linux load average
系統(tǒng)平均負(fù)載被定義為在特定時(shí)間間隔內(nèi)運(yùn)行隊(duì)列中的平均進(jìn)程數(shù)。如果一個(gè)進(jìn)程滿足以下條件則其就會(huì)位于運(yùn)行隊(duì)列中:
- 它沒(méi)有在等待I/O操作的結(jié)果
- 它沒(méi)有主動(dòng)進(jìn)入等待狀態(tài)(也就是沒(méi)有調(diào)用'wait')
- 沒(méi)有被停止(例如:等待終止)
SIP的第四期結(jié)束了,因?yàn)榭刂撇呗缘呢S富,早先的的壓力測(cè)試結(jié)果已經(jīng)無(wú)法反映在高并發(fā)和高壓力下SIP的運(yùn)行狀況,因此需要重新作壓力測(cè)試。跟在測(cè)試人員后面做了快一周的壓力測(cè)試,壓力測(cè)試的報(bào)告也正式出爐,本來(lái)也就算是告一段落,但第二天測(cè)試人員說(shuō)要修改報(bào)告,由于這次作壓力測(cè)試的同學(xué)是第一次作,有一個(gè)指標(biāo)沒(méi)有注意,因此需要修改幾個(gè)測(cè)試結(jié)果。那個(gè)沒(méi)有注意的指標(biāo)就是load average,他和我一樣開始只是注意了CPU,內(nèi)存的使用狀況,而沒(méi)有太注意這個(gè)指標(biāo),這個(gè)指標(biāo)與他們通常的限制(10左右)有差別。重新測(cè)試的結(jié)果由于這個(gè)指標(biāo)被要求壓低,最后的報(bào)告顯然不如原來(lái)的好看。自己也沒(méi)有深入過(guò)壓力測(cè)試,但是覺(jué)得不搞明白對(duì)將來(lái)機(jī)器配置和擴(kuò)容都會(huì)有影響,因此去問(wèn)了DBA和SA,得到的結(jié)果相差很大,看來(lái)不得不自己去找找問(wèn)題的根本所在了。
通過(guò)下面的幾個(gè)部分的了解,可以一步一步的找出Load Average在壓力測(cè)試中真正的作用。
CPU時(shí)間片
為了提高程序執(zhí)行效率,大家在很多應(yīng)用中都采用了多線程模式,這樣可以將原來(lái)的序列化執(zhí)行變?yōu)椴⑿袌?zhí)行,任務(wù)的分解以及并行執(zhí)行能夠極大地提高程序的運(yùn)行效率。但這都是代碼級(jí)別的表現(xiàn),而硬件是如何支持的呢?那就要靠CPU的時(shí)間片模式來(lái)說(shuō)明這一切。程序的任何指令的執(zhí)行往往都會(huì)要競(jìng)爭(zhēng)CPU這個(gè)最寶貴的資源,不論你的程序分成了多少個(gè)線程去執(zhí)行不同的任務(wù),他們都必須排隊(duì)等待獲取這個(gè)資源來(lái)計(jì)算和處理命令。先看看單CPU的情況。下面兩圖描述了時(shí)間片模式和非時(shí)間片模式下的線程執(zhí)行的情況:
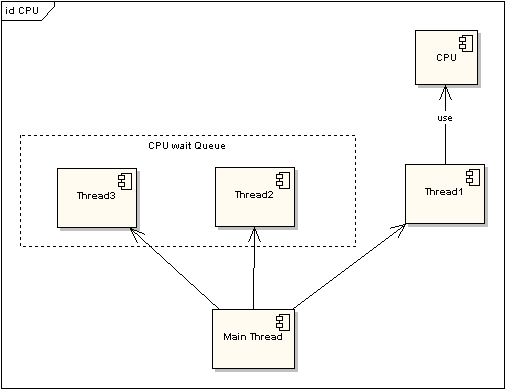
圖 1 非時(shí)間片線程執(zhí)行情況
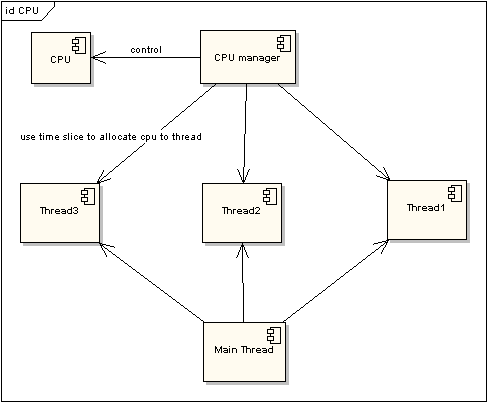
圖 2 非時(shí)間片線程執(zhí)行情況
在圖一中可以看到,任何線程如果都排隊(duì)等待CPU資源的獲取,那么所謂的多線程就沒(méi)有任何實(shí)際意義。圖二中的CPU Manager只是我虛擬的一個(gè)角色,由它來(lái)分配和管理CPU的使用狀況,此時(shí)多線程將會(huì)在運(yùn)行過(guò)程中都有機(jī)會(huì)得到CPU資源,也真正實(shí)現(xiàn)了在單CPU的情況下實(shí)現(xiàn)多線程并行處理。
