本文主要探討一下windows平臺上的完成端口開發及其與之相關的幾個重要的技術概念,這些概念都是與基于IOCP的開發密切相關的,對開發人員來講,又不得不給予足夠重視的幾個概念:
1) 基于IOCP實現的服務吞吐量
2)IOCP模式下的線程切換
3)基于IOCP實現的消息的亂序問題。
一����、IOCP簡介
提到IOCP����,大家都非常熟悉,其基本的編程模式,我就不在這里展開了����。在這里我主要是把IOCP中所提及的概念做一個基本性的總結�。IOCP的基本架構圖如下:
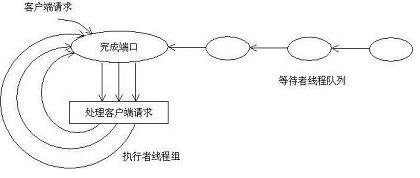
如圖所示:在IOCP中����,主要有以下的參與者:
--》完成端口:是一個FIFO隊列,操作系統的IO子系統在IO操作完成后,會把相應的IO packet放入該隊列。
--》等待者線程隊列:通過調用GetQueuedCompletionStatus API����,在完成端口上等待取下一個IO packet�。
--》執行者線程組:已經從完成端口上獲得IO packet����,在占用CPU進行處理。
除了以上三種類型的參與者����。我們還應該注意兩個關聯關系�,即:
--》IO Handle與完成端口相關聯:任何期望使用IOCP的方式來處理IO請求的����,必須將相應的IO Handle與該完成端口相關聯�。需要指出的時,這里的IO Handle����,可以是File的Handle,或者是Socket的Handle���。
--》線程與完成端口相關聯:任何調用GetQueuedCompletionStatus API的線程���,都將與該完成端口相關聯����。在任何給定的時候����,該線程只能與一個完成端口相關聯,與最后一次調用的GetQueuedCompletionStatus為準�。
二�、高并發的服務器(基于socket)實現方法
一般來講����,實現基于socket的服務器,有三種實現的方式(thread per request的方式���,我就不提了:)):
第一、線程池的方式���。使用線程池來對客戶端請求進行服務。使用這種方式時���,當客戶端對服務器的連接是短連接(所謂的短連接,即:客戶端對服務器不是長時間連接)時����,是可以考慮的。但是�,如若客戶端對服務器的連接是長連接時���,我們需要限制服務器端的最大連接數目為線程池線程的最大數目�,而這應用的設計本身來講����,是不好的設計方式���,scalability會存在問題�。
第二���、基于Select的服務器實現���。其本質是�,使用Select(操作系統提供的API)來監視連接是否可讀,可寫�,或者是否出錯�。相比于前一種方式����,Select允許應用使用一個線程(或者是有限幾個線程)來監視連接的可讀寫性。當有連接可讀可寫時���,應用可以以non-bolock的方式讀寫socket上的數據。使用Select的方式的缺點是����,當Select所監視的連接數目在千的數量級時�,性能會打折扣���。這是因為操作系統內核需要在內部對這些Socket進行輪詢����,以檢查其可讀寫性�。另一個問題是:應用必須在處理完所有的可讀寫socket的IO請求之后,才能再次調用Select,進行下一輪的檢查,否則會有潛在的問題。這樣����,造成的結果是���,對一些請求的處理會出現饑餓的現象����。
一般common的做法是Select結合Leader-Follower設計模式使用�。不過不管怎樣,Select的本質造成了其在Scalability的問題是不如IOCP,這也是很多high-scalabe的服務器采用IOCP的原因。
第三、IOCP實現高并發的服務器。IOCP是實現high-scalabe的服務器的首選�。其特點我們專門在下一小姐陳述�。
三����、IOCP開發的幾個概念
第一、服務器的吞吐量問題。
我們都知道,基于IOCP的開發是異步IO的����,也正是這一技術的本質����,決定了IOCP所實現的服務器的高吞吐量����。
