request) {
super(request);
}
/**
* 轉換由表單讀取的數據的內碼. 從 ISO 字符轉到 GBK.
*/
public String toChi(String input) {
try {
byte[] bytes = input.getBytes("ISO8859-1");
return new String(bytes, "utf-8");
} catch (Exception ex) {
}
return null;
}
/**
* Return the HttpServletRequest holded by this object.
*/
private HttpServletRequest getHttpServletRequest() {
return (HttpServletRequest) super.getRequest();
}
/**
* 讀取參數 -- 修正了中文問題.
*/
public String getParameter(String name) {
return toChi(getHttpServletRequest().getParameter(name));
}
/**
* 讀取參數列表 - 修正了中文問題.
*/
public String[] getParameterValues(String name) {
String values[] = getHttpServletRequest().getParameterValues(name);
if (values != null) {
for (int i = 0; i < values.length; i++) {
values[i] = toChi(values[i]);
}
}
return values;
}
}
public void destroy() {
}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException,
ServletException {
HttpServletRequest httpreq = (HttpServletRequest) request;
if (httpreq.getMethod().equals("POST")) {
request.setCharacterEncoding("utf-8");
} else {
request = new Request(httpreq);
}
response.setCharacterEncoding("utf-8");
chain.doFilter(request, response);
}
public void init(FilterConfig filterConfig) throws ServletException {
}
}
web.xml中加入如下配置信息
<filter-name>TomcatFormFilter</filter-name>
<filter-class>filters.TomcatFormFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>TomcatFormFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
上述都是使用統一的GBK編碼,如果想用utf-8編碼的話,稍作修改就可以了。
在解決了JSP亂碼問題之后,還有一個問題,就是數據庫亂碼問題。
我使用的數據庫是mysql
在hibernate的配置文件中加入
<property name="connection.useUnicode">true</property>
<property name="connection.characterEncoding">UTF-8</property>
就算是一整套的中文解決方案了。
]]>
]]>
匹配Email地址的正則表達式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配網址URL的正則表達式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
版本:v2.21 (2007-8-3) 作者:deerchao 來源:unibetter大學生社區 轉載請注明來源
目錄
- 本文目標
- 如何使用本教程
- 正則表達式到底是什么?
- 入門
- 測試正則表達式
- 元字符
- 字符轉義
- 重復
- 字符類
- 反義
- 替換
- 分組
- 后向引用
- 零寬斷言
- 負向零寬斷言
- 注釋
- 貪婪與懶惰
- 處理選項
- 平衡組/遞歸匹配
- 還有些什么東西沒提到
- 聯系作者
- 最后,來點廣告...
- 一些我認為你可能已經知道的術語的參考
- 網上的資源及本文參考文獻
- 更新說明
本文目標
30分鐘內讓你明白正則表達式是什么,并對它有一些基本的了解,讓你可以在自己的程序或網頁里使用它。
如何使用本教程
最重要的是——請給我30分鐘,如果你沒有使用正則表達式的經驗,請不要試圖在30秒內入門。當然,如果你是超人,那自然得另當別論。
別被下面那些復雜的表達式嚇倒,只要跟著我一步一步來,你會發現正則表達式其實并沒有你想像中的那么困難。當然,如果你看完了這篇教程之后,發現自己明白了很多,卻又幾乎什么都記不得,那也是很正常的——我認為,沒接觸過正則表達式的人在看完這篇教程后,能把提到過的語法記住80%以上的可能性為零。這里只是讓你明白基本的原理,以后你還需要多練習,多使用,才能熟練掌握正則表達式。
除了作為入門教程之外,本文還試圖成為可以在日常工作中使用的正則表達式語法參考手冊。就作者本人的經歷來說,這個目標還是完成得不錯的——你看,我自己也沒能把所有的東西記下來,不是嗎?
文本格式約定:專業術語 元字符/語法格式 正則表達式 正則表達式中的一部分(用于分析) 用于在其中搜索的字符串 對正則表達式或其中一部分的說明清除格式
正則表達式到底是什么?