多CPU的情況只是單CPU的擴(kuò)展,當(dāng)所有的CPU都滿負(fù)荷運(yùn)作的時(shí)候,就會(huì)對(duì)每一個(gè)CPU采用時(shí)間片的方式來(lái)提高效率。
在Linux的內(nèi)核處理過(guò)程中,每一個(gè)進(jìn)程默認(rèn)會(huì)有一個(gè)固定的時(shí)間片來(lái)執(zhí)行命令(默認(rèn)為1/100秒),這段時(shí)間內(nèi)進(jìn)程被分配到CPU,然后獨(dú)占使用。如果使用完,同時(shí)未到時(shí)間片的規(guī)定時(shí)間,那么就主動(dòng)放棄CPU的占用,如果到時(shí)間片尚未完成工作,那么CPU的使用權(quán)也會(huì)被收回,進(jìn)程將會(huì)被中斷掛起等待下一個(gè)時(shí)間片。
CPU利用率和Load Average的區(qū)別
壓 力測(cè)試不僅需要對(duì)業(yè)務(wù)場(chǎng)景的并發(fā)用戶等壓力參數(shù)作模擬,同時(shí)也需要在壓力測(cè)試過(guò)程中隨時(shí)關(guān)注機(jī)器的性能情況,來(lái)確保壓力測(cè)試的有效性。當(dāng)服務(wù)器長(zhǎng)期處于一 種超負(fù)荷的情況下運(yùn)行,所能接收的壓力并不是我們所認(rèn)為的可接受的壓力。就好比項(xiàng)目經(jīng)理在給一個(gè)人估工作量的時(shí)候,每天都讓這個(gè)人工作12個(gè)小時(shí),那么所制定的項(xiàng)目計(jì)劃就不是一個(gè)合理的計(jì)劃,那個(gè)人遲早會(huì)垮掉,而影響整體的項(xiàng)目進(jìn)度。
CPU利用率在過(guò)去常常被我們這些外行認(rèn)為是判斷機(jī)器是否已經(jīng)到了滿負(fù)荷的一個(gè)標(biāo)準(zhǔn),看到50%-60%的使用率就認(rèn)為機(jī)器就已經(jīng)壓到了臨界了。CPU利用率,顧名思義就是對(duì)于CPU的使用狀況,這是對(duì)一個(gè)時(shí)間段內(nèi)CPU使用狀況的統(tǒng)計(jì),通過(guò)這個(gè)指標(biāo)可以看出在某一個(gè)時(shí)間段內(nèi)CPU被占用的情況,如果被占用時(shí)間很高,那么就需要考慮CPU是否已經(jīng)處于超負(fù)荷運(yùn)作,長(zhǎng)期超負(fù)荷運(yùn)作對(duì)于機(jī)器本身來(lái)說(shuō)是一種損害,因此必須將CPU的利用率控制在一定的比例下,以保證機(jī)器的正常運(yùn)作。
Load Average是CPU的Load,它所包含的信息不是CPU的使用率狀況,而是在一段時(shí)間內(nèi)CPU正在處理以及等待CPU處理的進(jìn)程數(shù)之和的統(tǒng)計(jì)信息,也就是CPU使用隊(duì)列的長(zhǎng)度的統(tǒng)計(jì)信息。為什么要統(tǒng)計(jì)這個(gè)信息,這個(gè)信息的對(duì)于壓力測(cè)試的影響究竟是怎么樣的,那就通過(guò)一個(gè)類比來(lái)解釋CPU利用率和Load Average的區(qū)別以及對(duì)于壓力測(cè)試的指導(dǎo)意義。
