文章出處:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/winui/winui/windowsuserinterface/userinput/rawinput/aboutrawinput.asp
關于原始輸入
除了傳統的鍵盤和鼠標以外還有很多其他的輸入設備。例如:用戶輸入可以來自游戲桿設備,觸摸屏,麥克風以及其他可以提供用戶輸入的設備。這些設備被統稱為HID(人體工程學)設備。Raw Input的API為應用程序提供了穩定健壯的讀取原始數據數據的方式,包括鍵盤和鼠標。
這篇文章主要包括3個部分:
·??????????????? 原始輸入模型
·??????????????? 注冊原始輸入
·??????????????? 讀取原始輸入
原始輸入模型
以前鼠標和鍵盤數據處理模式是這樣的,鼠標和鍵盤產生輸入數據,系統中斷去處理這些與設備信息相關的數據,讓這些數據變得與設備無關。例如:鍵盤產生與鍵盤設備相關的ScanCode但是系統提供給應用程序虛擬鍵碼。除了隱藏原始輸入的細節,Windows管理器還不支持所有新的HID設備。為了要從HID設備里面得到信息,一個應用程序必須處理以下步驟:打開設備,管理共享模式,周期性讀取設備或者設置IO完成端口,或者更多操作。原始輸入模型及其相關的API允許比較容易的從輸入設備中獲取原始輸入,包括鍵盤和鼠標。
那么原始輸入模型和微軟原來的鼠標鍵盤輸入模型有什么差別呢?在原來的輸入模型,一個應用程序通過發送到他窗口的消息獲取與設備無關的消息,例如WM_CHAR,WM_MOUSEMOVE和WM_APPCOMMAND。與之原來模式不同的是:一個應用程序想獲取原始數據的必須注冊他想要獲取原始輸入的那些設備,應用程序會收到WM_INPUT消息。
原始輸入模型有很多優點:
- ?應用程序不需要查找和打開輸入設備。
- ?應用程序直接從設備獲取數據并根據他們的需要獲取數據。
- 應用程序能夠甄別來自兩個不同設備的輸入,盡管他們有可能是同一個類型的設備。例如:兩個鼠標設備。
- 應用程序能夠管理數據流,可以從一類設備或者某種制定類型設備獲取輸入數據。
- 當HID設備在市場上可以買到時候,能夠立即被使用,而不需要等待操作系統更新新的消息定義或者操作系統更新WM_APPCOMMAND消息。
需要注意的是:WM_APPCOMMAND確實是為一些HID設備提供的。然而WM_APPCOMMAND是一個高層的非設備相關的輸入事件,而WM_INPUT消息發送原始的底層的設備相關的消息。
注冊原始輸入
默認情況下,沒有應用程序會接受WM_INPUT消息。為了接受從一個設備發送原始輸入,你必須注冊這個設備。
為了注冊這個設備,一個應用程序首先必須創建一個指明他所希望接受設備類別的(top level collection――
TLC)RAWINPUTDEVICE結構。TLC被定義成為UsagePage(設備類)和Usage(設備類內的具體設備)。例如為了從鍵盤獲取原始輸入,設置UsagePage = 1 and Usage = 6,應用程序調用RegisterRawInputDevice去注冊這個設備。
注意:應用程序可以注冊系統當前沒有的設備。當設備可用之后,Windows管理器會自動將原始輸入數據發送到應用程序。應用程序可以調用GetRawInputDeviceList來獲取系統中原始輸入設備的列表。用GetRawInputDeviceList獲取的hDevice,應用程序調用GetRawInputDeviceInfo獲取設備信息。
通過RAWINPUTDEVICE中的dwFlag,應用程序可以選擇是否監聽還是忽略來自某個指定設備的信息。例如:一個應用程序能夠監聽所有的電話設備除了答錄機。
注意:鼠標和鍵盤也是HID設備,所以能夠從Hid設備的WM_INPUT消息或者從傳統的消息中獲取信息。應用程序能夠通過指定RAWINPUTDEVICE中的標志位選擇任意一個。
可以調用GetRegisteredRawInputDevice來得到應用程序的該設備的注冊狀態。
讀取原始輸入
應用程序會收到符合所注冊的TLC的HID設備的原始輸入消息。當一個應用程序收到了原始輸入,應用程序的消息隊列就會得到一個WM_INPUT消息,系統狀態被置成QS_RAWINPUT(QS_INPUT)同樣包含這個標志。不管應用程序在前臺和后臺都能夠收到消息。
有兩種方法去讀取原始數據:標準(沒有緩沖的)方法和緩沖方法。前者獲取原始輸入時,每次獲取一個RAWINPUT數據,而且對于大多數HID設備都是可以用這種方式讀取的。應用程序調用CallMessage得到WM_INPUT消息,然后應用程序通過WM_INPUT消息,調用GetRawInputData來獲取RAWINPUT句柄。
相對應的,緩存方式每次得到一系列的RAWINPUT結構。這是給那些能夠構產生很大數據量的原始輸入。用這種方法去獲取數據,首先調用GetRawInputBuffer去獲取一系列的RAWINPUT結構。注意NEXTTRAWINPUTBLOCK宏是用來獲取下一個RAWINPUT結構的。
為了獲取原始輸入HID設備的詳細信息。應用程序可以用GetRawInputdeviceInfo來查詢相對應的句柄。這個句柄可以是從WM_INPUT消息或者RAWINPUTHRADER.hDevice獲取。
posted @
2006-09-15 22:12 CPP&&設計模式小屋 閱讀(4453) |
評論 (3) |
編輯 收藏版權所有 未經作者允許 不得用于商業用途 轉載請附帶這第一,二行
http://www.shnenglu.com/shenhuafeng/
Modern C++ Design的第一章就是Policy Based Class Design,可見該技術是整個Loki庫的設計基礎.這種方式的優點是能夠增加程序庫的彈性和提高復用性.
