#
在使用VC 2005 的開發(fā)者會遇到這樣的問題,在使用std命名空間庫函數(shù)的時候,往往會出現(xiàn)類似于下面的警告:
warning C4996: strcpy was declared deprecated
出現(xiàn)這樣的警告,是因為VC2005中認(rèn)為CRT中的一組函數(shù)如果使用不當(dāng),可能會產(chǎn)生諸如內(nèi)存泄露、緩沖區(qū)溢出、非法訪問等安全問題。這些函數(shù)如:strcpy、strcat等。
對于這些問題,VC2005建議使用這些函數(shù)的更高級的安全版本,即在這些函數(shù)名后面加了一個_s的函數(shù)。這些安全版本函數(shù)使用起來更有效,也便于識別,如:strcpy_s,calloc_s等。
當(dāng)然,如果執(zhí)意使用老版本、非安全版本函數(shù),可以使用_CRT_SECURE_NO_DEPRECATE標(biāo)記來忽略這些警告問題。辦法是在編譯選項 C/C++ | Preprocessor | Preprocessor Definitions中,增加_CRT_SECURE_NO_DEPRECATE標(biāo)記即可。
補充:
然而,本以為上面的說法是件漂亮的法子,不想用后不爽。遂用舊法:
#pragma warning(disable:4996) //全部關(guān)掉
#pragma warning(once:4996) //僅顯示一個
關(guān)于這個話題網(wǎng)上流傳的是一個相同的版本,就是那個第一項是頭文件的區(qū)別,但后面列出的頭文件只有#include沒有(估計是原版的在不斷轉(zhuǎn)載的過程中有人不小心忘了把尖括號轉(zhuǎn)義,讓瀏覽器當(dāng)html標(biāo)記解析沒了)的那個。現(xiàn)在整理了一下,以后也會不斷補充內(nèi)容。
1)頭文件
windows下winsock.h或winsock2.h
linux下netinet/in.h(大部分都在這兒),unistd.h(close函數(shù)在這兒),sys/socket.h(在in.h里已經(jīng)包含了,可以省了)
2)初始化
windows下需要用WSAStartup啟動Ws2_32.lib,并且要用#pragma comment(lib,"Ws2_32")來告知編譯器鏈接該lib。
linux下不需要
3)關(guān)閉socket
windows下closesocket(...)
linux下close(...)
4)類型
windows下SOCKET
linux下int(我喜歡用long,這樣保證是4byte,因為-1我總喜歡寫成0xFFFF)
5)獲取錯誤碼
windows下getlasterror()/WSAGetLastError()
linux下,未能成功執(zhí)行的socket操作會返回-1;如果包含了errno.h,就會設(shè)置errno變量
6)設(shè)置非阻塞
windows下ioctlsocket()
linux下fcntl(),需要頭文件fcntl.h
7)send函數(shù)最后一個參數(shù)
windows下一般設(shè)置為0
linux下最好設(shè)置為MSG_NOSIGNAL,如果不設(shè)置,在發(fā)送出錯后有可能會導(dǎo)致程序退出
8)毫秒級時間獲取
windows下GetTickCount()
linux下gettimeofday()
9)多線程
windows下包含process.h,使用_beginthread和_endthread
linux下包含pthread.h,使用pthread_create和pthread_exit
10)用IP定義一個地址(sockaddr_in的結(jié)構(gòu)的區(qū)別)
windows下addr_var.sin_addr.S_un.S_addr
linux下addr_var.sin_addr.s_addr
而且Winsock里最后那個32bit的S_addr也有幾個以聯(lián)合(Union)的形式與它共享內(nèi)存空間的成員變量(便于以其他方式賦值),而Linux的Socket沒有這個聯(lián)合,就是一個32bit的s_addr。遇到那種得到了是4個char的IP的形式(比如127一個,0一個,0一個和1一個共四個char),WinSock可以直接用4個S_b來賦值到S_addr里,而在Linux下,可以用邊向左移位(一下8bit,共四下)邊相加的方法賦值。
11)異常處理
linux下當(dāng)連接斷開,還發(fā)數(shù)據(jù)的時候,不僅send()的返回值會有反映,而且還會像系統(tǒng)發(fā)送一個異常消息,如果不作處理,系統(tǒng)會出BrokePipe,程序會退出。為此,send()函數(shù)的最后一個參數(shù)可以設(shè)MSG_NOSIGNAL,禁止send()函數(shù)向系統(tǒng)發(fā)送異常消息。
使用條件變量可以以原子方式阻塞線程,直到某個特定條件為真為止。條件變量始終與互斥鎖一起使用。
使用條件變量,線程可以以原子方式阻塞,直到滿足某個條件為止。對條件的測試是在互斥鎖(互斥)的保護下進行的。
如果條件為假,線程通常會基于條件變量阻塞,并以原子方式釋放等待條件變化的互斥鎖。如果另一個線程更改了條件,該線程可能會向相關(guān)的條件變量發(fā)出信號,從而使一個或多個等待的線程執(zhí)行以下操作:
在以下情況下,條件變量可用于在進程之間同步線程:
-
線程是在可以寫入的內(nèi)存中分配的
-
內(nèi)存由協(xié)作進程共享
調(diào)度策略可確定喚醒阻塞線程的方式。對于缺省值 SCHED_OTHER,將按優(yōu)先級順序喚醒線程。
必須設(shè)置和初始化條件變量的屬性,然后才能使用條件變量。表 4–4 列出了用于處理條件變量屬性的函數(shù)。
表 4–4 條件變量屬性
表 4–5 中顯示了定義條件變量的范圍時 Solaris 線程和 POSIX 線程之間的差異。
表 4–5 條件變量范圍比較
|
Solaris
|
POSIX
|
定義
|
|
USYNC_PROCESS
|
PTHREAD_PROCESS_SHARED
|
用于同步該進程和其他進程中的線程
|
|
USYNC_THREAD
|
PTHREAD_PROCESS_PRIVATE
|
用于僅同步該進程中的線程
|
初始化條件變量屬性
使用 pthread_condattr_init(3C) 可以將與該對象相關(guān)聯(lián)的屬性初始化為其缺省值。在執(zhí)行過程中,線程系統(tǒng)會為每個屬性對象分配存儲空間。
pthread_condattr_init 語法
int pthread_condattr_init(pthread_condattr_t *cattr);