我們將CPU就類比為電話亭,每一個(gè)進(jìn)程都是一個(gè)需要打電話的人。現(xiàn)在一共有4個(gè)電話亭(就好比我們的機(jī)器有4核),有10個(gè)人需要打電話。現(xiàn)在使用電話的規(guī)則是管理員會(huì)按照順序給每一個(gè)人輪流分配1分鐘的使用電話時(shí)間,如果使用者在1分鐘內(nèi)使用完畢,那么可以立刻將電話使用權(quán)返還給管理員,如果到了1分鐘電話使用者還沒(méi)有使用完畢,那么需要重新排隊(duì),等待再次分配使用。
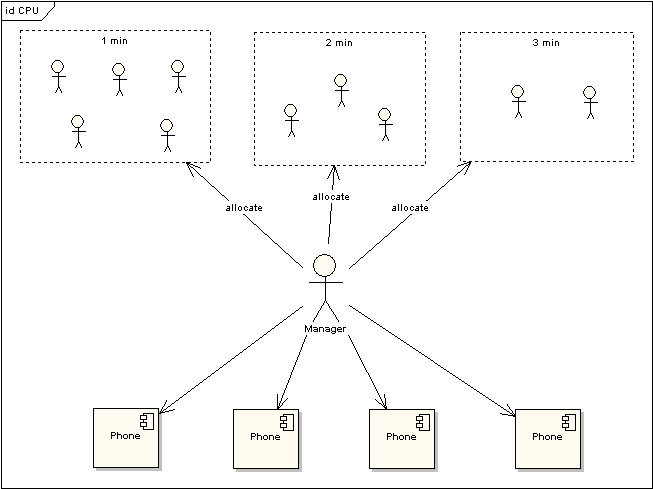
圖 3 電話使用場(chǎng)景
上圖中對(duì)于使用電話的用戶又作了一次分類,1min的代表這些使用者占用電話時(shí)間小于等于1min,2min表示使用者占用電話時(shí)間小于等于2min,以此類推。根據(jù)電話使用規(guī)則,1min的用戶只需要得到一次分配即可完成通話,而其他兩類用戶需要排隊(duì)兩次到三次。
電話的利用率 = sum (active use cpu time)/period
每一個(gè)分配到電話的使用者使用電話時(shí)間的總和去除以統(tǒng)計(jì)的時(shí)間段。這里需要注意的是是使用電話的時(shí)間總和(sum(active use cpu time)),這與占用時(shí)間的總和(sum(occupy cpu time))是有區(qū)別的。(例如一個(gè)用戶得到了一分鐘的使用權(quán),在10秒鐘內(nèi)打了電話,然后去查詢號(hào)碼本花了20秒鐘,再用剩下的30秒打了另一個(gè)電話,那么占用了電話1分鐘,實(shí)際只是使用了40秒)
電話的Average Load體現(xiàn)的是在某一統(tǒng)計(jì)時(shí)間段內(nèi),所有使用電話的人加上等待電話分配的人一個(gè)平均統(tǒng)計(jì)。
電話利用率的統(tǒng)計(jì)能夠反映的是電話被使用的情況,當(dāng)電話長(zhǎng)期處于被使用而沒(méi)有的到足夠的時(shí)間休息間歇,那么對(duì)于電話硬件來(lái)說(shuō)是一種超負(fù)荷的運(yùn)作,需要調(diào)整使用頻度。而電話Average Load卻從另一個(gè)角度來(lái)展現(xiàn)對(duì)于電話使用狀態(tài)的描述,Average Load越高說(shuō)明對(duì)于電話資源的競(jìng)爭(zhēng)越激烈,電話資源比較短缺。對(duì)于資源的申請(qǐng)和維護(hù)其實(shí)也是需要很大的成本,所以在這種高Average Load的情況下電話資源的長(zhǎng)期“熱競(jìng)爭(zhēng)”也是對(duì)于硬件的一種損害。
低利用率的情況下是否會(huì)有高Load Average的情況產(chǎn)生呢?理解占有時(shí)間和使用時(shí)間就可以知道,當(dāng)分配時(shí)間片以后,是否使用完全取決于使用者,因此完全可能出現(xiàn)低利用率高Load Average的情況。由此來(lái)看,僅僅從CPU的使用率來(lái)判斷CPU是否處于一種超負(fù)荷的工作狀態(tài)還是不夠的,必須結(jié)合Load Average來(lái)全局的看CPU的使用情況和申請(qǐng)情況。
所以回過(guò)頭來(lái)再看測(cè)試部對(duì)于Load Average的要求,在我們機(jī)器為8個(gè)CPU的情況下,控制在10 Load左右,也就是每一個(gè)CPU正在處理一個(gè)請(qǐng)求,同時(shí)還有2個(gè)在等待處理。看了看網(wǎng)上很多人的介紹一般來(lái)說(shuō)Load簡(jiǎn)單的計(jì)算就是2* CPU個(gè)數(shù)減去1-2左右(這個(gè)只是網(wǎng)上看來(lái)的,未必是一個(gè)標(biāo)準(zhǔn))。
