1、數據庫與面向對象編程語言的不同
關系數據庫的關注點是數據結構的聲明。這樣的話一些封裝手段就不可用了。沒有封裝,數據訪問就不會被明顯的約束。
表是通過外鍵關聯的。這同樣不能夠被封裝。
存在于數據庫中的數據是持久化的,并且存活得比程序要長。數據庫的結構一旦發生變化,數據就要進行遷徙。
如果系統被多次安裝,那么就會有不同的數據庫。那么如果數據庫結構發生變化,這個變化同樣要作用于每一份安裝。
不同的用戶可以同時訪問數據,但是他們可以每人擁有一份程序的拷貝。
類可以繼承,但數據不行。
源代碼可以在本地進行維護和測試,之后發布到源代碼管理服務器中。版本沖突可以被識別到,然后通過一些強有力的工具可以幫助解決這些問題。在大多數項目中,同一個數據庫往往為多個開發人員服務。
維護源代碼可以使用工具。數據庫的結構和數據則只能夠由人花更多的精力去維護。
訪問數據庫所花費的時間比起訪問訪問內存中對象的時間來要多上好幾倍。
關系型數據庫中的數據結構是淺層結構,然而當它們變成對象處于面向對象的系統中時,他們的含義變得更加深入,他們的關系變得更加錯綜復雜。
2程序與數據庫打交道時產生的一些問題
當程序與數據庫交互時,會產生這樣一些問題:
程序與數據庫之間的關聯往往不是類型安全的(想象JDBC)。編譯器無法評估程序與數據庫是否結構性兼容。某些映射類和持久層把這些問題拿到了一邊,卻沒有解決它們。類型安全性將會在影射類或持久層中失去,而不是其他的地方。
數據庫將會“隱藏”一些對象。這種情況發生在對象被寫入數據庫或者在讀取出來的地方。因此對象可以被程序的兩個部分交換使用,而不需要顯式得暴露于接口中。
大多數情況下往往采用表和對象一一對應的模式。這往往在強調數據的應用程序中是錯誤的做法。特別是當需要從數據庫讀取對象時,可能會需要多個表的極聯,或者為了滿足數據展示的需要,建立一些視圖。結果,當數據庫發生變化時,很難找到一個合適的途徑來決定那些類也要跟著修改。反過來說,通常無法明確類的那些變化會影響到查詢和視圖。
還有一些瑣碎的問題。數據庫中的數據類型與程序語言中的基本數據類型之間的映射會造成一些困難。比如時間戳的尺度,采用浮點數尺度或采用string或變長字符串集合就會有相當大的差別。
在面向對象的系統當中,關聯關系的建模是基于概念的(例如,賬目和收支有關)。在關系數據庫中,一對多關系和多對一關系都是適用的。所以也就無法找到一套確定的方案來實施重構。
因此我們在重構的時候需要著重考慮這樣三個地方:
1)有關數據庫結構、數據庫模型的重構;
2)不同版本的數據庫之間的數據遷移;
3)有關數據庫訪問代碼的重構。
3重構關系數據庫的數據庫結構
在實踐中,往往有一定數量的數據庫模式平行存在。至少有兩個模式:一個為開發者所使用(開發數據庫)一個為用戶所使用(產品數據庫)。
因此開發者總是可以嘗試著修改數據庫而不去驚擾用戶。只有當數據庫被徹底的測試完成,并且適合于構建與其上的系統,這樣才會將數據庫、程序作為一個穩定版本提交給用戶。
此外,每一個開發者應當擁有自己的數據庫實例,這樣他們才能夠獨立的測試他們對于數據庫的一些變動而不會影響到開發團隊的其他人員。這些不同版本數據庫實例的存在使得數據的遷移變成了一個關鍵話題。在下面的部分,我們將會討論這個話題。
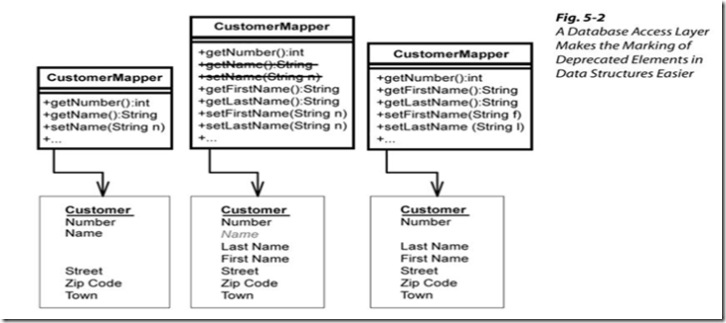
“逐步進化”這樣一個核心的原理不論在程序重構中還是數據結構的重構中都在重演著:老的結構并不會馬上被新的所取代。新舊數據庫結構往往會并存一段時間。老的數據庫結構會被標記為“過期”以讓那些新編寫的程序不去訪問它。然后已有的程序會被修改,一步又一步的向新數據庫過渡。一旦這個過程結束,老的數據結構就算完成了它的使命,他會被終結然后刪除。圖5-1示出了表“Customer”的變革。一開始的時候,姓和名是作為一個字段存儲的,他們合稱作“Name”。現在姓和名會被存放在兩個字段中,最后Name字段將被取代并被刪除。

在中間的狀態,表Customer包含冗余字段Name。程序或觸發器需要保障它們之間的一致性。
在Java中,你可以把那些過時的程序標記上“已過時”。但是在大多數數據庫和其他程序開發語言中沒有提供相關的功能。
在關系數據庫中,字段、表、視圖甚至整個數據庫的結構都有可能需要被標記為“過時”,當然,這視具體的重構過程而定。我們往往通過訪問層面的限制或提示來體現這些獨立的“已過時”標注。比如我們使用O/R mapping工具來生成這些數據的映射類,那么對于這些類或方法我們就可以用“已過時”進行標記了。當然,前提就是你許諾不會通過其他的手段來直接訪問數據庫。如果確實這樣,在你的下一個版本中使用這種方式標記“過時”的數據庫結構也就足夠了。
如果你無法保證對于數據庫的訪問只是通過O/R mapping的映射類,那么就和你的開發團隊訂立協議吧。列一張表,在這個表列舉因為重構而過時的那些東西。當然所有的開發者都要同意這個表上列舉的重構結果,并且能夠去貫徹它。
Ambler在他的網站上收集了很多數據庫中會被頻繁用到的重構方法。這些重構方法為數據庫重構提供了一些依據。
Ambler的重構方法的目的在于為數據庫的結構帶來改觀。因而只是獨立的添加一列并不能組成一次重構。獨立的添加一列不能夠給數據庫結構帶來任何的改觀。
有這樣幾種形式的重構:重構而提升數據的質量;重構而優化數據的結構;重構而提高數據的性能;重構而整合數據;重構而優化數據庫框架。
posted on 2007-08-10 22:47
littlegai 閱讀(306)
評論(0) 編輯 收藏 引用 所屬分類:
我的讀書筆記