在編寫處理字符串的程序或網頁時,經常會有查找符合某些復雜規則的字符串的需要。正則表達式就是用于描述這些規則的工具。換句話說,正則表達式就是記錄文本規則的代碼。
很可能你使用過Windows/Dos下用于文件查找的通配符(wildcard),也就是*和?。如果你想查找某個目錄下的所有的Word文檔的話,你會搜索*.doc。在這里,*會被解釋成任意的字符串。和通配符類似,正則表達式也是用來進行文本匹配的工具,只不過比起通配符,它能更精確地描述你的需求——當然,代價就是更復雜——比如你可以編寫一個正則表達式,用來查找所有以0開頭,后面跟著2-3個數字,然后是一個連字號“-”,最后是7或8位數字的字符串(像010-12345678或0376-7654321)。
正則表達式是用于進行文本匹配的工具,所以本文里多次提到了在字符串里搜索/查找,這種說法的意思是在給定的字符串中,尋找與給定的正則表達式相匹配的部分。有可能字符串里有不止一個部分滿足給定的正則表達式,這時每一個這樣的部分被稱為一個匹配。匹配在本文里可能會有三種意思:一種是形容詞性的,比如說一個字符串匹配一個表達式;一種是動詞性的,比如說在字符串里匹配正則表達式;還有一種是名詞性的,就是剛剛說到的“字符串中滿足給定的正則表達式的一部分”。
入門
學習正則表達式的最好方法是從例子開始,理解例子之后再自己對例子進行修改,實驗。下面給出了不少簡單的例子,并對它們作了詳細的說明。
假設你在一篇英文小說里查找hi,你可以使用正則表達式hi。
這是最簡單的正則表達式了,它可以精確匹配這樣的字符串:由兩個字符組成,前一個字符是h,后一個是i。通常,處理正則表達式的工具會提供一個忽略大小寫的選項,如果選中了這個選項,它可以匹配hi,HI,Hi,hI這四種情況中的任意一種。
不幸的是,很多單詞里包含hi這兩個連續的字符,比如him,history,high等等。用hi來查找的話,這里邊的hi也會被找出來。如果要精確地查找hi這個單詞的話,我們應該使用\bhi\b。
\b是正則表達式規定的一個特殊代碼(好吧,某些人叫它元字符,metacharacter),代表著單詞的開頭或結尾,也就是單詞的分界處。雖然通常英文的單詞是由空格或標點符號或換行來分隔的,但是\b并不匹配這些單詞分隔符中的任何一個,它只匹配一個位置。(如果需要更精確的說法,\b匹配這樣的位置:它的前一個字符和后一個字符不全是(一個是,一個不是或不存在)\w)
假如你要找的是hi后面不遠處跟著一個Lucy,你應該用\bhi\b.*\bLucy\b。
這里,.是另一個元字符,匹配除了換行符以外的任意字符。*同樣是元字符,不過它代表的不是字符,也不是位置,而是數量——它指定*前邊的內容可以連續重復出現任意次以使整個表達式得到匹配。因此,.*連在一起就意味著任意數量的不包含換行的字符。現在\bhi\b.*\bLucy\b的意思就很明顯了:先是一個單詞hi,然后是任意個任意字符(但不能是換行),最后是Lucy這個單詞。
如果同時使用其它的一些元字符,我們就能構造出功能更強大的正則表達式。比如下面這個例子:
0\d\d-\d\d\d\d\d\d\d\d匹配這樣的字符串:以0開頭,然后是兩個數字,然后是一個連字號“-”,最后是8個數字(也就是中國的電話號碼。當然,這個例子只能匹配區號為3位的情形)。
這里的\d是一個新的元字符,匹配任意的數字(0,或1,或2,或……)。-不是元字符,只匹配它本身——連字號。
為了避免那么多煩人的重復,我們也可以這樣寫這個表達式:0\d{2}-\d{8}。 這里\d后面的{2}({8})的意思是前面\d必須連續重復匹配2次(8次)。
測試正則表達式
如果你不覺得正則表達式很難讀寫的話,要么你是一個天才,要么,你不是地球人。正則表達式的語法很令人頭疼,即使對經常使用它的人來說也是如此。由于難于讀寫,容易出錯,所以很有必要創建一種工具來測試正則表達式。