關(guān)于Linux系統(tǒng)load average負(fù)載的理解
你可能對(duì)于 Linux 的負(fù)載均值(load averages)已有了充分的了解。負(fù)載均值在 uptime 或者 top 命令中可以看到,它們可能會(huì)顯示成這個(gè)樣子:
load average: 0.09, 0.05, 0.01
很多人會(huì)這樣理解負(fù)載均值:三個(gè)數(shù)分別代表不同時(shí)間段的系統(tǒng)平均負(fù)載(一分鐘、五 分鐘、以及十五分鐘),它們的數(shù)字當(dāng)然是越小越好。數(shù)字越高,說(shuō)明服務(wù)器的負(fù)載越 大,這也可能是服務(wù)器出現(xiàn)某種問(wèn)題的信號(hào)。
而事實(shí)不完全如此,是什么因素構(gòu)成了負(fù)載均值的大小,以及如何區(qū)分它們目前的狀況是 “好”還是“糟糕”?什么時(shí)候應(yīng)該注意哪些不正常的數(shù)值?
回答這些問(wèn)題之前,首先需要了解下這些數(shù)值背后的些知識(shí)。我們先用最簡(jiǎn)單的例子說(shuō)明, 一臺(tái)只配備一塊單核處理器的服務(wù)器。
行車過(guò)橋
一 只單核的處理器可以形象得比喻成一條單車道。設(shè)想下,你現(xiàn)在需要收取這條道路的過(guò)橋 費(fèi) -- 忙于處理那些將要過(guò)橋的車輛。你首先當(dāng)然需要了解些信息,例如車輛的載重、以及 還有多少車輛正在等待過(guò)橋。如果前面沒(méi)有車輛在等待,那么你可以告訴后面的司機(jī)通過(guò)。 如果車輛眾多,那么需要告知他們可能需要稍等一會(huì)。
因此,需要些特定的代號(hào)表示目前的車流情況,例如:
- 0.00 表示目前橋面上沒(méi)有任何的車流。 實(shí)際上這種情況與 0.00 和 1.00 之間是相同的,總而言之很通暢,過(guò)往的車輛可以絲毫不用等待的通過(guò)。
- 1.00 表示剛好是在這座橋的承受范圍內(nèi)。 這種情況不算糟糕,只是車流會(huì)有些堵,不過(guò)這種情況可能會(huì)造成交通越來(lái)越慢。
- 超過(guò) 1.00,那么說(shuō)明這座橋已經(jīng)超出負(fù)荷,交通嚴(yán)重的擁堵。 那么情況有多糟糕? 例如 2.00 的情況說(shuō)明車流已經(jīng)超出了橋所能承受的一倍,那么將有多余過(guò)橋一倍的車輛正在焦急的等待。3.00 的話情況就更不妙了,說(shuō)明這座橋基本上已經(jīng)快承受不了,還有超出橋負(fù)載兩倍多的車輛正在等待。

上面的情況和處理器的負(fù)載情況非常相似。一輛汽車的過(guò)橋時(shí)間就好比是處理器處理某線程 的實(shí)際時(shí)間。Unix 系統(tǒng)定義的進(jìn)程運(yùn)行時(shí)長(zhǎng)為所有處理器內(nèi)核的處理時(shí)間加上線程 在隊(duì)列中等待的時(shí)間。
和收過(guò)橋費(fèi)的管理員一樣,你當(dāng)然希望你的汽車(操作)不會(huì)被焦急的等待。所以,理想狀態(tài) 下,都希望負(fù)載平均值小于 1.00 。當(dāng)然不排除部分峰值會(huì)超過(guò) 1.00,但長(zhǎng)此以往保持這 個(gè)狀態(tài),就說(shuō)明會(huì)有問(wèn)題,這時(shí)候你應(yīng)該會(huì)很焦急。
“所以你說(shuō)的理想負(fù)荷為 1.00 ?”