#include <pthread.h>
pthread_condattr_t cattr;
int ret;
/* initialize an attribute to default value */
ret = pthread_condattr_init(&cattr);
調(diào)用此函數(shù)時,pshared 屬性的缺省值為 PTHREAD_PROCESS_PRIVATE。pshared 的該值表示可以在進程內(nèi)使用已初始化的條件變量。
cattr 的數(shù)據(jù)類型為 opaque,其中包含一個由系統(tǒng)分配的屬性對象。cattr 范圍可能的值為 PTHREAD_PROCESS_PRIVATE 和 PTHREAD_PROCESS_SHARED。PTHREAD_PROCESS_PRIVATE 是缺省值。
條件變量屬性必須首先由 pthread_condattr_destroy(3C) 重新初始化后才能重用。pthread_condattr_init() 調(diào)用會返回指向類型為 opaque 的對象的指針。如果未銷毀該對象,則會導(dǎo)致內(nèi)存泄漏。
pthread_condattr_init 返回值
pthread_condattr_init() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下任一情況,該函數(shù)將失敗并返回對應(yīng)的值。
ENOMEM
描述:
分配的內(nèi)存不足,無法初始化線程屬性對象。
EINVAL
描述:
cattr 指定的值無效。
刪除條件變量屬性
使用 pthread_condattr_destroy(3C) 可以刪除存儲并使屬性對象無效。
pthread_condattr_destroy 語法
int pthread_condattr_destroy(pthread_condattr_t *cattr);
#include <pthread.h>
pthread_condattr_t cattr;
int ret;
/* destroy an attribute */
ret
= pthread_condattr_destroy(&cattr);
pthread_condattr_destroy 返回值
pthread_condattr_destroy() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cattr 指定的值無效。
設(shè)置條件變量的范圍
pthread_condattr_setpshared(3C) 可用來將條件變量的范圍設(shè)置為進程專用(進程內(nèi))或系統(tǒng)范圍內(nèi)(進程間)。
pthread_condattr_setpshared 語法
int pthread_condattr_setpshared(pthread_condattr_t *cattr,
int pshared);
#include <pthread.h>
pthread_condattr_t cattr;
int ret;
/* all processes */
ret = pthread_condattr_setpshared(&cattr, PTHREAD_PROCESS_SHARED);
/* within a process */
ret = pthread_condattr_setpshared(&cattr, PTHREAD_PROCESS_PRIVATE);
如果 pshared 屬性在共享內(nèi)存中設(shè)置為 PTHREAD_PROCESS_SHARED,則其所創(chuàng)建的條件變量可以在多個進程中的線程之間共享。此行為與最初的 Solaris 線程實現(xiàn)中 mutex_init() 中的 USYNC_PROCESS 標(biāo)志等效。
如果互斥鎖的 pshared 屬性設(shè)置為 PTHREAD_PROCESS_PRIVATE,則僅有那些由同一個進程創(chuàng)建的線程才能夠處理該互斥鎖。PTHREAD_PROCESS_PRIVATE 是缺省值。PTHREAD_PROCESS_PRIVATE 所產(chǎn)生的行為與在最初的 Solaris 線程的 cond_init() 調(diào)用中使用 USYNC_THREAD 標(biāo)志相同。PTHREAD_PROCESS_PRIVATE 的行為與局部條件變量相同。PTHREAD_PROCESS_SHARED 的行為與全局條件變量等效。
pthread_condattr_setpshared 返回值
pthread_condattr_setpshared() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cattr 或 pshared 的值無效。
獲取條件變量的范圍
pthread_condattr_getpshared(3C) 可用來獲取屬性對象 cattr 的 pshared 的當(dāng)前值。
pthread_condattr_getpshared 語法
int pthread_condattr_getpshared(const pthread_condattr_t *cattr,
int *pshared);
#include <pthread.h>
pthread_condattr_t cattr;
int pshared;
int ret;
/* get pshared value of condition variable */
ret = pthread_condattr_getpshared(&cattr, &pshared);
屬性對象的值為 PTHREAD_PROCESS_SHARED 或 PTHREAD_PROCESS_PRIVATE。
pthread_condattr_getpshared 返回值
pthread_condattr_getpshared() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cattr 的值無效。
本節(jié)介紹如何使用條件變量。表 4–6 列出了可用的函數(shù)。
表 4–6 條件變量函數(shù)
初始化條件變量
使用 pthread_cond_init(3C) 可以將 cv 所指示的條件變量初始化為其缺省值,或者指定已經(jīng)使用 pthread_condattr_init() 設(shè)置的條件變量屬性。
pthread_cond_init 語法
int pthread_cond_init(pthread_cond_t *cv,
const pthread_condattr_t *cattr);
#include <pthread.h>
pthread_cond_t cv;