由于在不同的環境下正則表達式的一些細節是不相同的,本教程介紹的是Microsoft .Net 2.0下正則表達式的行為,所以,我向你介紹一個.Net下的工具Regex Tester。首先你確保已經安裝了.Net Framework 2.0,然后下載Regex Tester。這是個綠色軟件,下載完后打開壓縮包,直接運行RegexTester.exe就可以了。
下面是Regex Tester運行時的截圖:

元字符
現在你已經知道幾個很有用的元字符了,如\b,.,*,還有\d.當然還有更多的元字符可用,比如\s匹配任意的空白符,包括空格,制表符(Tab),換行符,中文全角空格等。\w匹配字母或數字或下劃線或漢字等。
下面來試試更多的例子:
\ba\w*\b匹配以字母a開頭的單詞——先是某個單詞開始處(\b),然后是字母a,然后是任意數量的字母或數字(\w*),最后是單詞結束處(\b)(好吧,現在我們說說正則表達式里的單詞是什么意思吧:就是幾個連續的\w。不錯,這與學習英文時要背的成千上萬個同名的東西的確關系不大)。
\d+匹配1個或更多連續的數字。這里的+是和*類似的元字符,不同的是*匹配重復任意次(可能是0次),而+則匹配重復1次或更多次。
\b\w{6}\b 匹配剛好6個字母/數字的單詞。
| 代碼 | 說明 |
|---|---|
| . | 匹配除換行符以外的任意字符 |
| \w | 匹配字母或數字或下劃線或漢字 |
| \s | 匹配任意的空白符 |
| \d | 匹配數字 |
| \b | 匹配單詞的開始或結束 |
| ^ | 匹配字符串的開始 |
| $ | 匹配字符串的結束 |
元字符^(和數字6在同一個鍵位上的符號)以及$和\b有點類似,都匹配一個位置。^匹配你要用來查找的字符串的開頭,$匹配結尾。這兩個代碼在驗證輸入的內容時非常有用,比如一個網站如果要求你填寫的QQ號必須為5位到12位數字時,可以使用:^\d{5,12}$。
這里的{5,12}和前面介紹過的{2}是類似的,只不過{2}匹配只能不多不少重復2次,{5,12}則是重復的次數不能少于5次,不能多于12次,否則都不匹配。
因為使用了^和$,所以輸入的整個字符串都要用來和\d{5,12}來匹配,也就是說整個輸入必須是5到12個數字,因此如果輸入的QQ號能匹配這個正則表達式的話,那就符合要求了。
和忽略大小寫的選項類似,有些正則表達式處理工具還有一個處理多行的選項。如果選中了這個選項,^和$的意義就變成了匹配行的開始處和結束處。
字符轉義
如果你想查找元字符本身的話,比如你查找.,或者*,就出現了問題:你沒法指定它們,因為它們會被解釋成其它的意思。這時你就必須使用\來取消這些字符的特殊意義。因此,你應該使用\.和\*。當然,要查找\本身,你也得用\\.
例如:www\.unibetter\.com匹配www.unibetter.com,c:\\Windows匹配c:\Windows。
重復
你已經看過了前面的*,+,{2},{5,12}這幾個匹配重復的方式了。下面是正則表達式中所有的限定符(指定數量的代碼,例如*,{5,12}等):
| 代碼/語法 | 說明 |
|---|---|
| * | 重復零次或更多次 |
| + | 重復一次或更多次 |
| ? | 重復零次或一次 |
| {n} | 重復n次 |
| {n,} | 重復n次或更多次 |
| {n,m} | 重復n到m次 |
下面是一些使用重復的例子:
Windows\d+匹配Windows后面跟1個或更多數字
13\d{9}匹配13后面跟9個數字(中國的手機號)
^\w+匹配一行的第一個單詞(或整個字符串的第一個單詞,具體匹配哪個意思得看選項設置)
字符類
要想查找數字,字母或數字,空白是很簡單的,因為已經有了對應這些字符集合的元字符,但是如果你想匹配沒有預定義元字符的字符集合(比如元音字母a,e,i,o,u),應該怎么辦?
