真的非常想再現(xiàn)那串算法,于是自己開始推敲。我來談談我推敲的過程。
命題:給定整數(shù)x,y,計算較小值m。
兩個數(shù)的差異,在于他們的差,于是想到計算z = x - y,我想也許可以利用這個中間值,利用一些巧妙的位運算求出,可是貌似還是比較困難。于是我打算重新理一下思路:
可能出現(xiàn)的情況:(暫時忽略特殊情況 z = 0)
1. x < y
z < 0
就是要找到一個函數(shù)f,滿足f(y , z) = x
2. x > y
z > 0
就需要這個f不僅滿足1,而且滿足此時f(y , z) = y
因為算法的目的是使用加減法、位運算這些基本運算,盡可能簡單的計算。所以我選擇了加法運算
y + g(z) = x , z = x - y < 0;
y + g(z) = y , z = x - y > 0;
最終變成尋求一元函數(shù)g
就是
g(z) = z, z < 0
g(z) = 0, z > 0
也就是要找到一個一元分段函數(shù),而且需要運算簡單,于是我想到了g(z) = (z >> 31) & z
如果z < 0,z>>31得到的是FFFFFFFF,再與上一個z,還是z,
如果z > 0, z>>31得到的是0000000,最終還是0
所以最終的算法是
z = x - y
m = ((z >> 31) & z) + y;
這個算法應該跟當初看到的比較接近了。它的優(yōu)點很顯然,全部是最基本的運算,而且不包含控制指令,而且完全可以直接由寄存器計算完成,效率很高。
算法本身并非什么驚天地泣鬼神大算法,而且在編譯器里肯定會有自己做這樣的優(yōu)化,其實最讓我欣慰的是我這次的思路,思路非常清晰,很久沒有動腦子的我,居然還能這么思考,我已經很高興了。其中主要包含兩種思想:分類討論、降低元數(shù)(降二元為一元)。這也是使用非常廣泛的方法了,前者主要幫助理清思路,后者主要降低復雜度。
Updated:
之前用的是z>>32,用gcc編譯會出現(xiàn)一個警告:
]]>
Aho-Corasick算法實踐
摘要:Aho-Corasick算法可以在文本串中識別一組關鍵字,所需時間和文本長度以及所有關鍵字的總長度成正比。該算法使用了一種稱為“trie”的特殊形式的狀態(tài)裝換圖。Trie是一個樹形結構的狀態(tài)裝換圖,從一個結點到它的各個子結點的邊上有不同的標號。Trie的葉子結點表示識別到的關鍵字。
在這里,將著重討論算法的實現(xiàn)。算法包含兩個部分,一是經典的KMP算法,二是KMP的擴展算法Aho-Corasick算法。前者實現(xiàn)單關鍵字的模式匹配,后者實現(xiàn)多關鍵字的匹配。(參考龍書詞法分析部分內容)
【源代碼:http://www.shnenglu.com/Files/yefeng/ACKMP.rar(vc9.0下測試通過) 】
一、經典KMP算法
當初,初學KMP算法時,總是通過反復的舉例去理解,沒有一種好的表達方式,而龍書描述這個算法使用了trie樹,也就是一個單鏈的狀態(tài)轉換圖。如模式b0b1...bn-1,trie樹如下: 
對模式串定義失效函數(shù)f:x->y,x,y in S,描述狀態(tài)轉移,f(s)表示在狀態(tài)s處,當下一個字符不是bs時轉向狀態(tài)f(s)繼續(xù)匹配。因此設置f(s)成為關鍵問題。
f(s)的存在其實主要是為了消除回溯。細節(jié)就不再多說了,這里只從原理上簡單說明。
設模式串為W,用文法描述,U、V表示W的一部分,w表示一個字符:
W -> UwV,
當U識別完成后,進入狀態(tài)s,識別w時,發(fā)現(xiàn)到來的字符不等于w,則需要轉向狀態(tài)f(s),f(s)到哪里去找呢?