簡單來說就是,一個Policy Based Class由很多基本的Policy來組成的,每個Policy Class代表了該復雜類(相對復雜)類的某些行為或者特性.有點類似于類的繼承,當然和類的繼承是不同的。
那么Policy Based Class有什么用呢?我們先看下面這個問題。
假如需要設計一個基礎庫,可能是基于某個特定領域的,那么庫的設計者就需要考慮這樣的問題,他需要將未來的可能的需求加以分類,抽象出層次,然后運用OO思想,希望能夠構造出一個開發的結構,當然其中的component的設計當然是越是靈活越好。
用傳統的OO設計思想,可能可以設計出一套非常完善的類庫 ,可能包羅萬象。當然的對于應用開發人員需要花很多時間去學習這個“包羅萬象”的基礎類庫。而且往往這樣的基礎庫不是通用性不強就是限制條件太多(例如MFC)可以說就是這樣一種類型的庫。
下面要展示一下運用多重繼承以及Templetes來實現的policy class,舉一個簡單的例子:
假如我們需要發明一個燈,它有不同的種類,有使用不同能源的工作方式以及有不同的操作方式,如果運用
policy based class來設計的話,可能是這樣的結構:
?1
 templete
<
templete
<
?2
????
class
?T,
?3
????templete?
<
class
>
?
class
?Work,
?4
????templete?
<
class
>
?
class
?OpMethod
?5
>
?6
class
?Light
?7
????:
public
?Work
<
T
>
,
?8
????????OpMethod
<
Light
>
?9
10


 {
{
11
 ????T
*
?xxOp()
????T
*
?xxOp()
12

 ????
{
????
{
13
????????
if
(Work(T).Status?
==
?ACMODE)
14
????????????OpMethod(
*
this
);
15
 ????}
????}
16
 }
}
當你實例化一個Policy Based Class的時候,你還可以給出默認的實現,就像成員函數聲明和定義時候給出的默認參數一樣。
回頭來看一下多重繼承和Templetes的特性:
多重繼承:欠缺一種一成不變的可以套用的代碼,在某種受控的情況下將繼承的Class組合起來(多重繼承只是將他們放在一起,然后提供一種訪問方式)。Templetes:有這樣的特性。
多重繼承由于繼承自多個Base Class,所以型別信息缺乏,而Templetes正式基于型別的。
多重繼承容易擴張,而Templetes的特化不容易擴張。
正是兩項技術的互補,才使這樣的技術實現成為可能。
Light對象繼承多個policy class,使得特性得以在編譯期間定值,從而實現Light Class功能的擴張。
而Templetes技術使得大部分Work以及OpMethod能夠共享大部分基礎代碼,而對特定的版本實現定值。
這樣的好處就是,應用程序開發人員得以在應用設計時期,使用這些Class,選擇適合自己的Policy組裝自己的代碼,從而使得程序大小得以精減,運行速率得以提高,而不必去包含整個又大又全的基礎類庫。
以上只是一些學習的心得和體會,如果有不對的地方,希望大家多多指教。
posted @
2006-09-13 23:22 CPP&&設計模式小屋 閱讀(2542) |
評論 (4) |
編輯 收藏
前段時間剛剛看完STL源代碼解析,覺得受益非淺,不過總體來說STL的源代碼還是比較淺顯易懂的.最近學習Andrei Alexandrescu的Modern C++ Design,隨后從網站上下載了Loki庫的源代碼,發覺還是有些難度的,準備將學習的點滴記錄于此,每天寫篇學習心得,也算是給自己一個學習的動力吧.
posted @
2006-09-13 11:32 CPP&&設計模式小屋 閱讀(5172) |
評論 (0) |
編輯 收藏
Petar Maymounkov and David Mazi`eres
fpetar,dmg@cs.nyu.edu
?
摘要
本文我們將描述一個在容易出錯的網絡環境中擁有可證實的穩定性和高性能穩定性的點對點(P2P)系統。我們的系統使用一個很新穎的基于異或運算的拓撲來發送查詢并且定位節點, 這簡化了算法并且使驗證更加容易。 這種拓撲結構具有以下特性,它能通過交換消息傳達和加強節點間的有用聯系信息。本系統利用這個信息來發送平行的,異步的查詢消息來對付節點的失效而不會給用戶帶來超時時延。
?
1
.介紹
???
