作為Visual C++程序員,大家心里都很憋屈!大家都在問,Visual C++的前途在哪里?堅持C++還有沒有意義?
在Visual Studio 2010中我們找到了答案,找到了C++的未來:C++王者歸來!
雖然在C++的發展歷程中經歷了上述小小的波折,但是我們應當看到,世界上還有無數的C++代碼在穩定地運行著,這些代碼還需要維護,需要升級。另外,C++在某些領域還是具有不可替代的優勢,無數基于C++的新項目正在進行著。微軟也逐漸意識到了這一點,開始不斷增強Visual Studio對C++的支持力度。在這次的Visual Studio 2010 CTP中,無論是從C++語言本身還是從IDE方面,都給我們帶來了很多期盼已久的新特性。花開兩朵,各表一枝。我們這里按下Visual Studio 2010在IDE方面的增強不表,單說它對即將到來的C++新標準C++0x的支持。
C++的新標準C++0x雖然還沒有正式發布,但是已經進入了feature freeze的階段,很多人都在猜測C++0x中的x到底是9還是10,從目前的情況來看,9是最大的可能了。Visual Studio 2010作為下一代開發工具,當然不會錯過對新的C++標準C++0x的支持。除了隨著之前發布的Visual C++ Feature Pack而引入的TR1包含的部分特性外,在新的Visual Studio 2010中,還引入了4個重要的C++新特性。號稱C++0x的“四大天王”。這些新特性的引入,必將給C++注入新的活力。
很多編程編程語言都支持匿名函數(anonymous function)。所謂匿名函數,就是這個函數只有函數體,而沒有函數名。Lambda表達式就是實現匿名函數的一種編程技巧,它為編寫匿名函數提供了簡明的函數式的句法。同樣是Visual Studio中的開發語言,Visual Basic和Visual C#早就實現了對Lambda表達式的支持,終于Visual C++這次也不甘落后,在Visual Studio 2010中添加了對Lambda表達式的支持。
Lambda表達式使得函數可以在使用的地方定義,并且可以在Lambda函數中使用Lambda函數之外的數據。這就為針對集合操作帶來了很大的便利。在作用上,Lambda表達式類似于函數指針和函數對象,Lambda表達式很好地兼顧了函數指針和函數對象的優點,卻沒有它們的缺點。相對于函數指針或是函數對象復雜的語法形式,Lambda表達式使用非常簡單的語法就可以實現同樣的功能,降低了Lambda表達式的學習難度,避免了使用復雜的函數對象或是函數指針所帶來的錯誤。我們可以看一個實際的例子:
// LambdaDemo.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <algorithm>
#include <iostream>
#include <ostream>
#include <vector>
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
vector<int> v;
for (int i = 0; i < 10; ++i) {
v.push_back(i);
}
for_each(v.begin(), v.end(), [] (int n) {
cout << n;
if (n % 2 == 0) {
cout << " even ";
} else {
cout << " odd ";
}
});
cout << endl;
return 0;
}
這段代碼循環遍歷輸出vector中的每一個數,并判斷這個數是奇數還是偶數。我們可以隨時修改Lambda表達式而改變這個匿名函數的實現,修改對集合的操作。在這段代碼中,C++使用一對中括號“[]”來表示Lambda表達式的開始,其后的”(int n)”表示Lambda表達式的參數。這些參數將在Lambda表達式中使用到。為了體會Lambda表達式的簡潔,我們來看看同樣的功能,如何使用函數對象實現:
#include "stdafx.h"
#include <algorithm>
#include <iostream>
#include <ostream>
#include <vector>
using namespace std;
struct LambdaFunctor {
void operator()(int n) const {
cout << n << " ";
if (n % 2 == 0) {
cout << " even ";
} else {
cout << " odd ";
}
}
};
int _tmain(int argc, _TCHAR* argv[])
{
vector<int> v;
for (int i = 0; i < 10; ++i) {
v.push_back(i);
}
for_each(v.begin(), v.end(), LambdaFunctor());
cout << endl;
return 0;
}
通過比較我們就可以發現,Lambda表達式的語法更加簡潔,使用起來更加簡單高效。
靜態斷言static_assert
在之前的C++標準C++03中,我們可以使用兩種斷言:
• 使用預處理中的條件編譯和#error指令,可以在預處理階段檢查一些編譯條件
• 可以使用宏assert來進行運行時檢查,以確保程序邏輯的正確性
但使用#error方法是非常煩瑣的,并且不能夠對模板參數進行檢查,因為模板實例化是在編譯時進行,而#error方法是在預處理階段進行的。而assert宏是在運行時進行檢查。不難發現,我們缺少了一樣東西,那就是可用于在編譯時檢查的工具。于是,靜態斷言應運而生。
在新的C++標準C++0x中,加入了對靜態斷言的支持,引入了新的關鍵字static_assert來表示靜態斷言。使用靜態斷言,我們可以在程序的編譯時期檢測一些條件是否成立,這個特性在調試模板函數的模板參數時特別有用。在編譯的時候,模板函數實例化,這時我們就可以使用靜態斷言去測試模板函數的參數是否按照我們的設計擁有合適的值。例如下面這段代碼:
template <int N> struct Kitten {
static_assert(N < 2, "Kitten<N> requires N < 2.");
};
int main() {
Kitten<1> peppermint;
Kitten<3> jazz;
