两者的主要差别是共享内存的大小
1.Posix�׃�n内存大小可通过函数ftruncate随时修改
2.System V�׃�n内存大小在创建时���已�l�确定,而且最大值根据系�l�有所不同
Posix�׃�n内存
#include <sys/mman.h> �Q�mmap�Q�munmap�Q�msync�Q�shm_open�Q�shm_unlink�Q?br />
最主要的函�? -- mmap
void* mmap(void* addr,size_t len,int prot,int flags,int fd,off_t offset)
函数���一个句柄映���到内存中,�q�个句柄可以是open的文件句柄,也可以是shm_open的共享内存区对象。当fd=-1时�ؓ匿名�׃�n内存�?br /> *nix一切皆文�g的观点,shm_open也是�?dev/shm目录下创��Z��个文件对象,�q�回对象的描�q�符�?br /> mmap���句柄作为共享内存的底层支撑对象�Q�映���到内存中,�q�样可以不通过read、write在进�E�之间共享内存。由此推���一下,�?nix的进�E�间传递数据更加原始的�Ҏ��是进�E�间��d��一个文件。但是频�J�的open、read、write、lseek�pȝ��调用会消耗过多的计算资源。所以想��C�����这个文件句柄映���到内存中,�q�样���提高了�q�程间传递数据的效率�?br />
需要注意的函数 -- msync
当修改了内存映射区的内存后,内核会在某个时刻���文件的内容更新。�ؓ了确信文件被更新�Q�调用函数msync。文件的更新可以是同步(MS_SYNC�Q�也可以是异步(MS_ASYNC�Q�。(估计�q�里也是调用了函数write更新文�g�Q?br />
System V�׃�n内存
#include <sys/shm.h> (shmget,shmat,shmdt,shmctl)
�׃��System V的共享内存有大小的限�Ӟ��所以可考虑�Q���用共享内存数�l�来解决�q�个问。虽然数�l�的大小即一个进�E�可以获取共享内存的数量也是有限�Ӟ��但是可以�~�解System V单个�׃�n内存�q�小的问题�?img src ="http://www.shnenglu.com/range/aggbug/184665.html" width = "1" height = "1" />
]]>
用于在c串haystack中查找c串needle�Q�忽略大���写。如果找到则�q�回needle串在haystack串中�W�一�ơ出现的位置的char指针
在实际的应用中如果只加上头文�Ӟ��当编译时会出�? warning: assignment makes pointer from integer without a cast
�q�是因�ؓ函数的声明在调用之后。未�l�声明的函数默认�q�回int型�?/span>
因此要在#include所�?/span>头文件之前加 #define _GNU_SOURCE �Q�以此解��x��问题�?/span>
]]>
之前没接触过�q�个�~�译宏,现在来认真学习之�?/span>
首先google�?/span>~~
原来#pragma pack有几�U��Ş式,我所接触到的�?/span>#pragma pack(n)�Q�即变量�?/span>n字节寚w���?/span>