嗯,這種情況其實(shí)并不完全正確。負(fù)荷 1.00 說(shuō)明系統(tǒng)已經(jīng)沒(méi)有剩余的資源了。在實(shí)際情況中 ,有經(jīng)驗(yàn)的系統(tǒng)管理員都會(huì)將這條線劃在 0.70:
- “需要進(jìn)行調(diào)查法則”: 如果長(zhǎng)期你的系統(tǒng)負(fù)載在 0.70 上下,那么你需要在事情變得更糟糕之前,花些時(shí)間了解其原因。
- “現(xiàn)在就要修復(fù)法則”:1.00 。 如果你的服務(wù)器系統(tǒng)負(fù)載長(zhǎng)期徘徊于 1.00,那么就應(yīng)該馬上解決這個(gè)問(wèn)題。否則,你將半夜接到你上司的電話,這可不是件令人愉快的事情。
- “凌晨三點(diǎn)半鍛煉身體法則”:5.00。 如果你的服務(wù)器負(fù)載超過(guò)了 5.00 這個(gè)數(shù)字,那么你將失去你的睡眠,還得在會(huì)議中說(shuō)明這情況發(fā)生的原因,總之千萬(wàn)不要讓它發(fā)生。
那么多個(gè)處理器呢?我的均值是 3.00,但是系統(tǒng)運(yùn)行正常!
哇喔,你有四個(gè)處理器的主機(jī)?那么它的負(fù)載均值在 3.00 是很正常的。
在多處理器系統(tǒng)中,負(fù)載均值是基于內(nèi)核的數(shù)量決定的。以 100% 負(fù)載計(jì)算,1.00 表示單個(gè)處理器,而 2.00 則說(shuō)明有兩個(gè)雙處理器,那么 4.00 就說(shuō)明主機(jī)具有四個(gè)處理器。

回到我們上面有關(guān)車輛過(guò)橋的比喻。1.00 我說(shuō)過(guò)是“一條單車道的道路”。那么在單車道 1.00 情況中,說(shuō)明這橋梁已經(jīng)被車塞滿了。而在雙處理器系統(tǒng)中,這意味著多出了一倍的 負(fù)載,也就是說(shuō)還有 50% 的剩余系統(tǒng)資源 -- 因?yàn)檫€有另外條車道可以通行。
所以,單處理器已經(jīng)在負(fù)載的情況下,雙處理器的負(fù)載滿額的情況是 2.00,它還有一倍的資源可以利用。
多核與多處理器
先脫離下主題,我們來(lái)討論下多核心處理器與多處理器的區(qū)別。從性能的角度上理解,一臺(tái)主 機(jī)擁有多核心的處理器與另臺(tái)擁有同樣數(shù)目的處理性能基本上可以認(rèn)為是相差無(wú)幾。當(dāng)然實(shí)際 情況會(huì)復(fù)雜得多,不同數(shù)量的緩存、處理器的頻率等因素都可能造成性能的差異。
但即便這些因素造成的實(shí)際性能稍有不同,其實(shí)系統(tǒng)還是以處理器的核心數(shù)量計(jì)算負(fù)載均值 。這使我們有了兩個(gè)新的法則:
- “有多少核心即為有多少負(fù)荷”法則: 在多核處理中,你的系統(tǒng)均值不應(yīng)該高于處理器核心的總數(shù)量。
- “核心的核心”法則: 核心分布在分別幾個(gè)單個(gè)物理處理中并不重要,其實(shí)兩顆四核的處理器 等于 四個(gè)雙核處理器 等于 八個(gè)單處理器。所以,它應(yīng)該有八個(gè)處理器內(nèi)核。
審視我們自己
讓我們?cè)賮?lái)看看 uptime 的輸出
~ $ uptime
23:05 up 14 days, 6:08, 7 users, load averages: 0.65 0.42 0.36