很簡單,你只需要在中括號里列出它們就行了,像[aeiou]就匹配任何一個英文元音字母,[.?!]匹配標點符號(.或?或!)(英文語句通常只以這三個標點結束)。
我們也可以輕松地指定一個字符范圍,像[0-9]代表的含意與\d就是完全一致的:一位數字,同理[a-z0-9A-Z_]也完全等同于\w(如果只考慮英文的話)。
下面是一個更復雜的表達式:\(?0\d{2}[) -]?\d{8}。
這個表達式可以匹配幾種格式的電話號碼,像(010)88886666,或022-22334455,或02912345678等。我們對它進行一些分析吧:首先是一個轉義字符\(,它能出現0次或1次(?),然后是一個0,后面跟著2個數字(\d{2}),然后是)或-或空格中的一個,它出現1次或不出現(?),最后是8個數字(\d{8})。不幸的是,它也能匹配010)12345678或(022-87654321這樣的“不正確”的格式。要解決這個問題,請在本教程的下面查找答案。
反義
有時需要查找不屬于某個能簡單定義的字符類的字符。比如想查找除了數字以外,其它任意字符都行的情況,這時需要用到反義:
| 代碼/語法 | 說明 |
|---|---|
| \W | 匹配任意不是字母,數字,下劃線,漢字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非數字的字符 |
| \B | 匹配不是單詞開頭或結束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou這幾個字母以外的任意字符 |
例子:\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括號括起來的以a開頭的字符串。
替換
好了,現在終于到了解決3位或4位區號問題的時間了。正則表達式里的替換指的是有幾種規則,如果滿足其中任意一種規則都應該當成匹配,具體方法是用|把不同的規則分隔開。聽不明白?沒關系,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7}這個表達式能匹配兩種以連字號分隔的電話號碼:一種是三位區號,8位本地號(如010-12345678),一種是4位區號,7位本地號(0376-2233445)。
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}這個表達式匹配3位區號的電話號碼,其中區號可以用小括號括起來,也可以不用,區號與本地號間可以用連字號或空格間隔,也可以沒有間隔。你可以試試用替換|把這個表達式擴展成也支持4位區號的。
\d{5}-\d{4}|\d{5}這個表達式用于匹配美國的郵政編碼。美國郵編的規則是5位數字,或者用連字號間隔的9位數字。之所以要給出這個例子是因為它能說明一個問題:使用替換時,順序是很重要的。如果你把它改成\d{5}|\d{5}-\d{4}的話,那么就只會匹配5位的郵編(以及9位郵編的前5位)。原因是匹配替換時,將會從左到右地測試每個分枝條件,如果滿足了某個分枝的話,就不會去管其它的替換條件了。
Windows98|Windows2000|WindosXP這個例子是為了告訴你替換不僅僅能用于兩種規則,也能用于更多種規則。
分組
我們已經提到了怎么重復單個字符(直接在字符后面加上限定符就行了);但如果想要重復多個字符又該怎么辦?你可以用小括號來指定子表達式(也叫做分組),然后你就可以指定這個子表達式的重復次數了,你也可以對子表達式進行其它一些操作(后面會有介紹)。
(\d{1,3}\.){3}\d{1,3}是一個簡單的IP地址匹配表達式。要理解這個表達式,請按下列順序分析它:\d{1,3}匹配1到3位的數字,(\d{1,3}\.){3}匹配三位數字加上一個英文句號(這個整體也就是這個分組)重復3次,最后再加上一個一到三位的數字(\d{1,3})。
不幸的是,它也將匹配256.300.888.999這種不可能存在的IP地址(IP地址中每個數字都不能大于255。題外話,好像反恐24小時第三季的編劇不知道這一點,汗...)。如果能使用算術比較的話,或許能簡單地解決這個問題,但是正則表達式中并不提供關于數學的任何功能,所以只能使用冗長的分組,選擇,字符類來描述一個正確的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解這個表達式的關鍵是理解2[0-4]\d|25[0-5]|[01]?\d\d?,這里我就不細說了,你自己應該能分析得出來它的意義。
后向引用
使用小括號指定一個子表達式后,匹配這個子表達式的文本(也就是此分組捕獲的內容)可以在表達式或其它程序中作進一步的處理。默認情況下,每個分組會自動擁有一個組號,規則是:從左向右,以分組的左括號為標志,第一個出現的分組的組號為1,第二個為2,以此類推。
