class A
{
public:
template <typename T>
T f(T val);
template <>
int f<int>(int val);
};
我用的是g++ 3.4.2 mingw版本。编译上面这�D�代码时�Q�错误信息如下:
5: error: invalid explicit specialization before '>' token
5: error: explicit specialization in non-namespace scope `class A'
如果把f的定义放到全局作用域中�Q�就不会出错。而上面这�D�代码在VC++ 8.0下可以编译通过。运行�v来也没有问题。别的编译器我没有试�q��?br />
Update�Q�多谢周星星的指点,比较“常规”的写法如下:
class A
{
public:
template <typename T>
T f(T val);
};
template <typename T>
T A::f(T val)
{
// ...
}
template <>
int A::f<int>(int val)
{
//...
}
�q�种写法���没有�Q何问�?在g++ 3.4.2和VC++ 8.0下均表现正常�Q�。至于�ؓ什么前面的写法��D��g++下报错,�q�不是很清楚�?img src ="http://www.shnenglu.com/chengmeng/aggbug/13604.html" width = "1" height = "1" />
]]>
历史�Q�高�U�程序语�a�的老祖宗,Fortran�Q�对源程序中的名字,或者叫标识�W?identifier)有很严格的规定,譬如首字母代表变量的�c�d���{�等。个����������是当�q�编译技术还未成熟时的权宜之计。后来主���的�E�序设计语言都放松了对名字的限制�Q�像C/C++/Java�Q�只有一点点���小的约束(�Ҏ��用字�W�的限制�Q�只能��用英文字母、数字、下划线�Q�必���M��下划�U�或英文字母开头。这也容易理解,完全是�ؓ了写词法分析器的方便�Q�。而和Fortran同时代的Lisp�Q�这斚w��更是大开�l�灯�Q�爱怎么定义怎么定义。然而到了现在,��g��有点复古的潮���,有些语言开始对名字讄���一些规则,比如Haskell,Erlang,包括Ruby�?br />
�a�归正传。Ruby中的名字规则主要是根据名字的�W�一个字母来军_���q�个名字的��用方式。具体来��_��
- 局部变量,�Ҏ��名,�Ҏ��参数�Q�以���写字母或下划线开��_���?_'�q�接�?br />Example�Q�i,note_controller
- 帔R���Q�全部大写,�?_'�q�接
Example�Q�A_NUM - �c�,模块(module)�Q�都是开头大写(因�ؓ�c�d��是全局变量�Q�,其他���写�q�且直接�q�接在一�?br />Example�Q�ActiveRecord
- 全局变量�Q�以'$'开��_��肯定是跟Perl学的�Q�我觉得不怎么好)
- 实例变量(instance variable)�Q�以'@'开��_��同上�Q?/li>
- �c�d���?class variable)�Q�以'@@'开��_��诡异�Q?/li>
]]>
Ruby的源代码�q�充分体��C��拿来��M��的精���,能重用的决不自己写:比如Hash表就用了一个通用的Hash表实玎ͼ�正则表达式则使用了GNU的regex库,random是有名的MT19937�Q�也是日本�h写的�Q�。尝试了一下编译,在mingw上执行标准三部曲�Q?/configure,make,make install�Q�一切OK�?br />
]]>
size_t little(size_t i)
{
size_t ones = calc_ones(i);
if(ones == i)
cout << i << "\n";
if(i < ones)
if((ones - i)/9 > 1)
return i - (ones - i)/8;
if(i > ones)
return ones;
return i - 1;
}
�q�是C++版本。主循环也要略微改变一下:
void solve()
{
size_t max = 10000000000;
for(size_t i = max;i > 0;i = little(i));
}
