InterLockedIncrement
举个例子�Q�如果一个变�?Long value =0;
首先说一下正常情况下的加减操作:value+=1�Q?/p>
1�Q�系�l�从Value的空间取出��|���q�动态生成一个空间来存储取出来的��|��
2�Q�将取出来的值和1作加法,�q�且���和攑֛�Value的空间覆盖掉原倹{��加法结束�?/p>
如果此时有两个Thread �Q�分别记作threadA�Q�threadB�?/p>
1�Q�threadA���Value从存储空间取出,�?�Q?/p>
2�Q�threadB���Value从存储空间取出,�?�Q?/p>
3�Q�threadA���取出来的值和1作加法,�q�且���和攑֛�Value的空间覆盖掉原倹{��加法结束,Value=1�?/p>
4�Q�threadB���取出来的值和1作加法,�q�且���和攑֛�Value的空间覆盖掉原倹{��加法结束,Value=1�?/p>
最后Value =1 �Q�而正���应该是2�Q�这���是问题的所在,InterLockedIncrement 能够保证在一个线�E�访问变量时其它�U�程不能讉K���?br>例:如果 static long addref=0; �?InterlockedIncrement(&addref); �?addref=1
InterLockedDecrement
LONG InterlockedDecrement(
LPLONG lpAddend // variable address
);
属于互锁函数�Q�用在同一�q�程内,需要对�׃�n的一个变量,做减法的时候,
防止其他�U�程讉K���q�个变量�Q�是实现�U�程同步的一�U�办法(互锁函数�Q?
首先要理解多�U�程同步�Q�共享资源(同时讉K��全局变量的问题)�Q�否则就难以理解�?nbsp;
result = InterlockedDecrement�Q?amp;SomeInt�Q?nbsp;
如果不考虑多线�E�其实就�?nbsp; result = SomeInt - 1;
但是考虑到多�U�程问题���复杂了一些。就是说如果惌���得到我预期的�l�果�q�不�Ҏ���?nbsp;
result = SomeInt - 1�Q?nbsp;
举例�?
SomeInt如果==1;
预期的结果result当然==0;
但是,如果SomeInt是一个全�E�共享的全局变量情况��׃��一样了�?nbsp;
C语言�?result = SomeInt - 1�Q?
在实际的执行�q�程中,有好几条指��o�Q�在指��o执行�q�程中,其它�U�程可能改变SomeInt��|��使真正的�l�果与你预期的不一致�?nbsp;
所以InterlockedDecrement(&SomeInt)的执行过�E�是�q�样�?nbsp;
{
__���止其他�U�程讉K�� (&SomeInt) �q�个地址
SomeInt --;
move EAX, someInt; // 讑֮��q�回�?C++函数的返回�?nbsp; 都放在EAX�?
__开攑օ�他线�E�访�?nbsp; (&SomeInt) �q�个地址
}
但是实际上只需要几条指令加前缀���可以完成,以上说明是放大的�?nbsp;
你也�怼���_���q�有必要�? 一般来��_��发生错误的概率不大,但是防范��L��必要�?
]]>
#define _ThreadPool_H_
#pragma warning(disable: 4530)
#pragma warning(disable: 4786)
#include <cassert>
#include <vector>
#include <queue>
#include <windows.h>
class ThreadJob //工作基类
{
public:
//供线�E�池调用的虚函数
virtual void DoJob(void *pPara) = 0;
};
class ThreadPool
{
public:
//dwNum �U�程池规�?br> ThreadPool(DWORD dwNum = 4) : _lThreadNum(0), _lRunningNum(0)
{
InitializeCriticalSection(&_csThreadVector);
InitializeCriticalSection(&_csWorkQueue);
_EventComplete = CreateEvent(0, false, false, NULL);
_EventEnd = CreateEvent(0, true, false, NULL);
_SemaphoreCall = CreateSemaphore(0, 0, 0x7FFFFFFF, NULL);
_SemaphoreDel = CreateSemaphore(0, 0, 0x7FFFFFFF, NULL);
assert(_SemaphoreCall != INVALID_HANDLE_VALUE);
assert(_EventComplete != INVALID_HANDLE_VALUE);
assert(_EventEnd != INVALID_HANDLE_VALUE);
assert(_SemaphoreDel != INVALID_HANDLE_VALUE);
AdjustSize(dwNum <= 0 ? 4 : dwNum);
}
~ThreadPool()
{
DeleteCriticalSection(&_csWorkQueue);
CloseHandle(_EventEnd);
CloseHandle(_EventComplete);
CloseHandle(_SemaphoreCall);
CloseHandle(_SemaphoreDel);
vector<ThreadItem*>::iterator iter;
for(iter = _ThreadVector.begin(); iter != _ThreadVector.end(); iter++)
{
if(*iter)
delete *iter;
}
DeleteCriticalSection(&_csThreadVector);
}
//调整�U�程池规�?br> int AdjustSize(int iNum)
{
if(iNum > 0)
{
ThreadItem *pNew;
EnterCriticalSection(&_csThreadVector);
for(int _i=0; _i<iNum; _i++)
{
_ThreadVector.push_back(pNew = new ThreadItem(this));
assert(pNew);
pNew->_Handle = CreateThread(NULL, 0, DefaultJobProc, pNew, 0, NULL);
assert(pNew->_Handle);
}
LeaveCriticalSection(&_csThreadVector);
}
else
{
iNum *= -1;
ReleaseSemaphore(_SemaphoreDel, iNum > _lThreadNum ? _lThreadNum : iNum, NULL);
}
