1. Kademlia����q?/b>
Kademlia(����U�Kad)属于一�U�典型的�l�构化P2P覆盖�|�络(Structured P2P Overlay Network)�Q�以分布式的应用层全�|�方式来�q�行信息的存储和���索是其尝试解决的主要问题。在Kademlia�|�络中,所有信息均�?key, value="" />的哈希表条目形式加以存储�Q�这些条目被分散地存储在各个节点上,从而以全网方式构成一张巨大的分布式哈希表。我们可以�Ş象地把这张哈希大表看成是一本字典:只要知道了信息烦引的key�Q�我们便可以通过Kademlia协议来查询其所对应的value信息�Q�而不���这个value信息�I�竟是存储在哪一个节点之上。在eMule、BitTorrent�{�P2P文�g交换�pȝ��中,Kademlia主要充当了文件信息检索协议这一关键角色�Q�但Kad�|�络的应用�ƈ不仅限于文�g交换。下文的描述���主要围�l�eMule中Kad�|�络的设计与实现展开�?/p>
2. eMule的Kad�|�络中究竟存储了哪些信息?
只要是能够表�q�成�?key, value="" />字典条目形式的信息Kad�|�络均能存储�Q�一个Kad�|�络能够同时存储多张分布式哈希表。以eMule��Z���Q�在��M��时刻�Q�其Kad�|�络均存储�ƈ�l�护着两张分布式哈希表�Q�一张我们可以将其命名�ؓ关键词字典,而另一张则可以�U�C��为文件烦引字典�?/p>
a. 关键词字�?/b>�Q�主要用于根据给出的关键词查询其所对应的文件名�U�及相关文�g信息�Q�其中key的值等于所�l�出的关键词字符串的160比特SHA1散列�Q�而其对应的value则�ؓ一个列表,在这个列表当中,�l�出了所有的文�g名称当中拥有对应关键词的文�g信息�Q�这些信息我们可以简单地用一�?元组条目表示�Q?文�g名,文�g长度�Q�文件的SHA1校验�?�Q��D个例子,假定存在着一个文件“warcraft_frozen_throne.iso”,当我们分别以“warcraft”、“frozen”、“throne”这三个关键词来查询Kad�Ӟ��Kad���有可能分别�q�回三个不同的文件列表,�q�三个列表的共同之处则在于它们均包含着一个文件名为“warcraft_frozen_throne.iso”的信息条目�Q�通过该条目,我们可以获得对应iso文�g的名�U�、长度及�?60比特的SHA1校验倹{�?/p>
b. 文�g索引字典�Q�用于根据给出的文�g信息来查询文件的拥有�?卌���文�g的下载服务提供�?�Q�其中key的值等于所需下蝲文�g的SHA1校验�?�q�主要是因�ؓ�Q�从�l�计学角度而言�Q?60比特的SHA1文�g校验值可以唯一地确定一份特定数据内容的文�g)�Q�而对应的value也是一个列表,它给��Z��当前所有拥有该文�g的节点的�|�络信息�Q�其中的列表条目我们也可以用一�?元组表示�Q?拥有者IP�Q�下载侦听端口,拥有者节点ID)�Q�根据这些信息,eMule便知道该到哪里去下蝲具备同一SHA1校验值的同一份文件了�?/p>
3. 利用Kad�|�络搜烦�q�下载文件的基本���程是怎样�?
��Z��我们对eMule的Kad�|�络中两本字典的理解�Q�利用Kad�|�络搜烦�q�下载某一特定文�g的基本过�E�便很明白了�Q�仍以“warcraft_frozen_throne.iso”�ؓ例,首先我们可以通过warcraft、frozen、throne�{��Q一关键词查询关键词字典�Q�得到该iso的SHA1校验��|��然后再通过该校验值查询Kad文�g索引字典�Q�从而获得所有提供“warcraft_frozen_throne.iso”下载的�|�络节点�Q���而以分段下蝲方式去这些节点下载整个iso文�g�?/p>
在上�q�过�E�中�Q�Kad�|�络实际上所��L��作用���q��当于两本字典�Q�但值得再次指出的是�Q�Kad�q�不是以集中的烦引服务器(如华语P2P源动力、Razorback 2、DonkeyServer �{�,骡友们应该很熟悉�?方式来实现这两本字典的存储和搜烦的,因�ؓ�q�两本字典的所�?key, value="" />条目均分布式地存储在参与Kad�|�络的各节点中,相关文�g信息、下载位�|�信息的存储和交换均无需集中索引服务器的参与�Q�这不仅提高了查询效率,而且�q�提高了整个P2P文�g交换�pȝ��的可靠性,同时具备相当的反拒绝服务��d��能力�Q�更有意思的是,它能帮助我们有效地抵制FBI的追捕,因�ؓ俗话说得好:法不��M��…看到这里,�怿�大家都能理解“分布式信息���索”所带来的好处了吧。但是,�q�些条目�I�竟是怎样存储的呢?我们又该如何通过Kad�|�络来找到它�?不着急,慢慢来�?/p>
4. 什么叫做节点的ID和节点之间的距离?