這是個(gè)雙核處理器,從結(jié)果也說(shuō)明有很多的空閑資源。實(shí)際情況是即便它的峰值會(huì)到 1.7,我也從來(lái)沒(méi)有考慮過(guò)它的負(fù)載問(wèn)題。
那么,怎么會(huì)有三個(gè)數(shù)字的確讓人困擾。我們知道,0.65、0.42、0.36 分別說(shuō)明上一分鐘、最后五分鐘以及最后十五分鐘的系統(tǒng)負(fù)載均值。那么這又帶來(lái)了一個(gè)問(wèn)題:
我們以哪個(gè)數(shù)字為準(zhǔn)?一分鐘?五分鐘?還是十五分鐘?
其 實(shí)對(duì)于這些數(shù)字我們已經(jīng)談?wù)摿撕芏啵艺J(rèn)為你應(yīng)該著眼于五分鐘或者十五分鐘的平均數(shù) 值。坦白講,如果前一分鐘的負(fù)載情況是 1.00,那么仍可以說(shuō)明認(rèn)定服務(wù)器情況還是正常的。 但是如果十五分鐘的數(shù)值仍然保持在 1.00,那么就值得注意了(根據(jù)我的經(jīng)驗(yàn),這時(shí)候你應(yīng) 該增加的處理器數(shù)量了)。
那么我如何得知我的系統(tǒng)裝備了多少核心的處理器?
在 Linux 下,可以使用
cat /proc/cpuinfo
獲取你系統(tǒng)上的每個(gè)處理器的信息。如果你只想得到數(shù)字,那么就使用下面的命令:
grep 'model name' /proc/cpuinfo | wc -l
1 load average 的定義
在特定時(shí)間間隔內(nèi)運(yùn)行隊(duì)列中的平均進(jìn)程數(shù)。
2 w 命令查看 load average
load average: 1.00, 0.7, 0.8
1分鐘 5 分鐘 15分鐘
其中分別代表1分鐘,5分鐘,15分鐘系統(tǒng)的平均負(fù)載。則三個(gè)數(shù)字,會(huì)重點(diǎn)觀察5分鐘,15分鐘對(duì)應(yīng)的數(shù)值,這反映了系統(tǒng)一段時(shí)間的工作狀況。此值低于1.00為正常(注釋1),長(zhǎng)時(shí)間等于1.00需要引起注意,大于5.00說(shuō)明系統(tǒng)出現(xiàn)嚴(yán)重的 cpu資源不足,隨時(shí)可能出問(wèn)題,屬于critical級(jí)別。
3 load average 與cpu 利用率的區(qū)別
3.1 cpu 利用率的查看,top命令
3.2 什么是cpu利用率
單位時(shí)間內(nèi)進(jìn)程使用cpu時(shí)間的百分比
3.3 load average 與cpu 利用率的區(qū)別
load average=占用cpu進(jìn)程+排隊(duì)進(jìn)程數(shù)
cpu利用率=單位時(shí)間內(nèi)進(jìn)程使用cpu時(shí)間的百分比
load average 表示的是cpu還有多少件事情要處理,cpu利用率表示:一個(gè)進(jìn)程別cpu處理時(shí),占用時(shí)間片(注釋2)的比值。
注釋1:這里指的是1個(gè)cpu所對(duì)應(yīng)的負(fù)載值。
注釋2:在Linux的內(nèi)核處理過(guò)程中,每一個(gè)進(jìn)程默認(rèn)會(huì)有一個(gè)固定的時(shí)間片來(lái)執(zhí)行命令(默認(rèn)為1/100秒),這段時(shí)間稱為時(shí)間片。