摘自http://blog.csdn.net/hackbuteer1/article/details/7722667
在 各種計算機(jī)體系結(jié)構(gòu)中,對于字節(jié)、字等的存儲機(jī)制有所不同,因而引發(fā)了計算機(jī) 通信領(lǐng) 域中一個很重要的問題,即通信雙方交流的信息單元(比特、字節(jié)、字、雙字等等)應(yīng)該以什么樣的順序進(jìn)行傳送。如果不達(dá)成一致的規(guī)則,通信雙方將無法進(jìn)行正 確的編/譯碼從而導(dǎo)致通信失敗。目前在各種體系的計算機(jī)中通常采用的字節(jié)存儲機(jī)制主要有兩種:Big-Endian和Little-Endian,下面先從字節(jié)序說起。
一、什么是字節(jié)序
字節(jié)序,顧名思義字節(jié)的順序,再多說兩句就是大于一個字節(jié)類型的數(shù)據(jù)在內(nèi)存中的存放順序(一個字節(jié)的數(shù)據(jù)當(dāng)然就無需談順序的問題了)。其實大部分人在實際的開 發(fā)中都很少會直接和字節(jié)序打交道。唯有在跨平臺以及網(wǎng)絡(luò)程序中字節(jié)序才是一個應(yīng)該被考慮的問題。
在所有的介紹字節(jié)序的文章中都會提到字 節(jié)序分為兩類:Big-Endian和Little-Endian,引用標(biāo)準(zhǔn)的Big-Endian和Little-Endian的定義如下:
a) Little-Endian就是低位字節(jié)排放在內(nèi)存的低地址端,高位字節(jié)排放在內(nèi)存的高地址端。
b) Big-Endian就是高位字節(jié)排放在內(nèi)存的低地址端,低位字節(jié)排放在內(nèi)存的高地址端。
c) 網(wǎng)絡(luò)字節(jié)序:TCP/IP各層協(xié)議將字節(jié)序定義為Big-Endian,因此TCP/IP協(xié)議中使用的字節(jié)序通常稱之為網(wǎng)絡(luò)字節(jié)序。
1.1 什么是高/低地址端
首先我們要知道C程序映像中內(nèi)存的空間布局情況:在《C專 家編程》中或者《Unix環(huán)境高級編程》中有關(guān)于內(nèi)存空間布局情況的說明,大致如下圖:
----------------------- 最高內(nèi)存地址 0xffffffff
棧底
棧
棧頂
-----------------------
NULL (空洞)
-----------------------
堆
-----------------------
未初始 化的數(shù)據(jù)
----------------------- 統(tǒng)稱數(shù)據(jù)段
初始化的數(shù)據(jù)
-----------------------
正 文段(代碼段)
----------------------- 最低內(nèi)存地址 0x00000000
由圖可以看出,再內(nèi)存分布中,棧是向下增長的,而堆是向上增長的。
以上圖為例如果我們在棧 上分配一個unsigned char buf[4],那么這個數(shù)組變量在棧上是如何布局的呢?看下圖:
棧底 (高地址)
----------
buf[3]
buf[2]
buf[1]
buf[0]
----------
棧頂 (低地址)
其實,我們可以自己在編譯器里面創(chuàng)建一個數(shù)組,然后分別輸出數(shù)組種每個元素的地址,來驗證一下。
1.2 什么是高/低字節(jié)
現(xiàn)在我們弄清了高/低地址,接著考慮高/低字節(jié)。有些文章中稱低位字節(jié)為最低有效位,高位字節(jié)為最高有效位。如果我們有一個32位無符號整型0x12345678,那么高位是什么,低位又是什么呢? 其實很簡單。在十進(jìn)制中我們都說靠左邊的是高位,靠右邊的是低位,在其他進(jìn)制也是如此。就拿 0x12345678來說,從高位到低位的字節(jié)依次是0x12、0x34、0x56和0x78。
高/低地址端和高/低字節(jié)都弄清了。我們再來回顧 一下Big-Endian和Little-Endian的定義,并用圖示說明兩種字節(jié)序:
以unsigned int value = 0x12345678為例,分別看看在兩種字節(jié)序下其存儲情況,我們可以用unsigned char buf[4]來表示value:
Big-Endian: 低地址存放高位,如下圖:
棧底 (高地址)
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
棧頂 (低地址)
Little-Endian: 低地址存放低位,如下圖:
棧底 (高地址)
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
棧 頂 (低地址)
二、各種Endian
2.1 Big-Endian
計算機(jī)體系結(jié)構(gòu)中一種描述多字節(jié)存儲順序的術(shù)語,在這種機(jī)制中最重要字節(jié)(MSB)存放在最低端的地址 上。采用這種機(jī)制的處理器有IBM3700系列、PDP-10、Mortolora微處理器系列和絕大多數(shù)的RISC處理器。
+----------+
| 0x34 |<-- 0x00000021
+----------+
| 0x12 |<-- 0x00000020
+----------+
圖 1:雙字節(jié)數(shù)0x1234以Big-Endian的方式存在起始地址0x00000020中
在Big-Endian中,對于bit序列 中的序號編排方式如下(以雙字節(jié)數(shù)0x8B8A為例):
bit 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+----------------------------------------+
圖 2:Big-Endian的bit序列編碼方式
2.2 Little-Endian
計算機(jī)體系結(jié)構(gòu)中 一種描述多字節(jié)存儲順序的術(shù)語,在這種機(jī)制中最不重要字節(jié)(LSB)存放在最低端的地址上。采用這種機(jī)制的處理器有PDP-11、VAX、Intel系列微處理器和一些網(wǎng)絡(luò)通信設(shè)備。該術(shù)語除了描述多字節(jié)存儲順序外還常常用來描述一個字節(jié)中各個比特的排放次序。
+----------+
| 0x12 |<-- 0x00000021
+----------+
| 0x34 |<-- 0x00000020
+----------+
圖3:雙字節(jié)數(shù)0x1234以Little-Endian的方式存在起始地址0x00000020中
在 Little-Endian中,對于bit序列中的序號編排和Big-Endian剛好相反,其方式如下(以雙字節(jié)數(shù)0x8B8A為例):
bit 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+-----------------------------------------+
圖 4:Little-Endian的bit序列編碼方式
注意:通常我們說的主機(jī)序(Host Order)就是遵循Little-Endian規(guī)則。所以當(dāng)兩臺主機(jī)之間要通過TCP/IP協(xié)議進(jìn)行通信的時候就需要調(diào)用相應(yīng)的函數(shù)進(jìn)行主機(jī)序 (Little-Endian)和網(wǎng)絡(luò)序(Big-Endian)的轉(zhuǎn)換。
采用 Little-endian模式的CPU對操作數(shù)的存放方式是從低字節(jié)到高字節(jié),而Big-endian模式對操作數(shù)的存放方式是從高字節(jié)到低字節(jié)。 32bit寬的數(shù)0x12345678在Little-endian模式CPU內(nèi)存中的存放方式(假設(shè)從地址0x4000開始存放)為:
內(nèi)存地址 0x4000 0x4001 0x4002 0x4003
存放內(nèi)容 0x78 0x56 0x34 0x12
而在Big- endian模式CPU內(nèi)存中的存放方式則為:
內(nèi)存地址 0x4000 0x4001 0x4002 0x4003
存放內(nèi)容 0x12 0x34 0x56 0x78
具體的區(qū)別如下:

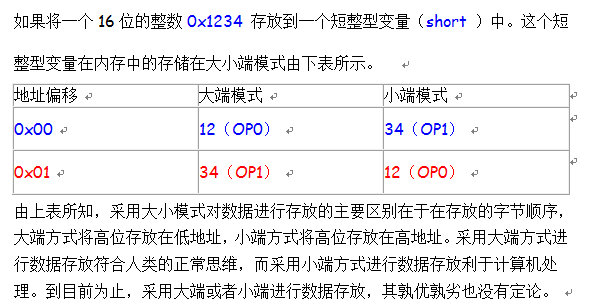
三、Big-Endian和Little-Endian優(yōu)缺點
