第一部分 接觸 Lucene
Lucene的核心
本書的第一部分(first half of)覆蓋了Lucene的對外接口(covers out-of-the-box Lucene)。你將接觸到Lucene(Meet Lucene)的一個(gè)全面的概況(general overview),并且還開發(fā)一個(gè)完整的索引建立和檢索的程序。每一個(gè)連續(xù)的章節(jié)(Each successive chapter)系統(tǒng)地(systematically )深入研究(delves into)特定的領(lǐng)域(specific areas)。索引“Indexing”數(shù)據(jù)和文檔以及隨后搜索“Searching”它們是使用Lucene的第一步。回到一個(gè)覆蓋索引的進(jìn)程(Returning to a glossed-over indexing process),分析器“Analysis”將替代( fill in)你對影響Lucene索引后的文本的事物的理解。搜索“Searching”是Lucene真正擅長(really shines)的地方。本部分結(jié)束的(concludes with)章節(jié)是介紹僅使用內(nèi)置的特性探討高級(jí)搜索“Advanced searching”技術(shù),而擴(kuò)展搜索“Extending search”展示(showcasing)Lucene對自定義的目標(biāo)“custom purposes”的擴(kuò)展性(extensibility)。
接觸 Lucene
This chapter covers 本章節(jié)包括
■ Understanding Lucene 理解 Lucene
■ Using the basic indexing API 使用基本的索引API
■ Working with the search API 在工作中使用搜索API
■ Considering alternative products 考慮其他可選的產(chǎn)品
Lucene的流行和成功背后的關(guān)鍵因素(key factors)的其中一個(gè)就是它的簡單(simplicity)。它的索引和搜索API的細(xì)致暴露(careful exposure)出一個(gè)良好設(shè)計(jì)軟件的標(biāo)志(a sign of the well- designed software)。因此(Consequently),你為了開始使用它不需要深入了解(in-depth knowledge about)Lucene的信息索引和獲取(retrieval)是怎樣工作的。而且(Moreover),Lucene的簡單易懂(straightforward)的API只需你學(xué)習(xí)使用它的一小部分(a handful of)類。
在本章中,我們通過可以使用的(ready-to-use)代碼示例向你怎樣使用Lucene來執(zhí)行基本的索引和搜索,然后我們簡單地介紹(briefly introduce)所有這些這兩節(jié)步驟中(for both of these processes)你需要了解的核心元素。我們同樣也提供關(guān)于Java/non-Java,free和商業(yè)產(chǎn)品競爭的簡單回顧(brief reviews)。
1.1 信息組織和訪問的演化information organization and access
(略)
1.2 理解 Lucene
不同的人使用不同的方法(different approaches)來解決相同的問題,即信息超負(fù)荷問題(information overload)。一些人使用新奇的(novel)用戶接口來工作,一些使用智能的代理(intelligent agents),另一些開發(fā)成熟的(sophisticated)搜索工具如Lucene。在本節(jié)稍后我們展示(jump into action)代碼示例之前,我們提供你一張高層次(high-level)的圖,說明哪些是Lucene的東西,哪些不是,以及Lucene未來的樣子。
1.2.1 Lucene 是什么
Lucene 是一個(gè)高性能(high performance)的可伸縮的(scalable)信息檢索庫(Information Retrieval (IR) library),它可以讓你給你的應(yīng)用程序添加索引和搜索能力。Lucene是一個(gè)成熟的(mature)免費(fèi)的open-source 項(xiàng)目,使用Java實(shí)現(xiàn),它是廣泛流行的Apache Jakarta項(xiàng)目大家庭中的其中一個(gè)成員,并且許可License是基于自由主義(liberal)的Apache Software License基礎(chǔ)之上的。同樣的(As such),Lucene現(xiàn)在在很短的幾年內(nèi)已經(jīng)成為一個(gè)最流行的免費(fèi)的Java IR library。
