Stride is an important concept in digital image processing. It allows performing several operations with an image in a very fast manner (in constant time) by simple modification of image metadata. If you are interested in finding out what stride is and how to use it stick with us.
Pixel representation in a computer memory
Before we dive into the concept of stride we first need to revise how digital images are stored in a computer memory. We will start from a pixel.
An image pixel is represented in a computer memory by a fixed number of bits. Typical pixel bit depth (amount of bits per pixel) is 32, 16, 8 or, for binary images, 1 bit. In typical RGB images, 8 bits are often used to store the color value of a single channel. Thus, the total bit depth of one pixel is 24. Processing 32 and 16-bit chunks of data is simple and effective on a typical 32 and 64-bit processors. Therefore, the pixels are stored in the format of 32 bits, where the older (or younger, depending on the implementation) 8 bits remain unused. Such an approach to storing pixels requires more memory, but it allows speeding up image processing by using the standard size of the machine word. Thus, a standard RGB image occupies 32 bits in memory and has a depth of 24 bits. We will call another 8 bits necessary to supplement the size of the memory occupied by a pixel to the value of a multiple of degree 2, pixel padding. The total number of bytes occupied by a pixel in memory is called pixel stride (See Image 1).
Image representation in a computer memory
Images are stored in computer memory pixel-by-pixel, line by line. The upper left corner of the image is usually chosen as a coordinate origin (the upper left pixel of the image has the index [0, 0]). The image is stored in memory as a one-dimensional array. Pixels of the first line of the image are first written to the memory, then pixels of the second line and so on up to the last line. Each line in addition to the pixel bytes may also contain additional bytes — line padding. Additional bytes usually do not contain useful information and do not affect the visualization of an image when, for example, displayed on the screen. These additional bytes serve to complement a line, which is necessary for more efficient image processing and is caused by the specificity of the hardware used. For example, Cairo (a popular open source vector graphics software library) requires alignment of rows to multiple 4 bytes, which allows for more efficient image processing algorithms using vectorized processor operations and processing several image pixels simultaneously.
Introducing the term of line padding requires to introduce another closely coupled term — line stride.
Line stride (increment, pitch or step size) is the number of bytes that one needs to add to the address in the first pixel of a row in order to go to the address of the first pixel of the next row. It is important to note that an image width is measured in pixels and describes an image itself (and doesn’t depend on how an image is stored in a computer memory). In contrast, a line stride depends on how an image is represented in memory and is measured in bytes.
In program source code, an image is usually represented by a data structure containing metadata (image width and height, line stride, number of channels, encoding type, etc.), as well as a pointer to the address of the first image pixel in memory (further we will refer to this address as data_begin). This information allows us to unambiguously read and decode an image from memory, as well as to perform a series of fast image operations by changing only a metadata associated with an image.
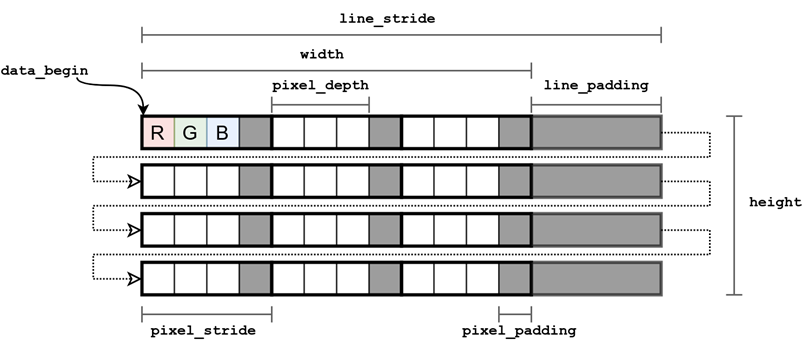
An image representation in a computer memory. Lines of an image are stored one by one in one-dimensional array.
Image operations:
Let’s summarize all the terms which we introduced to this moment:
pixel_address — a pixel address in memory
pixel depth —the number of bits per pixel (containing valuable information)
pixel_stride — the number of bytes occupied in memory by a pixel of an image
data_begin — the address of the first image pixel in memory
channels — the number of image channels (3 for an RGB-image)
channel_address — the address of a particular pixel channel in memory
height — the image height in pixels
width — the image width in pixels
line_stride — the number of bytes occupied in memory by a line of an image
Operations:
1. Computing pixel address in memory
The equation relating pixel memory address to its coordinates [y, x] in the image coordinate system can be represented as:
pixel_address = data_begin + y * line_stride + x * pixel_stride, (1)
where data_begin — the address of the first image pixel in memory.
Equation (1) is used whenever you access an image in memory. In the rest of operations, presented in this post, we will only change a metadata associated with an image and assume, that the equation (1) is applied after in order to access image.
2. Pixel decoding (for RGB image with an equal amount of bits per channel):
channel_address = pixel_address + n * depth / channels, (2)
where n is a channel index: n = 0, 1, …, channels — 1. Thus, for instance, for the typical RGB-image with an equal amount of bits per channel, a channel address in memory can be computed as follows:
R = pixel_address,
G = pixel_address + depth / channels,
B = pixel_address + 2 * depth / channels.
It is important to note that these equations depend on the type of the image stored. There are formats in which different number of bytes is used to store different channels.
3. Image flip
3.1 Vertical flip
data_begin = data_begin + (height- 1) * line_stride ,
line_stride = -line_stride.
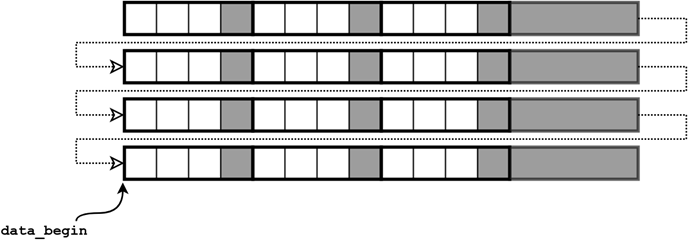
Pointer to the first image pixel for the vertical flip
The negative line stride being inserted into equation (1) allows us to move upwards reading (or visualizing) an image from the last row to the first, thus, realizing vertical flip.
3.2 Horizontal flip
data_begin = data_begin + (width — 1) * pixel_stride ,
pixel_stride = -pixel_stride.
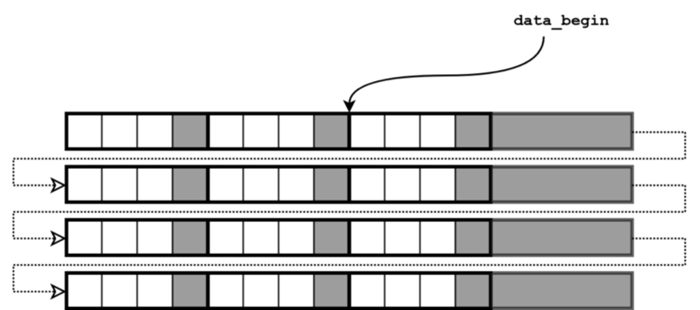
Pointer to the first image pixel for the horizontal flip
In the same manner as with negative line stride in the previous example, the negative pixel stride here allows us to move from right to left and to read (or visualize) an image flipped horizontally.
3.3 Vertical and horizontal flip
The combination of previous two approaches allows to flip an image in both directions at once:
data_begin = data_begin + (height-1) * line_stride + (width-1) * pixel_stride,
line_stride = -line_stride,
pixel_stride = -pixel_stride.
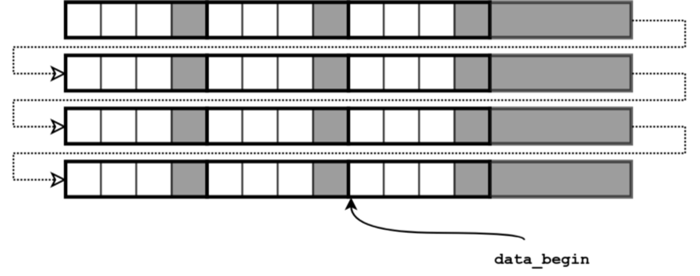
Pointer to the first image pixel for the simultaneous vertical and horizontal flip
4. Extracting image subwindow
data_begin = new_data_begin,
width = new_width,
height = new_height.
With this approach we set a new origin of our image (inside a boundary of the original image) and set a width and height which basically tell us how many time we should apply an equation (1) to read all pixels (width x height) and after which amount of pixels read we should increase the y coordinate (to start reading pixels of the next row). Note that such parameters as line stride remain unchanged.
5. Extracting single image channel
To extract a single image channel we can use a combination of equations (1) and (2):
pixel_address = data_begin + y * line_stride + x * pixel_stride + n * depth / channels,
where n — channel index, n = 0, 1, …, channels — 1.
REFERENCES
1. A programmer’s view on digital images: the essentials: https://www.collabora.com/news-and-blog/blog/2016/02/16/a-programmers-view-on-digital-images-the-essentials/
2. Microsoft Media Foundation Programming Guide: Image Stride:Image Stride When a video image is stored in memory, the memory buffer might contain extra padding bytes after each row of pixels…docs.microsoft.com
3. Wikipedia: Stride of an array: https://en.wikipedia.org/wiki/Stride_of_an_array
4. Cairo library: https://cairographics.org/
Raster Images


Vector Images


A PDF describes the content and appearance of one or more pages. It also contains a definition of the physical size of those pages. That page size definition is not as straightforward as you might think. There can in fact be up to 5 different definitions in a PDF that relate to the size of its pages. These are called the boundary boxes or page boxes:
· The MediaBox is used to specify the width and height of the page. For the average user, this probably equals the actual page size. For prepress use, this is not the case as we prefer our pages to be defined slightly oversized so that we can see the bleed (Images or other elements touching an outer edge of a printed page need to extend beyond the edge of the paper to compensate for inaccuracies in trimming the page), the crop marks and useful information such as the file name or the date and time when the file was created. This means that PDF files used in graphic arts usually have a MediaBox which is larger than the trimmed page size.
· The CropBox defines the region that the PDF viewer application is expected to display or print. So if a PDF contains a CropBox definition, Acrobat uses it for screen display and printing. For prepress use, the CropBox is pretty irrelevant. The GWG industry association recommends not to use it at all.
· The TrimBox defines the intended dimensions of the finished page. Contrary to the CropBox, the TrimBox is very important because it defines the actual page size that gets printed. The imposition programs and workflows that I know all use the TrimBox as the basis for positioning pages on a press sheet. By default the TrimBox equals the CropBox.
· The BleedBox determines the region to which the page contents needs to be clipped when output in a production environment. Usually the BleedBox is 3 to 5 millimeters larger than the TrimBox. It is nice to know the size of the BleedBox but it isn’t that important in graphic arts. Most prepress systems allow you to define the amount of bleed yourself and ignore the BleedBox. By default the BleedBox equals the CropBox.
· The ArtBox is a bit of a special case. It was originally added to indicate the area covered by the artwork of the page. It is never used for that but can be handy in a few cases:
· On a PDF page that contains an advertisement, the ArtBox can be used to define the location of that ad. This allows you to place that PDF on another page but only use the area covered by the advert.
· A more common use of the ArtBox is as a means to indicate the safety zone. When creating a poster that will be placed in a lightbox, the designer must make sure text and logo’s aren’t positioned too close to the edge. If the poster is not mounted properly, this could cause that text or logo to disappear behind the frame of the lightbox. In book design, there is also a margin where you cannot put text because the binding might make it difficult to read text that is too close to the spine. The area where it is safe to place graphic elements is called the safety zone or text safe area. The ArtBox can be used to indicate the dimensions of this part of the page.
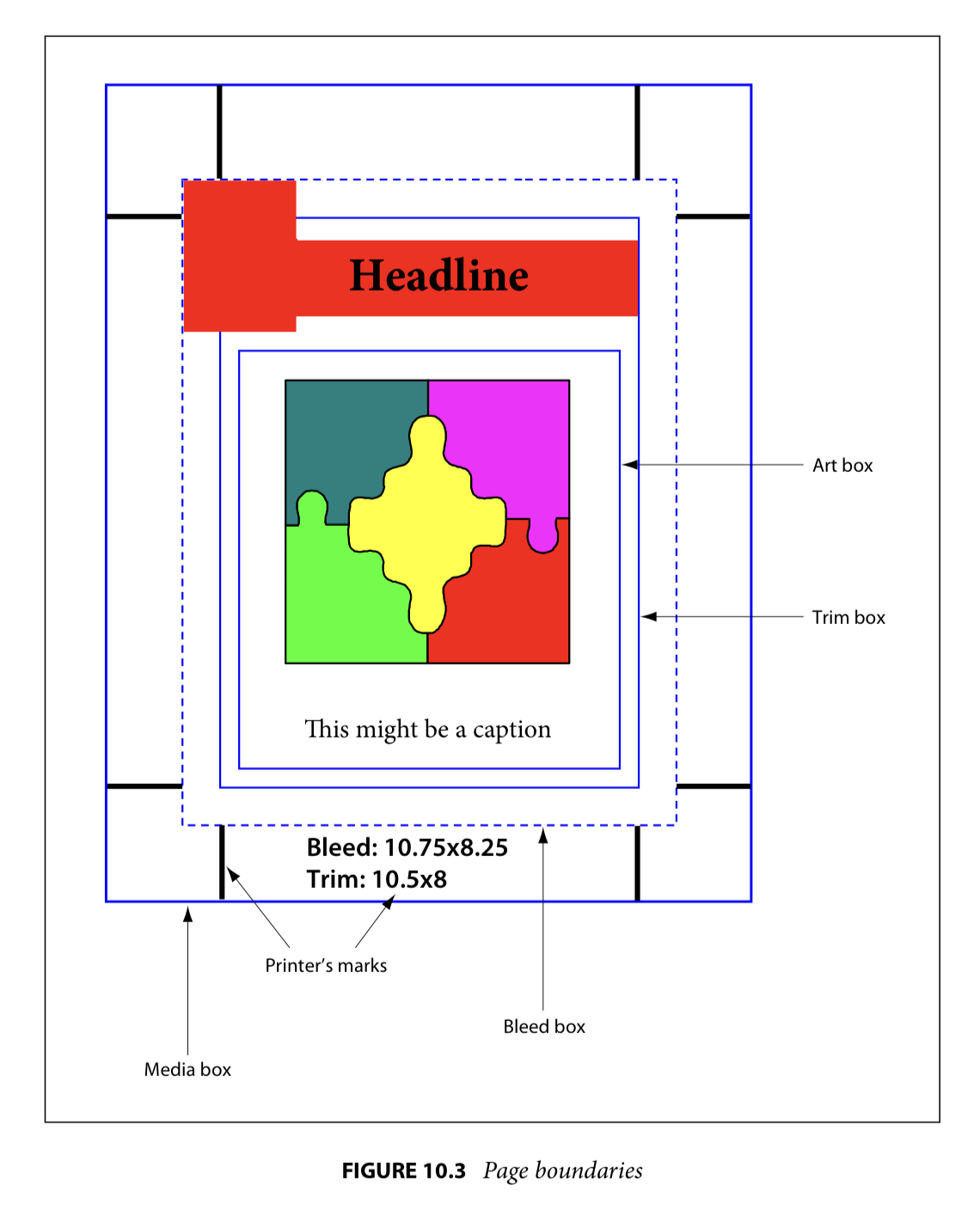
General rules regarding page boxes
· Each page in a PDF can have different sizes for the various page boxes.
· The page boxes are always rectangular. That may seem logical but artwork is not always rectangular: a PDF can represent an oval label or the foldout of a cardboard box.
· A PDF always has a MediaBox definition. All the other page boxes do not necessarily have to be present in regular PDF files.
· The above rule is not true for the PDF/X file formats:
· PDF/X-1a and PDF/X-3 compliant files need to include the MediaBox, TrimBox, and BleedBox.
· PDF/X-4 files need, next to the MediaBox, a TrimBox or an ArtBox, but not both. The ArtBox or TrimBox cannot be larger that the BleedBox. If a CropBox is present, the ArtBox, TrimBox, and BleedBox need to extend beyond its boundaries.
· The MediaBox is the largest page box in a PDF. The other page boxes can equal the size of the MediaBox but they are not expected to be larger (The latter is explicitly required in the PDF/X-4 requirements). If they are larger, the PDF viewer will use the values of the MediaBox.
BBox
Within PDF files there is another box, the bounding box or BBox, that is used. The bounding box is a rectangular frame that determines the dimensions of an object (such as a graphic, font or pattern) that is placed inside a PDF document. As such, this box has nothing to do with the page boxes.
Architectures
Please send updates/corrections to predef-contribute.