return (int)_lThreadNum;
}
//调用�U�程�?br> void Call(void (*pFunc)(void *), void *pPara = NULL)
{
assert(pFunc);
EnterCriticalSection(&_csWorkQueue);
_JobQueue.push(new JobItem(pFunc, pPara));
LeaveCriticalSection(&_csWorkQueue);
ReleaseSemaphore(_SemaphoreCall, 1, NULL);
}
//调用�U�程�?br> inline void Call(ThreadJob * p, void *pPara = NULL)
{
Call(CallProc, new CallProcPara(p, pPara));
}
//�l�束�U�程�? �q�同步等�?br> bool EndAndWait(DWORD dwWaitTime = INFINITE)
{
SetEvent(_EventEnd);
return WaitForSingleObject(_EventComplete, dwWaitTime) == WAIT_OBJECT_0;
}
//�l�束�U�程�?br> inline void End()
{
SetEvent(_EventEnd);
}
inline DWORD Size()
{
return (DWORD)_lThreadNum;
}
inline DWORD GetRunningSize()
{
return (DWORD)_lRunningNum;
}
bool IsRunning()
{
return _lRunningNum > 0;
}
protected:
//工作�U�程
static DWORD WINAPI DefaultJobProc(LPVOID lpParameter = NULL)
{
ThreadItem *pThread = static_cast<ThreadItem*>(lpParameter);
assert(pThread);
ThreadPool *pThreadPoolObj = pThread->_pThis;
assert(pThreadPoolObj);
InterlockedIncrement(&pThreadPoolObj->_lThreadNum);
HANDLE hWaitHandle[3];
hWaitHandle[0] = pThreadPoolObj->_SemaphoreCall;
hWaitHandle[1] = pThreadPoolObj->_SemaphoreDel;
hWaitHandle[2] = pThreadPoolObj->_EventEnd;
JobItem *pJob;
bool fHasJob;
for(;;)
{
DWORD wr = WaitForMultipleObjects(3, hWaitHandle, false, INFINITE);
//响应删除�U�程信号
if(wr == WAIT_OBJECT_0 + 1)
break;
//从队列里取得用户作业
EnterCriticalSection(&pThreadPoolObj->_csWorkQueue);
if(fHasJob = !pThreadPoolObj->_JobQueue.empty())
{
pJob = pThreadPoolObj->_JobQueue.front();
pThreadPoolObj->_JobQueue.pop();
assert(pJob);
}
LeaveCriticalSection(&pThreadPoolObj->_csWorkQueue);
//受到�l�束�U�程信号���定是否�l�束�U�程(�l�束�U�程信号&& 是否�q�有工作)
if(wr == WAIT_OBJECT_0 + 2 && !fHasJob)
break;
if(fHasJob && pJob)
{
InterlockedIncrement(&pThreadPoolObj->_lRunningNum);
pThread->_dwLastBeginTime = GetTickCount();
pThread->_dwCount++;
pThread->_fIsRunning = true;
pJob->_pFunc(pJob->_pPara); //�q�行用户作业
delete pJob;
pThread->_fIsRunning = false;
InterlockedDecrement(&pThreadPoolObj->_lRunningNum);
}
}
//删除自��n�l�构
EnterCriticalSection(&pThreadPoolObj->_csThreadVector);
pThreadPoolObj->_ThreadVector.erase(find(pThreadPoolObj->_ThreadVector.begin(), pThreadPoolObj->_ThreadVector.end(), pThread));
LeaveCriticalSection(&pThreadPoolObj->_csThreadVector);
delete pThread;
InterlockedDecrement(&pThreadPoolObj->_lThreadNum);
if(!pThreadPoolObj->_lThreadNum) //所有线�E�结�?br> SetEvent(pThreadPoolObj->_EventComplete);
return 0;
}
//调用用户对象虚函�?br> static void CallProc(void *pPara)
{
CallProcPara *cp = static_cast<CallProcPara *>(pPara);
assert(cp);
if(cp)
{
cp->_pObj->DoJob(cp->_pPara);
delete cp;
}
}
//用户对象�l�构
struct CallProcPara
{
ThreadJob* _pObj;//用户对象
void *_pPara;//用户参数
CallProcPara(ThreadJob* p, void *pPara) : _pObj(p), _pPara(pPara) { };
};
//用户函数�l�构
struct JobItem
{
void (*_pFunc)(void *);//函数
void *_pPara; //参数
JobItem(void (*pFunc)(void *) = NULL, void *pPara = NULL) : _pFunc(pFunc), _pPara(pPara) { };
};
//�U�程池中的线�E�结�?br> struct ThreadItem
{
HANDLE _Handle; //�U�程句柄
ThreadPool *_pThis; //�U�程池的指针
DWORD _dwLastBeginTime; //最后一�ơ运行开始时�?br> DWORD _dwCount; //�q�行�ơ数
bool _fIsRunning;