NOTE 貫穿本書中,我們將使用term Information Retrieval (IR)來描述像Lucene這樣的搜索工具。人們常常將IR libraries引用為搜索引擎,但是你卻不應(yīng)該搞混IR libraries和web search engines。
正如你馬上就會(huì)發(fā)現(xiàn)的一樣,Lucene提供一個(gè)簡單的而且依然強(qiáng)大的核心API,而且僅需要最小限度地學(xué)習(xí)全文索引和檢索(full-text indexing and searching),你僅需要學(xué)習(xí)一把(a handful of)類就能開始把Lucene集成進(jìn)一個(gè)應(yīng)用程序。因?yàn)長ucene是一個(gè)Java庫,它不承擔(dān)(make assumptions about)它索引和檢索的是什么,這使得它比其它一些搜索應(yīng)用程序更有優(yōu)勢(an advantage over)。對Lucene陌生(new to)的人經(jīng)常錯(cuò)把它當(dāng)作一個(gè)可以馬上使用(ready-to-use)的應(yīng)用程序,就像一個(gè)文件檢索(file-search)程序,或者一個(gè)web網(wǎng)絡(luò)爬蟲(crawler),或者一個(gè)web站點(diǎn)搜索引擎。這些都不是Lucene的實(shí)質(zhì):Lucene實(shí)際是一個(gè)軟件庫(software library),一個(gè)開發(fā)工具包(toolkit)如果你愿意這樣稱呼(if you will),而不是一個(gè)具備完整特性的(full-featured)搜索應(yīng)用程序。這使它關(guān)注自己的文本索引和搜索技術(shù)(It concerns itself with text indexing and searching),并且這些事它完成得非常好。Lucene使得你的應(yīng)用程序處理業(yè)務(wù)規(guī)則(business rules),特別地針對它的問題領(lǐng)域(problem domain),而把復(fù)雜的索引和搜索實(shí)現(xiàn)掩蓋起來,只提供簡單易用(simple-to-use)的API。你可以把Lucene當(dāng)作一層(layer),應(yīng)用程序位于它之上(sit on top of),就像圖1.5所描述(depicted)的那樣。一些擁有完整特性的搜索程序被建立在Lucene上層。如果你尋找一些與之相關(guān)的預(yù)創(chuàng)建的東西(something prebuilt)或者一個(gè)為了抓取(crawling),處理(document handling)和搜索文檔,請參考(consult) Lucene Wiki “powered by” 網(wǎng)頁(http://wiki.apache.org/jakarta-lucene/PoweredBy)更多選項(xiàng)如下: Zilverline, SearchBlox, Nutch, LARM, and jSearch, 還有其它一小部分的命名(to name a few)。個(gè)案研究(Case studies of)包括Nutch 和SearchBlox 將在第10章介紹。
1.2.2 Lucene 能為你做什么
Lucene 允許給你的程序添加索引和搜索的能力。(這些功能將在1.3節(jié)里描述),Lucene能夠索引并且可以使得任何能夠被轉(zhuǎn)換成文本格式的(textual format)數(shù)據(jù)能夠被搜索(search- able),請參考圖1.5。
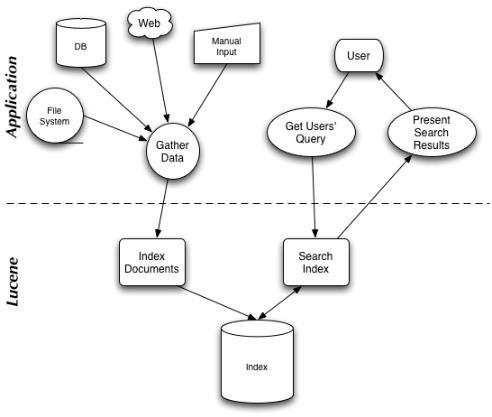
Figure 1.5 A typical application integration with Lucene一個(gè)集成了Lucene的典型程序