Alpha
| Type | Macro | Description |
|---|---|---|
| Identification | __alpha__ | Defined by GNU C |
| Version | __alpha_ev'V'__ | V = Version |
| Identification | __alpha | Defined by DEC C |
| Identification | _M_ALPHA | Defined by Visual Studio |
Example
| CPU | Macro |
|---|---|
| Alpha EV4 | __alpha_ev4__ |
| Alpha EV5 | __alpha_ev5__ |
| Alpha EV6 | __alpha_ev6__ |
AMD64
| Type | Macro | Description |
|---|---|---|
| Identification | __amd64____amd64__x86_64____x86_64 | Defined by GNU C and Sun Studio |
| Identification | _M_X64_M_AMD64 | Defined by Visual Studio |
Notice that x32 can be detected by checking if the CPU uses the ILP32 data model.
ARM
| Type | Macro | Description |
|---|---|---|
| Identification | __arm__ | Defined by GNU C and RealView |
| Identification | __thumb__ | Defined by GNU C and RealView in Thumb mode |
| Version | __ARM_ARCH_'V'__ | V = Version Defined by GNU C 1 |
| Identification | __TARGET_ARCH_ARM__TARGET_ARCH_THUMB | Defined by RealView |
| Version | __TARGET_ARCH_ARM = V__TARGET_ARCH_THUMB = V | V = Version |
| Version | __TARGET_ARCH_'VR' | VR = Version and Revision |
| Identification | _ARM | Defined by ImageCraft C |
| Identification | _M_ARM | Defined by Visual Studio |
| Identification | _M_ARMT | Defined by Visual Studio in Thumb mode |
| Version | _M_ARM = V | V = Version |
| Identification | __arm | Defined by Diab |
Example
| CPU | Macro | _M_ARM |
|---|---|---|
| ARM 2 | __ARM_ARCH_2__ | |
| ARM 3 | __ARM_ARCH_3____ARM_ARCH_3M__ | |
| ARM 4T | __ARM_ARCH_4T____TARGET_ARM_4T | |
| ARM 5 | __ARM_ARCH_5____ARM_ARCH_5E__ | 5 |
| ARM 5T | __ARM_ARCH_5T____ARM_ARCH_5TE____ARM_ARCH_5TEJ__ | |
| ARM 6 | __ARM_ARCH_6____ARM_ARCH_6J____ARM_ARCH_6K____ARM_ARCH_6Z____ARM_ARCH_6ZK__ | 6 |
| ARM 6T2 | __ARM_ARCH_6T2__ | |
| ARM 7 | __ARM_ARCH_7____ARM_ARCH_7A____ARM_ARCH_7R____ARM_ARCH_7M____ARM_ARCH_7S__ | 7 |
ARM64
| Type | Macro | Description |
|---|---|---|
| Identification | __aarch64__ | Defined by GNU C 1 |
Blackfin
| Type | Macro | Description |
|---|---|---|
| Identification | __bfin__BFIN__ | Defined by GNU C |
Convex
| Type | Macro | Description |
|---|---|---|
| Identification | __convex__ | Defined by GNU C |
| Version | __convex_'V'__ | V = Version |
Example
| CPU | Macro |
|---|---|
| Convex C1 | __convex_c1__ |
| Convex C2 | __convex_c2__ |
| Convex C32xx series | __convex_c32__ |
| Convex C34xx series | __convex_c34__ |
| Convex C38xx series | __convex_c38__ |
Epiphany
| Type | Macro | |
|---|---|---|
| Identification | __epiphany__ |
HP/PA RISC
| Type | Macro | Description |
|---|---|---|
| Identification | __hppa__ | Defined by GNU C |
| Identification | __HPPA__ | Defined by Stratus VOS C |
| Identification | __hppa | |
| Version | _PA_RISC'V'_'R' | V = Version R = Revision |
See also OpenPA.net.
Example
| CPU | Macro |
|---|---|
| PA RISC 1.0 | _PA_RISC1_0 |
| PA RISC 1.1 | _PA_RISC1_1__HPPA11____PA7100__ |
| PA RISC 2.0 | _PA_RISC2_0__RISC2_0____HPPA20____PA8000__ |
Intel x86
| Type | Macro | Format | Description |
|---|---|---|---|
| Identification | i386__i386__i386__ | Defined by GNU C | |
| Version | __i386____i486____i586____i686__ | Defined by GNU C | |
| Identification | __i386 | Defined by Sun Studio | |
| Identification | __i386__IA32__ | Defined by Stratus VOS C | |
| Identification | _M_I86 | Only defined for 16-bits architectures Defined by Visual Studio, Digital Mars, and Watcom C/C++ (see note below) | |
| Identification | _M_IX86 | Only defined for 32-bits architectures Defined by Visual Studio, Intel C/C++, Digital Mars, and Watcom C/C++ | |
| Version | _M_IX86 | V00 | V = Version |
| Identification | __X86__ | Defined by Watcom C/C++ | |
| Identification | _X86_ | Defined by MinGW32 | |
| Identification | __THW_INTEL__ | Defined by XL C/C++ | |
| Identification | __I86__ | Defined by Digital Mars | |
| Version | __I86__ | V | V = Version |
| Identification | __INTEL__ | Defined by CodeWarrior | |
| Identification | __386 | Defined by Diab |
Notice that Watcom C/C++ defines _M_IX86 for both 16-bits and 32-bits architectures. Use __386__ or _M_I386 to detect 32-bits architectures in this case.
Notice that the Stratus VOS is big-endian on IA32, so these macros cannot be used to detect endianness if __VOS__ is set.
Example
| CPU | _M_IX86 | __I86__ |
|---|---|---|
| 80386 | 300 | 3 |
| 80486 | 400 | 4 |
| Pentium | 500 | 5 |
| Pentium Pro/II | 600 | 6 |
Intel Itanium (IA-64)
| Type | Macro | Format | Description |
|---|---|---|---|
| Identification | __ia64___IA64__IA64__ | Defined by GNU C | |
| Identification | __ia64 | Defined by HP aCC | |
| Identification | _M_IA64 | Defined by Visual Studio | |
| Identification | _M_IA64 | Defined by Intel C/C++ | |
| Version | _M_IA64 | ? | |
| Identification | __itanium__ | Defined by Intel C/C++ |
Example
| CPU | _M_IA64 (Intel C/C++) |
|---|---|
| 64100 |
Motorola 68k
| Type | Macro | Description |
|---|---|---|
| Identification | __m68k__ | Defined by GNU C |
| Version | __mc'V'____mc'V'mc'V' | V = Version |
| Identification | M68000 | Defined by SAS/C |
| Identification | __MC68K__ | Defined by Stratus VOS C |
| Version | __MC'V'__ | V = Version |
Example
| CPU | Macro |
|---|---|
| 68000 | __mc68000____MC68000__ |
| 68010 | __mc68010__ |
| 68020 | __mc68020____MC68020__ |
| 68030 | __mc68030____MC68030__ |
| 68040 | __mc68040__ |
| 68060 | __mc68060__ |
MIPS
| Type | Macro | Description |
|---|---|---|
| Identification | __mips__mips | Defined by GNU C |
| Version | _MIPS_ISA = _MIPS_ISA_MIPS'V' | V = MIPS ISA level |
| Version | _R3000_R4000_R5900 | |
| Identification | __mips | Defined by MIPSpro and GNU C |
| Version | __mips | The value indicates the MIPS ISA (Instruction Set Architecture) level |
| Version | __MIPS_ISA'V'__ | V = MIPS ISA level |
| Identification | __MIPS__ | Defined by Metrowerks |
Example
| CPU | _MIPS_ISA | GNU C Macro | __mips | MIPSpro Macro |
|---|---|---|---|---|
| R2000 | _MIPS_ISA_MIPS1 | 1 | ||
| R3000 | _MIPS_ISA_MIPS1 | _R3000 | 1 | |
| R6000 | _MIPS_ISA_MIPS2 | 2 | __MIPS_ISA2__ | |
| R4000 | _R4000 | |||
| R4400 | _MIPS_ISA_MIPS3 | 3 | __MIPS_ISA3__ | |
| R8000 | _MIPS_ISA_MIPS4 | 4 | __MIPS_ISA4__ | |
| R10000 | _MIPS_ISA_MIPS4 | 4 | __MIPS_ISA4__ |
PowerPC
| Type | Macro | Description |
|---|---|---|
| Identification | __powerpc__powerpc____powerpc64____POWERPC____ppc____ppc64____PPC____PPC64___ARCH_PPC_ARCH_PPC64 | Defined by GNU C |
| Version | __ppc'V'__ | V = Version |
| Identification | _M_PPC | Defined by Visual Studio |
| Version | _M_PPC | ? |
| Identification | _ARCH_PPC_ARCH_PPC64 | Defined by XL C/C++ |
| Version | _ARCH_'V' | V = Version |
| Version | __PPCGECKO__ | Gekko Defined by CodeWarrior |
| Version | __PPCBROADWAY__ | Broadway Defined by CodeWarrior |
| Version | _XENON | Xenon |
| Identification | __ppc | Defined by Diab |
Example
| CPU | _M_PPC | Macro | XL Macro |
|---|---|---|---|
| PowerPC 440 | _ARCH_440 | ||
| PowerPC 450 | _ARCH_450 | ||
| PowerPC 601 | 601 | __ppc601__ | _ARCH_601 |
| PowerPC 603 | 603 | __ppc603__ | _ARCH_603 |
| PowerPC 604 | 604 | __ppc604__ | _ARCH_604 |
| PowerPC 620 | 620 |
Pyramid 9810
| Type | Macro |
|---|---|
| Identification | pyr |
RS/6000
| Type | Macro | Description |
|---|---|---|
| Identification | __THW_RS6000 | Defined by XL C/C++ |
| Identification | _IBMR2 | |
| Identification | _POWER | |
| Identification | _ARCH_PWR_ARCH_PWR2_ARCH_PWR3_ARCH_PWR4 |
SPARC
| Type | Macro | Description |
|---|---|---|
| Identification | __sparc__ | Defined by GNU C |
| Identification | __sparc | Defined by Sun Studio |
| Version | __sparc_v8____sparc_v9__ | Defined by GNU C |
| Version | __sparcv8__sparcv9 | Defined by Sun Studio |
Example
| CPU | Sun Studio Macro | GNU C Macro |
|---|---|---|
| SPARC v8 (SuperSPARC) | __sparcv8 | __sparc_v8__ |
| SPARC v9 (UltraSPARC) | __sparcv9 | __sparc_v9__ |
SuperH
| Type | Macro | Description |
|---|---|---|
| Identification | __sh__ | Defined by GNU C |
| Version | __sh1____sh2____sh3____SH3____SH4____SH5__ |
SystemZ
| Type | Macro | Description |
|---|---|---|
| Identification | __370____THW_370__ | Identifies System/370 Defined by XL C/C++ |
| Identification | __s390__ | Identifies System/390 Defined by GNU C |
| Identification | __s390x__ | Identifies z/Architecture Defined by GNU C |
| Identification | __zarch__ | Identifies z/Architecture Defined by clang |
| Identification | __SYSC_ZARCH__ | Identifies z/Architecture Defined by Systems/C |
TMS320
| Type | Macro | Description |
|---|---|---|
| Identification | _TMS320C2XX__TMS320C2000__ | C2000 series |
| Identification | _TMS320C5X__TMS320C55X__ | C5000 series |
| Identification | _TMS320C6X__TMS320C6X__ | C6000 series |
Example
| DSP | Macro |
|---|---|
| C28xx | _TMS320C28X |
| C54x | _TMS320C5XX |
| C55x | __TMS320C55X__ |
| C6200 | _TMS320C6200 |
| C6400 | _TMS320C6400 |
| C6400+ | _TMS320C6400_PLUS |
| C6600 | _TMS320C6600 |
| C6700 | _TMS320C6700 |
| C6700+ | _TMS320C6700_PLUS |
| C6740 | _TMS320C6740 |
TMS470
| Type | Macro |
|---|---|
| Identification | __TMS470__ |
Someone gives you a bug. "The light in the conference room on the 26th floor is on. It needs to be off."
A note on the bug says, “This will take you like 5 minutes. It's just flipping a switch."
You go to the conference room on 26. The light is on, but there's no light switch in the room.
So you prepare to install one. But the designer says it would ruin the room’s aesthetic. Plus, the walls are concrete. With the proper tools, you could install the switch. But no one will approve the purchase of the proper tools. Without the proper tools it will take two days. And they want it done now, because they're afraid that any minute the CEO might decide to go to the 26th floor and happen to walk by the conference room and ask why the hell that light is on.
And now you're getting emails asking why the light isn't off yet.
So now you have to stop and send a group email to explain the situation, and several people start up a panicked email chain.
You know if you wait for the problem to be resolved by anyone discussing it in the email chain, it won’t get fixed. The bug has your name on it, and it's dated today, so you're the one in trouble if it isn't resolved. So you go up into the hallway ceiling on 26, find the wires leading to the light, cut and cap them. Finally. Problem solved.
In order to quell the panic in the email thread, you report back how you solved the issue.
You don’t hear anything for a while. When you do, everyone is concerned that now the light can’t be turned on and off. What if the CEO wants to have a meeting in there? So here’s what they ask you to do: They want you to run wires from the light down into the basement. When someone needs the light to be on or off, they’ll contact you, and have you run to the basement and either connect or disconnect the wires.
You protest the ridiculousness of this solution. Your boss says, “Yeah, I know it’s not ideal. But it’s the only solution we have right now."
At this point you realize you have a choice. You could do this. Or you could quit in protest, and find another job. But you realize that once you start that new job, they’re likely to ask you to do something just as idiotic, if not more so.
So you go run the wires from floor 26 down to the basement. When you get to the basement, you see dozens of wires hanging out of the walls, from all the people who have had to do this exact same thing before. (So that’s where the idea came from.) You set up the wires and label them as best you can, with a short apology to whoever has to deal with this next.
When you get back to your desk, you have a message. QA has reopened the bug. It says, “I see light."
You head back up to the conference room on 26. The light is off. You go back to your desk and close the bug, reporting that you checked on it in person.
QA reopens the bug again. “Room still lit” it says. After looking at the unlit bulb one more time, you tell your boss, who suggests you go back down to the basement and check the wires. You protest that you are looking at the light right now and it’s off. “I know, but this way you can tell QA you checked out absolutely everything."
So you sigh and head to the basement. Sure enough, the wires are not connected. The ends are capped. They are not resting on anything that could conduct electricity.
You report back to QA that you checked the wires, which are not connected, and that you looked at the bulb, which was unlit.
“I didn’t mean the bulb,” says QA. “The bug is about light in the room. There’s still too much light. Shouldn’t you close the blinds?"
You respond that the blinds don’t fall under your control, and that the bug specifies the light being turned off.
Not believing you, QA sends out a group email asking if the blinds are covered by the bug.
Some time passes before you hear from anyone. Finally someone from the email chain calls you.
“Theoretically,” they ask, “could someone participating in a meeting in the conference room on 26 open or close the blinds by themselves if it was too bright or too dark?"
Yes they could, you reply.
“Like, an ordinary person? They wouldn’t need you to do it?"
Yes, an ordinary person. No, they wouldn’t need you. Anyone can do it.
“Great. Excellent. Then we’ll leave that for now. I’ll schedule a stand-up meeting about the blinds issue."
So the bug is closed. Now, the CEO, possibly having caught wind of all the discussion and furtive activity surrounding the conference room on 26, wants to have a meeting there. You get several panicked emails that they need the light on.
You go to the basement, connect the wires, and return to your desk, to find 32 new messages in your inbox. “Something’s wrong—the light’s not on!” “There’s a problem — no light!” “Are you getting these emails?” and so on.
The 32nd email says, “Nevermind—the light’s on."
This process is repeated more or less exactly when it’s time to turn the light off again.
But if there’s any good news, it’s this: after the meeting, everyone forgets that there even is a conference room on 26, so you never have to do anything about it again.
Wow, gold! Thanks!