Big-Endian優(yōu)點:靠首先提取高位字節(jié),你總是可以由看看在偏移位置為0的字節(jié)來確定這個數(shù)字是 正數(shù)還是負(fù)數(shù)。你不必知道這個數(shù)值有多長,或者你也不必過一些字節(jié)來看這個數(shù)值是否含有符號位。這個數(shù)值是以它們被打印出來的順序存放的,所以從二進(jìn)制到十進(jìn)制的函數(shù)特別有效。因而,對于不同要求的機(jī)器,在設(shè)計存取方式時就會不同。
Little-Endian優(yōu)點:提取一個,兩個,四個或者更長字節(jié)數(shù)據(jù)的匯編指令以與其他所有格式相同的方式進(jìn)行:首先在偏移地址為0的地方提取最低位的字節(jié),因為地址偏移和字節(jié)數(shù)是一對一的關(guān)系,多重精度的數(shù)學(xué)函數(shù)就相對地容易寫了。
如果你增加數(shù)字的值,你可能在左邊增加數(shù)字(高位非指數(shù)函數(shù)需要更多的數(shù)字)。 因此, 經(jīng)常需要增加兩位數(shù)字并移動存儲器里所有Big-endian順序的數(shù)字,把所有數(shù)向右移,這會增加計算機(jī)的工作量。不過,使用Little- Endian的存儲器中不重要的字節(jié)可以存在它原來的位置,新的數(shù)可以存在它的右邊的高位地址里。這就意味著計算機(jī)中的某些計算可以變得更加簡單和快速。
四、請寫一個C函數(shù),若處理器是Big_endian的,則返回0;若是Little_endian的,則返回1。
- int checkCPU(void)
- {
- union
- {
- int a;
- char b;
- }c;
- c.a = 1;
- return (c.b == 1);
- }
說明:
1 在c中,聯(lián)合體(共用體)的數(shù)據(jù)成員都是從低地址開始存放。
2 若是小端模式,由低地址到高地址c.a存放為0x01 00 00 00,c.b被賦值為0x01;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 01 00 00 00
c.b 01 00
————————————————————————————
3 若是大端模式,由低地址到高地址c.a存放為0x00 00 00 01,c.b被賦值為0x0;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 00 00 00 01
c.b 00 00
————————————————————————————
4 根據(jù)c.b的值的情況就可以判斷cpu的模式了。
舉例,一個16進(jìn)制數(shù)是 0x11 22 33,其存放的位置是
地址0x3000 中存放11
地址0x3001 中存放22
地址0x3002 中存放33
連起來就寫成地址0x3000-0x3002中存放了數(shù)據(jù)0x112233
而這種存放和表示方式,正好符合大端。
另外一個比較好理解的寫法如下:
- bool checkCPU() // 如果是大端模式,返回真
- {
- short int test = 0x1234;
-
- if( *((char *)&test) == 0x12) // 低地址存放高字節(jié)數(shù)據(jù)
- return true;
- else
- return false;
- }
-
- int main(void)
- {
- if( !checkCPU())
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
-
- return 0;
- }
- int main(void)
- {
- short int a = 0x1234;
- char *p = (char *)&a;
-
- if( *p == 0x34)
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
-
- return 0;
- }
-
- int main(void)
- {
- short int a = 0x1234;
- char x0 , x1;
-
- x0 = ((char *)&a)[0];
- x1 = ((char *)&a)[1];
-
- if( x0 == 0x34)
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
-
- return 0;
- }