return 0;
}
當我們在主函數中使用“1”去實例化Kitten這個結構體時,在編譯的時候,靜態斷言static_assert會測試參數N的值,當N的值小于2時就會產生一個斷言錯誤,并將相應的調試幫助信息輸出到“Error List”窗口中,這樣程序員就可以對問題快速定位,解決問題就更加方便了。
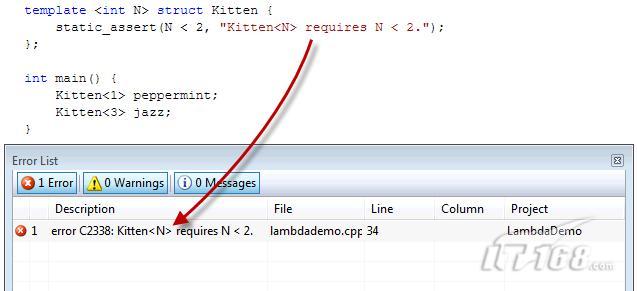
圖2 static_assert斷言及其輸出
另外,靜態斷言還帶來很多其他的優勢。例如靜態斷言在編譯時進行處理,不會產生任何運行時刻空間和時間上的開銷,這就使得它比assert宏具有更好的效率。另外比較重要的一個特性是如果斷言失敗,它會產生有意義且充分的診斷信息,幫助程序員快速解決問題。
auto關鍵字
在C++0x中,auto關鍵字的意義發生了改變。從Visual C++ 2010開始,auto關鍵字將用于指引編譯器根據變量的初始值來決定變量的數據類型。換句話說,我們可以把auto當成一種新的數據類型,它可以“從初始化器(initialize)中推導出所代表的變量的真正類型”。這種對auto關鍵字的使用方式可以大大消除當前替代方式所導致的冗長和易出錯的代碼。我們看一個實際的例子:
#include <iostream>
#include <map>
#include <ostream>
#include <regex>
#include <string>
using namespace std;
using namespace std::tr1;
int main() {
map<string, string> m;
const regex r("(\\w+) (\\w+)");
for (string s; getline(cin, s); ) {
smatch results;
if (regex_match(s, results, r)) {
m[results[1]] = results[2];
}
}
for (auto i = m.begin(); i != m.end(); ++i) {
cout << i->second << " are " << i->first << endl;
}
return 0;
}
在這段代碼中,我們使用auto關鍵字來代替了真正的數據類型map<string, string>::iterator,這使得整個代碼自然而簡潔。
另外,跟其他數據類型一樣,我們也可以對auto關鍵字進行修飾,例如添加const,指針(*),左值引用(&),右值引用(&&)等等,編譯器會根據auto類型所代表的真正的數據來決定這些修飾的具體含義。
為了兼容一些舊有的C++代碼,我們可以使用/Zc:auto這個編譯器選項,來告訴編譯器是采用auto關鍵字的原有定義還是在新標準C++0x中的定義。
右值引用
作為最重要的一項語言特性,右值引用(rvalue references)被引入到 C++0x中。我們可以通過操作符“&&”來聲明一個右值引用,原先在C++中使用“&”操作符聲明的引用現在被稱為左值引用。
int a;
int& a_lvref = a; // 左值引用
int b;
int&& b_rvref = b; // 右值應用
左值引用和右值引用的表現行為基本一致,它們唯一的差別就是右值引用可以綁定到一個臨時對象(右值)上,而左值引用不可以。例如:
int& a_lvref = int(); // error C2440: 'initializing' : cannot convert from 'int' to 'int &'
int&& b_rvref = int(); // OK!
在第一行代碼中,我們將一個臨時對象int()綁定到一個左值引用,將產生一個編譯錯誤。而在第二行中,我們將臨時對象綁定到右值引用,就可以順利通過編譯。
右值是無名的數據,例如函數的返回值一般說來就是右值。當對右值進行操作的時候,右值本身往往沒有必要保留,因此在某些情況下可以直接“移動”之。通過右值引用,程序可以明確的區分出傳入的參數是否為右值,從而避免了不必要的拷貝,程序的效率也就得到了提高。我們考慮一個簡單的數據交換的小程序,從中來體會右值引用所帶來的效率提升。我們可以寫一個函數swap來實現兩個變量值的交換:
template <class T> swap(T& a, T& b)
{
T tmp(a); // tmp對象創建后,我們就擁有了a的兩份拷貝
a = b; // 現在我們擁有b的兩份拷貝
b = tmp; // 現在我們擁有a的兩份拷貝
}
在這段代碼中,雖然我們只是為了進行簡單的數據交換,但是卻執行了多次對象拷貝。這些對象的拷貝操作,特別是當這些對象比較大的時候,無疑會影響程序的效率。
那么,如果使用右值引用如何實現呢?
// RValueRef.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
template <class T>
T&& move(T&& a)
{
return a;
}
template <class T> void swap(T& a, T& b)
{
T tmp(move(a)); // 對象a被移動到對象tmp,a被清空
a = move(b); // 對象b被移動到對象a,b被清空
b = move(tmp); // 對象tmp被移動到對象b
}
int _tmain(int argc, _TCHAR* argv[])
{
int a = 1;
int b = 2;
swap(a, b);
return 0;
}
在這段重新實現的代碼中,我們使用了一個move()函數來代替對象的賦值操作符“=”,move()只是簡單地接受一個右值引用或者左值引用作為參數,然后直接返回相應對象的右值引用。這一過程不會產生拷貝(Copy)操作,而只會將源對象移動(Move)到目標對象。
正是拷貝(Copy)和移動(Move)的差別,使得右值引用成為C++0x中最激動人心的新特性之一。從實踐角度講,它能夠完美是解決C++中長久以來為人所詬病的臨時對象的效率問題。從語言本身講,它健全了C++中的引用類型在左值右值方面的缺陷。從庫設計者的角度講,它給庫設計者又帶來了一把利器。而對于廣大的庫使用者而言,不動一兵一卒便能夠獲得“免費的”效率提升。
在Visual Studio 2010中,因為有了對這些C++0x新特性的支持,重新點燃了程序員們對C++的熱情。C++重振雄風,指日可待!