变量寚w��在每个系�l�中是不一��L���Q�默认的寚w��方式能有效的提高cpu取指取数的速度�Q�但是可能会���费一定的�I�间。在�|�络�E�序中采�?/span>#pragma pack(1),卛_��量紧�~�,不但可以减少�|�络���量�Q�还可以兼容各种�pȝ���Q�不会因为系�l�对齐方式不同而导致解包错误�?/span>
了解了概念和优点�Q�现在我们就来测试之~
�q�_���Q?/span>CPU—Pentium E5700 内存—2G
1.操作�pȝ���Q?/span>ubuntu 11.04 32bit �~�译器:G++ 4.5.2
2.操作�pȝ���Q?/span>windows xp �~�译器:VS2010
先看�W�一个测试�?/span>
�l�构体在正常情况和紧�~�情况在以上不同环境下占用的内存大小�?/span>
2 int i;
3 short s;
4 double d;
5 char c;
6 short f;
7 }
���试�l�果为:
1�Q?br /> 
2�Q?br /> 
���试�l�果分析�Q?/span>
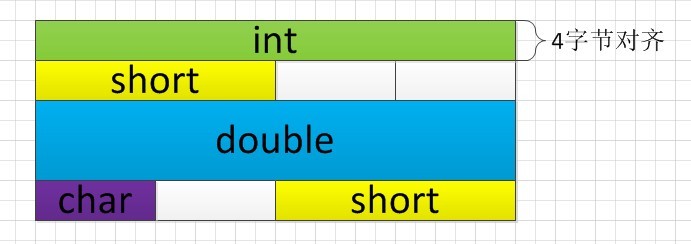
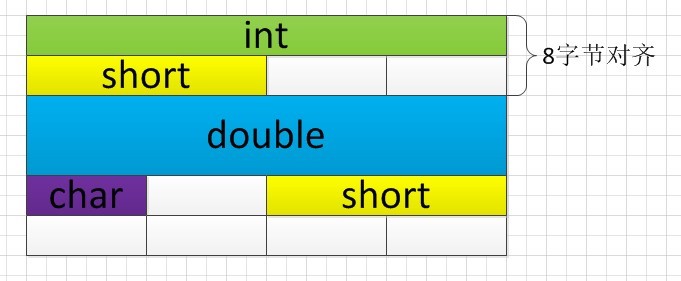
可以看出紧羃后结构体的大����ؓ15�Q�是�l�构体内�|�类型大���的和。但是在默认情况下,�l�构体的大小都是寚w��字节数的倍数�?/span>ubuntu�?/span>pack只需�?/span>20个字节,�?/span>windows�?/span>24个字节。这是因�?/span>ubuntu是以4字节寚w���Q��?/span>windows则是以最大的内置�c�d��的字节数寚w���Q�在�l�构体内最大的内置�c�d���?/span>double�Q�其大小�?/span>8个字节。他们在内存中的寚w��方式如下图:
1�Q?/span>
2�Q?/span>
�q�需注意的是�Q?/span>在对齐类型的内部都是�?/span>2字节寚w��的�?/span>
�l�论�Q?/span>在默认情况下�Q?/span>linux操作�pȝ��是以4字节寚w���Q?/span>windows操作�pȝ��则是以最大的内置�c�d��寚w���?/span>
�W�二个测�?/span>
一个结构体内包含另外一个结构体�Q�其大小的情��c�?/span>
内部的结构体�?/span>
2 short s;
3 double d;
4 }
外部的结构体�?/span>
1 struct complex _pack{
3 struct pack s;
4 double d;
5 };
我们有四�U�情况:
1. pack紧羃�Q?/span>complex _pack紧羃
2. pack紧羃�Q?/span>complex _pack默认
3. pack默认�Q?/span>complex _pack紧羃
4. pack默认�Q?/span>complex _pack默认
以下的排列均按此��序�?/span>
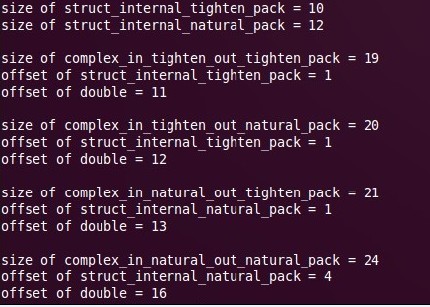
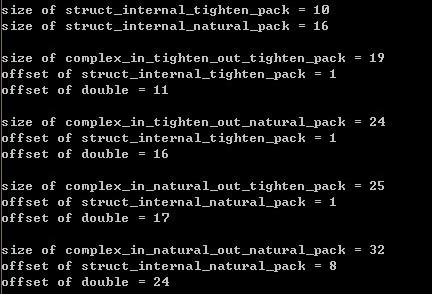
���试的结�?/span>
1�Q?/span>
2�Q?/span>
���试�l�果分析�Q?/span>
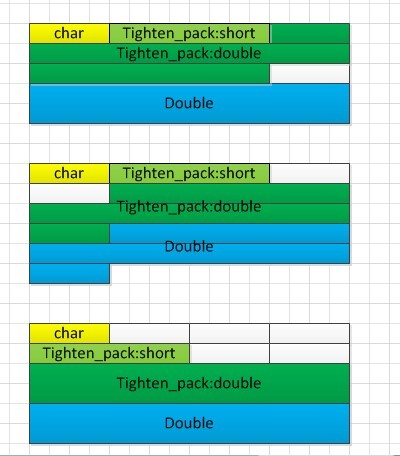