Lucene并不關(guān)心數(shù)據(jù)源,及其格式,甚至其語言,只要你能夠把它轉(zhuǎn)換成文本就行。這意味著你能夠使用Lucene來索引和搜索存儲(chǔ)在文件中的數(shù)據(jù),以及在遠(yuǎn)端web服務(wù)器的web網(wǎng)頁,還有存儲(chǔ)在本地文件系統(tǒng)中文檔,簡單的文本文件, Microsoft Word 文檔,或者PDF文檔,或者任何其它你能分離出(extract)文本信息的格式都行。簡單地,通過Lucene的幫助你能夠索引存儲(chǔ)在你的數(shù)據(jù)庫中的數(shù)據(jù),可以給你的用戶提供全文檢索能力(full-text search capabilities),而這很多數(shù)據(jù)庫都不提供。一旦你集成了Lucene,使用你的程序的用戶就能夠讓搜索這樣一些查詢詞:+George +Rice -eat –pudding, Apple –pie +Tiger, animal:monkey 或者food:banana,等等。.使用Lucene,你能夠索引和搜索email郵件,郵件列表檔案,即時(shí)通信聊天信息,你的Wiki網(wǎng)頁,等等繼續(xù)。
1.2.3 Lucene 的歷史
Lucene 最先是由Doug Cutting開發(fā)的,它最初提供下載是在它在SourceForge網(wǎng)站的主頁上。它后來加入Apache軟件基金的高質(zhì)量的開源Java產(chǎn)品的Jakarta家族是在2001年九月份。從那之后的每一次發(fā)布,項(xiàng)目得到可喜明顯易見的增強(qiáng),吸引更多的用戶和開發(fā)者加入。在2004年七月份,發(fā)布了 Lucene version 1.4,后來修正了一個(gè)bug在10月份早期發(fā)布了1.4.2 版本。
Doug Cutting 在Lucene幕后依然保持主要的影響力,但是自從Lucene移動(dòng)到Apache Jakarta的庇護(hù)(umbrella)之下后,更多聰明的智慧力量加入到這個(gè)項(xiàng)目中來。在本書寫作的時(shí)候,Lucene的核心團(tuán)隊(duì)包括了半打的活躍開發(fā)者(a dozen active developers),其中兩個(gè)還是本書的作者。除了這些官方的開發(fā)者之外,Lucene還有一個(gè)非常龐大(a fairly large)而且活躍的技術(shù)用戶社區(qū),非常頻繁地貢獻(xiàn)(frequently contributes)補(bǔ)丁,BUG修復(fù),以及新的特性等。
1.2.4 誰在使用 Lucene
誰在使用呢?除了Lucene的Wiki網(wǎng)站提及(mentioned)的團(tuán)體(organizations)之外,許多(a number of)其他的大型的著名的(well-known)跨國(multinational)組織也在使用Lucene。它為Eclipse IDE提供搜索能力,大不列顛百科全書(Encyclopedia Britannica)CD-ROM/DVD,F(xiàn)edEx 還有Mayo Clinic,惠普Hewlett-Packard,New Scientist magazine, Epiphany,MIT’s OpenCourseware 以及DSpace, Akamai’s EdgeComputing platform等等,當(dāng)然,你的名字也將很快加入此列表中。
1.2.5 Lucene 其它語言版本:Perl, Python, C++, .NET, Ruby
有一條判斷一個(gè)開源軟件是否成功的途徑是通過考察它被改成其它編程語言的數(shù)量。使用這個(gè)標(biāo)準(zhǔn),Lucene是非常成功的,盡管原始的Lucene是用Java寫的,在本書寫作的時(shí)候,Lucene已經(jīng)被有很多其它語言版本了: Perl,Python,C++ 和 .NET,以及一些基礎(chǔ)(groundwork)的工作在轉(zhuǎn)換到Ruby語言的工作中完成了。這是及其令人興奮的新聞,對那些需要訪問用不同語言寫成的應(yīng)用程序的Lucene索引時(shí)的開發(fā)者來說確實(shí)如此。你在第9章中能夠?qū)W到更多有關(guān)這方面的東西。
1.3 索引和搜索Indexing and searching
所有搜索引擎的心就是索引的概念(concept):處理那些原始的數(shù)據(jù)轉(zhuǎn)換成一個(gè)非常有效率(highly efficient)的交叉引用的(cross-reference)查找(lookup)為了便于(facilitate)加快(rapid)搜索。讓我們做一個(gè)快速的從很高層面來觀察(quick high-level look at)索引和搜索的處理。
1.3.1 索引是什么,為什么它很重要?