本論文描述Kademlia , 一個點對點(P2P)的<鍵, 值>元組存儲和查詢系統。 Kademlia擁有許多的可喜的特點,這些特點是任何以前的P2P系統所無法同時提供的。它減少了節點必須發送的用來相互認識的配置消息的數量。在做鍵查詢的同時, 配置消息將會被自動傳播。 節點擁有足夠的知識和靈活性來通過低時延路徑發送查詢請求。 Kademlia使用平行的,異步的查詢請求來避免節點失效所帶來的超時時延。通過節點記錄相互的存在的算法可以抵抗某些基本的拒絕服務(DoS)攻擊。 最后, 僅僅使用在分布式運行時間上較弱的假設(通過對現有點對點系統的測量而確認的這些假設),我們可以正式的證實Kademlia的許多重要特性。
??? Kademlia
使用了許多點對點(P2P)系統的基本方法。 鍵是一個160-bit的隱式數量(例如, 對一些大型數據進行SHA-1哈希的值)。 每個參與的機器都擁有一個節點ID, 160位的鍵。 <鍵, 值>對將存儲在那些ID與鍵很‘接近’的節點上, 這里‘接近’當然是按照一個接近度的概念來計算的。最后, 一個基于節點ID的路由算法使得任何人可以在一個目的鍵附近定位到一個服務器。
Kademlia
的許多的優點都是得益于它使用了一個很新穎的方法, 那就是用節點間的鍵作異或運算的結果來作為節點間的距離。異或運算是對稱的, 允許Kademlia的參與者接收來自相同分布的并且包含在其路由表中的節點的查找請求。如果沒有這個性質,就像Chord一樣,系統無法從它們收到的查詢請求中學習到有用的路由信息。更糟的是, 由于Chord中的運算是不對稱的, Chord的路由表更加嚴格。 Chord節點的查找表的每一項都必須存儲精確的按ID域的間隔遞增的節點。在這個間隔內的任何節點都比這個間隔內的某些鍵大,因此離鍵很遠。相反,Kademlia 可以在一定的間隔內發送請求給任何節點, 允許基于時延來選擇路由,甚至發送平行的,異步的查詢。
為了在特定的ID附近定位節點,Kademlia自始至終使用一個單程的路由算法。相反,其它一些系統使用一種算法來接近目標ID,然后在最后的幾個跳數使用另外一種算法。在現有系統中,Kademlia與pastry的第一階段最像,(雖然作者并沒有用這種方式來描述),Kademlia 的異或運算可以使當前節點到目標ID的距離粗略的持續減半,以此來尋找節點。在第二階段,Pastry不再使用距離運算,而是改為比較ID的數字區別。它使用第二種,數字區別運算作為替代。不幸的是,按第二種運算計算的接近比第一種的遠得多,這造成特定節點ID值的中斷,降低了性能,并且導致在最差行為下的正式分析的嘗試失敗。
?
2
.系統描述
每個Kademlia節點有一個160位的節點ID。在Chord系統中,ID是通過某種規則構造出來的,但在這片文章中,為了簡化,我們假設每臺機器在加入系統時將選擇一個隨機的160位值。每條節點發送的消息包含它的節點ID, 同時允許接收者記錄下發送者的存在信息,如果有必要的話。
鍵,同樣也是160位的標識符。為了發布和尋找<鍵,值>對,Kademlia依賴一個概念,那就是兩標識符之間的距離的概念。給定兩個標識符, x和y, Kademlia定義兩者的位異或(XOR)的結果作為兩者的距離,d(x,y)=x⊕y。我們首先注意到異或運算是一個有意義的運算,雖然不是歐幾里得運算。很明顯具有下面的性質: d(x,x)=0;如果x≠y, 則d(x, y)>0;任意的x, y: d(x, y) = d(y, x)。 異或運算還滿足三角性質:d(x, y) + d(y, z) ≥ d(x, z)。 這個三角性質之所以成立是基于下面這個事實: d(x, z) = d(x, y) + d(y, z); 并且任意的a>=0, b≥0: a+b≥a⊕b。
跟Chord的順時針循環運算一樣,異或運算也是單向的。對于給定的一個點x以及距離Δ,僅有一個點y,使得d(x, y) = Δ。 單向性確保所有對于相同的鍵的查詢將匯聚到相同路徑中來,而不管是什么起源節點。因此,在查找路徑上緩存<鍵,值>對可以減少‘撞車’的機會。跟Pastry而不是Chord一樣, 異或運算也是對稱的。(對所有的x以及y, d(x,y) = d(y,x))
?
2
.1.節點狀態
Kademlia
節點存儲互相的聯系信息,以用于路由查詢消息。對于任何0 =< i < 160, 每個節點保存那些到本節點的距離為2i 到2i+1之間的節點信息列表,包括<IP地址,UDP端口, 節點ID>。我們把這些列表稱為K-桶。每個K-桶中的節點按最后聯系的時間排序――最久未聯系的節點放在頭部,最近聯系的節點放在尾部。對于比較小的i值,K-桶通常是空的(因為沒有合適的節點存在于系統中)。對于比較大的i值,列表節點數可以達到k的大小,k是一個系統級別的冗余參數。k值的選擇必須滿足一個條件,那就是任意k個節點在一個小時內都失效的可能性很小(例如k =20)。
圖1:
以當前已在線時間的函數的形式顯示了節點在接下來的一小時后繼續在線的比例。X軸代表分鐘,y軸代表那些已經在線了x分鐘的節點中將繼續在線1小時的比例。
?
當一個Kademlia節點收到來自另外一個節點的任何消息(請求的或者回復的),它將更新自己的一個K-桶,即發送節點ID對應的那個桶。如果發送節點已經存在于接收者的K-桶中,接收者會把它移到列表的尾部。如果這個節點還沒有存在于對應的K-桶中并且這個桶少于k個節點,則接收者把發送者插入到列表的尾部。如果對應的K-桶已經滿了,則發送者將向該K-桶中的最久未聯系節點發送ping命令測試是否存在,如果最久未聯系節點沒有回復,則把它從列表中移除,并把新的發送者插入到列表尾部。如果它回復了,則新的發送者信息會丟棄掉。
K-
桶非常高效的實現了剔除最久未聯系節點的策略,存活的節點將永遠不會從列表中移除。這種偏向保留舊節點的做法是我們對由Saroiu等人收集的Gnutella協議的跟蹤數據進行分析而得出來的。圖1以當前已存在時間的函數的形式顯示了Gnutella節點在一小時后繼續在線的比例。一個節點存活的時間越長,則這個節點繼續存活一小時的可能性越大。通過保留存活時間最長的那些節點,K-桶中存儲的節點繼續在線的概率大大提高了。
K-
桶的第二個優點是它提供了對一定的拒絕服務(DoS)的攻擊的抵抗。系統中不斷涌入新節點并不會造成節點路由狀態的更新過快。Kademlia節點只有在舊節點離開系統時才會向k-桶中插入新節點。
?