2
3 #if (defined _WIN64 || defined __x86_64__)
4
5 /**
6 * ../bit_scan_forward
7 * @return index (0..63) of least significant one bit
8 */
9 unsigned bit_scan_forward(unsigned long long x)
10 {
11 asm("bsfq %0, %0" : "=r" (x) : "0" (x));
12 return unsigned(x);
13 }
14
15 /**
16 * bit_scan_reverse
17 * @return index (0..63) of most significant one bit
18 */
19 unsigned bit_scan_reverse(unsigned long long x)
20 {
21 asm("bsrq %0, %0" : "=r" (x) : "0" (x));
22 return unsigned(x);
23 }
24
25 #elif (defined _WIN32) || (defined __linux__)
26
27 /**
28 * ../bit_scan_forward
29 * @return index (0..63) of least significant one bit
30 */
31 unsigned bit_scan_forward(unsigned long long x)
32 {
33 asm("bsf %0, %0" : "=r" (x) : "0" (x));
34 return unsigned(x);
35 }
36
37 /**
38 * bit_scan_reverse
39 * @return index (0..63) of most significant one bit
40 */
41 unsigned bit_scan_reverse(unsigned long long x)
42 {
43 asm("bsr %0, %0" : "=r" (x) : "0" (x));
44 return unsigned(x);
45 }
46
47 #endif
48
49 #endif
д»ҠеӨ©зңӢиҖҒеӨ–еҶҷзҡ„ж–Үз« жҸҗеҲ°дә?/span>C#еӣҪйҷ…ж ҮеҮҶ…
д»Җд№ҲпјҢC#ҳqҳжңүеӣҪйҷ…ж ҮеҮҶеQҹдёҚдјҡеҗ§еQҹи°·жӯҢдёҖдёӢпјҢжһң然еҰӮжӯӨеQ?/span>06тqҙе°ұжңүдәҶISOж ҮеҮҶ…еұ…然ҳqҳиғҪд»?/span>ISOе®ҳзҪ‘дёӢиқІеҲ°з”өеӯҗзүҲгҖ?/span>
зңӢжқҘйҮ‘й’ұһ®ұжҳҜеҘҪдёңиҘҝе•ҠеQҢжңүй’ЮpғҪдҪүK¬јжҺЁзЈЁйҒ“зҗҶеңЁең°зҗғдёҠе“ӘйҮҢйғҪеҘҪз”?/span>…
ҫl§з®Ӣи°дhӯҢеQҢеңЁMSDNдёҠеҸ‘зҺоCәҶдёӢйқўзҡ„ж–Үеӯ—гҖ?/span>
ҳqһжҺҘеQ?/span>http://msdn.microsoft.com/en-us/netframework/aa569283
In June 2005, the General Assembly of the international standardization organization Ecma approved edition 3 of the C# Language and the Common Language Infrastructure (CLI) specifications, as updated Ecma-334 and Ecma-335, respectively (see press release). The updated technical report on the CLI, Ecma TR-84, and a new technical report on the CLI, Ecma TR-89, were also ratified.
In July 2005, Ecma submitted the Standards and TRs to ISO/IEC JTC 1 via the ISO Fast-Track process. The Standards were adopted in April 2006 as ISO/IEC 23270:2006 (C#), ISO/IEC 23270:2006 (CLI), ISO/IEC TR 23272:2006 (CLI, XML Libraries) and ISO ISO/IEC TR 25438:2006 (CLI, Common Generics).
In July 2006 the General Assembly of Ecma approved edition 4 of the Standards which correspond to the ISO 2006 versions.
Latest Standards
The following official Ecma documents are available for C# and the CLI (TR-84, TR-89). These links are direct from Ecma:
|
| File name |
| Size (Bytes) |
| Content |
|
|
| 2 614 003 |
| C# Language Specification | |
|
|
| 3 219 107 |
| Common Language Infrastructure | |
|
|
| 754 982 |
| XML-based Library Specification | |
|
|
| 187 450 |
| Information Derived from Partition IV XML File | |
|
|
| 19 329 610 |
| XML Tool, Libraries in Microsoft© Word and PDF | |
|
|
| 589 400 |
| Common Generics Library | |
|
|
| 461 074 |
| Common Generics Library Reference Implementation |
Reference implementation for TR-89
Reference implementation for the Parallel API
The official ISO/IEC documents are available from the ISO/IEC Freely Available Standards page. These links are direct from that page:
|
| File name |
| Content |
|
|
| Information technology -- Programming languages -- C# | |
|
|
| Information technology -- Common Language Infrastructure (CLI) | |
|
| ISO/IEC TR 23272:2006 |
| Information technology -- Common Language Infrastructure (CLI) |
|
|
| Information technology -- Common Language Infrastructure (CLI) |
Current Working Draft
Work on the 5th edition of Ecma-335 CLI standard began in mid-2009. The TC49-TG3 task group is working on extending both the virtual machine and class libraries of the CLI specification. In addition, improvements are being made to clarify existing elements of the specification. Many of these improvements are the result of feedback received from outside the task group, for which the task group is grateful.
Posted below is a snapshot of the committee's work as of 27 March 2010.
The participants in TC49/TG3 are providing these working documents to the public for informational purposes only. The contents are subject to change as often as once a month. To participate in the standardization process, contact your organization's Ecma representative. If your company does not currently participate in Ecma and wishes to do so, please contact ECMA directly.
The following organizations and contributors are actively participating in the work of TC49/TG3:
Eiffel Software, Microsoft Corporation, Novell Corporation, Kahu Research, and Twin Roots.
Many of the organizations that are currently participating in the TC49/TG3 work have volunteered to mirror this site. The URLs for the mirror sites are:
- Eiffel Software
- Microsoft Corporation
- Novell Corporation
- Kahu Research
- Twin Roots
Available Documents (Documents current as of 27 March 2010)
The following working draft documents are available:
- CLI Partition I - Architecture (word/pdf zip)
- CLI Partition II - Metadata and File Format (word/pdf zip)
- CLI Partition III - CIL (word/pdf zip)
- CLI Partition IV - Library (word/pdf zip)
- CLI Partition V - Binary Formats (word/pdf zip)
- CLI Partition VI - Annexes (word/pdf zip)
- Class Library XML (xml zip)
- Class Library Detailed Specifications (word/pdf zip)
Annotated Standards
Members of the Standard committees and others have combined to produce annotated versions of the Standards. These are:
- The Common Language Infrastructure Annotated Standard, James S. Miller & Susann Ragsdale, Addison-Wesley, 2004, ISBN 0-321-15493-2 (based on Edition 2 of Ecma-335)
- C# Annotated Standard, Jon Jagger, Nigel Perry & Peter Sestoft, Morgan Kaufmann, 2007, ISBN 978-0-12-372511-0 (based on Edition 4 of Ecma-334)
Microsoft Implementation Specific Versions
The following documents are versions of the Standards with Microsoft implementation-specific notes added. These notes provide extra information about Microsoft's Common Language Runtime (CLR) implementation of the CLI.
|
| File name |
| Size (Bytes) |
| Content |
|
|
| 815 983 |
| Common Language Infrastructure, Partition I: Concepts and Architecture | |
|
|
| 1 758 195 |
| Common Language Infrastructure, Partition II: Metadata Definition and Semantics | |
|
|
| 661 414 |
| Common Language Infrastructure, Partition III: CIL Instruction Set | |
|
|
|
|
| Common Language Infrastructure, Partition IV: Profiles and Libraries | |
|
|
|
|
| Common Language Infrastructure, Partition V: Binary Formats | |
|
|
|
|
| Common Language Infrastructure, Partition VI: Annexes |
The Ecma 4th and ISO 2nd Editions
Aside from bug fixes, major enhancements from previous editions include:
CLI
- First-class support for generics at the runtime and class library level
- An API to help developers begin multithreaded and parallel programming
- Enhancements to the Common Intermediate Language (CIL) and Common Language Specification (CLS)
- An interchangeable debug format
C#
- First-class language support for generics
- Anonymous methods
- Iterators
- Nullable Types
Previous Editions Background
In August, 2000, Microsoft Corporation, Hewlett-Packard and Intel Corporation co-sponsored the submission of specifications for the Common Language Infrastructure (CLI) and C# programming language to the international standardization organization Ecma. As a result, Ecma formed two task groups (TG3 and TG2, respectively) within TC39, its technical committee responsible for programming languages and application development.
During the next year, the co-sponsor companies, in conjunction with other Ecma members and guests (including IBM, Fujitsu Software, Plum Hall, Monash University and ISE), refined these specifications into standards. In December, 2001, the Ecma General Assembly ratified the 1st edition of the C# and CLI standards as Ecma-334 and Ecma-335, respectively. A technical report on the CLI, Ecma TR-84, was also ratified.
In late December, 2001, Ecma submitted the standards and TR to ISO/IEC JTC 1 via the latter's Fast-Track process. The subsequent 6-month evaluation and comment period resulted in two NO votes (Japan and UK) on the draft standards, and one NO vote (Japan) on the draft TR. All comments resulting from this review were considered at a ballot resolution meeting held in October, 2002. The two NO votes on the standards were resolved, making acceptance unanimous. However, Japan did not change its NO vote on the draft TR (Japan would like to see a formatted/readable rendering of the CLI class library as part of the standard, not as a TR; this will be considered for a future edition).
The ISO/IEC standards and TR were published in April, 2003, and are known formally as ISO/IEC 23270 (C#), ISO/IEC 23271 (CLI) and ISO/IEC 23272 (CLI TR). Equivalent specifications were adopted as 2nd edition standards and TR by Ecma at its December, 2002, General Assembly.
Joining Ecma
To participate in the standardization process, contact your organization’s Ecma representative. If your company does not currently participate in Ecma and wishes to do so, please contact Ecma directly.
Acknowledgements
The following organizations have participated in the work of Ecma TC39/TG2 and TC39/TG3 and their contributions are gratefully acknowledged: Borland, Fujitsu, Hewlett-Packard, Intel Corporation, International Business Machines, ISE, IT University Copenhagen, JSL (UK), Kahu Research (New Zealand), Microsoft Corporation, Monash University, Netscape, Novell Corporation, OpenWave, Plum Hall, Sun Microsystems.
Many of the organizations that have participated in the TC39/TG2 and TC39/TG3 work have volunteered to mirror this site. The links for the mirror sites are:
- Intel Corporation
- ISE (Eiffel)
- IT University, Copenhagen
- Kahu Research, New Zealand
- Microsoft Corporation
- Novell (Mono)
иҪ¬и„“еQҢе·ІҫlҸи®°дёҚжё…еҮәеӨ„еQҢжҠұжӯүгҖ?/p>
1гҖҒе„ҝж—УһјҢһ®Ҹз”·еӯ©е®¶еҫҲз©·еQҢеҗғйҘӯж—¶еQҢйҘӯеёёеёёдёҚеӨҹеҗғпјҢжҜҚдәІһ®ұжҠҠиҮӘе·ұј„—йҮҢзҡ„йҘӯеҲҶз»ҷеӯ©еӯҗеҗғгҖӮжҜҚдәІиҜҙеQҢеӯ©еӯҗ们еQҢеҝ«еҗғеҗ§еQҢжҲ‘дёҚйҘҝеQ?#8212;—жҜҚдәІж’’зҡ„ҪW¬дёҖдёӘи°Һ
гҖҖгҖҖ
2гҖҒз”·еӯ©й•ҝнw«дҪ“зҡ„ж—¶еҖҷпјҢеӢӨеҠізҡ„жҜҚдәІеёёз”Ёе‘Ёж—Ҙдј‘жҒҜж—¶й—ҙеҺ»еҺүKғҠеҶңжқ‘жІПxІҹйҮҢжҚһдәӣйұјжқҘз»ҷеӯ©еӯҗ们иЎҘй’ҷгҖӮйұј еҫҲеҘҪеҗғпјҢйұјжұӨд№ҹеҫҲйІңгҖӮеӯ©еӯҗ们еҗғйұјзҡ„ж—¶еҖҷпјҢжҜҚдәІһ®ұеңЁдёҖж—Ғе•ғйұјйӘЁеӨЯ_јҢз”ЁиҲҢеӨҙиҲ”йұјйӘЁеӨҙдёҠзҡ„иӮүжёҚгҖӮз”·еӯ©еҝғз–ы|јҢһ®ұжҠҠиҮӘе·ұј„—йҮҢзҡ„йұјеӨ№еҲ°жҜҚдәІј„—йҮҢеQҢиҜ·жҜҚдәІеҗғйұјгҖӮжҜҚдәІдёҚ еҗғпјҢжҜҚдәІеҸҲз”ЁҪ{·еӯҗжҠҠйұјеӨ№еӣһз”·еӯ©зҡ„зў—йҮҢгҖӮжҜҚдәІиҜҙеQҢеӯ©еӯҗпјҢеҝ«еҗғеҗ§пјҢжҲ‘дёҚзҲұеҗғйұы|јҒ——жҜҚдәІж’’зҡ„ҪW¬дәҢдёӘи°Һ
гҖҖгҖҖ
3гҖҒдёҠеҲқдёӯдәҶпјҢдёЮZәҶҫ~ҙеӨҹз”·еӯ©е’Ңе“Ҙе§җзҡ„еӯҰиҙ№еQҢеҪ“ҫ~қзнnе·Ҙзҡ„жҜҚдәІһ®ұеҺ»еұ…委дјҡйўҶдәӣзҒ«жҹҙзӣ’жӢҝеӣһ家жқҘеQҢжҷҡдё?ҫpҠдәҶжҢЈзӮ№еҲҶеҲҶй’ЮpЎҘзӮ№е®¶з”ЁгҖӮжңүдёӘеҶ¬еӨ©пјҢз”·еӯ©еҚҠеӨңйҶ’жқҘеQҢзңӢеҲ°жҜҚдәІиҝҳнw¬зқҖнw«еӯҗеңЁжСaзҒҜдёӢҫpҠзҒ«жҹҙзӣ’гҖӮз”·еӯ©иҜҙеQҢжҜҚдәФҢјҢзқЎдәҶеҗ§пјҢжҳҺж—©жӮЁиҝҳиҰҒдёҠзҸӯе‘ўгҖӮжҜҚдәІз¬‘ҪW‘пјҢиҜЯ_јҢеӯ©еӯҗеQ?еҝ«зқЎеҗ§пјҢжҲ‘дёҚеӣҺНјҒ——жҜҚдәІж’’зҡ„ҪW¬дёүдёӘи°Һ
гҖҖгҖҖ
4гҖҒй«ҳиҖғйӮЈтqЯ_јҢжҜҚдәІиҜ·дәҶеҒҮеӨ©еӨ©з«ҷеңЁиҖғзӮ№й—ЁеҸЈдёәеҸӮеҠ й«ҳиҖғзҡ„з”·еӯ©еҠ©йҳөгҖӮж—¶йҖўзӣӣеӨҸпјҢзғҲж—ҘеҪ“еӨҙеQҢеӣәжү§зҡ„ жҜҚдәІеңЁзғҲж—ҘдёӢдёҖз«ҷе°ұжҳҜеҮ дёӘе°Ҹж—¶гҖӮиҖғиҜ•ҫl“жқҹзҡ„й“ғеЈ°е“ҚдәҶпјҢжҜҚдәІҳqҺдёҠеҺ»йҖ’иҝҮдёҖжқҜз”Ёҫ|җеӨҙ瓶жҲцеҘҪзҡ„Ӣ№“иҢ¶еҸ®еҳұеӯ©еӯҗе–қдәҶеQҢиҢ¶дәҰжө“еQҢжғ…жӣҙжө“гҖӮжңӣзқҖжҜҚдәІтqІиЈӮзҡ„еҳҙе”Үе’Ңж»ЎеӨҙзҡ„жұ— зҸ пјҢз”·еӯ©һ®ҶжүӢдёӯзҡ„ҫ|җеӨҙ瓶еҸҚйҖ’иҝҮеҺ»иҜ·жҜҚдәІе–қгҖӮжҜҚдәІиҜҙеQҢеӯ©еӯҗпјҢеҝ«е–қеҗ§пјҢжҲ‘дёҚжёЯ_јҒ——жҜҚдәІж’’зҡ„еӣӣдёӘи°?