可以看到�Q�现在��@环从大到���。little函数扑ֈ�下一个可能满���题目约束的i。在little函数中,首先计算���于i�?的个数ones�Q�如果ones和i相等�Q�就���i输出�Q�这���是题目要求�q�的事)。如果i���于ones�Q�那么就要在���于i的自然数中找下一个可能满���x��件的数。因为搜索的范围不超�q?0^10�Q�所以一个数中至多含�?�?�Q�按照这�U�极端情况,也必���d��i减少(ones-i)/8才有可能满��条�g(�q�里之所以是8�Q�因为同时i也减���了�Q�。如果i大于ones�Q�考虑一个小于i的数i'�Q�可以考虑一下calc_ones(i')的取��|��极端情况�Q�[i',i)的范围内的整数没有一个包�?�Q�也���是说当i减少到i'�?的个数没有损失,那么calc_ones(i') = calc_ones(i)�Q�如果i'>calc_ones(i)�Q�则���有i'>calc_ones(i')�Q�直到i'=calc_ones(i)�Q�因此下一个需要查看的数就是calc_ones(i)。其实上面这一�D�讨论可以用一个式子来概括�Q�对i'<i,calc_ones(i)-9*(i-i') <= calc_ones(i') <= calc_ones(i)。这样就能大大提高速度了�?br />
]]>
]]>
Turbo下蝲
Update�Q�说一下下载文件的情况。有两个部分�Q�一个是prerequisites�Q�另一个是main installation。奇怪的是prerequisites当中�q�包�?NET Framework 1.1�Q�是不是太old了一点?�q�部分prerequisites和Borland Develop Studio基本上是一��L���?br />
�l�箋Update�Q�很不幸�Q�未能成功。安装了一遍之后,启动时接�q�保错,��g��是在��d��rtl100.bpl和coreide100.bpl的时候出了段错误�Q�结果IDE是启动了�Q�和C++有关的项目还有组件一个都没有……虽然还剩了诸如�~�译器和�~�辑器调试器�{�内容,但意义不大。考虑到机子上原来�q�装了个C++ Builder 6�Q�卸之,再重装一遍Turbo C++�Q�还是老样子……彻底放弃�?br />
]]>
�q�是直接�l�出代码�Q?br />
#include <iostream>
#include <string>
using namespace std;
int main()
{
const char *p = string("hello").c_str();
cout << p << endl;
return 0;
}
��x��输出�l�果是什么?
�q�时VS2005和g++的结果就不一样了。VS2005上什么都不输出,而g++ 3.4上则输出了似乎非常合理的�l�果�Q�hello�Q�符合很多�h的预期。不�q�查了标准以后,�q�是把票投给VS2005�?br />
首先�Q?font face="Courier New">string("hello")产生了一个temporary object�Q�或者说临时对象。C++标准对��时对象的生存�?life time)有明���的规定�Q�可见标�?2.2节第3-5条。第3条讨��Z��临时对象的析构时��_��
3. ... Temporary objects are destroyed as the last step in evaluating the full-expression (1.9) that (lexically) contains the point where they were created. This is true even if that evaluation ends in throwing an exception.
�q�又涉及到full-expression的定义了�Q�参�?.9节。整个对p的初始化构成了一个full-expression。在下结��Z��前,�q�要先看看第4�?条,分别讨论了两个例外情形,一个是�����时对象作为初始化子,例如string s = string("hello")�Q�第二是���一个引用变量绑定到�q�个临时对象上,例如const string &s = string("hello")�Q�总而言之,在这两种情�Ş中可以通过一个名字来存取�q�个对象�Q�此对象的生存期����g长到变量名的作用域结束。除此之外,都按照第3条处理�?br />