2
.2.Kademlia協議
Kademlia
協議由4個遠程過程調用(RPC)組成:PING,STORE,FIND_NODE, FIND_VALUE。 PING RPC 測試節點是否存在。STORE指示一個節點存儲一個<鍵,值>對以用于以后的檢索。
FIND_NODE
把160位ID作為變量,RPC的接收者將返回k個它所知道的最接近目標ID的<IP地址,UDP端口,節點ID>元組。這些元組可以來自于一個K-桶,也可以來自于多個K-桶(當最接近的K-桶沒有滿時)。在任何情況下, RPC接收者都必須返回k項(除非這個節點的所有的K-桶的元組加起來都少于k個,這種情況下RPC接收者返回所有它知道的節點)
FIND_VALUE
和FIND_NODE行為相似――返回<IP地址,UDP端口,節點ID>元組。僅有一點是不同的,如果RPC接收者已經收到了這個鍵的STORE RPC,則只需要返回這個已存儲的值。
在所有RPC中,接收者都必須回應一個160位的隨機RPC ID,這可以防止地址偽造。PING中則可以為RPC接收者在RPC回復中捎回以對發送者的網絡地址獲得額外的保證。
Kademlia
參與者必須做的最重要的工作是為一個給定的節點ID定位k個最接近節點。我們稱這個過程為節點查詢。Kademlia使用一種遞歸算法來做節點查詢。查詢的發起者從最接近的非空的K-桶中取出а個節點(或者,如果這個桶沒有а項,則只取出它所知道的最接近的幾個節點)。發起者然后向選定的а個節點發送平行的,異步的FIND_NODE RPC。а是一個系統級別的并行參數,比如為3。
在這個遞歸的步驟中,發起者重新發送FIND_NODE給那些從上次RPC中學習到的節點(這個遞歸可以在之前的所有的а個RPC返回之前開始)。在這返回的與目標最接近的k個節點中,發起者將選擇а個還沒有被詢問過的節點并且重新發送FIND_NODE RPC給它們。沒有立即作出響應的節點將不再予以考慮除非并且直到它們作出響應。如果經過一輪的FIND_NODE都沒有返回一個比已知最接近的節點更接近的節點,則發起者將重新向所有k個未曾詢問的最接近節點發送FIND_NODE。直到發起者已經詢問了k個最接近節點并且得到了響應,這個查詢才結束。當а=1時,查詢算法在消息開支和檢測失效節點時的時延上與Chord非常相似。 然而,Kademlia可以做到低時延路由因為它有足夠的靈活性來選擇k個節點中的一個去做查詢。
按照上面的查詢過程,大多數的操作都可以實現。要存儲一個<鍵,值>對,參與者定位k個與鍵最接近的節點然后向這些節點發送STORE RPC。另外,每個節點每個小時都會重新發布它所有的<鍵,值>對。這可以以高概率的把握確保<鍵,值>對的持續存在于系統中(我們將會在驗證概略一節中看到)。通常來說,我們還要求<鍵,值>對的原始發布者每隔24小時重新發布一次。否則,所有的<鍵,值>對在最原始發布的24小時后失效,以盡量減少系統中的陳舊信息。
最后,為了維持<鍵,值>對在發布-搜索生命周期中的一致性,我們要求任何時候節點w擁有一個新節點u,u比w更接近w中的一些<鍵,值>對。w將復制這些<鍵,值>對給u并且不從自己的數據庫中刪除。
為了查找到一個<鍵,值>對,節點首先查找k個ID與鍵接近的節點。然而,值查詢使用FIND_VALUE而不是FIND_NODE RPC。 而且,只要任何節點返回了值,則這個過程立即結束。為了緩存(caching)的緣故,只要一個查詢成功了,這個請求節點將會把這個<鍵,值>對存儲到它擁有的最接近的并且沒能返回值的節點上。
由于這個拓撲的單向性,對相同的鍵的以后的搜索將很有可能在查詢最接近節點前命中已緩存的項。對于一個特定的鍵,經過多次的查找和傳播,系統可能在許多的節點上都緩存了這個鍵。為了避免“過度緩存”,我們設計了一個<鍵,值>對在任何節點的數據庫中的存活時間與當前節點和與鍵ID最接近的節點ID之間的節點數成指數級的反比例關系。簡單的剔除最久未聯系節點會導致相似的生存時間分布,沒有很自然的方法來選擇緩存大小,因為節點不能提前知道系統將會存儲多少個值。
???
一般來說,由于存在于節點之間的查詢的通信,桶會保持不停地刷新。為了避免當沒有通信時的病態情況,每個節點對在一個小時內沒有做過節點查詢的桶進行刷新,刷新意味著在桶的范圍內選擇一個隨機ID然后為這個ID做節點搜索。
為了加入到這個網絡中,節點u必須與一個已經加入到網絡中的節點w聯系。u把w加入到合適的桶中,然后u為自己的節點ID做一次節點查找。最后,節點u刷新所有比最接近的鄰居節點更遠的K-桶。在這個刷新過程中,節點u進行了兩項必需的工作:既填充了自己的K-桶,又把自己插入到了其它節點的K-桶中。
?