后向引用用于重復搜索前面某個分組匹配的文本。例如,\1代表分組1匹配的文本。難以理解?請看示例:
\b(\w+)\b\s+\1\b可以用來匹配重復的單詞,像go go, kitty kitty。首先是一個單詞,也就是單詞開始處和結束處之間的多于一個的字母或數字(\b(\w+)\b),然后是1個或幾個空白符(\s+),最后是前面匹配的那個單詞(\1)。
你也可以自己指定子表達式的組名。要指定一個子表達式的組名,請使用這樣的語法:(?<Word>\w+)(或者把尖括號換成'也行:(?'Word'\w+)),這樣就把\w+的組名指定為Word了。要反向引用這個分組捕獲的內容,你可以使用\k<Word>,所以上一個例子也可以寫成這樣:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括號的時候,還有很多特定用途的語法。下面列出了最常用的一些:
| 捕獲 | |
|---|---|
| (exp) | 匹配exp,并捕獲文本到自動命名的組里 |
| (?<name>exp) | 匹配exp,并捕獲文本到名稱為name的組里,也可以寫成(?'name'exp) |
| (?:exp) | 匹配exp,不捕獲匹配的文本,也不給此分組分配組號 |
| 零寬斷言 | |
| (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 |
| (?!exp) | 匹配后面跟的不是exp的位置 |
| (?<!exp) | 匹配前面不是exp的位置 |
| 注釋 | |
| (?#comment) | 這種類型的組不對正則表達式的處理產生任何影響,用于提供注釋讓人閱讀 |
我們已經討論了前兩種語法。第三個(?:exp)不會改變正則表達式的處理方式,只是這樣的組匹配的內容不會像前兩種那樣被捕獲到某個組里面。
零寬斷言
接下來的四個用于查找在某些內容(但并不包括這些內容)之前或之后的東西,也就是說它們像\b,^,$那樣用于指定一個位置,這個位置應該滿足一定的條件(斷言),因此它們也被稱為零寬斷言。最好還是拿例子來說明吧:
(?=exp)也叫零寬度正預測先行斷言,它斷言自身出現的位置的后面能匹配表達式exp。比如\b\w+(?=ing\b),匹配以ing結尾的單詞的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.時,它會匹配sing和danc。
(?<=exp)也叫零寬度正回顧后發斷言,它斷言自身出現的位置的前面能匹配表達式exp。比如(?<=\bre)\w+\b會匹配以re開頭的單詞的后半部分(除了re以外的部分),例如在查找reading a book時,它匹配ading。
假如你想要給一個很長的數字中每三位間加一個逗號(當然是從右邊加起了),你可以這樣查找需要在前面和里面添加逗號的部分:((?<=\d)\d{3})*\b,用它對1234567890進行查找時結果是234567890。
下面這個例子同時使用了這兩種斷言:(?<=\s)\d+(?=\s)匹配以空白符間隔的數字(再次強調,不包括這些空白符)。
負向零寬斷言
前面我們提到過怎么查找不是某個字符或不在某個字符類里的字符的方法(反義)。但是如果我們只是想要確保某個字符沒有出現,但并不想去匹配它時怎么辦?例如,如果我們想查找這樣的單詞--它里面出現了字母q,但是q后面跟的不是字母u,我們可以嘗試這樣:
\b\w*q[^u]\w*\b匹配包含后面不是字母u的字母q的單詞。但是如果多做測試(或者你思維足夠敏銳,直接就觀察出來了),你會發現,如果q出現在單詞的結尾的話,像Iraq,Benq,這個表達式就會出錯。這是因為[^u]總要匹配一個字符,所以如果q是單詞的最后一個字符的話,后面的[^u]將會匹配q后面的單詞分隔符(可能是空格,或者是句號或其它的什么),后面的\w*\b將會匹配下一個單詞,于是\b\w*q[^u]\w*\b就能匹配整個Iraq fighting。負向零寬斷言能解決這樣的問題,因為它只匹配一個位置,并不消費任何字符。現在,我們可以這樣來解決這個問題:\b\w*q(?!u)\w*\b。
零寬度負預測先行斷言(?!exp),斷言此位置的后面不能匹配表達式exp。例如:\d{3}(?!\d)匹配三位數字,而且這三位數字的后面不能是數字;\b((?!abc)\w)+\b匹配不包含連續字符串abc的單詞。
同理,我們可以用(?<!exp),零寬度正回顧后發斷言來斷言此位置的前面不能匹配表達式exp:(?<![a-z])\d{7}匹配前面不是小寫字母的七位數字。