ThreadItem(ThreadPool *pthis) : _pThis(pthis), _Handle(NULL), _dwLastBeginTime(0), _dwCount(0), _fIsRunning(false) { };
~ThreadItem()
{
if(_Handle)
{
CloseHandle(_Handle);
_Handle = NULL;
}
}
};
std::queue<JobItem *> _JobQueue; //工作队列
std::vector<ThreadItem *> _ThreadVector; //�U�程数据
CRITICAL_SECTION _csThreadVector, _csWorkQueue; //工作队列临界, �U�程数据临界
HANDLE _EventEnd, _EventComplete, _SemaphoreCall, _SemaphoreDel;//�l�束通知, 完成事�g, 工作信号�Q�删除线�E�信�?br> long _lThreadNum, _lRunningNum; //�U�程�? �q�行的线�E�数
};
#endif //_ThreadPool_H_
使用说明1�Q?/p>
调用�Ҏ��
{
YourClass* yourObject = (YourClass*) p;
//

}
ThreadPool tp;
for(i=0; i<100; i++)
tp.Call(threadfunc);
ThreadPool tp(20);//20为初始线�E�池规模
tp.Call(threadfunc, lpPara);
使用时注意几点:
1. ThreadJob 没什么用�Q�直接写�U�程函数吧�?nbsp;
2. �U�程函数�Q�threadfunc�Q�的入口参数void* 可以转成自定义的�c�d��对象�Q�这个对象可以记录下�U�程�q�行中的数据�Q��ƈ讄����U�程当前状态,以此与线�E�进行交互�?/p>
3. �U�程池有一个EndAndWait函数�Q�用于让�U�程池中所有计���正常结束。有时线�E�池中的一个线�E�可能要�q�行很长旉����Q�怎么办?可以通过�U�程函数threadfunc的入口参数对象来处理�Q�比如:
{
int cmd; // cmd = 1是上�U�程停止计算�Q�正帔R��出�?br>};
threadfunc(void* p) {
YourClass* yourObject = (YourClass*)p;
while (true) {
// do some calculation
if (yourClass->cmd == 1)
break;
}
}
在主�U�程中设�|�yourClass->cmd = 1�Q�该�U�程��׃��自然�l�束�?/p>
使用说明2�Q?/p>
void threadfunc(void *p)
{
//
}
ThreadPool tp;
for(i=0; i<100; i++)
tp.Call(threadfunc);
ThreadPool tp(20);//20为初始线�E�池规模
tp.Call(threadfunc, lpPara);
tp.AdjustSize(50);//增加50
tp.AdjustSize(-30);//减少30
{
public:
virtual void DoJob(void *p)//自定义的虚函�?br> {
//
.}
};
MyThreadJob mt[10];
ThreadPool tp;
for(i=0; i<100 i++)
tp.Call(mt + i);//tp.Call(mt + i, para);
]]>
信号量内核对�?br> 互斥内核对象
分别介绍如下�Q?br>
使线�E�同�?br>
在程序中使用多线�E�时�Q�一般很���有多个�U�程能在其生命期内进行完全独立的操作。更多的情况是一些线�E�进行某些处理操作,而其他的�U�程必须对其处理�l�果�q�行了解。正常情况下对这�U�处理结果的了解应当在其处理��d��完成后进行�?br>
如果不采取适当的措施,其他�U�程往往会在�U�程处理��d���l�束前就去访问处理结果,�q�就很有可能得到有关处理�l�果的错误了解。例如,多个�U�程同时讉K��同一个全局变量�Q�如果都是读取操作,则不会出现问题。如果一个线�E�负责改变此变量的��|��而其他线�E�负责同时读取变量内容,则不能保证读取到的数据是�l�过写线�E�修改后的�?br>
��Z�����保�ȝ���E�读取到的是�l�过修改的变量,���必���d��向变量写入数据时���止其他�U�程对其的�Q何访问,直至赋��D���E�结束后再解除对其他�U�程的访问限制。象�q�种保证�U�程能了解其他线�E��Q务处理结束后的处理结果而采取的保护措施即�ؓ�U�程同步�?br>
�U�程同步是一个非常大的话题,包括�Ҏ��面面的内宏V��从大的斚w���Ԍ���U�程的同步可分用��h��式的�U�程同步和内核对象的�U�程同步两大�c�R��用��h��式中�U�程的同步方法主要有原子讉K��和��界区�{�方法。其特点是同步速度特别快,适合于对�U�程�q�行速度有严��D��求的场合�?br>
内核对象的线�E�同步则主要�׃��件、等待定时器、信号量以及信号灯等内核对象构成。由于这�U�同步机制��用了内核对象�Q���用时必须���线�E�从用户模式切换到内核模式,而这�U��{换一般要耗费�q�千个CPU周期�Q�因此同步速度较慢�Q�但在适用性上却要�q�优于用��h��式的�U�程同步方式�?br>
临界�?/strong>
临界区(Critical Section�Q�是一�D늋�占对某些�׃�n资源讉K��的代码,在�Q意时��d��允许一个线�E�对�׃�n资源�q�行讉K��。如果有多个�U�程试图同时讉K��临界区,那么在有一个线�E�进入后其他所有试图访问此临界区的�U�程���被挂�v�Q��ƈ一直持�l�到�q�入临界区的�U�程���d��。��界区在被释放后,其他�U�程可以�l�箋抢占�Q��ƈ以此辑ֈ�用原子方式操作共享资源的目的�?br>
临界区在使用时以CRITICAL_SECTION�l�构对象保护�׃�n资源�Q��ƈ分别用EnterCriticalSection�Q�)和LeaveCriticalSection�Q�)函数��L��识和释放一个��界区。所用到的CRITICAL_SECTION�l�构对象必须�l�过InitializeCriticalSection�Q�)的初始化后才能��用,而且必须���保所有线�E�中的�Q何试图访问此�׃�n资源的代码都处在此��界区的保护之下。否则��界区���不会�v到应有的作用�Q�共享资源依然有被破坏的可能�?br>
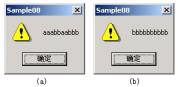
�? 使用临界��Z��持线�E�同�?br>
下面通过一�D�代码展�C�Z��临界区在保护多线�E�访问的�׃�n资源中的作用。通过两个�U�程来分别对全局变量g_cArray[10]�q�行写入操作�Q�用临界区结构对象g_cs来保持线�E�的同步�Q��ƈ在开启线�E�前对其�q�行初始化。�ؓ了��实验效果更加明显�Q�体现出临界区的作用�Q�在�U�程函数对共享资源g_cArray[10]的写入时�Q�以Sleep�Q�)函数延迟1毫秒�Q���其他�U�程同其抢占CPU的可能性增大。如果不使用临界区对其进行保护,则共享资源数据将被破坏(参见�?�Q�a�Q�所�C�������结果)�Q�而��用��界区对线�E�保持同步后则可以得到正���的�l�果�Q�参见图1�Q�b�Q�所�C�������结果)。代码实现清单附下:
| // 临界区结构对�?br>CRITICAL_SECTION g_cs; // �׃�n资源 char g_cArray[10]; UINT ThreadProc10(LPVOID pParam) { // �q�入临界�?br> EnterCriticalSection(&g_cs); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[i] = 'a'; Sleep(1); } // ���d��临界�?br> LeaveCriticalSection(&g_cs); return 0; } UINT ThreadProc11(LPVOID pParam) { // �q�入临界�?br> EnterCriticalSection(&g_cs); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[10 - i - 1] = 'b'; Sleep(1); } // ���d��临界�?br> LeaveCriticalSection(&g_cs); return 0; } …… void CSample08View::OnCriticalSection() { // 初始化��界区 InitializeCriticalSection(&g_cs); // 启动�U�程 AfxBeginThread(ThreadProc10, NULL); AfxBeginThread(ThreadProc11, NULL); // �{�待计算完毕 Sleep(300); // 报告计算�l�果 CString sResult = CString(g_cArray); AfxMessageBox(sResult); } |
在��用��界区�Ӟ��一般不允许其运行时间过长,只要�q�入临界区的�U�程�q�没有离开�Q�其他所有试图进入此临界区的�U�程都会被挂赯���进入到�{�待状态,�q�会在一定程度上影响。程序的�q�行性能。尤光���要注意的是不要将�{�待用户输入或是其他一些外界干预的操作包含��C��界区。如果进入了临界区却一直没有释放,同样也会引�v其他�U�程的长旉����{�待。换句话��_��在执行了EnterCriticalSection�Q�)语句�q�入临界区后无论发生什么,必须���保与之匚w��的LeaveCriticalSection�Q�)都能够被执行到。可以通过��d���l�构化异常处理代码来���保LeaveCriticalSection�Q�)语句的执行。虽然��界区同步速度很快�Q�但却只能用来同步本�q�程内的�U�程�Q�而不可用来同步多个进�E�中的线�E��?br>
MFC��Z��界区提供有一个CCriticalSection�c�,使用该类�q�行�U�程同步处理是非常简单的�Q�只需在线�E�函��C��用CCriticalSection�c�L��员函数Lock�Q�)和UnLock�Q�)标定�����保护代码片段卛_��。对于上�q�C��码,可通过CCriticalSection�c�d��其改写如下:
| // MFC临界区类对象 CCriticalSection g_clsCriticalSection; // �׃�n资源 char g_cArray[10]; UINT ThreadProc20(LPVOID pParam) { // �q�入临界�?br> g_clsCriticalSection.Lock(); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[i] = 'a'; Sleep(1); } // ���d��临界�?br> g_clsCriticalSection.Unlock(); return 0; } UINT ThreadProc21(LPVOID pParam) { // �q�入临界�?br> g_clsCriticalSection.Lock(); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[10 - i - 1] = 'b'; Sleep(1); } // ���d��临界�?br> g_clsCriticalSection.Unlock(); return 0; } …… void CSample08View::OnCriticalSectionMfc() { // 启动�U�程 AfxBeginThread(ThreadProc20, NULL); AfxBeginThread(ThreadProc21, NULL); // �{�待计算完毕 Sleep(300); // 报告计算�l�果 CString sResult = CString(g_cArray); AfxMessageBox(sResult); } |
���理事�g内核对象
在前面讲�q�线�E�通信时曾使用�q�事件内核对象来�q�行�U�程间的通信�Q�除此之外,事�g内核对象也可以通过通知操作的方式来保持�U�程的同步。对于前面那�D���用��界区保持�U�程同步的代码可用事件对象的�U�程同步�Ҏ��改写如下�Q?br>
|
// 事�g句柄 |
在创建线�E�前�Q�首先创��Z��个可以自动复位的事�g内核对象hEvent�Q�而线�E�函数则通过WaitForSingleObject�Q�)�{�待函数无限�{�待hEvent的置位,只有在事件置位时WaitForSingleObject�Q�)才会�q�回�Q�被保护的代码将得以执行。对于以自动复位方式创徏的事件对象,在其�|�位后一被WaitForSingleObject�Q�)�{�待到就会立卛_��位,也就是说在执行ThreadProc12�Q�)中的受保护代码时�Q�事件对象已�l�是复位状态的�Q�这时即使有ThreadProc13�Q�)对CPU的抢占,也会�׃��WaitForSingleObject�Q�)没有hEvent的置位而不能���l�执行,也就没有可能破坏受保护的�׃�n资源。在ThreadProc12�Q�)中的处理完成后可以通过SetEvent�Q�)对hEvent的置位而允许ThreadProc13�Q�)对共享资源g_cArray的处理。这里SetEvent�Q�)所��L��作用可以看作是对某项特定��d��完成的通知�?br>
使用临界区只能同步同一�q�程中的�U�程�Q�而��用事件内核对象则可以对进�E�外的线�E�进行同步,其前提是得到�Ҏ��事�g对象的访问权。可以通过OpenEvent�Q�)函数获取得到�Q�其函数原型为:
| HANDLE OpenEvent( DWORD dwDesiredAccess, // 讉K��标志 BOOL bInheritHandle, // �l�承标志 LPCTSTR lpName // 指向事�g对象名的指针 ); |