pthread_condattr_t cattr;
int ret;
/* initialize a condition variable to its default value */
ret = pthread_cond_init(&cv, NULL);
/* initialize a condition variable */
ret = pthread_cond_init(&cv, &cattr);
cattr 設(shè)置為 NULL。將 cattr 設(shè)置為 NULL 與傳遞缺省條件變量屬性對象的地址等效,但是沒有內(nèi)存開銷。對于 Solaris 線程,請參見cond_init 語法。
使用 PTHREAD_COND_INITIALIZER 宏可以將以靜態(tài)方式定義的條件變量初始化為其缺省屬性。PTHREAD_COND_INITIALIZER 宏與動態(tài)分配具有 null 屬性的 pthread_cond_init() 等效,但是不進行錯誤檢查。
多個線程決不能同時初始化或重新初始化同一個條件變量。如果要重新初始化或銷毀某個條件變量,則應(yīng)用程序必須確保該條件變量未被使用。
pthread_cond_init 返回值
pthread_cond_init() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下任一情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cattr 指定的值無效。
EBUSY
描述:
條件變量處于使用狀態(tài)。
EAGAIN
描述:
必要的資源不可用。
ENOMEM
描述:
內(nèi)存不足,無法初始化條件變量。
基于條件變量阻塞
使用 pthread_cond_wait(3C) 可以以原子方式釋放 mp 所指向的互斥鎖,并導(dǎo)致調(diào)用線程基于 cv 所指向的條件變量阻塞。對于 Solaris 線程,請參見cond_wait 語法。
pthread_cond_wait 語法
int pthread_cond_wait(pthread_cond_t *cv,pthread_mutex_t *mutex);
#include <pthread.h>
pthread_cond_t cv;
pthread_mutex_t mp;
int ret;
/* wait on condition variable */
ret = pthread_cond_wait(&cv, &mp);
阻塞的線程可以通過 pthread_cond_signal() 或 pthread_cond_broadcast() 喚醒,也可以在信號傳送將其中斷時喚醒。
不能通過 pthread_cond_wait() 的返回值來推斷與條件變量相關(guān)聯(lián)的條件的值的任何變化。必須重新評估此類條件。
pthread_cond_wait() 例程每次返回結(jié)果時調(diào)用線程都會鎖定并且擁有互斥鎖,即使返回錯誤時也是如此。
該條件獲得信號之前,該函數(shù)一直被阻塞。該函數(shù)會在被阻塞之前以原子方式釋放相關(guān)的互斥鎖,并在返回之前以原子方式再次獲取該互斥鎖。
通常,對條件表達式的評估是在互斥鎖的保護下進行的。如果條件表達式為假,線程會基于條件變量阻塞。然后,當(dāng)該線程更改條件值時,另一個線程會針對條件變量發(fā)出信號。這種變化會導(dǎo)致所有等待該條件的線程解除阻塞并嘗試再次獲取互斥鎖。
必須重新測試導(dǎo)致等待的條件,然后才能從 pthread_cond_wait() 處繼續(xù)執(zhí)行。喚醒的線程重新獲取互斥鎖并從 pthread_cond_wait() 返回之前,條件可能會發(fā)生變化。等待線程可能并未真正喚醒。建議使用的測試方法是,將條件檢查編寫為調(diào)用 pthread_cond_wait() 的 while() 循環(huán)。
pthread_mutex_lock();
while(condition_is_false)
pthread_cond_wait();
pthread_mutex_unlock();
如果有多個線程基于該條件變量阻塞,則無法保證按特定的順序獲取互斥鎖。
注 –
pthread_cond_wait() 是取消點。如果取消處于暫掛狀態(tài),并且調(diào)用線程啟用了取消功能,則該線程會終止,并在繼續(xù)持有該鎖的情況下開始執(zhí)行清除處理程序。
pthread_cond_wait 返回值
pthread_cond_wait() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cv 或 mp 指定的值無效。
解除阻塞一個線程
對于基于 cv 所指向的條件變量阻塞的線程,使用 pthread_cond_signal(3C) 可以解除阻塞該線程。對于 Solaris 線程,請參見cond_signal 語法。
pthread_cond_signal 語法
int pthread_cond_signal(pthread_cond_t *cv);
#include <pthread.h>
pthread_cond_t cv;
int ret;
/* one condition variable is signaled */
ret = pthread_cond_signal(&cv);
應(yīng)在互斥鎖的保護下修改相關(guān)條件,該互斥鎖用于獲得信號的條件變量中。否則,可能在條件變量的測試和 pthread_cond_wait() 阻塞之間修改該變量,這會導(dǎo)致無限期等待。
調(diào)度策略可確定喚醒阻塞線程的順序。對于 SCHED_OTHER,將按優(yōu)先級順序喚醒線程。
如果沒有任何線程基于條件變量阻塞,則調(diào)用 pthread_cond_signal() 不起作用。
示例 4–8 使用 pthread_cond_wait() 和 pthread_cond_signal()
pthread_mutex_t count_lock;
pthread_cond_t count_nonzero;
unsigned count;
decrement_count()
{
pthread_mutex_lock(&count_lock);
while (count == 0)
pthread_cond_wait(&count_nonzero, &count_lock);
count = count - 1;
pthread_mutex_unlock(&count_lock);
}
increment_count()
{
pthread_mutex_lock(&count_lock);
if (count == 0)
pthread_cond_signal(&count_nonzero);