一個更復雜的例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含屬性的簡單HTML標簽內里的內容。(<?(\w+)>)指定了這樣的前綴:被尖括號括起來的單詞(比如可能是<b>),然后是.*(任意的字符串),最后是一個后綴(?=<\/\1>)。注意后綴里的\/,它用到了前面提過的字符轉義;\1則是一個反向引用,引用的正是捕獲的第一組,前面的(\w+)匹配的內容,這樣如果前綴實際上是<b>的話,后綴就是</b>了。整個表達式匹配的是<b>和</b>之間的內容(再次提醒,不包括前綴和后綴本身)。
注釋
小括號的另一種用途是能過語法(?#comment)來包含注釋。例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)。
要包含注釋的話,最好是啟用“忽略模式里的空白符”選項,這樣在編寫表達式時能任意的添加空格,Tab,換行,而實際使用時這些都將被忽略。啟用這個選項后,在#后面到這一行結束的所有文本都將被當成注釋忽略掉。
例如,我們可以前面的一個表達式寫成這樣:
(?<= # 斷言要匹配的文本的前綴 <(\w+)> # 查找尖括號括起來的字母或數字(即HTML/XML標簽) ) # 前綴結束 .* # 匹配任意文本 (?= # 斷言要匹配的文本的后綴 <\/\1> # 查找尖括號括起來的內容:前面是一個"/",后面是先前捕獲的標簽 ) # 后綴結束
貪婪與懶惰
當正則表達式中包含能接受重復的限定符時,通常的行為是(在使整個表達式能得到匹配的前提下)匹配盡可能多的字符。考慮這個表達式:a.*b,它將會匹配最長的以a開始,以b結束的字符串。如果用它來搜索aabab的話,它會匹配整個字符串aabab。這被稱為貪婪匹配。
有時,我們更需要懶惰匹配,也就是匹配盡可能少的字符。前面給出的限定符都可以被轉化為懶惰匹配模式,只要在它后面加上一個問號?。這樣.*?就意味著匹配任意數量的重復,但是在能使整個匹配成功的前提下使用最少的重復。現在看看懶惰版的例子吧:
a.*?b匹配最短的,以a開始,以b結束的字符串。如果把它應用于aabab的話,它會匹配aab和ab(為什么第一個匹配是aab而不是ab?簡單地說,因為正則表達式有另一條規則,比懶惰/貪婪規則的優先級更高:最先開始的匹配擁有最高的優先權——The Match That Begins Earliest Wins)。
| *? | 重復任意次,但盡可能少重復 |
| +? | 重復1次或更多次,但盡可能少重復 |
| ?? | 重復0次或1次,但盡可能少重復 |
| {n,m}? | 重復n到m次,但盡可能少重復 |
| {n,}? | 重復n次以上,但盡可能少重復 |
處理選項
上面介紹了幾個選項如忽略大小寫,處理多行等,這些選項能用來改變處理正則表達式的方式。下面是.Net中常用的正則表達式選項:
| 名稱 | 說明 |
|---|---|
| IgnoreCase(忽略大小寫) | 匹配時不區分大小寫。 |
| Multiline(多行模式) | 更改^和$的含義,使它們分別在任意一行的行首和行尾匹配,而不僅僅在整個字符串的開頭和結尾匹配。(在此模式下,$的精確含意是:匹配\n之前的位置以及字符串結束前的位置.) |
| Singleline(單行模式) | 更改.的含義,使它與每一個字符匹配(包括換行符\n)。 |
| IgnorePatternWhitespace(忽略空白) | 忽略表達式中的非轉義空白并啟用由#標記的注釋。 |
| RightToLeft(從右向左查找) | 匹配從右向左而不是從左向右進行。 |
| ExplicitCapture(顯式捕獲) | 僅捕獲已被顯式命名的組。 |
| ECMAScript(JavaScript兼容模式) | 使表達式的行為與它在JavaScript里的行為一致。 |
一個經常被問到的問題是:是不是只能同時使用多行模式和單行模式中的一種?答案是:不是。這兩個選項之間沒有任何關系,除了它們的名字比較相似(以至于讓人感到疑惑)以外。
平衡組/遞歸匹配
注意:這里介紹的平衡組語法是由.Net Framework支持的;其它語言/庫不一定支持這種功能,或者支持此功能但需要使用不同的語法。
有時我們需要匹配像( 100 * ( 50 + 15 ) )這樣的可嵌套的層次性結構,這時簡單地使用\(.+\)則只會匹配到最左邊的左括號和最右邊的右括號之間的內容(這里我們討論的是貪婪模式,懶惰模式也有下面的問題)。假如原來的字符串里的左括號和右括號出現的次數不相等,比如( 5 / ( 3 + 2 ) ) ),那我們的匹配結果里兩者的個數也不會相等。有沒有辦法在這樣的字符串里匹配到最長的,配對的括號之間的內容呢?