3
.驗證概述
為了驗證我們系統中的特有的函數,我們必須證實絕大多數的操作花費
[
log
n]
+
c
的時間開銷,并且c是一個比較小的常數,并且
<
鍵,值>查找將會以很高的概率返回一個存儲在系統中的鍵。
我們首先做一些定義。對于一個覆蓋距離的范圍為
[
2
i
,
2
i
+1)
的
K-
桶,定義這個桶的索引號為i。定義節點的深度h為160-i,其中i是最小的非空的桶的索引號。定義在節點x中節點y的桶高度為y將插入到x的桶的索引號減去x的最不重要的空桶的索引號。由于節點ID是隨機選擇的,因此高度的不統一分布是不太可能的。因此,在非常高的概率下,任意一個給定節點的高度在log n之內,其中n是系統中的節點數。而且,對于一個ID,最接近節點在第k接近的節點中的桶高度很有可能是在常數log k之內。
下一步我們將假設一個不變的條件,那就是每個節點的每個K-桶包含至少一個節點的聯系信息,如果這個節點存在于一個合適的范圍中。有了這個假設,我們可以發現節點的查找過程是正確的并且時間開銷是指數級的。假設與目標ID最接近的節點的深度是h。如果這個節點的h個最有意義的K-桶都是非空的,查詢過程在每一步都可以查找到一個到目標節點的距離更接近一半的節點(或者說距離更近了一個bit),因此在
h
-
log
k
步后目標節點將會出現。
如果這個節點的一個K-桶是空的,可能是這樣的一種情況,目標節點恰好在空桶對應的距離范圍之內。這種情況下,最后的幾步并不能使距離減半。然而,搜索還是能正確的繼續下去就像鍵中與空桶相關的那個位已經被置反了。因此,查找算法總是能在
h
-
log
k
步后
返回最接近節點。而且,一旦最接近節點已經找到,并行度會從а擴展到k。尋找到剩下的k-1個最接近節點的步數將不會超過最接近節點在第k接近節點中的桶高度,即不太可能超過log k加上一個常數。
為了證實前面的不變條件的正確性,首先考慮桶刷新的效果,如果不變條件成立。在被刷新后,一個桶或者包含k個有效節點,或者包含在它范圍內的所有節點,如果少于k個節點存在的話(這是從節點的查找過程的正確性而得出來的。)新加入的節點也會被插入到任何沒有滿的桶中去。因此,唯一違反這個不變條件的方法就是在一個特別的桶的范圍內存在k+1個活更多的節點,并且桶中的k個節點在沒有查找或刷新的干涉下全部失效。然而,k值被精確的選擇以保證使所有節點在一小時內(最大的刷新時間)全都失效的概率足夠小。
實際上,失敗的概率比k個節點在1小時內全都離開的概率小得多,因為每個進入或外出的請求消息都會更新節點的桶。這是異或運算的對稱性產生的,因為在一次進入或外出的請求中,與一個給定節點通信的對端節點的ID在該節點的桶范圍之內的分布是非常均勻的。
而且,即使這個不變條件在單個節點的單個桶中的確失效了,這也只影響到運行時間(在某些查詢中添加一個跳數),并不會影響到節點查找的正確性。只有在查找路徑中的k個節點都必須在沒有查找或刷新的干涉下在相同的桶中丟失k個節點,才可能造成一次查找失敗。如果不同的節點的桶沒有重疊,這種情況發生的概率是2-k*k。否則,節點出現在多個其它的節點的桶中,這就很可能會有更長的運行時間和更低概率的失敗情況。
現在我們來考慮下<鍵,值>對的恢復問題。當一個<鍵,值>對發布時,它將在k個與鍵接近的節點中存儲。同時每隔一小時將重新發布一次。因為即使是新節點(最不可靠的節點)都有1/2的概率持續存活一個小時,一個小時后<鍵,值>對仍然存在于k個最接近節點中的一個上的概率是1-2-k
。
這個性質并不會由于有接近鍵的新節點的插入而改變,因為一旦有這樣的節點插入,它們為了填充它們的桶將會與他們的最接近的那些節點交互,從而收到附近的它們應該存儲的<鍵,值>對。當然,如果這k個最接近鍵的節點都失效了,并且這個<鍵,值>對沒有在其它任何地方緩存,Kademlia將會丟失這個<鍵,值>對。
?
4
.討論
我們使用的基于異或拓撲的路由算法與Pastry [1], Tapestry [2]的路由算法中的第一步和 Plaxton的分布式搜索算法都非常的相似。然而,所有的這三個算法,當他們選擇一次接近目標節點b個bit的時候都會產生問題(為了加速的目的)。如果沒有異或拓撲,我們還需要一個額外的算法結構來從與目標節點擁有相同的前綴但是接下來的b個bit的數字不同的節點找到目標節點。所有的這三個算法在解決這個問題上采取的方法都是各不相同的,每個都有其不足之處;它們在大小為
O
(2
b
log
2
b
n
)
的主表之外
都
另外
需要
一個
大小為
O
(2
b
)
的
次要路由表,這增加了自舉和維護的開支,使協議變的更加復雜了,而且對于Pastry和Tapestry來說阻止了正確性與一致性的正式分析。Plaxton雖然可以得到證實,但在像點對點(P2P)網絡中的極易失效的環境中不太適應。
相反,Kademlia則非常容易的以不是2的基數被優化。我們可以配置我們的桶表來使每一跳b個bit的速度來接近目標節點。這就要求滿足一個條件,那就是任意的
0
< j < 2b
和
0
≤
i <
160
/b
,
在與我們的距離為[j2160-(i+1)b, (j+1)2160-(i+1)b]
的范圍內就要有一個桶,這個有實際的項的總量預計不會超過個桶。目前的實現中我們令b=5。
?