count = count + 1;
pthread_mutex_unlock(&count_lock);
}
pthread_cond_signal 返回值
pthread_cond_signal() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cv 指向的地址非法。
示例 4–8 說明了如何使用 pthread_cond_wait() 和 pthread_cond_signal()。
在指定的時間之前阻塞
pthread_cond_timedwait(3C) 的用法與 pthread_cond_wait() 的用法基本相同,區(qū)別在于在由 abstime 指定的時間之后 pthread_cond_timedwait() 不再被阻塞。
pthread_cond_timedwait 語法
int pthread_cond_timedwait(pthread_cond_t *cv,
pthread_mutex_t *mp, const struct timespec *abstime);
#include <pthread.h>
#include <time.h>
pthread_cond_t cv;
pthread_mutex_t mp;
timestruct_t abstime;
int ret;
/* wait on condition variable */
ret = pthread_cond_timedwait(&cv, &mp, &abstime);
pthread_cond_timewait() 每次返回時調(diào)用線程都會鎖定并且擁有互斥鎖,即使 pthread_cond_timedwait() 返回錯誤時也是如此。 對于 Solaris 線程,請參見cond_timedwait 語法。
pthread_cond_timedwait() 函數(shù)會一直阻塞,直到該條件獲得信號,或者最后一個參數(shù)所指定的時間已過為止。
注 –
pthread_cond_timedwait() 也是取消點。
示例 4–9 計時條件等待
pthread_timestruc_t to;
pthread_mutex_t m;
pthread_cond_t c;
...
pthread_mutex_lock(&m);
to.tv_sec = time(NULL) + TIMEOUT;
to.tv_nsec = 0;
while (cond == FALSE) {
err = pthread_cond_timedwait(&c, &m, &to);
if (err == ETIMEDOUT) {
/* timeout, do something */
break;
}
}
pthread_mutex_unlock(&m);
pthread_cond_timedwait 返回值
pthread_cond_timedwait() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下任一情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cv 或 abstime 指向的地址非法。
ETIMEDOUT
描述:
abstime 指定的時間已過。
超時會指定為當(dāng)天時間,以便在不重新計算值的情況下高效地重新測試條件,如示例 4–9 中所示。
在指定的時間間隔內(nèi)阻塞
pthread_cond_reltimedwait_np(3C) 的用法與 pthread_cond_timedwait() 的用法基本相同,唯一的區(qū)別在于 pthread_cond_reltimedwait_np() 會采用相對時間間隔而不是將來的絕對時間作為其最后一個參數(shù)的值。
pthread_cond_reltimedwait_np 語法
int pthread_cond_reltimedwait_np(pthread_cond_t *cv,
pthread_mutex_t *mp,
const struct timespec *reltime);
#include <pthread.h>
#include <time.h>
pthread_cond_t cv;
pthread_mutex_t mp;
timestruct_t reltime;
int ret;
/* wait on condition variable */
ret = pthread_cond_reltimedwait_np(&cv, &mp, &reltime);
pthread_cond_reltimedwait_np() 每次返回時調(diào)用線程都會鎖定并且擁有互斥鎖,即使 pthread_cond_reltimedwait_np() 返回錯誤時也是如此。對于 Solaris 線程,請參見 cond_reltimedwait(3C)。pthread_cond_reltimedwait_np() 函數(shù)會一直阻塞,直到該條件獲得信號,或者最后一個參數(shù)指定的時間間隔已過為止。
注 –
pthread_cond_reltimedwait_np() 也是取消點。
pthread_cond_reltimedwait_np 返回值
pthread_cond_reltimedwait_np() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下任一情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cv 或 reltime 指示的地址非法。
ETIMEDOUT
描述:
reltime 指定的時間間隔已過。
解除阻塞所有線程
對于基于 cv 所指向的條件變量阻塞的線程,使用 pthread_cond_broadcast(3C) 可以解除阻塞所有這些線程,這由 pthread_cond_wait() 來指定。
pthread_cond_broadcast 語法
int pthread_cond_broadcast(pthread_cond_t *cv);
#include <pthread.h>
pthread_cond_t cv;
int ret;
/* all condition variables are signaled */
ret = pthread_cond_broadcast(&cv);
如果沒有任何線程基于該條件變量阻塞,則調(diào)用 pthread_cond_broadcast() 不起作用。對于 Solaris 線程,請參見cond_broadcast 語法。
由于 pthread_cond_broadcast() 會導(dǎo)致所有基于該條件阻塞的線程再次爭用互斥鎖,因此請謹(jǐn)慎使用 pthread_cond_broadcast()。例如,通過使用 pthread_cond_broadcast(),線程可在資源釋放后爭用不同的資源量,如示例 4–10 中所示。