гҖҖгҖҖ
5гҖҒзҲ¶дәІз—…йҖқд№ӢеҗҺпјҢжҜҚдәІеҸҲеҪ“зҲ№еҸҲеҪ“еЁҳеQҢйқ зқҖиҮӘе·ұеңЁзјқҫU«зӨҫйҮҢйӮЈзӮ№еҫ®и–„收е…Ҙеҗ«иҫӣиҢ№иӢҰжӢүжүҜзқҖеҮ дёӘеӯ?еӯҗпјҢдҫӣ他们еҝөд№ҰпјҢж—ҘеӯҗҳqҮеҫ—иӢҰдёҚе ӘиЁҖгҖӮиғЎеҗҢиө\еҸЈз”өҫUҝжқҶдёӢдҝ®иЎЁзҡ„жқҺеҸ”еҸ”зҹҘйҒ“еҗҺеQҢеӨ§дәӢе°ҸдәӢе°ұжү‘ЦІ”ҳqҮжқҘжү“дёӘеё®жүӢеQҢжҗ¬жҗ¬з…ӨеQҢжҢ‘жҢ‘ж°ҙеQҢйҖҒдәӣй’ЮqІ®жқҘеё®иЎҘз”·еӯ©зҡ„е®үҷҮҢгҖӮдқhйқ?иҚүжңЁеQҢеӯ°иғҪж— жғ…гҖӮе·ҰйӮХdҸіиҲҚеҜ№жӯӨзңӢеңЁзңјйҮҢпјҢи®°еңЁеҝғйҮҢеQҢйғҪеҠқжҜҚдәІеҶҚе«ҒпјҢдҪ•еҝ…иӢҰдәҶиҮӘе·ұгҖӮ然иҖҢжҜҚдәІеӨҡтqҙжқҘеҚҙе®Ҳнw«еҰӮзҺүпјҢе§Ӣз»ҲдёҚе«ҒеQҢеҲ«дәәеҶҚеҠқпјҢжҜҚдәІд№ҹж–ӯ然дёҚеҗ¬пјҢжҜҚдәІ иҜЯ_јҢжҲ‘дёҚзҲұпјҒ——ж’’зҡ„дә”дёӘи°?
гҖҖгҖҖ
6гҖҒз”·еӯ©е’ҢеҘ№зҡ„е“Ҙе§җеӨ§еӯҰжҜ•дёҡеҸӮеҠ е·ҘдҪңеҗҺпјҢдёӢдәҶеІ—зҡ„жҜҚдәІһ®ұеңЁйҷ„иҝ‘еҶңиеNеёӮеңәж‘ҶдәҶдёӘе°Ҹж‘Ҡз»ҙжҢҒз”ҹӢz…RҖӮинnеңЁеӨ–ең°е·ҘдҪңзҡ„еӯ©еӯҗ们зҹҘйҒ“еҗҺһ®ұеёёеёёеҜ„й’ұеӣһжқҘиЎҘиҙҙжҜҚдәФҢјҢжҜҚдәІеқҡеҶідёҚиҰҒеQҢеЖҲһ®Ҷй’ұйҖҖдәҶеӣһеҺ…RҖӮжҜҚдәІиҜҙеQҢжҲ‘жңүй’ұеQ?#8212;—ж’’зҡ„е…ӯдёӘи°?
гҖҖгҖҖ
7гҖҒз”·еӯ©з•ҷж Ўд“Qж•ҷдёӨтqЯ_јҢеҗҺеҸҲиҖғеҸ–дәҶзҫҺеӣҪдёҖжүҖеҗҚзүҢеӨ§еӯҰзҡ„еҚҡеЈ«з”ҹеQҢжҜ•дёҡеҗҺз•ҷеңЁҫҹҺеӣҪдёҖе®¶з§‘з ”жңәжһ„е·ҘдҪңпјҢеҫ…йҒҮзӣёеҪ“дё°еҺҡеQҢжқЎд»¶еҘҪдәҶпјҢнw«еңЁејӮеӣҪзҡ„з”·еӯ©жғіжҠҠжҜҚдәІжҺҘжқҘднnдә«жё…јӣҸеҚҙиў«иҖҒдқhеӣһз»қдәҶгҖӮжҜҚдәІиҜҙеQҢжҲ‘дёҚд№ жғҜпјҒ——ж’’зҡ„дёғдёӘи°?
гҖҖгҖҖ
8гҖҒжҷҡтqЯ_јҢжҜҚдәІжӮЈдәҶиғғзҷҢеQҢдҪҸҳqӣдәҶеҢ»йҷўеQҢиҝңеңЁеӨ§иҘҝжҙӢеҪјеІёзҡ„з”·еӯ©д№ҳйЈһжңәиө¶еӣһжқҘж—¶еQҢжңҜеҗҺзҡ„жҜҚдәІе·ІжҳҜеҘ„еҘ„дёҖжҒҜдәҶгҖӮжҜҚдәІиҖҒдәҶеQҢжңӣзқҖиў«з—…ҷм”жҠҳјӮЁеҫ—жӯХdҺ»ӢzАLқҘзҡ„жҜҚдәФҢјҢз”·еӯ©жӮІз—ӣӢЖІз»қеQҢжҪёз„¶жіӘдёӢгҖӮжҜҚдәІеҚҙиҜЯ_јҢеӯ©еӯҗеQҢеҲ«е“ӯпјҢжҲ‘дёҚз–№{Җ?#8212;—ж’’зҡ„жңҖеҗҺдёҖдёӘи°Һ
жңүж—¶еҖҷз”ЁеҲоCҪҚҳqҗз®—гҖӮйңҖиҰҒеҝ«йҖҹжүҫеҲоCёҖдёӘж•ҙж•°зҡ„дәҢиҝӣеҲ¶з¬¬дёҖдё?/span>1жҲ?/span>0еңЁе“ӘдёӘдҪҚ(дёӢж Ү)еQҹдҫӢеҰӮпјҡеҚҒиҝӣеҲ¶ж•°100зҡ„дәҢҳqӣеҲ¶жҳ?/span>1100100еQҢйӮЈд№Ҳе®ғзҡ„第дёҖдё?/span>1еңЁдёӢж ?/span> дё?/span>2зҡ„дҪҚҫ|?/span>(bsf, bit scan forward)жҲ?/span>6зҡ„дҪҚҫ|?/span>(bsr, bit scan in reverse order)еQҢз”ұдәҺеҸӘз”ЁдәҺеӯҳеӮЁдёҖдёӘзҠ¶жҖҒпјҢиҮідәҺз”?/span>bsfҳqҳжҳҜbsrеҲҷж— жүҖи°“гҖ?/span>
и§ЈеҶіҳqҷдёӘй—®йўҳзҡ„第дёҖдёӘжғіжі•е°ұжҳҜз”ЁеҶ…иҒ”жұҮзј–зҡ„еҒҡжі•пјҢдҪҝз”Ёзү№еҲ«зҡ?/span>CPUжҢҮдЧoеҺАLүҫеQҢдҪҶжұҮзј–зҡ„еҸҜҝUАLӨҚжҖ§жҜ”иҫғе·®еQҢдёҚеҗҢзҡ„CPUеһӢеҸ·дҪҝз”Ёзҡ„жҢҮд»ӨеҸҜиғҪдёҚдёҖж шPјҢжү§иЎҢйҖҹеәҰд№ҹдёҚдёҖж —чҖ?/span>
еҒҮи®ҫжүҫдёҖдё?/span>64дҪҚж— ҪWҰеҸ·ж•ҙж•°дәҢиҝӣеҲ¶зҡ„ҪW¬дёҖдё?/span>1еQҢз”Ёbsf, AT& TжұҮзј–(gccжұҮзј–)еҸҜд»Ҙҳqҷж ·еҒҡпјҡ
1 // bit scan forward for 64 bit integral number
2 /* ============================================ */
3 inline int bsf_asm (uint64_t w)
4 {
5 int x1, x2;
6 asm ("bsf %0,%0\n" "jnz 1f\n" "bsf %1,%0\n" "jz 1f\n" "addl $32,%0\n"
7 "1:": "=&q" (x1), "=&q" (x2):"1" ((int) (w >> 32)),
8 "0" ((int) w));
9 return x1;
10 }
еҰӮжһңз”?/span>CжқҘе®һзҺ°зҡ„иҜқпјҢйӮЈе°ұжңүзӮ№йәИқғҰдәҶпјҢеңЁжӯӨдёҚи®ІеӨҚжқӮзҡ„ж•°еӯҰеҺҹзҗҶпјҢд»…д»…ҫlҷеҮәд»Јз ҒгҖ?/span>
1 // bit scan forward for 64 bit integral number
2 /* ============================================ */
3 inline int bsf_folded (uint64_t bb)
4 {
5 static const int lsb_64_table[64] =
6 {
7 63, 30, 3, 32, 59, 14, 11, 33,
8 60, 24, 50, 9, 55, 19, 21, 34,
9 61, 29, 2, 53, 51, 23, 41, 18,
10 56, 28, 1, 43, 46, 27, 0, 35,
11 62, 31, 58, 4, 5, 49, 54, 6,
12 15, 52, 12, 40, 7, 42, 45, 16,
13 25, 57, 48, 13, 10, 39, 8, 44,
14 20, 47, 38, 22, 17, 37, 36, 26
15 };
16 unsigned int folded;
17 bb ^= bb - 1;
18 folded = (int) bb ^ (bb >> 32);
19 return lsb_64_table[folded * 0x78291ACF >> 26];
20 }
еҰӮжһңжғід»ҺеҗҺеҫҖеүҚжҗңзҙўдёҖдёӘж•ҙж•°зҡ„дәҢиҝӣеҲ¶з¬¬дёҖдё?/span>1зҡ„дёӢж ҮпјҢз”ЁжұҮҫ~–еҸҜд»Ҙиҝҷж ·еҒҡгҖ?/span>
1 // bit scan in reverse order for 64 bit integral number
2 /* ============================================ */
3 inline int bsr_asm (uint64_t w)
4 {
5 int x1, x2;
6 asm ("bsr %1,%0\n" "jnz 1f\n" "bsr %0,%0\n" "subl $32,%0\n"
7 "1: addl $32,%0\n": "=&q" (x1), "=&q" (x2):"1" ((int) (w >> 32)),
8 "0" ((int) w));
9 return x1;
10 }
еҰӮжһңз”?/span>CжқҘе®һзҺ°зҡ„иҜқпјҢд№ҹжҜ”иҫғз®ҖеҚ•пјҢз”?/span>divide and conquer зҡ„еҺҹзҗҶе°ұдёҚдјҡеӨӘж…ўгҖ?/span>
1 // a logn (n == 32)algorithm for bit scan in reverse order
2 /* ============================================ */
3 inline int bsr32(uint32_t bb)
4 {
5 static const char msb_256_table[256] =
6 {
7 0, 0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3,
8 4, 4, 4, 4, 4, 4, 4, 4,4, 4, 4, 4,4, 4, 4, 4,
9 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
10 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
11 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
12 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
13 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
14 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
15 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
16 };
17 int result = 0;
18
19 if (bb > 0xFFFF)
20 {
21 bb >>= 16;
22 result += 16;
23 }
24 if (bb > 0xFF)
25 {
26 bb >>= 8;
27 result += 8;
28 }
29
30 return (result + msb_256_table[bb]);
31 }
32
33 /* ============================================ */
34 inline int bsr_in_C(uint64_t bb)
35 {
36 const uint32_t hb = bb >> 32;
37 return hb ? 32 + bsr32((uint32_t)hb) : bsr32((uint32_t)bb);
38
39 }
40
дёӢйқўҳqҷдёӘдјйg№Һд№ҹеҸҜд»ҘпјҢеӨЮpУ|ж—¶иҝ”еӣ?/span>-1023еQҢиҮідәҺйҖҹеәҰеҝ«ж…ўһ®ЮpҰҒзңӢзј–иҜ‘еҷЁзҡ„е—ңеҘҪдәҶгҖ?/span>
1 // bit scan in reverse order for 64 bit integral number
2 /* ============================================ */
3 inline int bsr_double (uint64_t bb)
4 {
5 union
6 {
7 double d;
8 struct
9 {
10 unsigned int mantissal : 32;
11 unsigned int mantissah : 20;
12 unsigned int exponent : 11;
13 unsigned int sign : 1;
14 };
15 } ud;
16 ud.d = (double)(bb & ~(bb >> 32));
17 return ud.exponent - 1023;
18 }
19