如果事�g对象已创建(在创��Z��件时需要指定事件名�Q�,函数���返回指定事件的句柄。对于那些在创徏事�g时没有指定事件名的事件内核对象,可以通过使用内核对象的��承性或是调用DuplicateHandle�Q�)函数来调用CreateEvent�Q�)以获得对指定事�g对象的访问权。在获取到访问权后所�q�行的同步操作与在同一个进�E�中所�q�行的线�E�同步操作是一��L���?br>
如果需要在一个线�E�中�{�待多个事�g�Q�则用WaitForMultipleObjects�Q�)来等待。WaitForMultipleObjects�Q�)与WaitForSingleObject�Q�)�c�M���Q�同时监视位于句柄数�l�中的所有句柄。这些被监视对象的句柄��n有��^�{�的优先权,��M��一个句柄都不可能比其他句柄��h��更高的优先权。WaitForMultipleObjects�Q�)的函数原型�ؓ�Q?br>
| DWORD WaitForMultipleObjects( DWORD nCount, // �{�待句柄�?br> CONST HANDLE *lpHandles, // 句柄数组首地址 BOOL fWaitAll, // �{�待标志 DWORD dwMilliseconds // �{�待旉���间隔 ); |
参数nCount指定了要�{�待的内核对象的数目�Q�存放这些内核对象的数组由lpHandles来指向。fWaitAll�Ҏ��定的�q�nCount个内核对象的两种�{�待方式�q�行了指定,为TRUE时当所有对象都被通知时函数才会返回,为FALSE则只要其中�Q何一个得到通知���可以返回。dwMilliseconds在这里的作用与在WaitForSingleObject�Q�)中的作用是完全一致的。如果等待超�Ӟ��函数���返回WAIT_TIMEOUT。如果返回WAIT_OBJECT_0到WAIT_OBJECT_0+nCount-1中的某个��|��则说明所有指定对象的状态均为已通知状态(当fWaitAll为TRUE�Ӟ��或是用以减去WAIT_OBJECT_0而得到发生通知的对象的索引�Q�当fWaitAll为FALSE�Ӟ��。如果返回值在WAIT_ABANDONED_0与WAIT_ABANDONED_0+nCount-1之间�Q�则表示所有指定对象的状态均为已通知�Q�且其中臛_��有一个对象是被丢弃的互斥对象�Q�当fWaitAll为TRUE�Ӟ���Q�或是用以减去WAIT_OBJECT_0表示一个等待正常结束的互斥对象的烦引(当fWaitAll为FALSE�Ӟ���?下面�l�出的代码主要展�C�Z��对WaitForMultipleObjects�Q�)函数的��用。通过对两个事件内核对象的�{�待来控制线�E��Q务的执行与中途退出:
| // 存放事�g句柄的数�l?br>HANDLE hEvents[2]; UINT ThreadProc14(LPVOID pParam) { // �{�待开启事�?br> DWORD dwRet1 = WaitForMultipleObjects(2, hEvents, FALSE, INFINITE); // 如果开启事件到辑ֈ��U�程开始执行�Q�?br> if (dwRet1 == WAIT_OBJECT_0) { AfxMessageBox("�U�程开始工�?"); while (true) { for (int i = 0; i < 10000; i++); // 在�Q务处理过�E�中�{�待�l�束事�g DWORD dwRet2 = WaitForMultipleObjects(2, hEvents, FALSE, 0); // 如果�l�束事�g�|�位则立即终止�Q务的执行 if (dwRet2 == WAIT_OBJECT_0 + 1) break; } } AfxMessageBox("�U�程退�?"); return 0; } …… void CSample08View::OnStartEvent() { // 创徏�U�程 for (int i = 0; i < 2; i++) hEvents[i] = CreateEvent(NULL, FALSE, FALSE, NULL); // 开启线�E?br> AfxBeginThread(ThreadProc14, NULL); // 讄���事�g0(开启事�? SetEvent(hEvents[0]); } void CSample08View::OnEndevent() { // 讄���事�g1(�l�束事�g) SetEvent(hEvents[1]); } |
MFC��Z��件相兛_��理也提供了一个CEvent�c�,共包含有除构造函数外�?个成员函数PulseEvent�Q�)、ResetEvent�Q�)、SetEvent�Q�)和UnLock�Q�)。在功能上分别相当与Win32 API的PulseEvent�Q�)、ResetEvent�Q�)、SetEvent�Q�)和CloseHandle�Q�)�{�函数。而构造函数则履行了原CreateEvent�Q�)函数创徏事�g对象的职责,其函数原型�ؓ�Q?br>
| CEvent(BOOL bInitiallyOwn = FALSE, BOOL bManualReset = FALSE, LPCTSTR lpszName = NULL, LPSECURITY_ATTRIBUTES lpsaAttribute = NULL ); |
按照此缺省设�|�将创徏一个自动复位、初始状态�ؓ复位状态的没有名字的事件对象。封装后的CEvent�c�M��用�v来更加方便,�?卛_���C�Z��CEvent�c�d��A、B两线�E�的同步�q�程�Q?br>
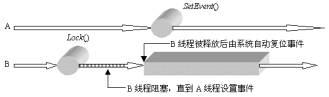
�? CEvent�c�d���U�程的同步过�E�示�?br>
B�U�程在执行到CEvent�c�L��员函数Lock�Q�)时将会发生阻塞,而A�U�程此时则可以在没有B�U�程�q�扰的情况下对共享资源进行处理,�q�在处理完成后通过成员函数SetEvent�Q�)向B发出事�g�Q���其被释放�Q�得以对A先前已处理完毕的�׃�n资源�q�行操作。可见,使用CEvent�c�d���U�程的同步方法与通过API函数�q�行�U�程同步的处理方法是基本一致的。前面的API处理代码可用CEvent�c�d��其改写�ؓ�Q?br>
| // MFC事�g�c�d���?br>CEvent g_clsEvent; UINT ThreadProc22(LPVOID pParam) { // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[i] = 'a'; Sleep(1); } // 事�g�|�位 g_clsEvent.SetEvent(); return 0; } UINT ThreadProc23(LPVOID pParam) { // �{�待事�g g_clsEvent.Lock(); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[10 - i - 1] = 'b'; Sleep(1); } return 0; } …… void CSample08View::OnEventMfc() { // 启动�U�程 AfxBeginThread(ThreadProc22, NULL); AfxBeginThread(ThreadProc23, NULL); // �{�待计算完毕 Sleep(300); // 报告计算�l�果 CString sResult = CString(g_cArray); AfxMessageBox(sResult); } |