示例 4–10 條件變量廣播
pthread_mutex_t rsrc_lock;
pthread_cond_t rsrc_add;
unsigned int resources;
get_resources(int amount)
{
pthread_mutex_lock(&rsrc_lock);
while (resources < amount) {
pthread_cond_wait(&rsrc_add, &rsrc_lock);
}
resources -= amount;
pthread_mutex_unlock(&rsrc_lock);
}
add_resources(int amount)
{
pthread_mutex_lock(&rsrc_lock);
resources += amount;
pthread_cond_broadcast(&rsrc_add);
pthread_mutex_unlock(&rsrc_lock);
}
請注意,在 add_resources() 中,首先更新 resources 還是首先在互斥鎖中調(diào)用 pthread_cond_broadcast() 無關(guān)緊要。
應(yīng)在互斥鎖的保護下修改相關(guān)條件,該互斥鎖用于獲得信號的條件變量中。否則,可能在條件變量的測試和 pthread_cond_wait() 阻塞之間修改該變量,這會導(dǎo)致無限期等待。
pthread_cond_broadcast 返回值
pthread_cond_broadcast() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cv 指示的地址非法。
銷毀條件變量狀態(tài)
使用 pthread_cond_destroy(3C) 可以銷毀與 cv 所指向的條件變量相關(guān)聯(lián)的任何狀態(tài)。對于 Solaris 線程,請參見cond_destroy 語法。
pthread_cond_destroy 語法
int pthread_cond_destroy(pthread_cond_t *cv);
#include <pthread.h>
pthread_cond_t cv;
int ret;
/* Condition variable is destroyed */
ret = pthread_cond_destroy(&cv);
請注意,沒有釋放用來存儲條件變量的空間。
pthread_cond_destroy 返回值
pthread_cond_destroy() 在成功完成之后會返回零。其他任何返回值都表示出現(xiàn)了錯誤。如果出現(xiàn)以下情況,該函數(shù)將失敗并返回對應(yīng)的值。
EINVAL
描述:
cv 指定的值無效。
喚醒丟失問題
如果線程未持有與條件相關(guān)聯(lián)的互斥鎖,則調(diào)用 pthread_cond_signal() 或 pthread_cond_broadcast() 會產(chǎn)生喚醒丟失錯誤。
滿足以下所有條件時,即會出現(xiàn)喚醒丟失問題:
僅當(dāng)修改所測試的條件但未持有與之相關(guān)聯(lián)的互斥鎖時,才會出現(xiàn)此問題。只要僅在持有關(guān)聯(lián)的互斥鎖同時修改所測試的條件,即可調(diào)用 pthread_cond_signal() 和 pthread_cond_broadcast(),而無論這些函數(shù)是否持有關(guān)聯(lián)的互斥鎖。
生成方和使用者問題
并發(fā)編程中收集了許多標(biāo)準(zhǔn)的眾所周知的問題,生成方和使用者問題只是其中的一個問題。此問題涉及到一個大小限定的緩沖區(qū)和兩類線程(生成方和使用者),生成方將項放入緩沖區(qū)中,然后使用者從緩沖區(qū)中取走項。
生成方必須在緩沖區(qū)中有可用空間之后才能向其中放置內(nèi)容。使用者必須在生成方向緩沖區(qū)中寫入之后才能從中提取內(nèi)容。
條件變量表示一個等待某個條件獲得信號的線程隊列。
示例 4–11 中包含兩個此類隊列。一個隊列 (less) 針對生成方,用于等待緩沖區(qū)中出現(xiàn)空位置。另一個隊列 (more) 針對使用者,用于等待從緩沖槽位的空位置中提取其中包含的信息。該示例中還包含一個互斥鎖,因為描述該緩沖區(qū)的數(shù)據(jù)結(jié)構(gòu)一次只能由一個線程訪問。
示例 4–11 生成方和使用者的條件變量問題
typedef struct {
char buf[BSIZE];
int occupied;
int nextin;
int nextout;
pthread_mutex_t mutex;
pthread_cond_t more;
pthread_cond_t less;
} buffer_t;
buffer_t buffer;
如示例 4–12 中所示,生成方線程獲取該互斥鎖以保護 buffer 數(shù)據(jù)結(jié)構(gòu),然后,緩沖區(qū)確定是否有空間可用于存放所生成的項。如果沒有可用空間,生成方線程會調(diào)用 pthread_cond_wait()。pthread_cond_wait() 會導(dǎo)致生成方線程連接正在等待 less 條件獲得信號的線程隊列。less 表示緩沖區(qū)中的可用空間。
與此同時,在調(diào)用 pthread_cond_wait() 的過程中,該線程會釋放互斥鎖的鎖定。正在等待的生成方線程依賴于使用者線程在條件為真時發(fā)出信號,如示例 4–12 中所示。該條件獲得信號時,將會喚醒等待 less 的第一個線程。但是,該線程必須再次鎖定互斥鎖,然后才能從 pthread_cond_wait() 返回。
獲取互斥鎖可確保該線程再次以獨占方式訪問緩沖區(qū)的數(shù)據(jù)結(jié)構(gòu)。該線程隨后必須檢查緩沖區(qū)中是否確實存在可用空間。如果空間可用,該線程會向下一個可用的空位置中進行寫入。
與此同時,使用者線程可能正在等待項出現(xiàn)在緩沖區(qū)中。這些線程正在等待條件變量 more。剛在緩沖區(qū)中存儲內(nèi)容的生成方線程會調(diào)用 pthread_cond_signal() 以喚醒下一個正在等待的使用者。如果沒有正在等待的使用者,此調(diào)用將不起作用。
最后,生成方線程會解除鎖定互斥鎖,從而允許其他線程處理緩沖區(qū)的數(shù)據(jù)結(jié)構(gòu)。
示例 4–12 生成方和使用者問題:生成方
void producer(buffer_t *b, char item)
{