5
.總結
使用了新穎的基于異或運算的拓撲,Kademlia是第一個結合了可證實的一致性和高性能,最小時延路由,和一個對稱,單向的拓撲的點對點(P2P)系統。此外,Kademlia引入了一個并發參數,а,這讓人們可以通過調整帶寬的一個常數參數來進行異步最低時延的跳選擇和不產生時延的失效恢復。最后,Kademlia是第一個利用了節點失效與它的已運行時間成反比這個事實的點對點(P2P)系統。
?
參考文獻
[1] A. Rowstron and P. Druschel. Pastry: Scalable, distributed object location and routing for large-scale peer-to-peer systems. Accepted for Middleware, 2001, 2001. http://research.microsoft.com/?antr/pastry/.
?
[2] Ben Y. Zhao, John Kubiatowicz, and Anthony Joseph. Tapestry: an infrastructure for fault-tolerant wide-area location and routing. Technical Report UCB/CSD-01-1141, U.C. Berkeley, April 2001.
?
[3] Andr′ea W. Richa C. Greg Plaxton, Rajmohan Rajaraman. Accessing nearby copies of replicated objects in a distributed environment. In Proceedings of the ACM SPAA, pages 311–320, June 1997.
?
[4] Stefan Saroiu, P. Krishna Gummadi and Steven D. Gribble. A Measurement Study of Peer-to-Peer File Sharing Systems. Technical Report UW-CSE-01-06-02, University of Washington, Department of Computer Science and Engineering, July 2001.
?
[5] Ion Stoica, Robert Morris, David Karger, M. Frans Kaashoek, and Hari Balakrishnan. Chord: A scalable peer-to-peer lookup service for internet applications. In Proceedings of the ACM SIGCOMM ’01 Conference, San Diego, California, August 2001.
posted @
2006-09-11 16:18 CPP&&設計模式小屋 閱讀(1999) |
評論 (0) |
編輯 收藏
前兩天在網上看到世界知名的電騾服務器Razorback 2被查封、4人被拘禁的消息,深感當前做eMule / BitTorrent等P2P文件交換軟件的不易。以分布式哈希表方式(DHT,Distributed Hash Table)來代替集中索引服務器可以說是目前可以預見到的為數不多的P2P軟件發展趨勢之一,比較典型的方案主要包括:CAN、CHORD、Tapestry、Pastry、Kademlia和Viceroy等,而Kademlia協議則是其中應用最為廣泛、原理和實現最為實用、簡潔的一種,當前主流的P2P軟件無一例外地采用了它作為自己的輔助檢索協議,如eMule、Bitcomet、Bitspirit和Azureus等。鑒于Kademlia日益增長的強大影響力,今天特地在blog里寫下這篇小文,算是對其相關知識系統的總結。
1. Kademlia簡述
Kademlia(簡稱Kad)屬于一種典型的結構化P2P覆蓋網絡(Structured P2P Overlay Network),以分布式的應用層全網方式來進行信息的存儲和檢索是其嘗試解決的主要問題。在Kademlia網絡中,所有信息均以的哈希表條目形式加以存儲,這些條目被分散地存儲在各個節點上,從而以全網方式構成一張巨大的分布式哈希表。我們可以形象地把這張哈希大表看成是一本字典:只要知道了信息索引的key,我們便可以通過Kademlia協議來查詢其所對應的value信息,而不管這個value信息究竟是存儲在哪一個節點之上。在eMule、BitTorrent等P2P文件交換系統中,Kademlia主要充當了文件信息檢索協議這一關鍵角色,但Kad網絡的應用并不僅限于文件交換。下文的描述將主要圍繞eMule中Kad網絡的設計與實現展開。
2. eMule的Kad網絡中究竟存儲了哪些信息?
只要是能夠表述成為字典條目形式的信息Kad網絡均能存儲,一個Kad網絡能夠同時存儲多張分布式哈希表。以eMule為例,在任一時刻,其Kad網絡均存儲并維護著兩張分布式哈希表,一張我們可以將其命名為關鍵詞字典,而另一張則可以稱之為文件索引字典。
a. 關鍵詞字典:主要用于根據給出的關鍵詞查詢其所對應的文件名稱及相關文件信息,其中key的值等于所給出的關鍵詞字符串的160比特SHA1散列,而其對應的value則為一個列表,在這個列表當中,給出了所有的文件名稱當中擁有對應關鍵詞的文件信息,這些信息我們可以簡單地用一個3元組條目表示:(文件名,文件長度,文件的SHA1校驗值),舉個例子,假定存在著一個文件“warcraft_frozen_throne.iso”,當我們分別以“warcraft”、“frozen”、“throne”這三個關鍵詞來查詢Kad時,Kad將有可能分別返回三個不同的文件列表,這三個列表的共同之處則在于它們均包含著一個文件名為“warcraft_frozen_throne.iso”的信息條目,通過該條目,我們可以獲得對應iso文件的名稱、長度及其160比特的SHA1校驗值。
b. 文件索引字典:用于根據給出的文件信息來查詢文件的擁有者(即該文件的下載服務提供者),其中key的值等于所需下載文件的SHA1校驗值(這主要是因為,從統計學角度而言,160比特的SHA1文件校驗值可以唯一地確定一份特定數據內容的文件);而對應的value也是一個列表,它給出了當前所有擁有該文件的節點的網絡信息,其中的列表條目我們也可以用一個3元組表示:(擁有者IP,下載偵聽端口,擁有者節點ID),根據這些信息,eMule便知道該到哪里去下載具備同一SHA1校驗值的同一份文件了。
3. 利用Kad網絡搜索并下載文件的基本流程是怎樣的?
