Document Object Model
From Wikipedia, the free encyclopedia
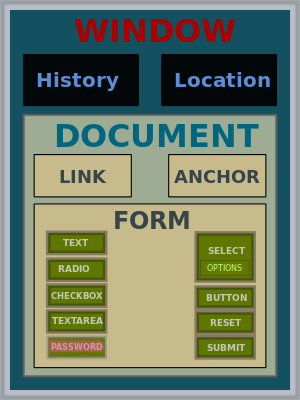
The Document Object Model (DOM) is a cross-platform and language-independent convention for representing and interacting with objects in HTML, XHTML and XML documents. Objects under the DOM (also sometimes called "Elements") may be specified and addressed according to the syntax and rules of the programming language used to manipulate them. The rules for programming and interacting with the DOM are specified in the DOM Application Programming Interface (API).
Contents[hide] |
[edit] History
The history of the Document Object Model is intertwined with the history of the "browser wars" of the late 1990s between Netscape Navigator and Microsoft Internet Explorer, likewise that of JavaScript and JScript, the first scripting languages to be widely implemented in the layout engines of web browsers.
[edit] Legacy DOM
JavaScript was released by Netscape Communications in 1996 within Netscape Navigator 2.0. Netscape's competitor, Microsoft, released Internet Explorer 3.0 later the same year with a port of JavaScript called JScript. JavaScript and JScript let web developers create web pages with client-side interactivity. The limited facilities for detecting user-generated events and modifying the HTML document in the first generation of these languages eventually became known as "DOM Level 0" or "Legacy DOM". No independent standard was developed for DOM Level 0, but it was partly described in the specification of HTML4.
Legacy DOM was limited in the kinds of elements that could be accessed. Form, link and image elements could be referenced with a hierarchical name that began with the root document object. A hierarchical name could make use of either the names or the sequential index of the traversed elements. For example, a form input element could be accessed as either "document.formName.inputName" or "document.forms[0].elements[0]".
The Legacy DOM enabled client-side form validation and the popular "rollover" effect.
[edit] Intermediate DOM
In 1997, Netscape and Microsoft released version 4.0 of Netscape Navigator and Internet Explorer, adding support for Dynamic HTML (DHTML), functionality enabling changes to a loaded HTML document. DHTML required extensions to the rudimentary document object that was available in the Legacy DOM implementations. Although the Legacy DOM implementations were largely compatible since JScript was based on JavaScript, the DHTML DOM extensions were developed in parallel by each browser maker and remained incompatible. These versions of the DOM became known as the "Intermediate DOM."
The Intermediate DOMs enabled the manipulation of Cascading Style Sheet (CSS) properties which influence the display of a document. They also provided access to a new feature called "layers" via the "document.layers" property (Netscape Navigator) and the "document.all" property (Internet Explorer). Because of the fundamental incompatibilities in the Intermediate DOMs, cross-browser development required special handling for each supported browser.
Subsequent versions of Netscape Navigator abandoned support for its Intermediate DOM. Internet Explorer continues to support its Intermediate DOM for backwards compatibility.
[edit] Standardization
The World Wide Web Consortium (W3C), founded in 1994 to promote open standards for the World Wide Web, brought Netscape Communications and Microsoft together with other companies to develop a standard for browser scripting languages, called "ECMAScript". The first version of the standard was published in 1997. Subsequent releases of JavaScript and JScript would implement the ECMAScript standard for greater cross-browser compatibility.
After the release of ECMAScript, W3C began work on a standardized DOM. The initial DOM standard, known as "DOM Level 1," was recommended by W3C in late 1998. About the same time, Internet Explorer 5.0 shipped with limited support for DOM Level 1. DOM Level 1 provided a complete model for an entire HTML or XML document, including means to change any portion of the document. Non-conformant browsers such as Internet Explorer 4.x and Netscape 4.x were still widely used as late as 2000.
DOM Level 2 was published in late 2000. It introduced the "getElementById" function as well as an event model and support for XML namespaces and CSS. DOM Level 3, the current release of the DOM specification, published in April 2004, added support for XPath and keyboard event handling, as well as an interface for serializing documents as XML.