pthread_mutex_lock(&b->mutex);
while (b->occupied >= BSIZE)
pthread_cond_wait(&b->less, &b->mutex);
assert(b->occupied < BSIZE);
b->buf[b->nextin++] = item;
b->nextin %= BSIZE;
b->occupied++;
/* now: either b->occupied < BSIZE and b->nextin is the index
of the next empty slot in the buffer, or
b->occupied == BSIZE and b->nextin is the index of the
next (occupied) slot that will be emptied by a consumer
(such as b->nextin == b->nextout) */
pthread_cond_signal(&b->more);
pthread_mutex_unlock(&b->mutex);
}
請注意 assert() 語句的用法。除非在編譯代碼時定義了 NDEBUG,否則 assert() 在其參數(shù)的計算結(jié)果為真(非零)時將不執(zhí)行任何操作。如果參數(shù)的計算結(jié)果為假(零),則該程序會中止。在多線程程序中,此類斷言特別有用。如果斷言失敗,assert() 會立即指出運行時問題。assert() 還有另一個作用,即提供有用的注釋。
以 /* now: either b->occupied ... 開頭的注釋最好以斷言形式表示,但是由于語句過于復(fù)雜,無法用布爾值表達式來表示,因此將用英語表示。
斷言和注釋都是不變量的示例。這些不變量是邏輯語句,在程序正常執(zhí)行時不應(yīng)將其聲明為假,除非是線程正在修改不變量中提到的一些程序變量時的短暫修改過程中。當(dāng)然,只要有線程執(zhí)行語句,斷言就應(yīng)當(dāng)為真。
使用不變量是一種極為有用的方法。即使沒有在程序文本中聲明不變量,在分析程序時也應(yīng)將其視為不變量。
每次線程執(zhí)行包含注釋的代碼時,生成方代碼中表示為注釋的不變量始終為真。如果將此注釋移到緊挨 mutex_unlock() 的后面,則注釋不一定仍然為真。如果將此注釋移到緊跟 assert() 之后的位置,則注釋仍然為真。
因此,不變量可用于表示一個始終為真的屬性,除非一個生成方或一個使用者正在更改緩沖區(qū)的狀態(tài)。線程在互斥鎖的保護下處理緩沖區(qū)時,該線程可能會暫時聲明不變量為假。但是,一旦線程結(jié)束對緩沖區(qū)的操作,不變量即會恢復(fù)為真。
示例 4–13 給出了使用者的代碼。該邏輯流程與生成方的邏輯流程相對稱。
示例 4–13 生成方和使用者問題:使用者
char consumer(buffer_t *b)
{
char item;
pthread_mutex_lock(&b->mutex);
while(b->occupied <= 0)
pthread_cond_wait(&b->more, &b->mutex);
assert(b->occupied > 0);
item = b->buf[b->nextout++];
b->nextout %= BSIZE;
b->occupied--;
/* now: either b->occupied > 0 and b->nextout is the index
of the next occupied slot in the buffer, or
b->occupied == 0 and b->nextout is the index of the next
(empty) slot that will be filled by a producer (such as
b->nextout == b->nextin) */
pthread_cond_signal(&b->less);
pthread_mutex_unlock(&b->mutex);
return(item);
}
PowerDesigner設(shè)置主鍵自增方法:選中主鍵字段,點擊進入屬性設(shè)置框,勾選"Identity",這里注意不同的SQL會有不同的方法,比如MySQL為:ATUO_INCREMENT,而SQL Server為:Identity,請選擇你需要的數(shù)據(jù)庫平臺。更換平臺方法:Tool-->Generate Physical Data Mode--> General(默認(rèn)就會打開這里)-->DBMS里選擇你的數(shù)據(jù)庫平臺即可。。。
sql語句中表名與字段名前的引號去除:
打開cdm的情況下,進入Tools-Model Options-Naming Convention,把Name和Code的標(biāo)簽的Charcter case選項設(shè)置成Uppercase或者Lowercase,只要不是Mixed Case就行!
或者選擇Database->Edit current database->Script->Sql->Format,有一項CaseSensitivityUsingQuote,它的 comment為“Determines if the case sensitivity for identifiers is managed using double quotes”,表示是否適用雙引號來規(guī)定標(biāo)識符的大小寫, 可以看到右邊的values默認(rèn)值為“YES”,改為“No”即可!
或者在打開pdm的情況下,進入Tools-Model Options-Naming Convention,把Name和Code的標(biāo)簽的Charcter case選項設(shè)置成Uppercase就可以!
在修改name的時候,code的值將跟著變動,很不方便修改方法:PowerDesign中的選項菜單里修改,在[Tool]-->[General Options]->[Dialog]->[Operating modes]->[Name to Code mirroring],這里默認(rèn)是讓名稱和代碼同步,將前面的復(fù)選框去掉就行了。
由pdm生成建表腳本時,字段超過15字符就發(fā)生錯誤(oracle) 原因未知,解決辦法是打開PDM后,會出現(xiàn)Database的菜單欄,進入Database - Edit Current DBMS -script-objects-column-maxlen,把value值調(diào)大(原為30),比如改成60。出現(xiàn)表或者其它對象的長度也有這種錯誤的話都可以選擇對應(yīng)的objects照此種方法更改!