д»ҘдёҠuint64_tе’?/span>uint32_tжҳҜж–°C++ж ҮеҮҶеҸҜд»Ҙж”ҜжҢҒзҡ„ж•ҙеһӢпјҢеҲҶеҲ«зӣёеҪ“дә?/span>ж—§зҡ„unsigned long longе’?/span>unsigned longҫcХdһӢгҖ?span style="color:blue">д»ҘдёҠд»Јз ҒдёҚжҳҜжҲ‘зҡ„еҺҹеҲӣеQҢиҖҢжҳҜжқҘиҮӘеӣҪеӨ–жҹҗдҪҚжңӢеҸӢеQҢжҲ‘ҪEҚеҫ®еҠ е·ҘдәҶдёҖдёӢи„“еҲ°иҝҷйҮҢпјҢзүҲжқғеұһдәҺеҺҹдҪңиҖ…пјҢеҰӮжһңжҲ‘жІЎжңүи®°й”ҷзҡ„иҜқеә”иҜҘжҳҜGNUгҖ?/span>
2007тqҙеҲқеQҢеҲҡеҲҡеҚёд»Иқҡ„иҒ”еҗҲеӣҪз§ҳд№Ұй•ҝе®үеҚ—еQҢеңЁеҫ·е…ӢиҗЁж–Ҝе·һзҡ„дёҖдёӘеә„еӣӯйҮҢдёҫиЎҢдәҶдёҖеңәж…Ҳе–„жҷҡе®Я_јҢж—ЁеңЁдёәйқһӢzІиӮчеӣ°е„ҝз«ҘеӢҹжҚҗгҖӮеә”йӮҖеҸӮеҠ жҷҡе®ҙзҡ„йғҪжҳҜеҜҢе•Ҷе’ҢҪCҫдјҡеҗҚжөҒгҖӮеңЁжҷҡе®ҙһ®ҶиҰҒејҖе§Ӣзҡ„ж—¶еҖҷпјҢдёҖдҪҚиҖҒеҰҮдәәйўҶзқҖдёҖдёӘе°ҸеҘӣ_ӯ©жқҘеҲ°дәҶеә„еӣӯзҡ„е…ҘеҸЈеӨ„пјҢһ®ҸеҘіеӯ©жүӢйҮҢжҚ§зқҖдёҖдёӘзңӢдёҠеҺ»еҫҲзІҫиҮҙзҡ„з“пLҪҗгҖ?/span>
е®ҲеңЁеә„еӣӯе…ҘеҸЈеӨ„зҡ„дҝқе®үе®үдёңһ®јжӢҰдҪҸдәҶҳqҷдёҖиҖҒдёҖһ®ҸгҖ?#8220;ӢЖўиҝҺдҪ 们еQҢиҜ·еҮәзӨәиҜдhҹ¬еQҢи°ўи°ўгҖ?#8221;гҖ?/span>
“иҜдhҹ¬еQҢеҜ№дёҚи“vеQҢжҲ‘们没жңүжҺҘеҲ°йӮҖиҜшPјҢжҳҜеҘ№иҰҒжқҘеQҢжҲ‘йҷӘеҘ№жқҘзҡ„гҖ?#8221;иҖҒеҰҮдәәжҠҡж‘ёзқҖһ®ҸеҘіеӯ©зҡ„еӨҙгҖ?/span>
“еҫҲжҠұжӯүпјҢйҷӨдәҶе·ҘдҪңдәәе‘ҳеQҢжІЎжңүиҜ·жҹ¬зҡ„дәЮZёҚиғҪиҝӣеҺ…RҖ?#8221;е®үдёңһ®ЖDҜҙгҖ?/span>
“дёЮZ»Җд№ҲпјҹҳqҷйҮҢдёҚжҳҜдёҫиЎҢж…Ҳе–„жҷҡе®ҙеҗ—пјҹжҲ‘们жҳҜжқҘиЎЁзӨәжҲ‘们зҡ„еҝғж„Ҹзҡ„еQҢйҡҫйҒ“дёҚеҸҜд»Ҙеҗ—пјҹ”иҖҒеҰҮдәәзҡ„иЎЁжғ…еҫҲдёҘиӮғпјҢ“еҸҜзҲұзҡ„е°ҸйңІиҘҝеQҢд»Һз”өи§ҶдёҠзҹҘйҒ“дәҶҳqҷйҮҢиҰҒдШ“йқһжҙІзҡ„еӯ©еӯҗ们дёҫиЎҢж…Ҳе–„ӢzХdҠЁеQҢеҘ№еҫҲжғідёәйӮЈдәӣеҸҜжҖңзҡ„еӯ©еӯҗеҒҡзӮ№дәӢпјҢеҶӣ_®ҡжҠҠиҮӘе·ұеӮЁй’ЮqҪҗйҮҢжүҖжңүзҡ„й’ұйғҪжӢҝеҮәжқҘпјҢжҲ‘еҸҜд»ҘдёҚҳqӣеҺ»еQҢзңҹзҡ„дёҚиғҪи®©еҘ№иҝӣеҺХdҗ—еQ?#8221;
“жҳҜзҡ„еQҢиҝҷйҮҢе°ҶиҰҒдӢDиЎҢдёҖеңәж…Ҳе–„жҷҡе®Я_јҢеә”йӮҖеҸӮеҠ зҡ„йғҪжҳҜеҫҲйҮҚиҰҒзҡ„дқhеЈ«пјҢ他们һ®ҶдШ“йқһжҙІзҡ„еӯ©еӯҗж…·ж…Ёи§ЈеӣҠгҖӮеҫҲй«ҳе…ҙдҪ 们еёҰзқҖзҲұеҝғжқҘеҲ°ҳqҷйҮҢеQҢдҪҶжҳҜпјҢжҲ‘жғіҳqҷеңәеҗҲдёҚйҖӮеҗҲдҪ 们ҳqӣеҺ»гҖ?#8221;е®үдёңһ®ЖD§ЈйҮҠиҜҙгҖ?/span>
“еҸ”еҸ”еQҢж…Ҳе–„зҡ„дёҚжҳҜй’ұпјҢжҳҜеҝғеQҢеҜ№еҗ—пјҹ”дёҖзӣҙжІЎжңүиҜҙиҜқзҡ„һ®ҸеҘіеӯ©й—®е®үдёңһ®ы|јҢеҘ№зҡ„иҜқи®©е®үдёңһ®јж„ЈдҪҸдәҶгҖ?#8220;жҲ‘зҹҘйҒ“收еҲ°йӮҖиҜпLҡ„дәәжңүеҫҲеӨҡй’ұпјҢ他们дјҡжӢҝеҮәеҫҲеӨҡй’ұеQҢжҲ‘жІЎжңүйӮЈд№ҲеӨҡпјҢдҪҶиҝҷжҳҜжҲ‘жүҖжңүзҡ„й’ұе•ҠеQҢеҰӮжһңжҲ‘зңҹзҡ„дёҚиғҪҳqӣеҺ»еQҢиҜ·её®жҲ‘жҠҠиҝҷдёӘеёҰҳqӣеҺ»еҗ§пјҒ”һ®ҸеҘіеӯ©йңІиҘҝиҜҙе®ҢпјҢһ®ҶжүӢдёӯзҡ„еӮЁй’ұҫ|җйҖ’з»ҷе®үдёңһ®№{Җ?/span>
е®үдёңһ®йgёҚзҹҘйҒ“жҳҜжҺҘҳqҳжҳҜдёҚжҺҘеQҢжӯЈеңЁд»–дёҚзҹҘжүҖжҺӘзҡ„ж—¶еҖҷпјҢҪHҒ然жңүдқhиҜЯ_јҡ“дёҚз”ЁдәҶпјҢеӯ©еӯҗеQҢдҪ иҜҙеҫ—еҜ№пјҢж…Ҳе–„зҡ„дёҚжҳҜй’ұеQҢжҳҜеҝғпјҢдҪ еҸҜд»ҘиҝӣеҺ»пјҢжүҖжңүжңүзҲұеҝғзҡ„дқhйғҪеҸҜд»ҘиҝӣеҺ…RҖ?#8221;иҜҙиҜқзҡ„жҳҜдёҖдҪҚиҖҒеӨҙеQҢд»–йқўеёҰеҫ®з¬‘еQҢз«ҷеңЁе°ҸйңІиҘҝнw«ж—ҒгҖӮд»–нw¬инnе’Ңе°ҸйңІиҘҝдәӨи°ҲдәҶеҮ еҸҘпјҢ然еҗҺзӣҙинnиөдhқҘеQҢжӢҝеҮЮZёҖд»ҪиҜ·жҹ¬йҖ’з»ҷе®үдёңһ®ы|јҡ“жҲ‘еҸҜд»ҘеёҰеҘ№иҝӣеҺХdҗ—еQ?#8221;
е®үдёңһ®јжҺҘҳqҮиҜ·жҹ¬пјҢжү“ејҖдёҖзңӢпјҢеҝҷеҗ‘иҖҒеӨҙ敬дәҶдёӘзӨјеQ?#8220;еҪ“然еҸҜд»ҘдәҶпјҢжІғдлu·е·ҙиҸІзү№е…Ҳз”ҹгҖ?#8221;
еҪ“еӨ©ж…Ҳе–„жҷҡе®ҙзҡ„дё»и§’дёҚжҳҜеҖЎи®®иҖ…зҡ„е®үеҚ—еQҢдёҚжҳҜжҚҗеҮ?00дёҮзҫҺе…ғзҡ„е·ҙиҸІзү№пјҢд№ҹдёҚжҳҜжҚҗеҮ?00дёҮзҫҺе…ғзҡ„жҜ”е°”·зӣ–иҢЁеQҢиҖҢжҳҜд»…д»…жҚҗеҮә30ҫҹҺе…ғйӣ?5ҫҹҺеҲҶзҡ„е°ҸйңІиҘҝеQҢеҘ№иөўеҫ—дәҶжңҖеӨҡжңҖзғӯзғҲзҡ„жҺҢеЈ°гҖӮиҖҢжҷҡе®ҙзҡ„дё»йўҳж ҮиҜӯд№ҹеҸҳжҲҗдәҶҳqҷж ·дёҖеҸҘиҜқ“ж…Ҳе–„зҡ„дёҚжҳҜй’ұеQҢжҳҜеҝғгҖ?#8221;ҪW¬дәҢеӨ©пјҢҫҹҺеӣҪеҗ„еӨ§еӘ’дҪ“ҫUпLә·д»ҘиҝҷеҸҘиҜқдҪңдШ“ж ҮйўҳеQҢжҠҘйҒ“дәҶҳqҷж¬Ўж…Ҳе–„жҷҡе®ҙгҖӮзңӢеҲ°жҠҘйҒ“еҗҺеQҢи®ёеӨҡжҷ®жҷ®йҖҡйҖҡзҡ„ҫҹҺеӣҪдәәзә·ҫUҜӮЎЁҪCшҷҰҒдёәйқһӢzІйӮЈдәӣиӮчҪIпLҡ„еӯ©еӯҗжҚҗиө гҖ?/span>
http://idlebox.net/2007/stx-btree/
дёҖдҪҚеҜdеӣҪжңӢеҸӢзҡ„жқоCҪңгҖ?/div>
2006тqҙзҡ„иҒҢеңәеҮәеҘҮзҡ„еҶ·жё…пјҢзӣёжҜ”еүҚеҮ тqЯ_јҢҪҺҖеҺҶзҡ„ж•°йҮҸе’ҢиҙЁйҮҸйғҪеӨ§дШ“дёҚеҰӮеQҢеҫҲйҡ‘Цҫ—жү‘ЦҲ°дёүе№ҙе·ҘдҪңҫlҸйӘҢд»ҘдёҠзҡ„дқhеQҢжңүдёҖдё?/span> дёҚжҳҜзү№еҲ«ҪWЁпјҢһ®ұжҳҜзү№еҲ«жҖӘгҖӮе°ұжҳҜд№ҲеQҢе№Іеҫ—еҘҪи°ҒжІЎдәӢжҚўе·ҘдҪңе•ҠпјҒSimonжҳҜдёҖ家еӨ–дјҒиКY件公еҸёзҡ„жҖИқ»ҸзҗҶпјҢжңҖҳq‘з»ҷҳqҷдёӘй—®йўҳж„ҒеқҸдәҶгҖӮйЎ№зӣ®дёҖдёӘжҺҘдёҖдёӘзҡ„жҺҘдёӢжқҘпјҢдәәжүӢӯ‘?/span> жқҘи¶Ҡзҙ§еј гҖӮиҷҪз„?/span>SimonжҳҜдёӘжһҒйҷҗҫ~–зЁӢзҡ„зІүдёқпјҢдҪҶд№ҹдёҚеҫ—дёҚжү№еҮҶдәҶдёҖд»ҪеҸҲдёҖд»Ҫзҡ„еҠ зҸӯз”ҢҷҜ·гҖ?/span>HRҫlҸзҗҶжҠҠиҝҷдёӘй—®йўҳеҪ’ҫl“еҲ°жҲҝдӯhдёҠпјҢд»–зҡ„еҰҷи®әжҳ?/span>“жҖ•еӨұдёҡдәҶҳqҳдёҚдёҠжҲҝ ӢЖҫпјҢдёҚж•ўи·Пx§Ҫ”гҖ?/span>
ҳqҷеӨ©еQ?/span>Kҷе№зӣ®ҫl„й•ҝAllenҫlҲдәҺеҝҚдёҚдҪҸдәҶеQҢеёҰдәҶдёҖдёӘеҸӘжңүдёҖтqҙе·ҘдҪңз»ҸйӘҢзҡ„һ®ҸдјҷеӯҗиҰҒSimonйқўиҜ•еQ?/span>“еҫҲиҒӘжҳҺпјҒҫlҸйӘҢһ®‘дәҶзӮҸVҖ?/span>”
SimonзҡЧғәҶзҡЮqңүжҜӣпјҢиҜЯ_јҡ“дҪ дёҚзҹҘйҒ“ҳqҷдёӘиҒҢдҪҚжңҖдҪҺиҰҒжұӮжҳҜдёүе№ҙе·ҘдҪңҫlҸйӘҢеҗ—пјҹ”
AllenиҜЯ_јҡ“ҳqҷе·ІҫlҸжҳҜдёүдёӘжңҲйҮҢйҖҡиҝҮжҠҖжңҜиҖғиҜ•дёӯжңҖеҘҪзҡ„дёҖдёӘдәҶеQҢиҖҒеӨ§еQҢиҜ•иҜ•еҗ§гҖ?/span>”Allenжҳ?/span>SimonеӨҡе№ҙзҡ„е“Ҙ们пјҢжҜ”иҫғйҡҸдҫҝгҖ?/span>
жҠөеҲ°йқўеӯҗдёҠжқҘеQ?/span>SimonеҸӘеҘҪи®?/span>AllenжҠҠе°ҸдјҷеӯҗеёҰиҝӣжқҘгҖ?/span>
Simonзҡ„йқўиҜ•йҖҡеёёжҳҜдёүжӯҘжӣІеQ?/span>
й—®йўҳдёҖеQҡдҪ иғҪиҜҙиҜҙжҜ•дёҡеҗҺзҡ„дё»иҰҒе·ҘдҪңз»ҸеҺҶеҗ—еQ?/span>
й—®йўҳдәҢпјҡеҶҚиҜҙиҜҙдҪ еңЁе…¬еҸёзҡ„еңоCҪҚеQ?/span>
й—®йўҳдёүпјҡдҪ зҡ„еҸ‘еұ•зӣ®ж ҮжҳҜд»Җд№ҲпјҹҪ{үеӣһҪ{”еҗҺеQҢжҜ”еҰӮиҜҙжһ¶жһ„еёҲпјҢд»–е°ұи·ҹзқҖй—®пјҡжғҢҷұЎдёҖдёӢдҪ еҪ“жһ¶жһ„еёҲзҡ„дёҖеӨ©пјҢиҜҙз»ҷжҲ‘еҗ¬еҗ¬пјҹ
һ®ҸдјҷеӯҗеӣһҪ{”第дёҖй—®йўҳеҫҲеҝ«еҫҲжё…жҘҡпјҢдёҖтqҙе·ҘдҪңеҪ“然没д»Җд№ҲдёңиҘСқҖ?/span>Simonи§үеҫ—һ®ҸдјҷеӯҗжҢәиҒӘжҳҺгҖӮжүҖд»ҘеңЁһ®ҸдјҷеӯҗеӣһҪ{”дәҶҪW¬дәҢдёӘй—®йўҳеҗҺеQҢй—®дәҶдёҖдёӘеҸ‘ж•ЈжҖ§зҡ„й—®йўҳеQ?/span>“дҪ еҲҡжүҚиҜҙдҪ еңЁе…¬еҸёйҮҢеӨ„дәҺдёӯҪ{үж°ҙтq»IјҢйӮЈжҜ”дҪ е·®зҡ„дқhдёЮZ»Җд№ҲдјҡжҜ”дҪ е·®е‘ўеQ?/span>”
ҳqҷдёӘй—®йўҳжҳҜдёӘйҷ·йҳұгҖ?/span>
һ®ҸдјҷеӯҗеҶ’еҶ’еӨұеӨұеӣһҪ{”иҜҙеQ?/span>“жҲ‘и§үеҫ—他们жҜҸеӨ©е·ҘдҪңжҳҜдёәе·ҘдҪңиҖҢе·ҘдҪңпјҢе·ҘдҪңжІЎжңүиҙЈд“Qж„ҹгҖ?/span>”
SimonзӮ№зӮ№еӨҙиҜҙеQ?/span>“жҳҜеҗ—еQҹйӮЈзңҹжҳҜҫpҹзі•зҡ„е‘ҳе·ҘгҖӮйӮЈдҪ еҲҡеҘҪжҜ”ҫpҹзі•зҡ„е‘ҳе·ҘеҘҪдёҖзӮ№дәҶеQ?/span>”
һ®Ҹдјҷеӯҗзҡ„и„жҖёҖдёӢеӯҗҫUўдәҶеQ?/span>“жҲ‘дёҚжҳҜиҝҷдёӘж„ҸжҖ?/span>……”
“еҘҪдәҶеQҢйӮЈдҪ иҜҙиҜҙжҜ”дҪ еҘҪзҡ„дқhдёЮZ»Җд№ҲжҜ”дҪ ејәеQ?/span>”
“жҲ‘и§үеҫ—д»–йқһеёёеҠӘеҠӣеQҢе·ҘдҪңеҫҲеӨҡе№ҙдәҶиҝҳеңЁеӯҰд№ еҗ„ҝUҚжһ„жһУһјҢж°ҙег^еҫҲй«ҳгҖ?/span>”дәҺжҳҜSimonһ®ұй—®йӮЈжңҖеҗҺдёҖдёӘй—®йўҳгҖӮжһңз„УһјҢһ®ҸдјҷеӯҗеӣһҪ{”зҡ„жҳҜиҰҒжҲҗдШ“жһ¶жһ„еёҲгҖӮеӨ§жҰ?/span>70еQ…зҡ„дәәжғіжҲҗдШ“жһ¶жһ„еёҲгҖӮдҪҶжҳҜжһ¶жһ„еёҲжҳҜд»Җд№Ҳе‘ўеQ?/span>