信号量内核对�?br>
信号量(Semaphore�Q�内核对象对�U�程的同步方式与前面几种�Ҏ��不同�Q�它允许多个�U�程在同一时刻讉K��同一资源�Q�但是需要限制在同一时刻讉K��此资源的最大线�E�数目。在用CreateSemaphore�Q�)创徏信号量时卌���同时指出允许的最大资源计数和当前可用资源计数。一般是���当前可用资源计数设�|��ؓ最大资源计敎ͼ�每增加一个线�E�对�׃�n资源的访问,当前可用资源计数��׃���?�Q�只要当前可用资源计数是大于0的,���可以发��Z��号量信号。但是当前可用计数减���到0时则说明当前占用资源的线�E�数已经辑ֈ�了所允许的最大数目,不能在允许其他线�E�的�q�入�Q�此时的信号量信号将无法发出。线�E�在处理完共享资源后�Q�应在离开的同旉���过ReleaseSemaphore�Q�)函数���当前可用资源计数加1。在��M��时候当前可用资源计数决不可能大于最大资源计数�?br>
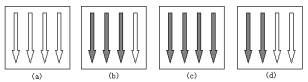
�? 使用信号量对象控制资�?br>
下面�l�合图例3来演�C�Z��号量对象对资源的控制。在�?中,以箭头和白色���头表示�׃�n资源所允许的最大资源计数和当前可用资源计数。初始如图(a�Q�所�C�,最大资源计数和当前可用资源计数均�ؓ4�Q�此后每增加一个对资源�q�行讉K��的线�E�(用黑色箭头表�C�)当前资源计数��׃��相应�?�Q�图�Q�b�Q�即表示的在3个线�E�对�׃�n资源�q�行讉K��时的状态。当�q�入�U�程数达�?个时�Q�将如图�Q�c�Q�所�C�,此时已达到最大资源计敎ͼ�而当前可用资源计��C��已减�?�Q�其他线�E�无法对�׃�n资源�q�行讉K��。在当前占有资源的线�E�处理完毕而退出后�Q�将会释攑և��I�间�Q�图�Q�d�Q�已有两个线�E�退出对资源的占有,当前可用计数�?�Q�可以再允许2个线�E�进入到对资源的处理。可以看出,信号量是通过计数来对�U�程讉K��资源�q�行控制的,而实际上信号量确实也被称作Dijkstra计数器�?br>
使用信号量内核对象进行线�E�同步主要会用到CreateSemaphore�Q�)、OpenSemaphore�Q�)、ReleaseSemaphore�Q�)、WaitForSingleObject�Q�)和WaitForMultipleObjects�Q�)�{�函数。其中,CreateSemaphore�Q�)用来创徏一个信号量内核对象�Q�其函数原型为:
| HANDLE CreateSemaphore( LPSECURITY_ATTRIBUTES lpSemaphoreAttributes, // 安全属性指�?br> LONG lInitialCount, // 初始计数 LONG lMaximumCount, // 最大计�?br> LPCTSTR lpName // 对象名指�?br>); |
参数lMaximumCount是一个有�W�号32位��|��定义了允许的最大资源计敎ͼ�最大取��g��能超�q?294967295。lpName参数可以为创建的信号量定义一个名字,�׃��其创建的是一个内核对象,因此在其他进�E�中可以通过该名字而得到此信号量。OpenSemaphore�Q�)函数卛_��用来�Ҏ��信号量名打开在其他进�E�中创徏的信号量�Q�函数原型如下:
| HANDLE OpenSemaphore( DWORD dwDesiredAccess, // 讉K��标志 BOOL bInheritHandle, // �l�承标志 LPCTSTR lpName // 信号量名 ); |
在线�E�离开对共享资源的处理�Ӟ��必须通过ReleaseSemaphore�Q�)来增加当前可用资源计数。否则将会出现当前正在处理共享资源的实际�U�程数�ƈ没有辑ֈ�要限制的数��|��而其他线�E�却因�ؓ当前可用资源计数�?而仍无法�q�入的情��c��ReleaseSemaphore�Q�)的函数原型�ؓ�Q?br>
| BOOL ReleaseSemaphore( HANDLE hSemaphore, // 信号量句�?br> LONG lReleaseCount, // 计数递增数量 LPLONG lpPreviousCount // 先前计数 ); |
该函数将lReleaseCount中的值添加给信号量的当前资源计数�Q�一般将lReleaseCount讄����?�Q�如果需要也可以讄���其他的倹{��WaitForSingleObject�Q�)和WaitForMultipleObjects�Q�)主要用在试图�q�入�׃�n资源的线�E�函数入口处�Q�主要用来判断信号量的当前可用资源计数是否允许本�U�程的进入。只有在当前可用资源计数值大�?�Ӟ��被监视的信号量内核对象才会得到通知�?br>
信号量的使用特点使其更适用于对Socket�Q�套接字�Q�程序中�U�程的同步。例如,�|�络上的HTTP服务器要对同一旉���内访问同一��面的用��h��加以限制�Q�这时可以�ؓ没一个用户对服务器的��面��h��讄���一个线�E�,而页面则是待保护的共享资源,通过使用信号量对�U�程的同步作用可以确保在��M��时刻无论有多���用户对某一��面�q�行讉K���Q�只有不大于讑֮�的最大用��h��目的�U�程能够�q�行讉K���Q�而其他的讉K��企图则被挂�v�Q�只有在有用户退出对此页面的讉K��后才有可能进入。下面给出的�C�Z��代码卛_���C�Z���c�M��的处理过�E�:
| // 信号量对象句�?br>HANDLE hSemaphore; UINT ThreadProc15(LPVOID pParam) { // 试图�q�入信号量关�?br> WaitForSingleObject(hSemaphore, INFINITE); // �U�程��d��处理 AfxMessageBox("�U�程一正在执行!"); // 释放信号量计�?br> ReleaseSemaphore(hSemaphore, 1, NULL); return 0; } UINT ThreadProc16(LPVOID pParam) { // 试图�q�入信号量关�?br> WaitForSingleObject(hSemaphore, INFINITE); // �U�程��d��处理 AfxMessageBox("�U�程二正在执�?"); // 释放信号量计�?br> ReleaseSemaphore(hSemaphore, 1, NULL); return 0; } UINT ThreadProc17(LPVOID pParam) { // 试图�q�入信号量关�?br> WaitForSingleObject(hSemaphore, INFINITE); // �U�程��d��处理 AfxMessageBox("�U�程三正在执�?"); // 释放信号量计�?br> ReleaseSemaphore(hSemaphore, 1, NULL); return 0; } …… void CSample08View::OnSemaphore() { // 创徏信号量对�?br> hSemaphore = CreateSemaphore(NULL, 2, 2, NULL); // 开启线�E?br> AfxBeginThread(ThreadProc15, NULL); AfxBeginThread(ThreadProc16, NULL); AfxBeginThread(ThreadProc17, NULL); } |