基于我們對eMule的Kad網絡中兩本字典的理解,利用Kad網絡搜索并下載某一特定文件的基本過程便很明白了,仍以“warcraft_frozen_throne.iso”為例,首先我們可以通過warcraft、frozen、throne等任一關鍵詞查詢關鍵詞字典,得到該iso的SHA1校驗值,然后再通過該校驗值查詢Kad文件索引字典,從而獲得所有提供“warcraft_frozen_throne.iso”下載的網絡節點,繼而以分段下載方式去這些節點下載整個iso文件。
在上述過程中,Kad網絡實際上所起的作用就相當于兩本字典,但值得再次指出的是,Kad并不是以集中的索引服務器(如華語P2P源動力、Razorback 2、DonkeyServer 等,騾友們應該很熟悉吧)方式來實現這兩本字典的存儲和搜索的,因為這兩本字典的所有條目均分布式地存儲在參與Kad網絡的各節點中,相關文件信息、下載位置信息的存儲和交換均無需集中索引服務器的參與,這不僅提高了查詢效率,而且還提高了整個P2P文件交換系統的可靠性,同時具備相當的反拒絕服務攻擊能力;更有意思的是,它能幫助我們有效地抵制FBI的追捕,因為俗話說得好:法不治眾…看到這里,相信大家都能理解“分布式信息檢索”所帶來的好處了吧。但是,這些條目究竟是怎樣存儲的呢?我們又該如何通過Kad網絡來找到它們?不著急,慢慢來。
4. 什么叫做節點的ID和節點之間的距離?
Kad網絡中的每一個節點均擁有一個專屬ID,該ID的具體形式與SHA1散列值類似,為一個長達160bit的整數,它是由節點自己隨機生成的,兩個節點擁有同一ID的可能性非常之小,因此可以認為這幾乎是不可能的。在Kad網絡中,兩個節點之間距離并不是依靠物理距離、路由器跳數來衡量的,事實上,Kad網絡將任意兩個節點之間的距離d定義為其二者ID值的逐比特二進制和數,即,假定兩個節點的ID分別為a與b,則有:d=a XOR b。在Kad中,每一個節點都可以根據這一距離概念來判斷其他節點距離自己的“遠近”,當d值大時,節點間距離較遠,而當d值小時,則兩個節點相距很近。這里的“遠近”和“距離”都只是一種邏輯上的度量描述而已;在Kad中,距離這一度量是無方向性的,也就是說a到b的距離恒等于b到a的距離,因為a XOR b==b XOR a
5. 條目是如何存儲在Kad網絡中的?
從上文中我們可以發現節點ID與條目中key值的相似性:無論是關鍵詞字典的key,還是文件索引字典的key,都是160bit,而節點ID恰恰也是160bit。這顯然是有目的的。事實上,節點的ID值也就決定了哪些條目可以存儲在該節點之中,因為我們完全可以把某一個條目簡單地存放在節點ID值恰好等于條目中key值的那個節點處,我們可以將滿足(ID==key)這一條件的節點命名為目標節點N。這樣的話,一個查找條目的問題便被簡單地轉化成為了一個查找ID等于Key值的節點的問題。
由于在實際的Kad網絡當中,并不能保證在任一時刻目標節點N均一定存在或者在線,因此Kad網絡規定:任一條目,依據其key的具體取值,該條目將被復制并存放在節點ID距離key值最近(即當前距離目標節點N最近)的k個節點當中;之所以要將重復保存k份,這完全是考慮到整個Kad系統穩定性而引入的冗余;這個k的取值也有講究,它是一個帶有啟發性質的估計值,挑選其取值的準則為:“在當前規模的Kad網絡中任意選擇至少k個節點,令它們在任意時刻同時不在線的幾率幾乎為0”;目前,k的典型取值為20,即,為保證在任何時刻我們均能找到至少一份某條目的拷貝,我們必須事先在Kad網絡中將該條目復制至少20份。
由上述可知,對于某一條目,在Kad網絡中ID越靠近key的節點區域,該條目保存的份數就越多,存儲得也越集中;事實上,為了實現較短的查詢響應延遲,在條目查詢的過程中,任一條目可被cache到任意節點之上;同時為了防止過度cache、保證信息足夠新鮮,必須考慮條目在節點上存儲的時效性:越接近目標結點N,該條目保存的時間將越長,反之,其超時時間就越短;保存在目標節點之上的條目最多能夠被保留24小時,如果在此期間該條目被其發布源重新發布的話,其保存時間還可以進一步延長。