Simonй—®йҒ“еQ?/span>“йӮЈдҪ дёЮZ»Җд№ҲиҰҒжҲҗдШ“жһ¶жһ„еёҲе‘ўеQ?/span>”
һ®ҸдјҷеӯҗдёҖж„ЈпјҢеӨ§жҰӮҳqҳжІЎжңүдқhҳqҷд№Ҳҫ|®з–‘ҳqҮд»–гҖ?/span>“тqҙзәӘеӨ§дәҶеQҢдёҚиғҪиҖҒеҶҷҪEӢеәҸеҗ§гҖ?/span>”ҳqҷдёӘеӣһзӯ”еQҢи®©SimonжғҢҷ“vе…ідәҺд»–еҜ№д»Җд№ҲжҳҜиҖҒзҡ„е®ҡд№үеQҡеҪ“дҪ еёҢжңӣеҒҡтqҙиҪ»дәәеҒҡзҡ„дәӢжғ…ж—¶еQҢдҪ һ®ЮpҝҳтqҙиҪ»еQӣеҰӮжһңдҪ еёҢжңӣеҒҡиҖҒе№ҙдәәеҒҡзҡ„дәӢжғ…пјҢдҪ е°ұиҖҒдәҶгҖӮиҝҷе’ҢдҪ еҮәз”ҹдәҶеӨҡй•ҝж—¶й—ҙжҳҜжІЎжңүе…ізі»зҡ„гҖ?/span>
SimonжҺҘзқҖй—®пјҡ“еҘҪеҗ§еQҢйӮЈдҪ иҜҙиҜҙдҪ жҲҗдШ“жһ¶жһ„еёҲд»ҘеҗҺпјҢжҜҸеӨ©йғҪдјҡеҒҡд»Җд№Ҳпјҹ”
һ®ҸдјҷеӯҗиҜҙеQ?/span>“жҲ‘иҝҳжІЎжғіҳqҮпјҢдёҚиҝҮеQҢжҲ‘жғӣ_ә”иҜҘдё»иҰҒжҳҜйңҖжұӮеҲҶжһҗпјҢи®ҫи®Ўжһ„жһ¶еҗ?/span>……”ҳqҷеӨ§жҰӮжҳҜзҺ°еңЁтqҙиҪ»дәәзҡ„йҖҡз—…еQҢе№ҙиҪЦMқhеҫҲе®№жҳ“иҝҪйҖҗдёҖдәӣиҮӘе·Чғ№ҹдёҚжё…жҘҡзҡ„зӣ®ж ҮгҖ?/span>
Simonй—®пјҡ“йӮЈи®ҫи®Ўжһ„жһ¶е…·дҪ“йғҪеҒҡдәӣд»Җд№Ҳе‘ўеQ?/span>”
һ®ҸдјҷеӯҗиҝҷӢЖЎзҡ„еӣһзӯ”жҳҜпјҡ“жҜ”еҰӮеQҢйҖүжӢ©ҪEӢеәҸжЎҶжһ¶еQҢеҶіе®ҡз”ЁSpringжҲ?/span>StrutsҪ{үзӯүгҖ?/span>”
“е“ҰпјҢйӮЈжҲ‘й—®дҪ еQҢдҪ жҖҺд№ҲиҜҙжңҚеҲ«дқhжҳҜз”ЁSpringҳqҳжҳҜStrutsе‘ўпјҹ”
“еҰӮжһңжҲ‘жңүҫlҸйӘҢеQҢжҲ‘дјҡзҹҘйҒ“е“ӘдёӘжӣҙеҘ?/span>……”
“жҳҜеҗ—еQҢдҪҶе…ідәҺSpringжҲ?/span>Strutsзҡ„зҹҘиҜҶд“Qи°ҒйғҪеҸҜд»ҘеҫҲе®№жҳ“еҫ—еҲ°гҖӮеҰӮжһңеҲ«дәЮZёҚеҗҢж„ҸдҪ зҡ„е»шҷ®®еQҢдҪ жҖҺд№ҲиҜҙжңҚд»–пјҹеҰӮжһңеҗҢж„ҸдҪ зҡ„е»шҷ®®еQҢйӮЈдҪ дёҚҳqҮжҳҜдҪңеҮәдәҶе’ҢеҲ«дқhдёҖж пLҡ„и®ӨиҜҶеQҢеҲ«дәәеҸҲеҮӯд»Җд№Ҳи®ӨеҸҜдҪ е‘ўпјҹ”
һ®ҸдјҷеӯҗжІЎжғҢҷҝҮжһ¶жһ„еёҲж—ҘеӯҗйҮҢҳqҳжңүдёҖдёӘиҜҙжңҚдқhзҡ„е·ҘдҪңпјҢиҜЯ_јҡ“жҲ‘жҳҜжһ¶жһ„еёҲпјҢжҲ‘еә”иҜҘжңүжқғеҠӣеҒҡеҶіе®ҡеҗ§еQ?/span>”
SimonжғҢҷ“vжқғеҠӣзҡ„дёүҝUҚеұӮӢЖЎпјҢҪW¬дёҖеұӮпјҢд»Хd‘ҪеQӣ第дәҢеұӮеQҢдё“дёҡпјӣҪW¬дёүеұӮпјҢе“ҒеҜdгҖ?/span>
Simonй—®пјҡ“еҰӮжһңеңЁдёҖдёӘжҲҗзҶҹзҡ„иҪҜдҡgдјҒдёҡйҮҢжІЎжңүдҪ жүҖжғҢҷұЎзҡ„жһ¶жһ„еёҲе‘ўпјҹжҲ–иҖ…иҜҙеQҢжһ¶жһ„еёҲҳqҷз§ҚиҒҢдёҡе·Із»ҸжӯЦMәЎжҲ–ж¶ҲеӨЧғәҶе‘ўпјҹдҪ дјҡжҖҺд№Ҳе®ҡдҪҚдҪ зҡ„иҒҢдёҡеQ?/span>”
һ®Ҹдјҷеӯҗжҳҫеҫ—еҫҲйңҮжғҠгҖ?/span>
Simonз”ЦMәҶдёҖдёӘзі»ҫlҹжһ„жһУһјҢ然еҗҺеҸҲз»ҷһ®ҸдјҷеӯҗзңӢдәҶдёҖҢDөд»Јз ҒгҖ?/span>
“йӮЈдёҖдёӘжӣҙйҡҫжҮӮеQ?/span>”Simonй—®гҖ?/span>
һ®ҸдјҷеӯҗжҢҮзқҖд»Јз ҒиҜЯ_јҡ“д»Јз ҒйҡҫжҮӮгҖ?/span>”
Simonзҡ„и§ЈйҮҠжҳҜеQ?/span>“ҳqҷе°ұжҳҜдШ“д»Җд№Ҳе®һйҷ…дёҠжүҖи°“зҡ„жһ¶жһ„еёҲдёҚеӯҳеңЁзҡ„еҺҹеӣ гҖӮдёҖдёӘжӣҙҪҺҖеҚ•зҡ„дёңиҘҝжҖҺд№ҲдјҡжӣҙжңүдӯhеҖје‘ўеQҹжҜҸдёӘдқhйғҪиғҪеӨҹз”»еҮшҷҝҷҝUҚжһ„жһ¶еӣҫеQҢдҪҶдёҚжҳҜжҜҸдёӘдәәйғҪиғҪеҶҷеҮәеҘҪзҡ„д»Јз ҒгҖ?/span>”
йҖҒиө°дәҶе°ҸдјҷеӯҗеQ?/span>SimonжңүзӮ№йҡ‘ЦҸ—гҖӮд»–жңүзӮ№е–ңж¬ўҳqҷдёӘһ®ҸдјҷеӯҗпјҢдҪҶжҳҜеQҢиҝҷеҸҲжҳҜдёҖдёӘиў«ж„ҡи ўзҡ„ж•ҷиӮІе’ҢиҜҜдқhеӯҗејҹзҡ„жҠҖжңҜжқӮеҝ—жұЎжҹ“зҡ„家дјҷгҖ?/span>SimonеңЁиҮӘе·Юqҡ„ҪW”и®°жң¬дёӯеҠ дәҶдёҖеҸҘиҜқеQҡдёӯеӣҪзЁӢеәҸе‘ҳжңҖж„ҡи ўзҡ„и®ӨиҜҶд№ӢдёүпјҡжҲ‘жғіеҪ“жһ¶жһ„еёҲгҖӮеүҚйқўдёӨдёӘиө«з„¶жҳҜеQ?/span>
35еІҒеҗҺеҶҷдёҚеҠЁзЁӢеәҸдәҶеQ?/span>
жҲ‘еҸӘиҰҒеҒҡJavaеQ?/span>CеQӢпјӢеQүпјӣ
ҳqҳжӣҫҫlҸеҗ¬дёҚе°‘дәәйј“еҗ№иҝҮи„ҡжң¬еQҢиҜҙи„ҡжң¬ҪEӢеәҸжҜ”C++ҪEӢеәҸж…ўдёҚдәҶеӨҡһ®‘пјҢжңүдқhз”ҡиҮіҫl?0%еQҢеҜ№жӯӨжҲ‘дёҚеҠ иҜ„и®әдәҶпјҢзңӢзңӢҳqҷйҮҢзҡ„жөӢиҜ•з»“жһңе°ұдёҖзӣ®дәҶ然гҖ?br>
дёӢйқўжңүдёӘӢ№®зӮ№еҜҶйӣҶеһӢзҡ„и®Ўз®—ҪEӢеәҸеQҢжІЎжңүдӢЙз”Ёblitz++е’ҢMTLеQҢеҫҲҪWҰеҗҲдёҖиҲ¬жҖ§еә”з”ЁпјҢеҰӮжһңз”ЁдёҠ他们йӮЈе°ұдёҚеҘҪиҜҙжҖҺд№Ҳж шPјҢеӣ дШ“дё»иҰҒжҳҜе’ҢFortranжҜ”科еӯҰи®ЎҪҺ—йҖҹеәҰж—¶жүҚз”ЁгҖӮе·ІҫlҸжңүдәәзј–з ҒжөӢиҜ•дәҶгҖ?br>еҸӘи®ІйҖҹеәҰеQҢеҰӮжһңеҶҚжҜ”еҶ…еӯҳпјҢе…¶д»–еҮ з§ҚиҜӯиЁҖһ®ұжІЎжңүеҝ…иҰҒжҜ”дёӢеҺ»дәҶгҖ?br>
дёҚеҗҢиҜӯиЁҖзүҲжң¬зҡ„д»Јз ҒеҲ°еҺҹдҪңиҖ…жҸҗдҫӣзҡ„ең°еқҖеҺЦMёӢиҪҪпјҡhttp://files.cnblogs.com/miloyip/smallpt20100623.zip
дёӢйқўжҳҜжөӢиҜ•з”Ёзҡ„зі»ҫlҹй…Қҫ|®пјҡ
Ӣ№ӢиҜ•й…ҚзҪ®
- јӢ¬дҡg: Intel Core i7 920@2.67Ghz(4 core, HyperThread), 12GB RAM
- ж“ҚдҪңҫpИқ»ҹ: Microsoft Windows 7 64-bit
|
Ӣ№ӢиҜ•еҗҚз§° |
ҫ~–иҜ‘еҷ?/span>/и§ЈиҜ‘еҷ?/span> |
ҫ~–иҜ‘/ҳqҗиЎҢйҖүйЎ№ |
|
VC++ |
Visual C++ 2008 (32-bit) |
/Ox /Ob2 /Oi /Ot /GL /FD /MD /GS- /Gy /arch:SSE /fp:fast |
|
VC++_OpenMP |
Visual C++ 2008 (32-bit) |
/Ox /Ob2 /Oi /Ot /GL /FD /MD /GS- /Gy /arch:SSE /fp:fast /openmp |
|
IC++ |
Intel C++ Compiler (32-bit) |
/Ox /Og /Ob2 /Oi /Ot /Qipo /GA /MD /GS- /Gy /arch:SSE2 /fp:fast /Zi /QxHost |
|
IC++_OpenMP |
Intel C++ Compiler (32-bit) |
/Ox /Og /Ob2 /Oi /Ot /Qipo /GA /MD /GS- /Gy /arch:SSE2 /fp:fast /Zi /QxHost /Qopenmp |
|
GCC |
GCC 4.3.4 in Cygwin (32-bit) |
-O3 -march=native -ffast-math |
|
GCC_OpenMP |
GCC 4.3.4 in Cygwin (32-bit) |
-O3 -march=native -ffast-math -fopenmp |
|
C++/CLI |
Visual C++ 2008 (32-bit), .Net Framework 3.5 |
/Ox /Ob2 /Oi /Ot /GL /FD /MD /GS- /fp:fast /Zi /clr /TP |
|
C++/CLI_OpenMP |
Visual C++ 2008 (32-bit), .Net Framework 3.5 |
/Ox /Ob2 /Oi /Ot /GL /FD /MD /GS- /fp:fast /Zi /clr /TP /openmp |
|
C# |
Visual C# 2008 (32-bit), .Net Framework 3.5 |
|
|
*C#_outref |
Visual C# 2008 (32-bit), .Net Framework 3.5 |
|
|
F# |
F# 2.0 (32-bit), .Net Framework 3.5 |
|
|
Java |
Java SE 1.6.0_17 |
-server |
|
JsChrome |
Chrome 5.0.375.86 |
|
|
JsFirefox |
Firefox 3.6 |
|
|
LuaJIT |
LuaJIT 2.0.0-beta4 (32-bit) |
|
|
Lua |
LuaJIT (32-bit) |
-joff |
|
Python |
Python 3.1.2 (32-bit) |
|
|
*IronPython |
IronPython 2.6 for .Net 4 |
|
|
*Jython |
Jython 2.5.1 |
|
|
Ruby |
Ruby 1.9.1p378 |
|
жёІжҹ“зҡ„и§ЈеғҸеәҰдё?/span>256x256еQҢжҜҸиұЎзҙ дҪ?/span>100ӢЖЎйҮҮж —чҖ?/span>
ҫl“жһңеҸҠеҲҶжһ?/span>
дёӢиЎЁдёӯйў„и®„Ўҡ„зӣёеҜ№ж—үҷ—ҙд»ҘжңҖеҝ«зҡ„еҚ•зәҝҪEӢжөӢиҜ?/span>(IC++)дҪңеҹәеҮҶпјҢз”Ёйј ж ҮжҢүеҲ—еҸҜж”№еҸҳеҹәеҮҶгҖӮз”ұдә?/span>RubyҳqҗиЎҢж—үҷ—ҙеӨӘй•ҝеQҢеҸӘжҜҸиұЎзҙ дҪң4ӢЖЎйҮҮж шPјҢжҠҠж—¶й—ҙд№ҳдё?/span>25гҖӮеҸҰ еӨ–пјҢеӣ дШ“еҗ„жөӢиҜ•зҡ„жёІжҹ“ж—үҷ—ҙзӣёе·®еҫҲиҝңеQҢжүҖд»Ҙз”ЁдәҶдёӨдёӘжЈ’еҪўеӣҫеҺАLҳҫҪCәж•°жҚ®пјҢеҲҶеҲ«жҳ„ЎӨәж—үҷ—ҙһ®‘дәҺ4000ҝU’е’Ңһ®‘дәҺ60ҝU’зҡ„Ӣ№ӢиҜ•(Rubyжҳ?/span>4000ҝU’д»ҘеӨ–пјҢдёҚдәҲжҳ?/span> ҪC?/span>)гҖ?/span>
|
Test |
Time(sec) |
Relative time |
|
IC++_OpenMP |
2.861 |
0.19x |
|
VC++_OpenMP |