為了避免(和\(把你的大腦徹底搞糊涂,我們還是用尖括號代替圓括號吧。現在我們的問題變成了如何把xx <aa <bbb> <bbb> aa> yy這樣的字符串里,最長的配對的尖括號內的內容捕獲出來?
這里需要用到以下的語法構造:
- (?'group') 把捕獲的內容命名為group,并壓入堆棧
- (?'-group') 從堆棧上彈出最后壓入堆棧的名為group的捕獲內容,如果堆棧本來為空,則本分組的匹配失敗
- (?(group)yes|no) 如果堆棧上存在以名為group的捕獲內容的話,繼續匹配yes部分的表達式,否則繼續匹配no部分
- (?!) 零寬負向先行斷言,由于沒有后綴表達式,試圖匹配總是失敗
如果你不是一個程序員(或者你是一個對堆棧的概念不熟的程序員),你就這樣理解上面的三種語法吧:第一個就是在黑板上寫一個 "group",第二個就是從黑板上擦掉一個"group",第三個就是看黑板上寫的還有沒有"group",如果有就繼續匹配yes部分,否則就匹配 no部分。
我們需要做的是每碰到了左括號,就在黑板上寫一個"group",每碰到一個右括號,就擦掉一個,到了最后就看看黑板上還有沒有--如果有那就證明左括號比右括號多,那匹配就應該失敗。
< #最外層的左括號 [^<>]* #最外層的左括號后面的不是括號的內容 ( ( (?'Open'<) #碰到了左括號,在黑板上寫一個"Open" [^<>]* #匹配左括號后面的不是括號的內容 )+ ( (?'-Open'>) #碰到了右括號,擦掉一個"Open" [^<>]* #匹配右括號后面不是括號的內容 )+ )* (?(Open)(?!)) #在遇到最外層的右括號前面,判斷黑板上還有沒有沒擦掉的"Open";如果還有,則匹配失敗 > #最外層的右括號
平衡組的一個最常見的應用就是匹配HTML,下面這個例子可以匹配嵌套的<div>標簽:<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>.
還有些什么東西沒提到
我已經描述了構造正則表達式的大量元素,還有一些我沒有提到的東西。下面是未提到的元素的列表,包含語法和簡單的說明。你可以在網上找到更詳細的參考資料來學習它們--當你需要用到它們的時候。如果你安裝了MSDN Library,你也可以在里面找到關于.net下正則表達式詳細的文檔。
| \a | 報警字符(打印它的效果是電腦嘀一聲) |
| \b | 通常是單詞分界位置,但如果在字符類里使用代表退格 |
| \t | 制表符,Tab |
| \r | 回車 |
| \v | 豎向制表符 |
| \f | 換頁符 |
| \n | 換行符 |
| \e | Escape |
| \0nn | ASCII代碼中八進制代碼為nn的字符 |
| \xnn | ASCII代碼中十六進制代碼為nn的字符 |
| \unnnn | Unicode代碼中十六進制代碼為nnnn的字符 |
| \cN | ASCII控制字符。比如\cC代表Ctrl+C |
| \A | 字符串開頭(類似^,但不受處理多行選項的影響) |
| \Z | 字符串結尾或行尾(不受處理多行選項的影響) |
| \z | 字符串結尾(類似$,但不受處理多行選項的影響) |
| \G | 當前搜索的開頭 |
| \p{name} | Unicode中命名為name的字符類,例如\p{IsGreek} |
| (?>exp) | 貪婪子表達式 |
| (?<x>-<y>exp) | 平衡組 |
| (?im-nsx:exp) | 在子表達式exp中改變處理選項 |
| (?im-nsx) | 為表達式后面的部分改變處理選項 |
| (?(exp)yes|no) | 把exp當作零寬正向先行斷言,如果在這個位置能匹配,使用yes作為此組的表達式;否則使用no |
| (?(exp)yes) | 同上,只是使用空表達式作為no |
| (?(name)yes|no) | 如果命名為name的組捕獲到了內容,使用yes作為表達式;否則使用no |
| (?(name)yes) | 同上,只是使用空表達式作為no |
聯系作者
好吧,我承認,我騙了你,讀到這里你肯定花了不止30分鐘.相信我,這是我的錯,而不是因為你太笨.我之所以說"30分鐘",是為了讓你有信心,有耐心繼續下去.既然你看到了這里,那證明我的陰謀成功了.上這種當的滋味還不錯吧?