或者使用下面的這種方法:
生成建表腳本時會彈出Database generation提示框:把options - check model的小勾給去掉,就是不進行檢查(不推薦)!
或者可以修改C:\Program Files\Sybase\PowerDesigner Trial 11\Resource Files\DBMS\oracl9i2.xdb文件
修改好后,再cdm轉(zhuǎn)為pdm時,選擇“Copy the DBMS definition in model”把把這個資源文件拷貝到模型中。
由CDM生成PDM時,自動生成的外鍵的重命名PDM Generation Options->Detail->FK index names默認(rèn)是%REFR%_FK,改為FK_%REFRCODE%,其中%REFRCODE%指的就是CDM中Relationship的code!另外自動生成的父字段的規(guī)則是PDM Generation Options->Detail->FK column name template中設(shè)置的,默認(rèn)是%.3:PARENT%_%COLUMN%,可以改為Par%COLUMN%表示是父字段!
建立一個表后,為何檢測出現(xiàn)Existence of index的警告 A table should contain at least one column, one index, one key, and one reference.
可以不檢查 Existence of index 這項,也就沒有這個警告錯誤了!
意思是說沒有給表建立索引,而一個表一般至少要有一個索引,這是一個警告,不用管也沒有關(guān)系!
如何防止一對一的關(guān)系生成兩個引用(外鍵)要定義關(guān)系的支配方向,占支配地位的實體(有D標(biāo)志)變?yōu)楦副怼?br>在cdm中雙擊一對一關(guān)系->Detail->Dominant role選擇支配關(guān)系
修改報表模板中一些術(shù)語的定義即文件:C:\Program Files\Sybase\PowerDesigner Trial 11\Resource Files\Report Languages\Chinese.xrl
Tools-Resources-Report Languages-選擇Chinese-單擊Properties或雙擊目標(biāo)
修改某些對象的名稱:Object Attributes\Physical Data Model\Column\
ForeignKey:外鍵
Mandatory:為空
Primary:主鍵
Table:表
用查找替換,把“表格”替換成“表”修改顯示的內(nèi)容為別的:Values Mapping\Lists\Standard,添加TRUE的轉(zhuǎn)化列為是,F(xiàn)ALSE的轉(zhuǎn)化列為空
另外Report-Title Page里可以設(shè)置標(biāo)題信息
PowerDesigner11中批量根據(jù)對象的name生成comment的腳本'******************************************************************************
'* File: name2comment.vbs
'* Purpose: Database generation cannot use object names anymore
' in version 7 and above.
' It always uses the object codes.
'
' In case the object codes are not aligned with your
' object names in your model, this script will copy
' the object Name onto the object comment for
' the Tables and Columns.
'
'* Title: 把對象name拷入comment屬性中
'* Version: 1.0
'* Author:
'* 執(zhí)行方法:PD11 -- Open PDM -- Tools -- Execute Commands -- Run Script
'******************************************************************************
Option Explicit
ValidationMode = True
InteractiveMode = im_Batch
Dim mdl ' the current model
' get the current active model
Set mdl = ActiveModel
If (mdl Is Nothing) Then
MsgBox "There is no current Model"
ElseIf Not mdl.IsKindOf(PdPDM.cls_Model) Then
MsgBox "The current model is not an Physical Data model."
Else
ProcessFolder mdl
End If
' This routine copy name into code for each table, each column and each view
' of the current folder
Private sub ProcessFolder(folder)
Dim Tab 'running table
for each Tab in folder.tables
if not tab.isShortcut then
tab.comment = tab.name
Dim col ' running column
for each col in tab.columns
col.comment= col.name
next
end if
next
Dim view 'running view
for each view in folder.Views
if not view.isShortcut then
view.comment = view.name
end if
next
' go into the sub-packages
Dim f ' running folder
For Each f In folder.Packages
if not f.IsShortcut then
ProcessFolder f
end if
Next
end sub
PowerDesigner 生成SQL的Existence of refernce錯誤問題現(xiàn)象:用PowerDesigner生成SQL語句時,提示Existence of refernce錯誤。
原因:該表沒有與其他表的關(guān)聯(lián)(如外鍵等),而PowerDesigner需要存在一個refernce才能生成SQL.
解決方法:
在工具欄空白處右鍵打開Palette面板,選中Link/Extended Dependency 按鈕,然后在提示出錯的表上添加到自己的Dependency。
重新生成SQL,你將發(fā)現(xiàn)剛才提示的錯誤沒有了,問題解決。
利用PowerDesigner批量生成測試數(shù)據(jù)主要解決方法:
A:在PowerDesigner 建表
B:然后給每一個表的字段建立相應(yīng)的摘要文件
步驟如下:
Model->Test Data Profiles配置每一個字段摘要文件General:輸入Name、Code、
選擇Class(數(shù)字、字符、時間)類型
選擇Generation Source: Automatic、List、ODBC、File Detail:配置字段相關(guān)信息
所有字段摘要文件配置完成后雙擊該表->選擇字段->Detail->選擇Test Data Parameters 摘要文件如果字段值與其它字段有關(guān)系在: Computed Expression 中輸入計算列--生成測試數(shù)據(jù):
DataBase->Generation Test Data->
選擇:Genration 類型(Sript、ODBC)
Selection(選擇要生成的表)
Test Data Genration(Default number of rows 生成記錄行數(shù))
在使用PowerDesigner的過程中,經(jīng)常遇到一些設(shè)置上面的問題,每次都去找老鳥幫忙解決,隔一段時間不用,下一次又忘掉了,不好意思再去麻煩他們了,所以現(xiàn)在用博客園記錄下來,以后上園子來找以前的東西.