6. Kad網絡節點需要維護哪些狀態信息?
在Kad網絡中,每一個節點均維護了160個list,其中的每個list均被稱之為一個k-桶(k-bucket),如下圖所示。在第i個list中,記錄了當前節點已知的與自身距離為2^i~2^(i+1)的一些其他對端節點的網絡信息(Node ID,IP地址,UDP端口),每一個list(k-桶)中最多存放k個對端節點信息,注意,此處的k與上文所提到的復制系數k含義是一致的;每一個list中的對端節點信息均按訪問時間排序,最早訪問的在list頭部,而最近新訪問的則放在list的尾部。
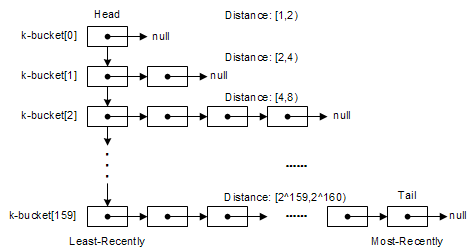
k-桶中節點信息的更新基本遵循Least-recently Seen Eviction原則:當list容量未滿(k-桶中節點個數未滿k個),且最新訪問的對端節點信息不在當前list中時,其信息將直接添入list隊尾,如果其信息已經在當前list中,則其將被移動至隊尾;在k-桶容量已滿的情況下,添加新節點的情況有點特殊,它將首先檢查最早訪問的隊首節點是否仍有響應,如果有,則隊首節點被移至隊尾,新訪問節點信息被拋棄,如果沒有,這才拋棄隊首節點,將最新訪問的節點信息插入隊尾。可以看出,盡可能重用已有節點信息、并且按時間排序是k-桶節點更新方式的主要特點。從啟發性的角度而言,這種方式具有一定的依據:在線時間長一點的節點更值得我們信任,因為它已經在線了若干小時,因此,它在下一個小時以內保持在線的可能性將比我們最新訪問的節點更大,或者更直觀點,我這里再給出一個更加人性化的解釋:MP3文件交換本身是一種觸犯版權法律的行為,某一個節點反正已經犯了若干個小時的法了,因此,它將比其他新加入的節點更不在乎再多犯一個小時的罪……-_-b
由上可見,設計采用這種多k-bucket數據結構的初衷主要有二:a. 維護最近-最新見到的節點信息更新;b. 實現快速的節點信息篩選操作,也就是說,只要知道某個需要查找的特定目標節點N的ID,我們便可以從當前節點的k-buckets結構中迅速地查出距離N最近的若干已知節點。
7. 在Kad網絡中如何尋找某特定的節點?
已知某節點ID,查找獲得當前Kad網絡中與之距離最短的k個節點所對應的網絡信息(Node ID,IP地址,UDP端口)的過程,即為Kad網絡中的一次節點查詢過程(Node Lookup)。注意,Kad之所以沒有把節點查詢過程嚴格地定義成為僅僅只查詢單個目標節點的過程,這主要是因為Kad網絡并沒有對節點的上線時間作出任何前提假設,因此在多數情況下我們并不能肯定需要查找的目標節點一定在線或存在。
整個節點查詢過程非常直接,其方式類似于DNS的迭代查詢:
a. 由查詢發起者從自己的k-桶中篩選出若干距離目標ID最近的節點,并向這些節點同時發送異步查詢請求;
b .被查詢節點收到請求之后,將從自己的k-桶中找出自己所知道的距離查詢目標ID最近的若干個節點,并返回給發起者;
c. 發起者在收到這些返回信息之后,再次從自己目前所有已知的距離目標較近的節點中挑選出若干沒有請求過的,并重復步驟1;
d. 上述步驟不斷重復,直至無法獲得比查詢者當前已知的k個節點更接近目標的活動節點為止。
e. 在查詢過程中,沒有及時響應的節點將立即被排除;查詢者必須保證最終獲得的k個最近節點都是活動的。
簡單總結一下上述過程,實際上它跟我們日常生活中去找某一個人打聽某件事是非常相似的,比方說你是個Agent Smith,想找小李(key)問問他的手機號碼(value),但你事先并不認識他,你首先肯定會去找你所認識的和小李在同一個公司工作的人,比方說小趙,然后小趙又會告訴你去找與和小李在同一部門的小劉,然后小劉又會進一步告訴你去找和小李在同一個項目組的小張,最后,你找到了小張,喲,正好小李出差去了(節點下線了),但小張恰好知道小李的號碼,這樣你總算找到了所需的信息。在節點查找的過程中,“節點距離的遠近”實際上與上面例子中“人際關系的密切程度”所代表的含義是一樣的。
最后說說上述查詢過程的局限性:Kad網絡并不適合應用于模糊搜索,如通配符支持、部分查找等場合,但對于文件共享場合來說,基于關鍵詞的精確查找功能已經基本足夠了(值得注意的是,實際上我們只要對上述查找過程稍加改進,并可以令其支持基于關鍵詞匹配的布爾條件查詢,但仍不夠優化)。這個問題反映到eMule的應用層面來,它直接說明了文件共享時其命名的重要性所在,即,文件名中的關鍵詞定義得越明顯,則該文件越容易被找到,從而越有利于其在P2P網絡中的傳播;而另一方面,在eMule中,每一個共享文件均可以擁有自己的相關注釋,而Comment的重要性還沒有被大家認識到:實際上,這個文件注釋中的關鍵詞也可以直接被利用來替代文件名關鍵詞,從而指導和方便用戶搜索,尤其是當文件名本身并沒有體現出關鍵詞的時候。
8. 在Kad網絡中如何存儲和搜索某特定的條目?
從本質上而言,存儲、搜索某特定條目的問題實際上就是節點查找的問題。當需要在Kad網絡中存儲一個條目時,可以首先通過節點查找算法找到距離key最近的k個節點,然后再通知它們保存條目即可。而搜索條目的過程則與節點查詢過程也是基本類似,由搜索發起方以迭代方式不斷查詢距離key較近的節點,一旦查詢路徑中的任一節點返回了所需查找的value,整個搜索的過程就結束。為提高效率,當搜索成功之后,發起方可以選擇將搜索到的條目存儲到查詢路徑的多個節點中,作為方便后繼查詢的cache;條目cache的超時時間與節點-key之間的距離呈指數反比關系。
9. 一個新節點如何首次加入Kad網絡?
當一個新節點首次試圖加入Kad網絡時,它必須做三件事,其一,不管通過何種途徑,獲知一個已經加入Kad網絡的節點信息(我們可以稱之為節點I),并將其加入自己的k-buckets;其二,向該節點發起一次針對自己ID的節點查詢請求,從而通過節點I獲取一系列與自己距離鄰近的其他節點的信息;最后,刷新所有的k-bucket,保證自己所獲得的節點信息全部都是新鮮的。
posted @
2006-09-11 14:09 CPP&&設計模式小屋 閱讀(1375) |
評論 (3) |
編輯 收藏