By 2005, large parts of W3C DOM were well-supported by common ECMAScript-enabled browsers, including Microsoft Internet Explorer version 6 (2001), Gecko-based browsers (like Mozilla, Firefox and Camino), Konqueror, Opera, and Safari.
[edit] Applications
DOM is likely to be best suited for applications where the document must be accessed repeatedly or out of sequence order. If the application is strictly sequential and one-pass, the SAX model is likely to be faster and use less memory. In addition, non-extractive XML parsing models, such as VTD-XML, provide a new memory-efficient option.
[edit] Web browsers
A web browser is not obliged to use DOM in order to render an HTML document. However, the DOM is required by JavaScript scripts that wish to inspect or modify a web page dynamically. In other words, the Document Object Model is the way JavaScript sees its containing HTML page and browser state.
[edit] Implementations
Because DOM supports navigation in any direction (e.g., parent and previous sibling) and allows for arbitrary modifications, an implementation must at least buffer the document that has been read so far (or some parsed form of it).
[edit] Layout engines
Web browsers rely on layout engines to parse HTML into a DOM. Some layout engines such as Gecko or Trident/MSHTML are associated primarily or exclusively with a particular browser such as Firefox or Internet Explorer. Others, such as WebKit, are shared by a number of browsers, such as Safari and Google Chrome. The different layout engines implement the DOM standards to varying degrees of compliance.
[edit] Libraries
- JAXP (Java API for XML Processing)
- libxml2
- MSXML
- VTD-XML for building SOA intermediary applications
- Xerces
[edit] See also
- DOM scripting
- JDOM - a Java-based document object model for XML that integrates with DOM and SAX and uses parsers to build the document.
- SXML - a model for representing XML and HTML in the form of S-expressions.
- Ajax - a methodology employing DOM in combination with techniques for retrieving data without reloading a page.
- TinyXml - efficient platform-independent XML library for C++.
[edit] References
- Flanagan, David (2006). JavaScript: The Definitive Guide. O'Reilly & Associates. pp. 312-313. ISBN 0596101996.
- Koch, Peter-Paul (May 14, 2001). "The Document Object Model: an Introduction". Digital Web Magazine. http://www.digital-web.com/articles/the_document_object_model/. Retrieved on January 10, 2009.
- Le Hégaret, Philippe (2002). "The W3C Document Object Model (DOM)". World Wide Web Consortium. http://www.w3.org/2002/07/26-dom-article.html. Retrieved on January 10, 2009.
- Guisset, Fabian. "What does each DOM Level bring?". Mozilla Developer Center. Mozilla Project. http://developer.mozilla.org/en/docs/DOM_Levels. Retrieved on January 10, 2009.
[edit] External links
| Wikimedia Commons has media related to: Document object models |
- W3.org on DOM
- Technology Reports
- Tutorials
- What does your user agent claim to support?
- W3C DOM scripts and compatibility tables (Quirksmode)
- Gecko DOM Reference (Mozilla Developer Center)
- DOM Reference (Tellme)
- IB DOM Utilities: Mapping JavaScript Objects to DOM Elements
[edit] Specifications
- Document Object Model (DOM) Level 1 Specification
- Level 2 Recommendations:
- Document Object Model (DOM) Level 2 Core Specification
- Document Object Model (DOM) Level 2 Views Specification
- Document Object Model (DOM) Level 2 Events Specification
- Document Object Model (DOM) Level 2 Style Specification
- Document Object Model (DOM) Level 2 Traversal and Range Specification
- Document Object Model (DOM) Level 2 HTML Specification
- Level 3 Recommendations:
- Level 3 Working Group Notes:
- Working Draft
[edit] Bindings
- Ada
- C
- C++: Arabica, Xerces
- Common Lisp: XPublish, CL-XML, CXML
- Haskell
- Java - W3C Document Object Model Level 2
- Pascal (Kylix programming tool)
- Perl
- PHP
- Python
- Ruby
- TCL
]]>
Imagine the user of a web application, viewing details of Object1. The user wants to compare Object1 with Object2 so opens the details of Object2 in a second window or tab. If the application is storing the "current object id" in session state or a cookie then this value will now correspond to Object2. The user then decides to modify Object1's details, so amends them on the page and saves the changes.