Kad�|�络中的每一个节点均拥有一个专属ID�Q�该ID的具体�Ş式与SHA1散列值类��|����Z��个长�?60bit的整敎ͼ�它是��p��点自己随机生成的�Q�两个节�Ҏ��有同一ID的可能性非�怹����,因此可以认�ؓ�q�几乎是不可能的。在Kad�|�络中,两个节点之间距离�q�不是依靠物理距���R���\由器��x��来衡量的�Q�事实上�Q�Kad�|�络����Q意两个节点之间的距离d定义为其二者ID值的逐比特二�q�制和数�Q�即�Q�假定两个节点的ID分别为a与b�Q�则有:d=a XOR b。在Kad中,每一个节炚w��可以�Ҏ���q�一距离概念来判断其他节点距���自��q��“远�q�”,当d值大�Ӟ��节点间距���较�q�,而当d值小�Ӟ��则两个节点相距很�q�。这里的“远�q�”和“距���Z��都只是一�U�逻辑上的度量描述而已�Q�在Kad中,距离�q�一度量是无方向性的�Q�也���是说a到b的距���L���{�于b到a的距���,因�ؓa XOR b==b XOR a
5.
从上文中我们可以发现节点ID�?key, value="" />条目中key值的�怼�性:无论是关键词字典的key�Q�还是文件烦引字典的key�Q�都�?60bit�Q�而节点ID恰恰也是160bit。这昄���是有目的的。事实上�Q�节点的ID��g�����决定了哪些
�׃��在实际的Kad�|�络当中�Q��ƈ不能保证在�Q一时刻目标节点N均一定存在或者在�U�,因此Kad�|�络规定�Q��Q一
�׃���q�可知,对于某一
6. Kad�|�络节点需要维护哪些状态信�?
在Kad�|�络中,每一个节点均�l�护�?60个list�Q�其中的每个list均被�U�C����Z��个k-�?k-bucket)�Q�如下图所�C�。在�W�i个list中,记录了当前节点已知的与自�w�距���Mؓ2^i~2^(i+1)的一些其他对端节点的�|�络信息(Node ID�Q�IP地址�Q�UDP端口)�Q�每一个list(k-�?中最多存放k个对端节点信息,注意�Q�此处的k与上文所提到的复制系数k含义是一致的�Q�每一个list中的对端节点信息均按讉K��旉���排序�Q�最早访问的在list头部�Q�而最�q�新讉K��的则攑֜�list的尾部�?/p>
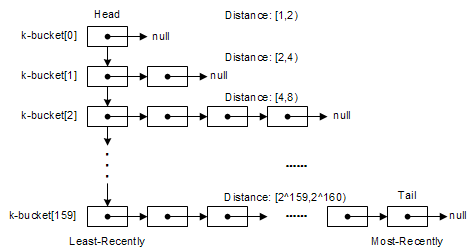
k-桶中节点信息的更新基本遵循Least-recently Seen Eviction原则�Q�当list定w��未满(k-桶中节点个数未满k�?�Q�且最新访问的对端节点信息不在当前list中时�Q�其信息���直接添入list队尾�Q�如果其信息已经在当前list中,则其���被�U�d��至队���;在k-桶容量已满的情况下,��d��新节点的情况有点�Ҏ���Q�它���首先检查最早访问的队首节点是否仍有响应�Q�如果有�Q�则队首节点被移至队���,新访问节点信息被抛弃�Q�如果没有,�q�才抛弃队首节点�Q�将最新访问的节点信息插入队尾。可以看出,���可能重用已有节点信息、�ƈ且按旉���排序是k-桶节�Ҏ��新方式的主要特点。从启发性的角度而言�Q�这�U�方式具有一定的依据�Q�在�U�时间长一点的节点更值得我们信�Q�Q�因为它已经在线了若�q�小�Ӟ��因此�Q�它在下一个小时以内保持在�U�的可能性将比我们最新访问的节点更大�Q�或者更直观点,我这里再�l�出一个更加�h性化的解释:MP3文�g交换本��n是一�U�触犯版权法律的行�ؓ�Q�某一个节点反正已�l�犯了若�q�个���时的法了,因此�Q�它���比其他新加入的节点更不在乎再多犯一个小时的�|�…�?_-b
�׃��可见�Q�设计采用这�U�多k-bucket数据�l�构的初衷主要有二:a. �l�护最�q?最新见到的节点信息更新�Q�b. 实现快速的节点信息�{�选操作,也就是说�Q�只要知道某个需要查扄���特定目标节点N的ID�Q�我们便可以从当前节点的k-buckets�l�构中迅速地查出距离N最�q�的若干已知节点�?/p>
7. 在Kad�|�络中如何寻找某特定的节�?
