基本函數(shù)F(n)=G(n) + H(n);
其中G(n)是從起始點到當(dāng)前點的距離,H(n)是從當(dāng)前點到目標(biāo)點的估計距離。
例如對于一個網(wǎng)格狀的路網(wǎng)可以橫走和豎走,H(n)就是標(biāo)準(zhǔn)Manhattan距離:
h(n) = D * (abs(n.x-goal.x) + abs(n.y-goal.y))
D是走一步的代價。
對于不同的情況H(n)的選取很關(guān)鍵,H越大運算時間越短但得到最優(yōu)解的可能性越低
H越小運算時間越長得到最優(yōu)解的可能性越高。當(dāng)H為0時就是dijkstra算法。
1) 創(chuàng)建OPEN和CLOSE表。其中OPEN為待評估的點,CLOSE為已經(jīng)運算評估過的點。其中OPEN使用二叉堆便于排序。
2) 初始化將起始點計算F(n)并加入到OPEN表。
3) 取當(dāng)前OPEN中的最小F(n)點為當(dāng)前點,將他從OPEN表中刪除,加入到CLOSE表。
4) 計算當(dāng)前點的所有附近點(即一步能達(dá)到的點)
4.1 對于附近點計算cost=當(dāng)前點的G(n)+當(dāng)前點到附近點的開銷。
4.2 如果附近點已經(jīng)在OPEN中則比較附近點的G(n)和cost,如果cost小于附近點的G(n)則更新OPEN表中的附近點的G(n)為cost和F(n),并把它的父節(jié)點設(shè)為當(dāng)前點。反之不做操作。
4.3 如果附近點在CLOSE表中則比較附近點的G(n)和cost,如果cost小于附近點的G(n),則將附近點從CLOSE表中刪除并更新該附近點的G(n)和F(n)并加入到OPEN表,并把它的父節(jié)點設(shè)為當(dāng)前點。反之不操作。
4.4 如果附近點既不在OPEN表也不在CLOSE表,則計算附近點的G(n),H(n)和F(n)并加入到OPEN表,并把它的父節(jié)點設(shè)為當(dāng)前點。
5) 從3步驟開始重新計算直到當(dāng)前點為目標(biāo)點。
6) 從目標(biāo)點開始按父節(jié)點給出到起始點的最短路徑。
其中的關(guān)鍵是對OPEN表、CLOSE表的數(shù)據(jù)結(jié)構(gòu)設(shè)計。由于OPEN表中存在排序和查找的基本操作,CLOSE表也存在查找的基本操作。
當(dāng)數(shù)據(jù)量大時,數(shù)據(jù)結(jié)構(gòu)的優(yōu)勢體現(xiàn)的非常明顯。OPEN表一般都使用二叉堆的形式,CLOSE表則使用簡單的數(shù)組即可。
實際測試產(chǎn)生一個1366*768 像素通路點和障礙點為1:2的隨機網(wǎng)格地圖從坐標(biāo)(100, 100)到(1000, 300)的算路時間(h取Manhattan距離)在5400雙核cpu,2g內(nèi)存下大概為120秒左右。

遺傳算法
網(wǎng)上建模實現(xiàn)的方法很多
第一種 針對網(wǎng)格狀地圖的遺傳算法
1. 將地圖抽象成網(wǎng)格,對于不同地形賦不同值,例如高速路標(biāo)的值可以比輔路低3到4倍。
2. 旋轉(zhuǎn)地圖使起點和終點調(diào)節(jié)成位于同一個縱坐標(biāo)。
3. 將起點到終點將的像素點劃分成幾個塊。
4. 對于每個塊產(chǎn)生隨機的基因(即變異的過程),保證每個塊的當(dāng)前基因位置與前一個基因位置相差小于2個像素點(即2個基因連通)。如圖紅藍(lán)為2個獨立的染色體:
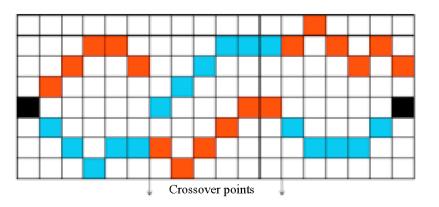
5. 計算所有染色體的適應(yīng)度 。選擇最小的2個染色體作為雙親。
。選擇最小的2個染色體作為雙親。
6. 對雙親進(jìn)行隨機交配產(chǎn)生子代。當(dāng)產(chǎn)生的子代形成一條通路時停止。否則返回到第五步。
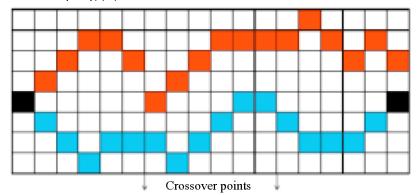
他人的運行結(jié)果:
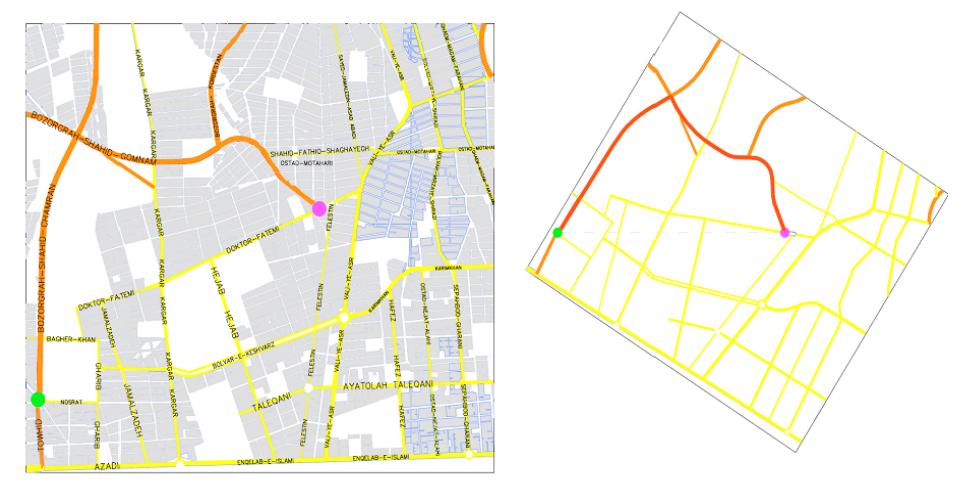
以上算法存在的最大缺陷是當(dāng)存在的路徑垂直于起點和終點的連接線時,無法產(chǎn)生適合的基因,因為該算法產(chǎn)生的基因?qū)τ诿恳粋€縱坐標(biāo)是唯一的。
l第二種 針對路網(wǎng)結(jié)構(gòu)的遺傳算法
大致思想如下:
1. 針對起點和終點先產(chǎn)生n條連通路徑作為原始的種群。
2. 計算每條路徑的適應(yīng)度(一般都以路徑的長度為基礎(chǔ)作為適應(yīng)度)。
3. 進(jìn)行隨機交配(前提是雙親必須有交叉點)。這個變化最大隨機的好壞決定了整個算法的優(yōu)劣。
4. 淘汰掉適應(yīng)度最低的m條道路。
5. 重復(fù)2-4步驟。設(shè)定結(jié)束條件為連續(xù)k次遺傳的最優(yōu)解都是同一個或者設(shè)定遺傳的次數(shù)(到例如50次自動結(jié)束)。
6. 將適應(yīng)度最高的作為最終解。
以上算法的難點在于原始種群的產(chǎn)生有一定難度,取小了無法滿足交叉條件,取大了耗費運算時間且復(fù)雜度提高