假設(shè)(Suppose)你需要搜索一個(gè)巨大數(shù)量的文件,而且你想能夠找出那些包含了某一些詞或者短語(a certain word or a phrase)的文件,你會(huì)怎樣寫一個(gè)程序完成這樣的事呢?一個(gè)幼稚的方法(naive approach)也許是持續(xù)地在每一個(gè)文件中掃描(sequentially scan)給定的詞匯或者短語。這個(gè)方法有很多缺點(diǎn)(a number of flaws),太巨大了。這就是索引進(jìn)來的地方:為了快速地搜索很龐大數(shù)量的文本,你必須先索引這些文本,并轉(zhuǎn)換成一個(gè)會(huì)讓你搜索更快速的格式,消除(eliminating)那些緩慢的按順序的掃描過程(the slow sequential scanning process)。這個(gè)轉(zhuǎn)換過程就叫索引(indexing),它的輸出被叫做一條索引(an index)。
你可以把一條索引當(dāng)作一個(gè)數(shù)據(jù)結(jié)構(gòu)(data structure),它允許快速的隨機(jī)訪問(fast random access)那些存儲(chǔ)在里面的詞匯。在它之后的的概念(concept behind it)與一本書后的索引類似(is analogous to),這可以讓你很快速地定位(locate)討論某些確定主題的(discuss certain topics)的頁。而在Lucene之中(In the case of Lucene),一條索引是一個(gè)特別設(shè)計(jì)的數(shù)據(jù)結(jié)構(gòu)(a specially designed data structure),典型的情況是(typically)存儲(chǔ)在文件系統(tǒng)之中作為一系列文件(a set of index files)。我們在附錄B(appendix B)中詳細(xì)地(in detail in)覆蓋了(cover)索引文件的結(jié)構(gòu),但是目前暫時(shí)把一條Lucene索引當(dāng)作一個(gè)允許快速檢索詞匯的工具。
1.3.2 什么是搜索呢 What is searching?
搜索(Searching)就是查找一條索引里的單詞來找出它們出現(xiàn)的文檔的這樣一個(gè)過程。一個(gè)搜索的質(zhì)量是用精度(precision)和回調(diào)法(recall metrics)來典型地描述(typically described)的。回調(diào)(Recall)測量(measures)搜索系統(tǒng)查找相關(guān)的(relevant)文檔是否好,然而(whereas)精度(precision)測量系統(tǒng)過濾出(filters out)不相關(guān)(irrelevant)文檔是否好,然而你在思考搜索的時(shí)候必須考慮許多(a number of)其他因素(factors)。我們已經(jīng)提及(mentioned)速度和快速搜索大量(large quantities of)文本的能力。支持(Support for)單個(gè)的(Single)和多個(gè)詞匯的查詢(multiterm queries),短語查詢(phrase queries),通配符(wildcards),結(jié)果分級(jí)(result ranking),以及排序(sorting)功能,也同樣重要,照現(xiàn)在的樣子(as is)輸入這些查詢的(entering those queries)一個(gè)友好的語法(friendly syntax)。Lucene的強(qiáng)大的軟件庫提供許多查詢特性,(bells)和(whistles)—很多我們都不得不展開(spread)我們的查詢覆蓋(coverage over)三章(第3章和5章和6章)。
1.4 Lucene in action: 一個(gè)簡單的程序
讓我們看看Lucene in action,為了寫這個(gè)程序,回想(recall)索引和搜索文件的問題,這個(gè)問題在 1.3.1 節(jié)描述過,此外(furthermore)假設(shè)(suppose)你需要索引和搜索存儲(chǔ)在一個(gè)目錄樹(directory tree)中的文件,而不是僅僅查找單一的一個(gè)目錄。為樂向你展示Lucene的索引和搜索能力,我們將使用一對命令行(command-line)的應(yīng)用程序:Indexer和Searcher。首先我們將給一個(gè)包含文本文件的目錄樹建立索引,然后我們搜索這個(gè)創(chuàng)建的索引。
這些示例程序?qū)⒆屇闶煜ぃ╢amiliarize)Lucene的API,它的輕松的使用(its ease of use)以及它的強(qiáng)大。這些代碼清單(code listings)是完整的,可以使用的(ready-to-use)命令行程序。如果文件的索引/檢索是你需要去解決的問題,你可以復(fù)制這些代碼清單,并且揉擰(tweak)它們來適合(suit)你所需要的地方。在接下來的章節(jié)中,我們將描述Lucene在許多更高級(jí)使用的細(xì)節(jié)(much greater detail)的每一個(gè)方面(each aspect)。
在我們能夠使用Lucene來搜索之前,我們需要先創(chuàng)建一個(gè)索引,所以我們以一個(gè)Indexer應(yīng)用程序作為開始。
1.4.1 創(chuàng)建一個(gè)索引
在本節(jié)中,你將看到一個(gè)單一的類叫作Indexer,它的四個(gè)靜態(tài)方法(static methods)合起來(together),它們遞歸地(recursively)來回遍歷(traverse)文件系統(tǒng)的目錄,并給所有擴(kuò)展名為.txt的文件建上索引。當(dāng)Indexer執(zhí)行完成后(completes execution),它會(huì)為它的同胞:Searcher工具(將在1.4.2節(jié)中介紹(presented))產(chǎn)生(leaves behind)一個(gè)Lucene索引。