已知某节点ID�Q�查找获得当前Kad�|�络中与之距���L��短的k个节�Ҏ��对应的网�l�信�?Node ID�Q�IP地址�Q�UDP端口)的过�E�,即�ؓKad�|�络中的一�ơ节�Ҏ��询过�E?Node Lookup)。注意,Kad之所以没有把节点查询�q�程严格地定义成��Z��仅只查询单个目标节点的过�E�,�q�主要是因�ؓKad�|�络�q�没有对节点的上�U�时间作��Z�Q何前提假设,因此在多数情况下我们�q�不能肯定需要查扄���目标节点一定在�U�或存在�?/p>
整个节点查询�q�程非常直接�Q�其方式�c�M��于DNS的�P代查询:
a. 由查询发赯���从自己的k-桶中�{�选出若干距离目标ID最�q�的节点�Q��ƈ向这些节点同时发送异步查询请求;
b .被查询节�Ҏ��到请求之后,���从自己的k-桶中扑և�自己所知道的距���L��询目标ID最�q�的若干个节点,�q�返回给发�v者;
c. 发�v者在收到�q�些�q�回信息之后�Q�再�ơ从自己目前所有已知的距离目标较近的节点中挑选出若干没有��h���q�的�Q��ƈ重复步骤1�Q?br />d. 上述步骤不断重复�Q�直��x��法获得比查询者当前已知的k个节�Ҏ��接近目标的活动节点�ؓ止�?br />e. 在查询过�E�中�Q�没有及时响应的节点���立卌���排除�Q�查询者必���M��证最�l�获得的k个最�q�节炚w��是活动的�?/p>
���单�ȝ��一下上�q�过�E�,实际上它跟我们日常生�z�M����L��某一个�h打听某�g事是非常�怼�的,比方说你是个Agent Smith�Q�想扑ְ��?key)问问他的手机��L��(value)�Q�但你事先�ƈ不认识他�Q�你首先肯定会去找你所认识的和���李在同一个公司工作的人,比方说小赵,然后����n又会告诉你去找与和小李在同一部门的小刘,然后���刘又会�q�一步告诉你��L��和小李在同一个项目组的小张,最后,你找��C�����张�Q�哟�Q�正好小李出差去�?节点下线�?�Q�但���张恰好知道���李的号码,�q�样你�ȝ��扑ֈ�了所需的信息。在节点查找的过�E�中�Q�“节点距��ȝ���q�近”实际上与上面例子中“�h际关�pȝ��密切�E�度”所代表的含义是一��L���?br />
最后说说上�q�查询过�E�的局限性:Kad�|�络�q�不适合应用于模�p�搜索,如通配�W�支持、部分查扄���场合�Q�但对于文�g�׃�n场合来说�Q�基于关键词的精���查扑֊�能已�l�基本��够了(值得注意的是�Q�实际上我们只要对上�q�查找过�E�稍加改�q�,�q�可以��o其支持基于关键词匚w��的布���条件查询,但仍不够优化)。这个问题反映到eMule的应用层面来�Q�它直接说明了文件共享时其命名的重要性所在,卻I��文�g名中的关键词定义得越明显�Q�则该文件越�Ҏ��被找刎ͼ�从而越有利于其在P2P�|�络中的传播�Q�而另一斚w���Q�在eMule中,每一个共享文件均可以拥有自己的相��x��释,而Comment的重要性还没有被大家认识到�Q�实际上�Q�这个文件注释中的关键词也可以直接被利用来替代文件名关键词,从而指导和方便用户搜烦�Q�尤其是当文件名本��n�q�没有体现出关键词的时候�?/p>
8. 在Kad�|�络中如何存储和搜烦某特定的
从本质上而言�Q�存储、搜索某特定
9. 一个新节点如何首次加入Kad�|�络?
当一个新节点首次试图加入Kad�|�络�Ӟ��它必���d��三�g事,其一�Q�不���通过何种途径�Q�获知一个已�l�加入Kad�|�络的节点信�?我们可以�U�C�������点I)�Q��ƈ���其加入自己的k-buckets�Q�其二,向该节点发�v一�ơ针对自己ID的节�Ҏ��询请求,从而通过节点I获取一�p�d��与自��p�����邻�q�的其他节点的信息;最后,��h��所有的k-bucket�Q�保证自己所获得的节点信息全部都是新鲜的�?/p>