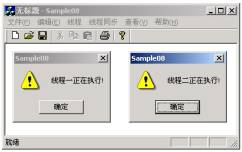
�? 开始进入的两个�U�程
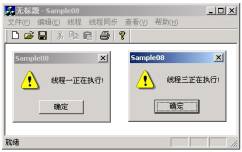
�? �U�程二退出后�U�程三才得以�q�入
上述代码在开启线�E�前首先创徏了一个初始计数和最大资源计数均�?的信号量对象hSemaphore。即在同一时刻只允�?个线�E�进入由hSemaphore保护的共享资源。随后开启的三个�U�程均试图访问此�׃�n资源�Q�在前两个线�E�试图访问共享资源时�Q�由于hSemaphore的当前可用资源计数分别�ؓ2�?�Q�此时的hSemaphore是可以得到通知的,也就是说位于�U�程入口处的WaitForSingleObject�Q�)���立卌���回,而在前两个线�E�进入到保护区域后,hSemaphore的当前资源计数减���到0�Q�hSemaphore���不再得到通知�Q�WaitForSingleObject�Q�)���线�E�挂赗���直到此前进入到保护区的�U�程退出后才能得以�q�入。图4和图5��Z���q�C��脉的�q�行�l�果。从实验�l�果可以看出�Q�信号量始终保持了同一时刻不超�q?个线�E�的�q�入�?br>
在MFC中,通过CSemaphore�c�d��信号量作了表�q�。该�c�d����h��一个构造函敎ͼ�可以构造一个信号量对象�Q��ƈ对初始资源计数、最大资源计数、对象名和安全属性等�q�行初始化,其原型如下:
| CSemaphore( LONG lInitialCount = 1, LONG lMaxCount = 1, LPCTSTR pstrName = NULL, LPSECURITY_ATTRIBUTES lpsaAttributes = NULL ); |
在构造了CSemaphore�c�d��象后�Q��Q何一个访问受保护�׃�n资源的线�E�都必须通过CSemaphore从父�c�CSyncObject�cȝ��承得到的Lock�Q�)和UnLock�Q�)成员函数来访问或释放CSemaphore对象。与前面介绍的几�U�通过MFC�c�M��持线�E�同步的�Ҏ���c�M���Q�通过CSemaphore�c�M��可以���前面的�U�程同步代码�q�行改写�Q�这两种使用信号量的�U�程同步�Ҏ��无论是在实现原理上还是从实现�l�果上都是完全一致的。下面给出经MFC改写后的信号量线�E�同步代码:
| // MFC信号量类对象 CSemaphore g_clsSemaphore(2, 2); UINT ThreadProc24(LPVOID pParam) { // 试图�q�入信号量关�?br> g_clsSemaphore.Lock(); // �U�程��d��处理 AfxMessageBox("�U�程一正在执行!"); // 释放信号量计�?br> g_clsSemaphore.Unlock(); return 0; } UINT ThreadProc25(LPVOID pParam) { // 试图�q�入信号量关�?br> g_clsSemaphore.Lock(); // �U�程��d��处理 AfxMessageBox("�U�程二正在执�?"); // 释放信号量计�?br> g_clsSemaphore.Unlock(); return 0; } UINT ThreadProc26(LPVOID pParam) { // 试图�q�入信号量关�?br> g_clsSemaphore.Lock(); // �U�程��d��处理 AfxMessageBox("�U�程三正在执�?"); // 释放信号量计�?br> g_clsSemaphore.Unlock(); return 0; } …… void CSample08View::OnSemaphoreMfc() { // 开启线�E?br> AfxBeginThread(ThreadProc24, NULL); AfxBeginThread(ThreadProc25, NULL); AfxBeginThread(ThreadProc26, NULL); } |
互斥内核对象
互斥�Q�Mutex�Q�是一�U�用途非常广泛的内核对象。能够保证多个线�E�对同一�׃�n资源的互斥访问。同临界区有些类��|��只有拥有互斥对象的线�E�才��h��讉K��资源的权限,�׃��互斥对象只有一个,因此���决定了��M��情况下此�׃�n资源都不会同时被多个�U�程所讉K��。当前占据资源的�U�程在�Q务处理完后应���拥有的互斥对象交出�Q�以便其他线�E�在获得后得以访问资源。与其他几种内核对象不同�Q�互斥对象在操作�pȝ��中拥有特�D�代码,�q�由操作�pȝ��来管理,操作�pȝ��甚至�q�允许其�q�行一些其他内核对象所不能�q�行的非常规操作。�ؓ便于理解�Q�可参照�?�l�出的互斥内核对象的工作模型�Q?br>

�? 使用互斥内核对象对共享资源的保护
图(a�Q�中的箭头�ؓ要访问资源(矩�Ş框)的线�E�,但只有第二个�U�程拥有互斥对象�Q�黑点)�q�得以进入到�׃�n资源�Q�而其他线�E�则会被排斥在外�Q�如图(b�Q�所�C�)。当此线�E�处理完�׃�n资源�q�准备离开此区域时���把其所拥有的互斥对象交出(如图�Q�c�Q�所�C�)�Q�其他�Q何一个试图访问此资源的线�E�都有机会得到此互斥对象�?br>
以互斥内核对象来保持�U�程同步可能用到的函��C��要有CreateMutex�Q�)、OpenMutex�Q�)、ReleaseMutex�Q�)、WaitForSingleObject�Q�)和WaitForMultipleObjects�Q�)�{�。在使用互斥对象前,首先要通过CreateMutex�Q�)或OpenMutex�Q�)创徏或打开一个互斥对象。CreateMutex�Q�)函数原型为:
| HANDLE CreateMutex( LPSECURITY_ATTRIBUTES lpMutexAttributes, // 安全属性指�?br> BOOL bInitialOwner, // 初始拥有�?br> LPCTSTR lpName // 互斥对象�?br>); |
参数bInitialOwner主要用来控制互斥对象的初始状态。一般多���其讄���为FALSE�Q�以表明互斥对象在创建时�q�没有�ؓ��M���U�程所占有。如果在创徏互斥对象时指定了对象名,那么可以在本�q�程其他地方或是在其他进�E�通过OpenMutex�Q�)函数得到此互斥对象的句柄。OpenMutex�Q�)函数原型为:
| HANDLE OpenMutex( DWORD dwDesiredAccess, // 讉K��标志 BOOL bInheritHandle, // �l�承标志 LPCTSTR lpName // 互斥对象�?br>); |
当目前对资源��h��讉K��权的�U�程不再需要访问此资源而要���d���Ӟ��必须通过ReleaseMutex�Q�)函数来释攑օ�拥有的互斥对象,其函数原型�ؓ�Q?br>
| BOOL ReleaseMutex(HANDLE hMutex); |
其唯一的参数hMutex为待释放的互斥对象句柄。至于WaitForSingleObject�Q�)和WaitForMultipleObjects�Q�)�{�待函数在互斥对象保持线�E�同步中所��L��作用与在其他内核对象中的作用是基本一致的�Q�也是等待互斥内核对象的通知。但是这里需要特别指出的是:在互斥对象通知引�v调用�{�待函数�q�回�Ӟ���{�待函数的返回��g��再是通常的WAIT_OBJECT_0�Q�对于WaitForSingleObject�Q�)函数�Q�或是在WAIT_OBJECT_0到WAIT_OBJECT_0+nCount-1之间的一个��|��对于WaitForMultipleObjects�Q�)函数�Q�,而是���返回一个WAIT_ABANDONED_0�Q�对于WaitForSingleObject�Q�)函数�Q�或是在WAIT_ABANDONED_0到WAIT_ABANDONED_0+nCount-1之间的一个��|��对于WaitForMultipleObjects�Q�)函数�Q�。以此来表明�U�程正在�{�待的互斥对象由另外一个线�E�所拥有�Q�而此�U�程却在使用完共享资源前���已�l�终止。除此之外,使用互斥对象的方法在�{�待�U�程的可调度性上同��用其他几�U�内核对象的�Ҏ��也有所不同�Q�其他内核对象在没有得到通知�Ӟ��受调用等待函数的作用�Q�线�E�将会挂��P��同时失去可调度性,而��用互斥的�Ҏ��却可以在�{�待的同时仍��h��可调度性,�q�也正是互斥对象所能完成的非常规操作之一�?br>
在编写程序时�Q�互斥对象多用在寚w��些�ؓ多个�U�程所讉K��的内存块的保护上�Q�可以确保�Q何线�E�在处理此内存块旉���对其拥有可靠的独占访问权。下面给出的�C�Z��代码即通过互斥内核对象hMutex对共享内存快g_cArray[]�q�行�U�程的独占访问保护。下面给出实��C��码清单:
| // 互斥对象 HANDLE hMutex = NULL; char g_cArray[10]; UINT ThreadProc18(LPVOID pParam) { // �{�待互斥对象通知 WaitForSingleObject(hMutex, INFINITE); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[i] = 'a'; Sleep(1); } // 释放互斥对象 ReleaseMutex(hMutex); return 0; } UINT ThreadProc19(LPVOID pParam) { // �{�待互斥对象通知 WaitForSingleObject(hMutex, INFINITE); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[10 - i - 1] = 'b'; Sleep(1); } // 释放互斥对象 ReleaseMutex(hMutex); return 0; } …… void CSample08View::OnMutex() { // 创徏互斥对象 hMutex = CreateMutex(NULL, FALSE, NULL); // 启动�U�程 AfxBeginThread(ThreadProc18, NULL); AfxBeginThread(ThreadProc19, NULL); // �{�待计算完毕 Sleep(300); // 报告计算�l�果 CString sResult = CString(g_cArray); AfxMessageBox(sResult); } |
互斥对象在MFC中通过CMutex�c�进行表�q�。��用CMutex�cȝ���Ҏ��非常���单,在构造CMutex�c�d��象的同时可以指明待查询的互斥对象的名字,在构造函数返回后卛_��讉K��此互斥变量。CMutex�c�M��是只含有构造函数这唯一的成员函敎ͼ�当完成对互斥对象保护资源的访问后�Q�可通过调用从父�c�CSyncObject�l�承的UnLock�Q�)函数完成对互斥对象的释放。CMutex�c�L��造函数原型�ؓ�Q?br>
| CMutex( BOOL bInitiallyOwn = FALSE, LPCTSTR lpszName = NULL, LPSECURITY_ATTRIBUTES lpsaAttribute = NULL ); |
该类的适用范围和实现原理与API方式创徏的互斥内核对象是完全�c�M��的,但要����z�的多,下面�l�出���是对前面的�C�Z��代码�l�CMutex�c�L��写后的程序实现清单:
| // MFC互斥�c�d���?br>CMutex g_clsMutex(FALSE, NULL); UINT ThreadProc27(LPVOID pParam) { // �{�待互斥对象通知 g_clsMutex.Lock(); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[i] = 'a'; Sleep(1); } // 释放互斥对象 g_clsMutex.Unlock(); return 0; } UINT ThreadProc28(LPVOID pParam) { // �{�待互斥对象通知 g_clsMutex.Lock(); // 对共享资源进行写入操�?br> for (int i = 0; i < 10; i++) { g_cArray[10 - i - 1] = 'b'; Sleep(1); } // 释放互斥对象 g_clsMutex.Unlock(); return 0; } …… void CSample08View::OnMutexMfc() { // 启动�U�程 AfxBeginThread(ThreadProc27, NULL); AfxBeginThread(ThreadProc28, NULL); // �{�待计算完毕 Sleep(300); // 报告计算�l�果 CString sResult = CString(g_cArray); AfxMessageBox(sResult); } |
���结
�U�程的��用�ɽE�序处理更够更加灉|���Q�而这�U�灵�z�d��样也会带来各�U�不���定性的可能。尤其是在多个线�E�对同一公共变量�q�行讉K��时。虽然未使用�U�程同步的程序代码在逻辑上或许没有什么问题,但�ؓ了确保程序的正确、可靠运行,必须在适当的场合采取线�E�同步措施�?/strong>
]]>