3.140 |
0.21x |
|
GCC_OpenMP |
3.359 |
0.23x |
|
C++/CLI_OpenMP |
5.147 |
0.35x |
|
IC++ |
14.761 |
1.00x |
|
VC++ |
17.632 |
1.19x |
|
GCC |
19.500 |
1.32x |
|
C++/CLI |
27.634 |
1.87x |
|
Java |
30.527 |
2.07x |
|
C#_outref |
44.220 |
3.00x |
|
F# |
47.172 |
3.20x |
|
C# |
48.194 |
3.26x |
|
JsChrome |
237.880 |
16.12x |
|
LuaJIT |
829.777 |
56.21x |
|
Lua |
1,227.656 |
83.17x |
|
IronPython |
2,921.573 |
197.93x |
|
JsFirefox |
3,588.778 |
243.13x |
|
Python |
3,920.556 |
265.60x |
|
Jython |
6,211.550 |
420.81x |
|
Ruby |
77,859.653 |
5,274.69x |
C++/.Net/Javaҫl„еҲ«
йқҷжҖҒиҜӯӯaҖе’ҢеҠЁжҖҒиҜӯӯaҖеңЁжӯӨӢ№ӢиҜ•дёӢзҡ„жҖ§иғҪдёҚеңЁеҗҢдёҖж•°йҮҸҫU§гҖӮе…ҲжҜ”иҫғйқҷжҖҒиҜӯӯaҖгҖ?/span>
C++е’?/span>.Netзҡ„жөӢиҜ•з»“жһңе’ҢдёҠдёҖҪӢҮеҚҡж–ҮзӣёиӢҘпјҢиҖ?/span>C#е’?/span>F#ж— жҳҫи‘—еҢәеҲ«гҖӮдҪҶжҳҜпјҢC++/CLIиҷҪ然еҗҢж ·дә§з”ҹILеQҢдәҺжӢ¬з®Ўзҡ?/span>.Netтqӣ_Ҹ°дёҠжү§иЎҢпјҢе…¶жёІжҹ“ж—¶й—?/span> еҚҙеҸӘжҳ?/span>C#/F#зҡ?/span>55%е·ҰеҸігҖӮдШ“д»Җд№Ҳе‘ўеQҹдӢЙз”?/span>ildasmеҺХdҸҚжұҮзј–C++/CLIе’?/span>C#зҡ„еҸҜжү§иЎҢж–ҮдҡgеҗҺпјҢеҸҜд»ҘеҸ‘зҺ°еQҢзЁӢеәҸзҡ„зғӯзӮ№еҮҪж•° Sphere.Intersect()еңЁдёӨдёӘзүҲжң¬дёӯеQ?/span>C++/CLIзүҲжң¬зҡ„д»Јз ҒеӨ§һ®?/span>(code size)дё?/span>201еӯ—иҠӮеQ?/span> C#еҲҷдШ“125еӯ—иҠӮеQ?/span> C++/CLIзүҲжң¬еңЁзј–иҜ‘ж—¶еQҢе·ІжҠҠеҮҪж•°еҶ…жүҖжң?/span>VecҫcИқҡ„ж–ТҺі•и°ғз”Ёе…ЁйғЁеҶ…иҒ”еQҢиҖ?/span>C#зүҲжң¬еҲҷдӢЙз”?/span>callvirtи°ғз”ЁVecзҡ„ж–№жі•гҖӮдј°и®?/span>JITжІЎжңүжҠҠиҝҷеҮҪж•°ҳq?/span> иЎҢеҶ…иҒ”пјҢеҒҡжҲҗҳqҷдёӘжҖ§иғҪе·®ејӮгҖӮеҸҰеӨ–пјҢC++/CLIзүҲжң¬дҪҝз”ЁдәҶеҖјзұ»еһӢпјҢтq¶дӢЙз”ЁжҢҮй’?/span>(д»Јз ҒдёӯдШ“еј•з”Ё)жүҳз®Ўд»Јз Ғ(C++/CLI)зҡ„жёІжҹ“ж—¶й—Я_јҢд»…дШ“еҺҹз”ҹйқһжӢ¬ҪҺЎд»Јз ?/span>(IC++)зҡ?/span>1.91еҖҚпјҢдёӘдқhи§үеҫ—.Netзҡ?/span>JITе·Із»ҸйқһеёёдёҚй”ҷгҖ?/span>
еҸҰдёҖж–ҡwқўеQ?/span>Javaзҡ„жҖ§иғҪиЎЁзҺ°йқһеёёҪHҒеҮәеQҢеҸӘжҜ?/span>C++/CLIҪEҚж…ўдёҖзӮ№пјҢJavaзүҲжң¬зҡ„жёІжҹ“ж—¶й—ҙдШ“C#/F#зҡ?/span>65%е·ҰеҸігҖӮд»ҘеүҚдёҖзӣҙи®ӨдёәпјҢC#дёҚе°‘и®ҫи®ЎдјҡдӢЙе…¶жҖ§иғҪй«ҳдәҺJavaеQҢдҫӢеҰ?/span>C#зҡ„ж–№жі•йў„и®ҫдШ“йқһиҷҡеQ?/span>JavaеҲҷйў„и®ҫдШ“иҷҡпјӣеҸҲдҫӢеҰ?/span>C#ж”ҜжҢҒstructдҪңеҖјзұ»еһ?/span>(value type)еQ?/span>JavaеҲҷеҸӘжң?/span>classеј•з”ЁҫcХdһӢ(reference type)еQҢеҗҺиҖ…еҝ…ҷеЦMӢЙз”?/span>GCгҖӮдҪҶжҳҜпјҢҳqҷдёӘӢ№ӢиҜ•жҳ„ЎӨәеQ?/span>Java VMеә”иҜҘең?/span>JITдёӯеҒҡдәҶеӨ§йҮҸдјҳеҢ–пјҢдј°и®Ўд№ҹеә”з”ЁдәҶеҶ…иҒ”еQҢжүҚиғҪдӢЙе…¶жҖ§иғҪйҖЖDҝ‘C++/CLIгҖ?/span>
ҫU?/span>C++ж–ҡwқўеQ?/span>Intel C++ҫ~–иҜ‘еҷЁжңҖеҝ«пјҢVisual C++ж…ўдёҖзӮ№зӮ№(1.19x)еQ?/span>GCCеҶҚж…ўдёҖзӮ№зӮ№(1.32x)гҖӮиҝҷҫl“жһңҪWҰеҗҲжң¬дқhйў„жңҹгҖ?/span> Intel C++зҡ?/span>OpenMPзүҲжң¬е’ҢеҚ•ҫUҝзЁӢжҜ”иҫғеQҢиҫҫ5.16еҠ йҖҹжҜ”(speedup)еQҢеҜ№дә?/span>4ж ?/span>Hyper ThreadingжқҘиҜҙҪҺ—жҳҜдёҚй”ҷзҡ„з»“жһңгҖӮиҜ»иҖ…иӢҘжңүе…ҙӯ‘ЈпјҢд№ҹеҸҜд»ҘиҮӘиЎҢжөӢиҜ?/span>C# 4.0зҡ„еЖҲиЎҢж–°зүТҺҖ§гҖ?/span>
еҠЁжҖҒиҜӯӯaҖҫl„еҲ«
йҰ–е…ҲеQҢиҰҒиҜҙдёҖеҸҘпјҢGoogleеӨӘејәдәҶпјҢйҡҫд»Ҙжғӣ_ғҸJsChomeзҡ„жёІжҹ“ж—¶й—ҙд»…жҳ?/span>IC++зҡ?/span>16.12еҖҚпјҢC#зҡ?/span>4.94еҖҚгҖ?/span>
д»ҘдёӢжҜ”иҫғеҗ„еҠЁжҖҒиҜӯӯaҖзҡ„зӣёеҜТҺ—¶й—Я_јҢд»?/span>JsChromeдёәеҹәеҮҶгҖ?/span> Chromeзҡ?/span>V8 JavaScriptеј•ж“Һ(1.00x)еӨ§е№…жҠӣзҰ»Firefoxзҡ?/span>SpiderMonkeyеј•ж“Һ(15.09x)гҖӮиҖ?/span>LuaJIT(3.49x)е’?/span>Lua(5.16x)еҲҷжҺ’ҪW¬дәҢе’Ң第дёүеҗҚгҖ?/span> Luaзҡ?/span>JITзүҲжң¬жҳҜжІЎжң?/span>JITзҡ?/span>68%еQҢеЖҲжІЎжңүжғӣ_ғҸдёӯзҡ„еҝ«пјҢдҪҶжҳҜд№ҹжҜ”Python(16.48x)еҝ«еҫ—еӨҡгҖӮжӣҫеҗ¬иҜҙҳq?/span>Rubyжңүж•ҲиғҪй—®йўҳпјҢжІЎжғіеҲ°й—®йўҳз«ҹ然еҰӮжӯӨдёҘйҮ?/span>(327.31x)еQҢе…¶жёІжҹ“ж—үҷ—ҙе·®дёҚеӨҡжҳҜPythonзҡ?/span>20еҖ?
C# vs C++ vs JavaжҖ§иғҪеҜТҺҜ”
C#, Java е’ҢC++еҜТҺҜ”жҖ§иғҪеёёеёёжҳҜеј•еҸ‘дәүи®®зҡ„дёҖдёӘиҜқйўҳгҖӮйӮЈдәӣдёҚзҶҹжӮүJITзҡ„дқhеёёеёёеЈ°з§°JITдёҠиҝҗиЎҢзҡ„д»ЦMҪ•ҪEӢеәҸи·ҹC++жҜ”йҖҹеәҰйғҪдёҚиЎҢгҖӮиҖҢйӮЈдәӣдӢЙз”ЁJavaе’ҢC#зҡ„дқhеҲ? еёёеёёеЈ°з§°жҖ§иғҪе·®еҲ«з”ҡе°ҸеQҢеҮ д№ҺеҸҜд»ҘеҝҪз•ҘдёҚи®ЎгҖӮиҝҷйҮҢжңүдёҖдёӘжөӢиҜ•еҜ№жҜ”з»“жһңеӣҫеQҢжқҘиҮӘfreenode IRCжңҚеҠЎеҷЁпјҢдёҚзҹҘйҒ“и°ҒӢ№ӢиҜ•зҡ„пјҢдҪҶжҳҜҫl“жһңдјйg№ҺеҫҲзңҹе®һгҖ?nbsp;
еҜ№дәҺжҲ‘жқҘиҜЯ_јҢеӣ дШ“жҖ§иғҪеҺҹеӣ йҖүжӢ©C++дјйg№ҺзҗҶз”ұдёҚиғцгҖӮи®°дҪҸпјҡе·ҘзЁӢеёҲжҜ”жңҚеҠЎеҷЁиҰҒжҳӮиҙөзҡ„еӨҡеQ?br>

йғЁеҲҶе…¶д»–дәәзҡ„иҜ„и®әеQ?br>
еҚ•зәҝҪEӢжөӢиҜ•зҡ„еQҢеӨҡҫUҝзЁӢеҰӮдҪ•еQҹеҶ…еӯҳиҖ—иҙ№еӨҡе°‘еQҹжөӢиҜ•зЁӢеәҸж•°жҚ®дӢЙз”Ёзҡ„иҜӯиЁҖеҶ…еҫҸҫcХdһӢ(жҜ”еҰӮint)ҳqҳжҳҜиҮӘе®ҡд№үзұ»еһӢпјҢеҰӮжһңиҜӯиЁҖжң¬инnеҶ…еҫҸзҡ„зұ»еһӢйӮЈҫ~–иҜ‘жҲҗдәҢҳqӣеҲ¶Ӣ№ӢиҜ•ж—үҷ—ҙж¶ҲиҖ—е·®еҲ«дёҚдјҡеӨҡеӨ§жҳҜжӯЈеёёзҡ„гҖ?br>PHPжІЎжңүй’ҲеҜ№WindowsҫpИқ»ҹдјҳеҢ–еQҢеӣ жӯӨйҖҹеәҰиӮҜе®ҡдёҠдёҚеҺ…RҖ?br>еңЁWindowsдёҠжөӢиҜ•JavaжҳҜеҗҰҳqҗиЎҢеңЁиҷҡжӢҹжңәдёҠпјҹй»ҳи®Өжғ…еҶөеҸҜеЖҲйқһеҰӮжӯ?и·ҹLinuxеҸҜдёҚеҗ?еQҒеҶҚиҖ…пјҢӢ№ӢиҜ•ҫl“жһңиҖ—иҙ№ж—үҷ—ҙеӨӘзҹӯиҜҜе·®зӣёеҜ№еҸҜиғҪеҫҲеӨ§еQҢеҫҲйҡҫиҜҙжҳҺе®һйҷ…жғ…еҪўгҖ?br>
жӣҙеӨҡиҜ„и®ә...
Bж ?/span>
еҚідәҢеҸүжҗңзҙўж ‘еQ?/span>
1.жүҖжңүйқһеҸ¶еӯҗҫl“зӮ№иҮӣ_ӨҡжӢҘжңүдёӨдёӘе„ҝеӯҗеQ?/span>Leftе’?/span>RightеQүпјӣ
2.жүҖжңүз»“зӮ№еӯҳеӮЁдёҖдёӘе…ій”®еӯ—еQ?/span>
3.йқһеҸ¶еӯҗз»“зӮ№зҡ„е·ҰжҢҮй’ҲжҢҮеҗ‘е°ҸдәҺе…¶е…ій”®еӯ—зҡ„еӯҗж ‘еQҢеҸіжҢҮй’ҲжҢҮеҗ‘еӨ§дәҺе…¶е…ій”®еӯ—зҡ„еӯҗж ‘пјӣ
еҰӮпјҡ
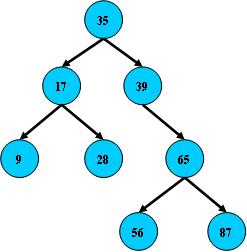
Bж ‘зҡ„жҗңзғҰеQҢд»Һж №з»“зӮ№ејҖе§ӢпјҢеҰӮжһңжҹҘиҜўзҡ„е…ій”®еӯ—дёҺз»“зӮ№зҡ„е…ій”®еӯ—зӣёҪ{үпјҢйӮЈд№Ҳһ®ұе‘ҪдёӯпјӣеҗҰеҲҷеQҢеҰӮжһңжҹҘиҜўе…ій”®еӯ—жҜ”з»“зӮ№е…ій”®еӯ—һ®ҸпјҢһ®Юpҝӣе…Ҙе·Ұе„ҝеӯҗеQӣеҰӮжһңжҜ”ҫl“зӮ№е…ій”®еӯ—еӨ§еQҢе°ұҳqӣе…ҘеҸӣ_„ҝеӯҗпјӣеҰӮжһңе·Ұе„ҝеӯҗжҲ–еҸӣ_„ҝеӯҗзҡ„жҢҮй’Ҳдёәз©әеQҢеҲҷжҠҘе‘ҠжүҫдёҚеҲ°зӣёеә”зҡ„е…ій”®еӯ—пјӣ
еҰӮжһңBж ‘зҡ„жүҖжңүйқһеҸ¶еӯҗҫl“зӮ№зҡ„е·ҰеҸӣ_ӯҗж ‘зҡ„ҫl“зӮ№ж•°зӣ®еқҮдҝқжҢҒе·®дёҚеӨҡеQҲег^иЎЎпјүеQҢйӮЈд№?/span>Bж ‘зҡ„жҗңзғҰжҖ§иғҪйҖЖDҝ‘дәҢеҲҶжҹҘжүҫеQӣдҪҶе®ғжҜ”ҳqһз®ӢеҶ…еӯҳҪIәй—ҙзҡ„дәҢеҲҶжҹҘжү„Ўҡ„дјҳзӮ№жҳҜпјҢж”№еҸҳBж ‘з»“жһ„пјҲжҸ’е…ҘдёҺеҲ йҷӨз»“зӮ№пјүдёҚйңҖиҰҒ移еҠЁеӨ§ҢDлҠҡ„еҶ…еӯҳж•°жҚ®еQҢз”ҡиҮійҖҡеёёжҳҜеёёж•°ејҖй”ҖеQ?/span>
дҪ?/span>Bж ‘еңЁҫlҸиҝҮеӨҡж¬ЎжҸ’е…ҘдёҺеҲ йҷӨеҗҺеQҢжңүеҸҜиғҪеҜЖDҮҙдёҚеҗҢзҡ„з»“жһ„пјҡ
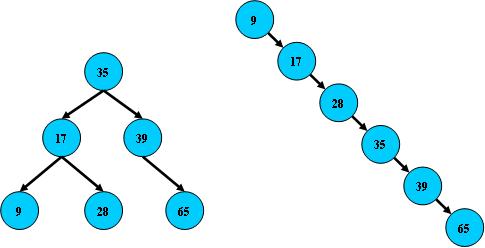