要投訴我,或者覺得我其實可以做得更好,或者有任何其它問題,歡迎來我的博客進行討論.
一些我認為你可能已經知道的術語的參考
- 字符
- 程序處理文字時最基本的單位,可能是字母,數字,標點符號,空格,換行符,漢字等等。
- 字符串
- 0個或更多個字符的序列。
- 文本
- 文字,字符串。
- 匹配
- 符合規則,檢驗是否符合規則,符合規則的部分。
- 斷言
- 聲明一個應該為真的事實。只有當斷言為真時才會對正則表達式繼續進行匹配。
網上的資源及本文參考文獻
- 微軟的正則表達式教程
- System.Text.RegularExpressions.Regex類(MSDN)
- 專業的正則表達式教學網站(英文)
- 關于.Net下的平衡組的詳細討論(英文)
- Mastering Regular Expressions (Second Edition)
]]>
]]>
適配器模式是使用面向對象設計概念的優秀示例,其中一個原因就是因為他非常簡單。
同時,它也是有關三個重要設計原則的優秀示例:委托,繼承和抽象。
概念UML類圖
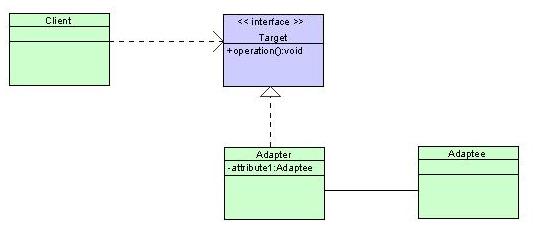
實例類圖
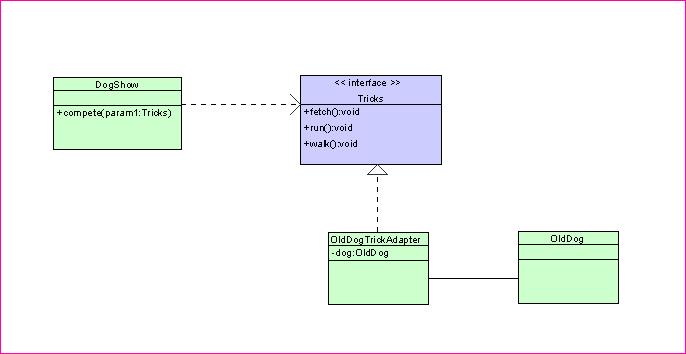
 // Triks.java
// Triks.java2
3
package oyjpart.designpattern;4
5

 public interface Tricks
public interface Tricks  {
{6
 public void walk();
public void walk();7
public void run();8
public void fetch();9
 }
}10
// DogShow.java2
3
package oyjpart.designpattern;4
5
public class DogShow {6

 public void compete(Tricks target) {
public void compete(Tricks target) {7
target.run();8
target.walk();9
target.fetch();10
 }
}11
12
public static void main(String[] args) {13
OldDog oldDog = new OldDog("Tim");14
OldDogTricksAdapter oldDogTricksAdapter = new OldDogTricksAdapter(oldDog); 15
new DogShow().compete(oldDogTricksAdapter);16
}17
}18
19
// OldDog.java2
3
package oyjpart.designpattern;4
5
public class OldDog {6
String name;7
8
public OldDog(String name) {9
this.name = name;10
}11
12
public void walk() {13
System.out.println("Old Dog " + name + " is walking");14
}15
16
public void sleep() {17
System.out.println("Old Dog " + name + " is sleeping");18
}19
20
}21
22
2
// OldDogTricksAdapter.java3
4
package oyjpart.designpattern;5
6
public class OldDogTricksAdapter implements Tricks {7
private OldDog adaptee;8
9
public OldDogTricksAdapter(OldDog oldDog) {10
this.adaptee = oldDog;11
}12
13
public void walk() {14
System.out.println("This dog can walk");15
}16
17
public void fetch() {18
System.out.println("This dog cannot fetch");19
}20
21
public void run() {22
System.out.println("This dog cannot run");23
}24
}25
26
]]>