有了�q�些准备�Q�拿前面�l�的例子往里套���明白了�Q�这里没有出�?�?所指出的例外,因此�W?条的原则适用。而不���full-expression如何�Q�可以确定的是在p被初始化之后临时对象string("hello")的析构函数就应该被调用。在VS2005中进行调试,可以发现string析构函数调用的时间就在p被初始化之后�Q�语�?font face="Courier New">cout << p << endl执行之前。手头没有方便的工具来调试g++�~�译出来的程�?不太会用gdb调试C++�E�序�Q�特别涉及到STL)。至于之后p指向的内存到底如何,则和具体的string实现相关了。这样分析下来,VS2005的结果还是比较不错的�Q�而g++的结果则�Ҏ��让�h产生误解�?br />
Update�Q�察看g++�~�译出来的汇�~�代码,发现g++同样在表辑ּ�求值后析构了��时对象,只不�q�由于实��C��的原因,p指向的内容还没有清空�?img src ="http://www.shnenglu.com/chengmeng/aggbug/12024.html" width = "1" height = "1" />
]]>
def sievePerformance(n)
r = Benchmark.realtime() do
sieve = Array.new(n,true)
sieve[0..1] = [false,false]
2.upto(n) do |i|
if sieve[i]
(2*i).step(n,i) do |j|
sieve[j] = false
end
end
end
end
r
end
�q�段代码抄自前面Robert C.Martin先生的blog�Q�对�{�法作性能���试。初看�v来,�E�序的主体是二重循环�Q�因此算法的复杂性好像是O(N2)之类的玩意?要么是O(NlnN)�Q?br />
下图是Ruby自带的benchmark模块���量的结果,上限N�?0000�?00000�Q�步�?0000。Rober C.Martin的文章里也有一张图�Q�是�?000000�?000000�Q�从图中可以看到�Q�他电脑的性能�q�胜于我�Q�我要是�?000000�?000000�q�么跑一遍,花儿都谢了……��M���Q�实���的�l�果是:�q�个���法的性能基本上是�U�性的。出于对ruby�q�样的解释型语言的某�U�不信�Q�Q�我又把�q�段�E�序用C++重写了一遍,拿C标准库提供的clock函数���量旉����Q�结果在N���于10000000的时候,基本上呈�U�性,但再往后花费的旉������开始超�q�线性增长了�?br />
下面我给一个比较粗略的分析�Q�解释�ؓ什么这个算法的复杂度表��Cؓ�U�性。首先,我认��Z��要花�Ҏ��间的是对sieve数组的读写,循环变量的增加应该可以忽略。如果p<N是素敎ͼ�那么���p���q�入内��@环将i的倍数“挖掉”,也就是对sieve的相应元素赋��|��要进行[N/p]-1�ơ。这样就得到��d��的赋值次数S为:
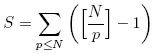
其中p为素数。显�?br />
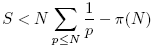
数论中有个Mertens定理可以估计上面括号中的和式�Q�结果�ؓ
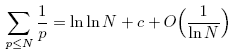
其中c是一个常数。可以看刎ͼ�在N很大时和式的主要部分为NlnlnN。而lnlnN是一个增长极慢的函数�Q�lnln105=2.44�Q�lnln109=2.91�Q�几乎就可以当常数处理(臛_���?2位无�W�号整数范围内)。其他的一些项�Q�比如��@环变量的步进�Q�都是O(N)�Q�这也就不难理解整个�E�序的性能是几乎是O(N)了�?br />
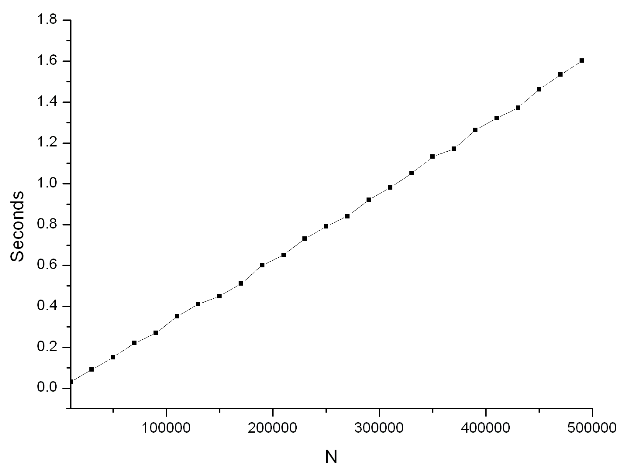
Update�Q�上面的代码有个很明昄���问题�Q�就是内循环应该从i*i开始,而不�?*i�Q�这样对于比较大的N�Q�性能提高很明显(接近一半)。另外一个可改进的地�Ҏ��外层循环的upto(n)�Q�可以改为upto(Integer(Math.sqrt(n))�Q�其实这两个改动效果是重叠的�Q��Q意改一个就差不多了。赋值次数S应�ؓ�Q?br />
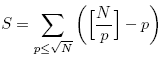
�l�果为:
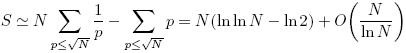
可以看到效率的提升是很明昄����Q�毕竟lnln232也才不到3.1�Q�ln2�U��ؓ0.7�?br />
]]>
用Haskell写了两个排序���法�Q�快速排序和合�ƈ排序。都很短�Q�没几行�E�序�Q�虽然效率肯定是不敢恭维的,但能用来满��我们那自�ƺ欺人的���感�Q�言���意赅不是很高的境界么�Q�不���是写文章还是写�E�序都差不多。但同时要清楚,要可��L��。说了这么多�q�是看看成果吧:
module Sort where其实只利用了递归和Haskell强大的列表处理功能。这也不是Haskell的专利,我相信Python或Ruby或Lisp也完全能做到�?img src ="http://www.shnenglu.com/chengmeng/aggbug/11424.html" width = "1" height = "1" />
-- Quick Sort Algorithm
quicksort [] = []
quicksort (x:xs) = quicksort [y | y <- xs,y <= x]
++ [x] ++ quicksort [y | y <- xs,y > x]
-- Merge two ordered sequences
merge' [] [] = []
merge' lst [] = lst
merge' [] lst = lst
merge' (x1:xs1) (x2:xs2) =
if x1 < x2
then x1:(merge' xs1 (x2:xs2))
else x2:(merge' (x1:xs1) xs2)
-- Merge Sort Algorithm
mergesort [] = []
mergesort (x:[]) = [x]
mergesort lst =
let parts = splitAt (div (length lst) 2) lst
in merge' (mergesort (fst parts))
(mergesort (snd parts))
]]>
sub is_prime {
my ($number) = @_;
return (1 x $number) !~ m/\A (?: 1? | (11+?)(?> \1+)) \Z/xms;
}
是不是有点匪��h��思?堪称Perl中的混�ؕ代码(Obfuscated Code)。所以正则表辑ּ��q�个玩意�Q�用得好了不��_��巨强大无比,可是晦�ӆ��h��也不输于机器码。我现在对Perl了解不多�Q�上面这行正则表辑ּ����p��我郁闷了很久�Q�刚看到���p��了:?:�?>是什么东西?赶紧���d��Programming Perl看,原来是Perl的Extented Regular Expression……恶补了一阵之后回头来琢磨�Q�终于大致明白其中的道理�?br />
原理其实很简单,���是最原始的方法:如果要决定正整数N是不是素敎ͼ����拿���于N的正整数(�?开�?挨个去除�Q�如果发现除���则表明是合数。当�Ӟ��0�?要特�D�处理,他们两个都不是素敎ͼ�前面正则表达式中�??���是��Z���q�个目的。�?11+?)(?> \1+)���开始了循环���验的�q�程。这其中的过�E�很有意思,最好是拿Perl的re模块来debug一下,只要在文件开头加上use re"debug"���成了,执行时会详细的输出整个匹配的�q�程。我们现在就来跟�t�一下,在匹配时到底发生了什么好玩的事情�?br />
(1 x $number)创徏了一个长度�ؓ$number�Q�全部由'1'�l�成的串。首先,(11+?)可以匚w��长度不小�?的全�?1'�l�成的字�W�串。假如我们拿"1111"��d��配,那么首先(11+?)会匹配整个串�Q��ƈ���这部分匚w��到的内容保存在\1中。然后往下走�Q�这时第二部分的要求不能满��了—�??> \1+)。暂且不��?>是什么意思,�q�个表达式的要求���是前面匚w��到的部分重复出现一�ơ以�?看到�q�里可能已经有�h明白了,�q�不���是整除么?变态整除!)�Q�但是目前的匚w��不满������求:整个串都匚w��光了�Q�只剩下一个\Z了。所以我们唯物主义的正则表达式引擎会backtracing(回溯)�Q�往回退一步,�?11+?)只匹�?111"�Q�但�q�样�q�是不行�Q�只好再往回退�Q�这时你发现�Q�\1中的内容�?11"�Q�剩下的部分也是"11"�Q�匹配成功了。其实这只是4=2*2的另一�U�说法。注意到函数中的匚w���q�算�W�是!~�Q�整个函数返�?。如果一直回退到最��?"11")�q�是匚w��不了�Q�说�?number是一个素数�?br />
说到�q�里�Q�作者的巧思确实值得佩服�Q�虽然看�I�了会觉得不�q�如此。然后还有两个问题没有解冻I�����是?>�?:到底是干什么吃的??>的意思是No backtracing,?:则是Cluster but no grouping�?>可以不要�Q�不影响�l�果(可能�Ҏ��率有些媄响,但相信没有�h会拿�q�种办法��d��定素性的)�Q�但?:��׃��可缺���了�?/font>
]]>