在两个操作系�l�下�Q�除了第一�U�情�?/span>----内结构体和外�l�构体都紧羃----相同之外�Q�其他三�U�情况都不相同。我们可以根据偏�Uȝ��出结构体在内存中的情��c��第一�U�情�늜�略�?/span>
1�Q?/span>
2�Q?/span>

�l�论�Q?/span>#pragma pack只媄响当前结构体的变量的寚w��情况�Q��ƈ不会影响�l�构体内部的�l�构体变量的排列情况。或者说#pragma pack的作用域只是一�?/span>。我们由�W�三�U�情况,内部�l�构体正常,外部�l�构体紧�~�,可以得出�l�构体的寚w��是按偏移计算的�?/span>
�q�里�q�有一个问题没解决�Q��ؓ什么第二种情况内部�l�构体的偏移都是1?不是4或�?�Q?/p>
]]>
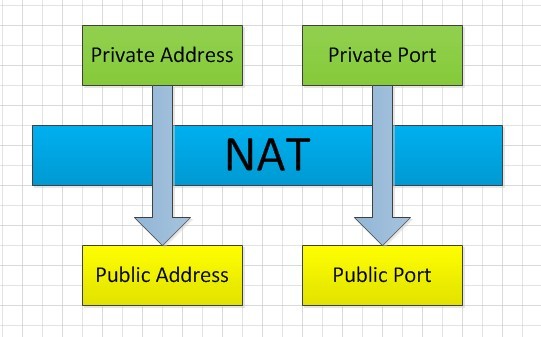
上图昄����?/span>NAT的原理�?/span>NAT���内�|�的IP替换为公�|?/span>IP�Q�将端口映射为公�|�的端口。公�|?/span>IP替换内网IP是固定的�Q?/span>NAT的不���之处在于端口的替换。因�?/span>NAT�q�没有�Ş成标准,替换�{�略有几�U�,�q�也�?/span>NAT行�ؓ的关键�?/span>
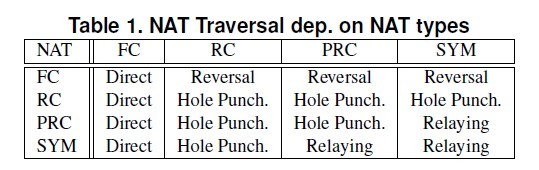
在�?/span>Behavior and Classification of NAT Devices and Implications for NAT Traversal》一文中���把端口映射的行为分成四�U�,其中包括保留端口�Q�不保留端口�Q�端口重载,端口复用。这四种分类最�l�区分了NAT的四�U�类型即Full cone NAT�Q?/span>Symmetric NAT�Q?/span>Port-Restrictes cone NAT �Q?/span>Address-Restriced cone NAT�?/span>
��Z��使覆盖网�l�中的节点相互通信�Q�我们需要进�?/span>NAT�I�越。在�?/span>A NAT Traversal Mechanism for Peer-To-Peer Networks》一文种介绍了根据两端不同的NAT�c�d��对应的四�U?/span>NAT�I�越�Ҏ��。如下图
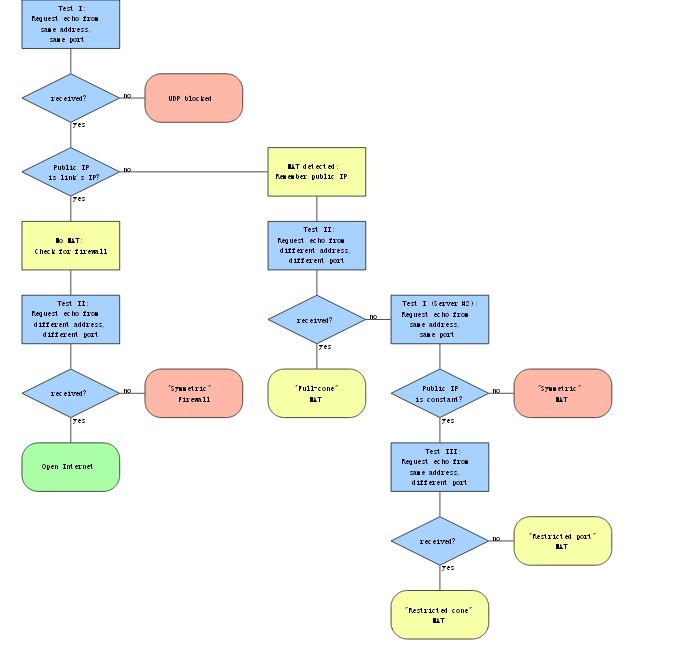
上图�?/span>STUN协议的流�E�,其主要的思想是通过STUN的回���来判断��L���?/span>NAT�c�d���?/span>
除了直接�q�接�Q�反向连接、打�z�和依赖都需要第三台��L��的帮助�?/span>
在�?/span>Characterization and Measurement of TCP Traversal through NATs and Firewalls》一文中介绍�?/span>TCP�I�越的方法。在STUNT#2�Ҏ��中,�W�三��C��机和两台需要连接的��L��都有长连接,当一斚w��要发��h���q�接�Ӟ��向第三台��L��发请求,�W�三��C��机向被请求的��L��发送邀��P��此时需要连接的��L��都向�Ҏ��发�?/span>SYN包,此时双方的防火墙都有了洞�Q�只要有一方的SYN包到辑֯�方主机,�q�接��׃��被徏立�?/span>Relay�Ҏ��需要耗费的代价太大,�?/span>P2P应用中一般会消极的处理双斚w��是对�U?/span>NAT的情��c�?/span>
]]>
]]>