еҸҢҷҫ№д№ҹжҳҜдёҖдё?/span>Bж ‘пјҢдҪҶе®ғзҡ„жҗңзҙўжҖ§иғҪе·Із»ҸжҳҜзәҝжҖ§зҡ„дәҶпјӣеҗҢж ·зҡ„е…ій”®еӯ—йӣҶеҗҲжңүеҸҜиғҪеҜјиҮҙдёҚеҗҢзҡ„ж ‘з»“жһ„зғҰеј•пјӣжүҖд»ҘпјҢдҪҝз”ЁBж ‘иҝҳиҰҒиҖғиҷ‘һ®ҪеҸҜиғҪи®©Bж ‘дҝқжҢҒе·Ұеӣ„Ўҡ„ҫl“жһ„еQҢе’ҢйҒҝе…ҚеҸӣ_ӣҫзҡ„з»“жһ„пјҢд№ҹе°ұжҳҜжүҖи°“зҡ„“тqҢҷЎЎ”й—®йўҳеQ?/span>
е®һйҷ…дҪҝз”Ёзҡ?/span>Bж ‘йғҪжҳҜеңЁеҺ?/span>Bж ‘зҡ„еҹәзЎҖдёҠеҠ дёҠег^иЎЎз®—жі•пјҢеҚ?#8220;тqҢҷЎЎдәҢеҸүж ?#8221;еQӣеҰӮдҪ•дҝқжҢ?/span>Bж ‘з»“зӮ№еҲҶеёғеқҮеҢҖзҡ„ег^иЎЎз®—жі•жҳҜтqҢҷЎЎдәҢеҸүж ‘зҡ„е…ій”®еQӣег^иЎЎз®—жі•жҳҜдёҖҝUҚеңЁBж ‘дёӯжҸ’е…Ҙе’ҢеҲ йҷӨз»“зӮ№зҡ„Ҫ{–з•ҘеQ?/span>
B-ж ?/span>
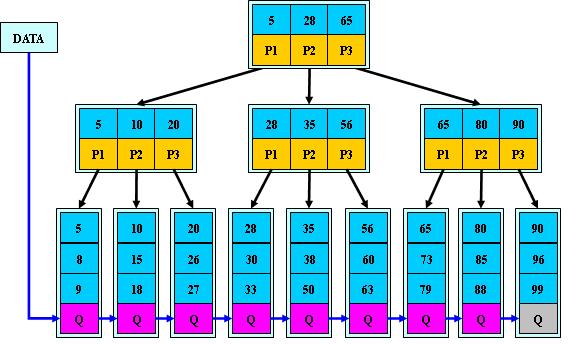
жҳҜдёҖҝUҚеӨҡи·Ҝжҗңзҙўж ‘еQҲеЖҲдёҚжҳҜдәҢеҸүзҡ„пјүеQ?/span>
1.е®ҡд№үд»АL„ҸйқһеҸ¶еӯҗз»“зӮТҺңҖеӨҡеҸӘжң?/span>MдёӘе„ҝеӯҗпјӣдё?/span>M>2еQ?/span>
2.ж №з»“зӮ№зҡ„е„ҝеӯҗж•оCШ“[2, M]еQ?/span>
3.йҷӨж №ҫl“зӮ№д»ҘеӨ–зҡ„йқһеҸ¶еӯҗҫl“зӮ№зҡ„е„ҝеӯҗж•°дё?/span>[M/2, M]еQ?/span>
4.жҜҸдёӘҫl“зӮ№еӯҳж”ҫиҮӣ_°‘M/2-1еQҲеҸ–дёҠж•ҙеQүе’ҢиҮӣ_ӨҡM-1дёӘе…ій”®еӯ—еQӣпјҲиҮӣ_°‘2дёӘе…ій”®еӯ—еQ?/span>
5.йқһеҸ¶еӯҗз»“зӮ№зҡ„е…ій”®еӯ—дёӘж•?/span>=жҢҮеҗ‘е„ҝеӯҗзҡ„жҢҮй’ҲдёӘж•?/span>-1еQ?/span>
6.йқһеҸ¶еӯҗз»“зӮ№зҡ„е…ій”®еӯ—пјҡK[1], K[2], …, K[M-1]еQӣдё”K[i] < K[i+1]еQ?/span>
7.йқһеҸ¶еӯҗз»“зӮ№зҡ„жҢҮй’ҲеQ?/span>P[1], P[2], …, P[M]еQӣе…¶дё?/span>P[1]жҢҮеҗ‘е…ій”®еӯ—е°Ҹдә?/span>K[1]зҡ„еӯҗж ‘пјҢP[M]жҢҮеҗ‘е…ій”®еӯ—еӨ§дә?/span>K[M-1]зҡ„еӯҗж ‘пјҢе…¶е®ғP[i]жҢҮеҗ‘е…ій”®еӯ—еұһдә?/span>(K[i-1], K[i])зҡ„еӯҗж ‘пјӣ
8.жүҖжңүеҸ¶еӯҗз»“зӮ№дҪҚдәҺеҗҢдёҖеұӮпјӣ
еҰӮпјҡеQ?/span>M=3еQ?/span>
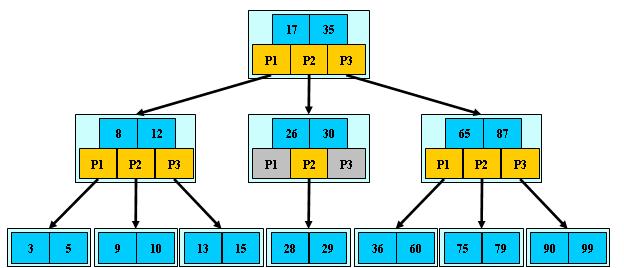
B-ж ‘зҡ„жҗңзғҰеQҢд»Һж №з»“зӮ№ејҖе§ӢпјҢеҜ№з»“зӮ№еҶ…зҡ„е…ій”®еӯ—еQҲжңүеәҸпјүеәҸеҲ—ҳqӣиЎҢдәҢеҲҶжҹҘжүҫеQҢеҰӮжһңе‘ҪдёӯеҲҷҫl“жқҹеQҢеҗҰеҲҷиҝӣе…ҘжҹҘиҜўе…ій”®еӯ—жүҖеұһиҢғеӣҙзҡ„е„ҝеӯҗҫl“зӮ№еQӣйҮҚеӨҚпјҢзӣҙеҲ°жүҖеҜ№еә”зҡ„е„ҝеӯҗжҢҮй’ҲдШ“ҪIәпјҢжҲ–е·ІҫlҸжҳҜеҸ¶еӯҗҫl“зӮ№еQ?/span>
B-ж ‘зҡ„зүТҺҖ§пјҡ
1.е…ій”®еӯ—йӣҶеҗҲеҲҶеёғеңЁж•ҙйў—ж ‘дёӯеQ?/span>
2.д»ЦMҪ•дёҖдёӘе…ій”®еӯ—еҮәзҺ°дё”еҸӘеҮәзҺ°еңЁдёҖдёӘз»“зӮ№дёӯеQ?/span>
3.жҗңзғҰжңүеҸҜиғҪеңЁйқһеҸ¶еӯҗз»“зӮ№з»“жқҹпјӣ
4.е…¶жҗңзҙўжҖ§иғҪҪ{үдӯhдәҺеңЁе…ій”®еӯ—е…ЁйӣҶеҶ…еҒҡдёҖӢЖЎдәҢеҲҶжҹҘжүҫпјӣ
5.иҮӘеҠЁеұӮж¬ЎжҺ§еҲ¶еQ?/span>
з”ЧғәҺйҷҗеҲ¶дәҶйҷӨж №з»“зӮ№д»ҘеӨ–зҡ„йқһеҸ¶еӯҗз»“зӮ№пјҢиҮӣ_°‘еҗ«жңүM/2дёӘе„ҝеӯҗпјҢјӢ®дҝқдәҶз»“зӮ№зҡ„иҮӣ_°‘еҲ©з”ЁзҺҮпјҢе…¶жңҖеә•жҗңзҙўжҖ§иғҪдёәпјҡ
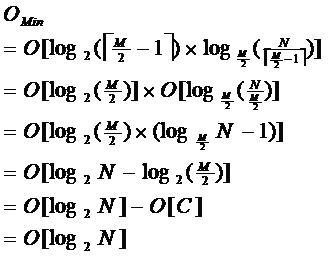
е…¶дёӯеQ?/span>Mдёшҷ®ҫе®ҡзҡ„йқһеҸ¶еӯҗз»“зӮТҺңҖеӨҡеӯҗж ‘дёӘж•ҺНјҢNдёәе…ій”®еӯ—жҖАL•°еQ?/span>
жүҖд»?/span>B-ж ‘зҡ„жҖ§иғҪжҖАLҳҜҪ{үдӯhдәҺдәҢеҲҶжҹҘжүҫпјҲдё?/span>MеҖјж— е…»IјүеQҢд№ҹһ®ұжІЎжң?/span>Bж ‘ег^иЎЎзҡ„й—®йўҳеQ?/span>
з”ЧғәҺM/2зҡ„йҷҗеҲУһјҢеңЁжҸ’е…Ҙз»“зӮТҺ—¶еQҢеҰӮжһңз»“зӮ№е·Іж»ЎпјҢйңҖиҰҒе°Ҷҫl“зӮ№еҲҶиЈӮдёЮZёӨдёӘеҗ„еҚ?/span>M/2зҡ„з»“зӮ№пјӣеҲ йҷӨҫl“зӮ№ж—УһјҢйңҖһ®ҶдёӨдёӘдёҚӯ‘?/span>M/2зҡ„е…„ејҹз»“зӮ№еҗҲтqУһјӣ
B+ж ?/span>
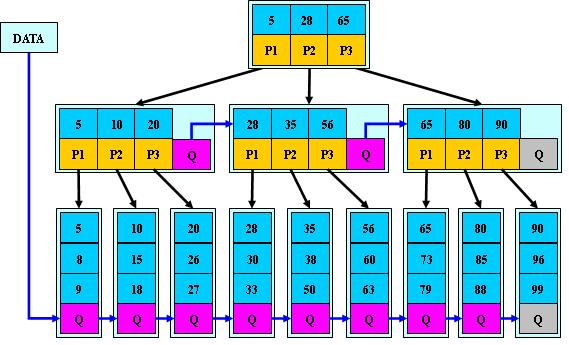
B+ж ‘жҳҜB-ж ‘зҡ„еҸҳдҪ“еQҢд№ҹжҳҜдёҖҝUҚеӨҡи·Ҝжҗңзҙўж ‘еQ?/span>
1.е…¶е®ҡд№үеҹәжң¬дёҺB-ж ‘еҗҢеQҢйҷӨдәҶпјҡ
2.йқһеҸ¶еӯҗз»“зӮ№зҡ„еӯҗж ‘жҢҮй’ҲдёҺе…ій”®еӯ—дёӘж•°зӣёеҗҢеQ?/span>
3.йқһеҸ¶еӯҗз»“зӮ№зҡ„еӯҗж ‘жҢҮй’ҲP[i]еQҢжҢҮеҗ‘е…ій”®еӯ—еҖјеұһдә?/span>[K[i], K[i+1])зҡ„еӯҗж ‘пјҲB-ж ‘жҳҜејҖеҢәй—ҙеQүпјӣ
5.дёәжүҖжңүеҸ¶еӯҗз»“зӮ№еўһеҠ дёҖдёӘй“ҫжҢҮй’ҲеQ?/span>
6.жүҖжңүе…ій”®еӯ—йғҪеңЁеҸ¶еӯҗҫl“зӮ№еҮәзҺ°еQ?/span>
еҰӮпјҡеQ?/span>M=3еQ?/span>
B+зҡ„жҗңзҙўдёҺB-ж ‘д№ҹеҹәжң¬зӣёеҗҢеQҢеҢәеҲ«жҳҜB+ж ‘еҸӘжңүиҫҫеҲ°еҸ¶еӯҗз»“зӮТҺүҚе‘ҪдёӯеQ?/span>B-ж ‘еҸҜд»ҘеңЁйқһеҸ¶еӯҗз»“зӮ№е‘ҪдёӯпјүеQҢе…¶жҖ§иғҪд№ҹзӯүд»·дәҺеңЁе…ій”®еӯ—е…ЁйӣҶеҒҡдёҖӢЖЎдәҢеҲҶжҹҘжүҫпјӣ
B+зҡ„зү№жҖ§пјҡ
1.жүҖжңүе…ій”®еӯ—йғҪеҮәзҺ°еңЁеҸ¶еӯҗҫl“зӮ№зҡ„й“ҫиЎЁдёӯеQҲзЁ еҜҶзғҰеј•пјүеQҢдё”й“ҫиЎЁдёӯзҡ„е…ій”®еӯ—жҒ°еҘҪжҳҜжңүеәҸзҡ„пјӣ
2.дёҚеҸҜиғҪеңЁйқһеҸ¶еӯҗз»“зӮ№е‘Ҫдёӯпјӣ
3.йқһеҸ¶еӯҗз»“зӮ№зӣёеҪ“дәҺжҳҜеҸ¶еӯҗз»“зӮ№зҡ„зҙўеј•еQҲзЁҖз–ҸзғҰеј•пјүеQҢеҸ¶еӯҗз»“зӮ№зӣёеҪ“дәҺжҳҜеӯҳеӮЁпјҲе…ій”®еӯ—пјүж•°жҚ®зҡ„ж•°жҚ®еұӮеQ?/span>
4.жӣҙйҖӮеҗҲж–Үдҡgзҙўеј•ҫpИқ»ҹеQ?/span>
B*ж ?/span>
жҳ?/span>B+ж ‘зҡ„еҸҳдҪ“еQҢеңЁB+ж ‘зҡ„йқһж №е’ҢйқһеҸ¶еӯҗҫl“зӮ№еҶҚеўһеҠ жҢҮеҗ‘е…„ејҹзҡ„жҢҮй’ҲеQ?/span>
B*ж ‘е®ҡд№үдәҶйқһеҸ¶еӯҗз»“зӮ№е…ій”®еӯ—дёӘж•°иҮӣ_°‘дё?/span>(2/3)*MеQҢеҚіеқ—зҡ„жңҖдҪҺдӢЙз”ЁзҺҮдё?/span>2/3еQҲд»Јжӣ?/span>B+ж ‘зҡ„1/2еQүпјӣ
B+ж ‘зҡ„еҲҶиЈӮеQҡеҪ“дёҖдёӘз»“зӮТҺ»Ўж—УһјҢеҲҶй…ҚдёҖдёӘж–°зҡ„з»“зӮ№пјҢтq¶е°ҶеҺҹз»“зӮ№дёӯ1/2зҡ„ж•°жҚ®еӨҚеҲ¶еҲ°ж–°з»“зӮ№пјҢжңҖеҗҺеңЁзҲ¶з»“зӮ№дёӯеўһеҠ ж–°з»“зӮ№зҡ„жҢҮй’ҲеQ?/span>B+ж ‘зҡ„еҲҶиЈӮеҸӘеӘ„е“ҚеҺҹҫl“зӮ№е’ҢзҲ¶ҫl“зӮ№еQҢиҖҢдёҚдјҡеӘ„е“Қе…„ејҹз»“зӮ№пјҢжүҖд»Ҙе®ғдёҚйңҖиҰҒжҢҮеҗ‘е…„ејҹзҡ„жҢҮй’ҲеQ?/span>
B*ж ‘зҡ„еҲҶиЈӮеQҡеҪ“дёҖдёӘз»“зӮТҺ»Ўж—УһјҢеҰӮжһңе®ғзҡ„дёӢдёҖдёӘе…„ејҹз»“зӮТҺңӘж»ЎпјҢйӮЈд№Ҳһ®ҶдёҖйғЁеҲҶж•°жҚ®ҝUХdҲ°е…„ејҹҫl“зӮ№дёӯпјҢеҶҚеңЁеҺҹз»“зӮТҺҸ’е…Ҙе…ій”®еӯ—еQҢжңҖеҗҺдҝ®ж”№зҲ¶ҫl“зӮ№дёӯе…„ејҹз»“зӮ№зҡ„е…ій”®еӯ—пјҲеӣ дШ“е…„ејҹҫl“зӮ№зҡ„е…ій”®еӯ—иҢғеӣҙж”№еҸҳдәҶпјүеQӣеҰӮжһңе…„ејҹд№ҹж»ЎдәҶеQҢеҲҷеңЁеҺҹҫl“зӮ№дёҺе…„ејҹз»“зӮ№д№Ӣй—ҙеўһеҠ ж–°ҫl“зӮ№еQҢеЖҲеҗ„еӨҚеҲ?/span>1/3зҡ„ж•°жҚ®еҲ°ж–°з»“зӮ№пјҢжңҖеҗҺеңЁзҲ¶з»“зӮ№еўһеҠ ж–°ҫl“зӮ№зҡ„жҢҮй’Ҳпјӣ
жүҖд»ҘпјҢB*ж ‘еҲҶй…Қж–°ҫl“зӮ№зҡ„жҰӮзҺҮжҜ”B+ж ‘иҰҒдҪҺпјҢҪIәй—ҙдҪҝз”ЁзҺҮжӣҙй«ҳпјӣ
һ®Ҹз»“
Bж ‘пјҡдәҢеҸүж ‘пјҢжҜҸдёӘҫl“зӮ№еҸӘеӯҳеӮЁдёҖдёӘе…ій”®еӯ—еQҢзӯүдәҺеҲҷе‘ҪдёӯеQҢе°ҸдәҺиө°е·Ұз»“зӮ№пјҢеӨ§дәҺиө°еҸіҫl“зӮ№еQ?/span>
B-ж ‘пјҡеӨҡиө\жҗңзғҰж ‘пјҢжҜҸдёӘҫl“зӮ№еӯҳеӮЁM/2еҲ?/span>MдёӘе…ій”®еӯ—еQҢйқһеҸ¶еӯҗҫl“зӮ№еӯҳеӮЁжҢҮеҗ‘е…ій”®еӯ—иҢғеӣҙзҡ„еӯҗз»“зӮ№пјӣ
жүҖжңүе…ій”®еӯ—еңЁж•ҙйў—ж ‘дёӯеҮәзҺҺНјҢдё”еҸӘеҮәзҺ°дёҖӢЖЎпјҢйқһеҸ¶еӯҗз»“зӮ№еҸҜд»Ҙе‘Ҫдёӯпјӣ
B+ж ‘пјҡең?/span>B-ж ‘еҹәјӢҖдёҠпјҢдёәеҸ¶еӯҗз»“зӮ№еўһеҠ й“ҫиЎЁжҢҮй’ҲпјҢжүҖжңүе…ій”®еӯ—йғҪеңЁеҸ¶еӯҗҫl“зӮ№дёӯеҮәзҺҺНјҢйқһеҸ¶еӯҗз»“зӮ№дҪңдёәеҸ¶еӯҗз»“зӮ№зҡ„зҙўеј•еQ?/span>B+ж ‘жҖАLҳҜеҲ°еҸ¶еӯҗз»“зӮТҺүҚе‘ҪдёӯеQ?/span>
B*ж ‘пјҡең?/span>B+ж ‘еҹәјӢҖдёҠпјҢдёәйқһеҸ¶еӯҗҫl“зӮ№д№ҹеўһеҠ й“ҫиЎЁжҢҮй’ҲпјҢһ®Ҷз»“зӮ№зҡ„жңҖдҪҺеҲ©з”ЁзҺҮд»?/span>1/2жҸҗй«ҳеҲ?/span>2/3гҖ?/span>
иҪ¬иҮӘ: http://blog.csdn.net/manesking/archive/2007/02/09/1505979.aspx