If the application is really badly coded then the save operation could update the record corresponding to the current object id (Object2) with the new details for Object1. Even if it updates the right record, the current id in session state is still wrong - if this id is used to select the data for the next page that the user visits then they will end up with both tabs/windows pointing at Object2.
Processes
The problem stems from the fact that multiple tabs and windows can be running in the same process.
Firefox uses the same process for multiple tabs and, by default, the same process for all windows, whether they are launched from Windows or from each other (Ctrl-N style).
IE6 managed it's own processes so you could never be entirely certain about when further processes would be created unless you forced the situation using the -new command line switch. The most common situation I've found is that Ctrl-N creates a window using the existing process, Javascript calls (e.g. window.open, window.show...) use the existing process, but launching IE from Windows creates a new process.
IE7 has abandoned the -new switch, and seems to use a new process for each new window launched from Windows. All tabs within a window, however, run under one process, and spawning windows with Ctrl-N or Javascript commands seems to always re-use the existing process as well.
Cookies and Session State
Sharing a process isn't itself a bad thing. Time and resources can be saved by this approach, but unfortunately a browser's cookies are tied to it's process. If a page is displayed in two tabs or windows running in the same process, then the two instances of the page will share their cookies.
There are two types of cookie. Persistent cookies are saved to disk and kept until their expiry date. Persistent cookies will always be shared between multiple instances of the same page, regardless of whether the pages are running in the same browser process. If the page creates a persistent cookie called "ObjectID" then this will be stored in a file on disk and will be accessible to any other instance of that same page (unless you use a different browser application - IE and Firefox do not share cookies).
Session cookies, on the other hand, are kept in memory and are only available until the browser process ends. If two instances of a web application run in two separate processes then there will be two separate session cookies, but if the two instances are in the same process, then they will share the session cookie.
Furthermore, if the web application is relying on a session cookie to store a session id (the default setup for an ASP.NET web application is to store the ASP.NET_SessionId in a session cookie) then anything in session state will be shared between the two pages: if one of them updates session state then the other will be affected.
Options
What this means for a developer is that it is quite possible that your application will have to cope with multiple copies of the same page running in the same process, sharing cookies. Ideally you should be able to have each page running independently of the others, regardless of them sharing a process.
Normally you can work around the problem by using viewstate. Small objects can be stored directly in viewstate but you shouldn't be sending anything too big down the line to the browser. If your object is more than a simple integer or short string then it will probably be better to generate a GUID and store that in viewstate, using the GUID to access a part of sessionstate which can be kept unique for that instance of the page, regardless of the process-sharing.
In the example we began with, the current object id could easily be stored in viewstate. If there was an object that needed to be persisted for some reason then it would probably be better off in session state, so the second technique would be better.
There are times, however, when viewstate doesn't work. In some situations (for example, setting up dynamically generated controls) the current object id may be required in Page_Init, when viewstate is not available. This was actually the situation which lead to us developing an HTA-based intranet (each instance of an HTA has it's own process, so cookies and sessions are never shared), but HTA is not an option for a normal website.
Probably the best solution, if you're using ASP.NET, is cookieless sessions. In this situation the ASP.NET session id is part of the URL, and is not shared between tabs or windows. This solution works well in the Page_Init situation, but leads to some very unwieldy URLs and has other drawbacks connected to security and absolute linking. It is also an application (or machine) setting, so cannot be used as a last resort only for those few pages that need Page_Init.
Conclusion
In general, viewstate is the perfect solution to the problem. Each instance of a page can keep track of its own state, with no interference from other instances.
When state information is required in Page_Init things get a little more complicated and cookieless sessions are definitely worth considering.
Test Code
A simple page incrementing a counter in session state can be used to demonstrate the problem. Launching new windows with CTRL-N in either browser will default to using the existing process, as will all tabs.
Protected Sub Page_Load(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Load
Dim x As Integer
If IsNothing(Session("test")) Then
x = 1234
Else
x = CInt(Session("test")) + 1
End If
Session("test") = x
Label1.Text = CInt(Session("test"))
End Sub
forwarded by as follows:
http://www.cloudward.net/techLife/article.asp?id=1758
]]>