我們不期望你熟悉(be familiar with)在這個(gè)例子中使用的這些少數(shù)的Lucene類和方法,我們會(huì)簡單地介紹它們(explain them shortly)。在這些有注釋的代碼清單(the annotated code listing)后,我們向你展示怎樣使用Indexer,如果它能在你看到它是怎么編碼的之前幫助你學(xué)習(xí)Indexer是怎樣使用的,請直接跳到(go directly to)在這些代碼后的使用討論(usage discussion)部分。
Using Indexer to index text files
Listing 1.1 shows the Indexer command-line program. It takes two arguments:
■ A path to a directory where we store the Lucene index
■ A path to a directory that contains the files we want to index
Listing 1.1 Indexer: traverses a file system and indexes .txt files

 /** *//**
/** *//**
 * This code was originally written for
* This code was originally written for
* Erik's Lucene intro java.net article
 */
*/
public class Indexer  {
{

 public static void main(String[] args) throws Exception {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
throw new Exception("Usage: java " + Indexer.class.getName()
+ " <index dir> <data dir>");
 }
}
File indexDir = new File(args[0]);
File dataDir = new File(args[1]);
long start = new Date().getTime();
int numIndexed = index(indexDir, dataDir);
long end = new Date().getTime();
System.out.println("Indexing " + numIndexed + " files took "
+ (end - start) + " milliseconds");
}
// open an index and start file directory traversal
public static int index(File indexDir, File dataDir)
throws IOException {
if (!dataDir.exists() || !dataDir.isDirectory()) {
throw new IOException(dataDir
+ " does not exist or is not a directory");
}
IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(), true); writer.setUseCompoundFile(false);
indexDirectory(writer, dataDir);
int numIndexed = writer.docCount();
writer.optimize();
writer.close();
return numIndexed;
}
// recursive method that calls itself when it finds a directory
private static void indexDirectory(IndexWriter writer, File dir)
throws IOException {
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
File f = files[i];
if (f.isDirectory()) {
indexDirectory(writer, f);
} else if (f.getName().endsWith(".txt")) {
indexFile(writer, f);
}
}
}
// method to actually index a file using Lucene
private static void indexFile(IndexWriter writer, File f)
throws IOException {
if (f.isHidden() || !f.exists() || !f.canRead()) {
return;
}
System.out.println("Indexing " + f.getCanonicalPath());
Document doc = new Document();
doc.add(Field.Text("contents", new FileReader(f)));
doc.add(Field.Keyword("filename", f.getCanonicalPath()));
writer.addDocument(doc);
}
}
譯者 Naven 審校 Scar 未完待續(xù)