那就要看U是什么樣子了。不管什么情況,只要U非空串,總可以表示成:
U -> uXu,或 U -> u,或U-> uXx,(x != u)
可以發(fā)現(xiàn),前綴u是,如果后綴也是u,意味著主串中u已經被識別,如果還從模式串頭匹配u無疑是多余的,所以f(s)應該是識別前綴u后進入的狀態(tài)。然后再匹配下一個字符。而滿足條件的u可能會有多個,所以總是選擇最長的那個。偽代碼如下:
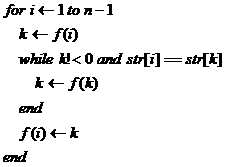
到此為止,應該算是可以結束KMP了,但實際情況下還可以對f函數(shù)進行優(yōu)化。很多書本上描述的next數(shù)組就可以從f函數(shù)推導過來。
其實也顯然,設狀態(tài)s接收字符w,當與輸入字符c不等于c時,轉向狀態(tài)t,倘若t狀態(tài)也只接收字符w,顯然再次比較w與c是多余的,之后必然再次轉向狀態(tài)f(t)。在運行的時候,這些狀態(tài)轉換時沒有意義的,可以在構造f之后,直接將f(s)設置為f(t)提高運行效率(不過此時f函數(shù)的意義已經不同了)。f優(yōu)化如下:
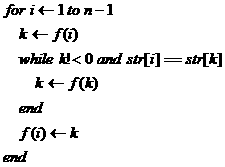
二、多關鍵字匹配與Aho-Corasick算法
Aho和Corasick對KMP算法進行了推廣,使它可以在一個文本串識別一個關鍵字集合中的任何關鍵字。在這種情況下,trie是一棵真正的樹,從其根結點開始就會出現(xiàn)分支。如果一個字符串是某個關鍵字的前綴,那么在trie中就又一個和該字符串對應的狀態(tài)。如關鍵字集合{he,she,his,hers},trie樹如下:
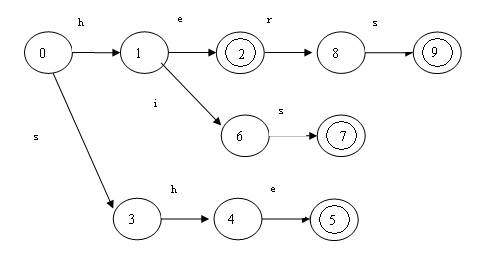
類似的,仍然構造類似KMP算法中那樣的實效函數(shù)。對于上面的例子,失效函數(shù)如下:
|
s |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
f(s) |
-1 |
0 |
0 |
0 |
1 |
2 |
0 |
3 |
0 |
3 |
1.構造失效函數(shù)
類似KMP算法,同樣采用實效實效函數(shù)推進的方法,假設當前狀態(tài)為s,s的一個孩子結點的根結點根節(jié)點t狀態(tài),如果當前的失效函數(shù)已知為f(s),則顯然地,f(t)必定是f(s)的孩子結點狀態(tài),所要做的就是在狀態(tài)f(s)處尋找接受字符同s->t下一個狀態(tài),如果能找到,那就是f(t),否則說明到s處匹配串的前綴長度太長,需縮減,所以需要找到更短的后綴,于是就到f(s)處繼續(xù),如果仍然找不到,則轉到f(f(s))處,形成狀態(tài)的遞歸轉移。構造中需要遍歷之前結點的所有孩子,所以需采用廣度優(yōu)先遍歷,偽代碼如下:
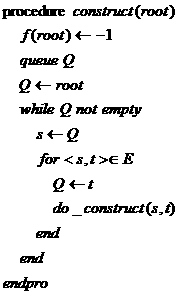
具體的構造如下:
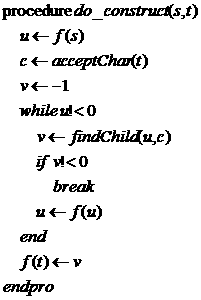
2.構造Trie樹
具體實現(xiàn)當然需要用到樹形結構了,顯然采用靜態(tài)鏈表應該是最適合的,因為樹構造完就不需要改變,而且當模式串比較多的時候可以減少內存碎片。
每一個結點有5個域:接受字符,下一個兄弟結點,第一個孩子結點,失效函數(shù)值,結點狀態(tài)。
但是有一種特殊情況,如上面的第二個圖,在進行匹配時,hers是永遠不會被匹配,因為he總是先于hers被匹配。這里就不考慮在內點狀態(tài)結束,這個問題暫時無法解決。于是可以做個特殊處理,只使用4個域,因為此時匹配成功后狀態(tài)就到了葉子結點,葉子結點不存在孩子域,這個域被浪費了,這里就可以借用一下,比如此域值為x,當x<0時,使用x xor 0x80000000表示識別到的模式串編號。
另一個棘手的問題是結點個數(shù)問題,這個數(shù)組到底多大?如何確定?
可以使用分值算法計算,先把模式串按字典順序排好序,設想n個排好序的模式串第i位排在一起,相同字符的組成一組,如AiBi…Xi,再把每組下一個字符,也就是第i+1位排在一起,相同字符的組成一組,如A’iB’I…X’i,以此遞歸運算。偽代碼如下:

3.缺點
水平有限,程序缺點很多,很多問題都沒有解決。
1.如果存在兩個模式串,一個是另一個的子串,那么后者將無法被匹配。
2.無法處理動態(tài)決定大小寫敏感性
3.不夠完整,只能向后匹配
]]>