我們舉一個及其簡化的例子,來說明這一問題。在網絡服務器的開發過程中����,影響其性能吞吐量的,有很多因素����,在這里����,我們只是把關注點放在兩個方面����,即:網絡IO速度與Disk IO速度。我們假設:在一個千兆的網絡環境下���,我們的網絡傳輸速度的極限是大概125M/s,而Disk IO的速度是10M/s����。在這樣的前提下����,慢速的Disk 設備會成為我們整個應用的瓶頸。我們假設線程A負責從網絡上讀取數據�,然后將這些數據寫入Disk����。如果對Disk的寫入是同步的�,那么線程A在等待寫完Disk的過程是不能再從網絡上接受數據的,在寫入Disk的時間內,我們可以認為這時候Server的吞吐量為0(沒有接受新的客戶端請求)����。對于這樣的同步讀寫Disk�,一些的解決方案是通過增加線程數來增加服務器處理的吞吐量����,即:當線程A從網絡上接受數據后,驅動另外單獨的線程來完成讀寫Disk任務。這樣的方案缺點是:需要線程間的合作,需要線程間的切換(這是另一個我們要討論的問題)。而IOCP的異步IO本質����,就是通過操作系統內核的支持,允許線程A以非阻塞的方式向IO子系統投遞IO請求�,而后馬上從網絡上讀取下一個客戶端請求����。這樣���,結果是:在不增加線程數的情況下����,IOCP大大增加了服務器的吞吐量。說到這里�,聽起來感覺很像是DMA���。的確�,許多軟件的實現技術����,在本質上,與硬件的實現技術是相通的�。另外一個典型的例子是硬件的流水線技術�,同樣�,在軟件領域,也有很著名的應用����。好像話題扯遠了����,呵呵:)
第二�、線程間的切換問題。
服務器的實現�,通過引入IOCP���,會大大減少Thread切換帶來的額外開銷。我們都知道,對于服務器性能的一個重要的評估指標就是:System\Context Switches����,即單位時間內線程的切換次數����。如果在每秒內���,線程的切換次數在千的數量級上���,這就意味著你的服務器性能值得商榷����。Context Switches/s應該越小越好。說到這里���,我們來重新審視一下IOCP。
完成端口的線程并發量可以在創建該完成端口時指定(即NumberOfConcurrentThreads參數)。該并發量限制了與該完成端口相關聯的可運行線程的數目(就是前面我在IOCP簡介中提到的執行者線程組的最大數目)�。當與該完成端口相關聯的可運行線程的總數目達到了該并發量���,系統就會阻塞任何與該完成端口相關聯的后續線程的執行�,直到與該完成端口相關聯的可運行線程數目下降到小于該并發量為止。最有效的假想是發生在有完成包在隊列中等待����,而沒有等待被滿足���,因為此時完成端口達到了其并發量的極限�。此時����,一個正在運行中的線程調用GetQueuedCompletionStatus時�,它就會立刻從隊列中取走該完成包。這樣就不存在著環境的切換,因為該處于運行中的線程就會連續不斷地從隊列中取走完成包����,而其他的線程就不能運行了����。
完成端口的線程并發量的建議值就是你系統CPU的數目����。在這里,要區分清楚的是���,完成端口的線程并發量與你為完成端口創建的工作者線程數是沒有任何關系的,工作者線程數的數目,完全取決于你的整個應用的設計(當然這個不宜過大,否則失去了IOCP的本意:))���。
第三、IOCP開發過程中的消息亂序問題。
使用IOCP開發的問題在于它的復雜�。我們都知道�,在使用TCP時���,TCP協議本身保證了消息傳遞的次序性���,這大大降低了上層應用的復雜性����。但是當使用IOCP時,問題就不再那么簡單。如下例:
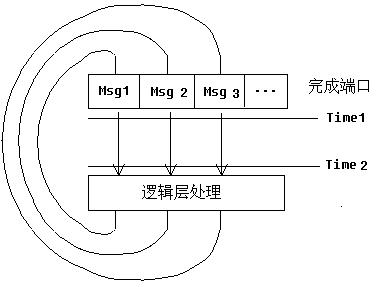
三個線程同時從IOCP中讀取Msg1, Msg2,與Msg3。由于TCP本身消息傳遞的有序性���,所以,在IOCP隊列內,Msg1-Msg2-Msg3保證了有序性�。三個線程分別從IOCP中取出Msg1,Msg2與Msg3,然后三個線程都會將各自取到的消息投遞到邏輯層處理����。在邏輯處理層的實現�,我們不應該假定Msg1-Msg2-Msg3順序�,原因其實很簡單,在Time 1~Time 2的時間段內���,三個線程被操作系統調度的先后次序是不確定的,所以在到達邏輯處理層���,
Msg1,Msg2與Msg3的次序也就是不確定的。所以���,邏輯處理層的實現,必須考慮消息亂序的情況�,必須考慮多線程環境下的程序實現����。
在這里�,我把消息亂序的問題單列了出來。其實在IOCP的開發過程中�,相比于同步的方式���,應該還有其它更多的難題需要解決�,這也是與Select方式相比���,IOCP的缺點����,實現復雜度高。
結束語:
ACE的Proactor Framework����, 對windows平臺的IOCP做了基于Proactor設計模式的���,面向對象的封裝�,這在一定程度上簡化了應用開發的難度,是一個很好的異步IO的開發框架���,推薦學習使用���。
Reference:
Microsoft Technet,Inside I/O Completion Ports