1
取消Name和Code關(guān)聯(lián)的設(shè)置
在設(shè)計PDM文件的時候,設(shè)計一張表,在填寫欄位的時候,如果我們輸入Name,Code會跟著變化.這個完全是西方人的習(xí)慣,因為他們的Name和Code都是E文,所以不會出現(xiàn)什么問題.但是,我們使用的時候,就會很不習(xí)慣,Name應(yīng)該是中文名字,Code才是資料庫的實際字段名.
下面記錄修改設(shè)置的步驟:
Step 1:
菜單欄找到Tools,點開,找到General Options,點擊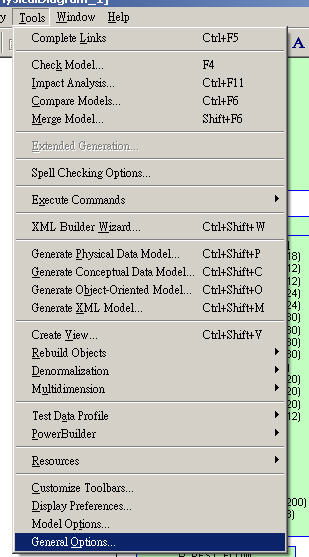
Step 2:打開Dialog將Operating modes中的 Name To Code mirroring 將前面的勾去掉
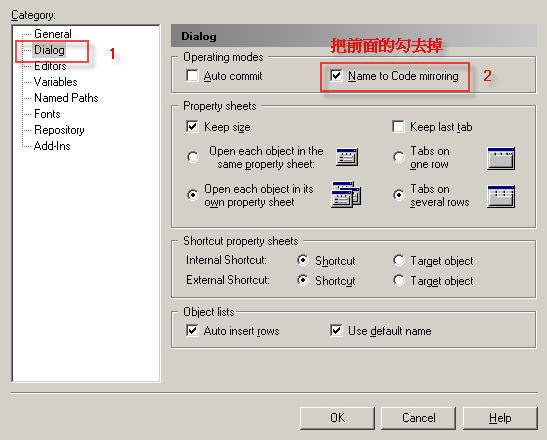
OK!完成
摘要:
··· 2
第一節(jié) 全文檢索系統(tǒng)與Lucene簡介··· 3
一、 什么是全文檢索與全文檢索系統(tǒng)?··· 3
二、 什么是Lucene?&...
閱讀全文
一、Lucene源碼實現(xiàn)分析的說明
通過以上對Lucene系統(tǒng)結(jié)構(gòu)的分析,我們已經(jīng)大致的清楚了Lucene 系統(tǒng)的組成,以及在Lucene系統(tǒng)之上的開發(fā)步驟。接下來,我們試圖來分析Lucene項目(采用Lucene 1.2版本)的源碼實現(xiàn),考察其實現(xiàn)的細(xì)節(jié)。這不僅僅是我們嘗試用C++語言重新實現(xiàn)Lucene的必須工作,也是進一步做Lucene開發(fā)工作的必要準(zhǔn)備。因此,這一部分所涉及到的內(nèi)容,對于Lucene上的應(yīng)用開發(fā)也是有價值的,尤其是本部分所做的文件格式分析。
由于本文建立在我們的畢設(shè)項目之上,且同時我們需要實現(xiàn)cLucene項目,因此很遺憾的我們并沒有完全的完成Lucene的所有源碼實現(xiàn)的分析工作。接下來的部分,我們將涉及的部分為Lucene文件格式分析,Lucene中的存儲抽象模塊分析,以及Lucene中的索引構(gòu)建邏輯模塊分析。這一部分,我們主要涉及到的是文件格式分析與存儲抽象模塊分析。
二、Lucene索引文件格式
在Lucene的web站點上,有關(guān)于 Lucene的文件格式的規(guī)范,其規(guī)定了Lucene的文件格式采取的存儲單位、組織結(jié)構(gòu)、命名規(guī)范等等內(nèi)容,但是它僅僅是一個規(guī)范說明,并沒有從實現(xiàn)者角度來衡量這個規(guī)范的實現(xiàn)。因此,我們以下的內(nèi)容,結(jié)合了我們自己的分析與文件格式的定義規(guī)范,以期望給出一個更加清晰的文件格式說明。具體的文檔規(guī)范可以參考后面的文獻2。
首先在Lucene的文件格式中,以字節(jié)為基礎(chǔ),定義了如下的數(shù)據(jù)類型:
表 3.1 Lucene文件格式中定義的數(shù)據(jù)類型
| 數(shù)據(jù)類型 |
所占字節(jié)長度(字節(jié)) |
說明 |
| Byte |
1 |
基本數(shù)據(jù)類型,其他數(shù)據(jù)類型以此為基礎(chǔ)定義 |
| UInt32 |
4 |
32位無符號整數(shù),高位優(yōu)先 |
| UInt64 |
8 |
64位無符號整數(shù),高位優(yōu)先 |
| VInt |
不定,最少1字節(jié) |
動態(tài)長度整數(shù),每字節(jié)的最高位表明還剩多少字節(jié),每字節(jié)的低七位表明整數(shù)的值,高位優(yōu)先。可以認(rèn)為值可以為無限大。其示例如下
| 值 |
字節(jié)1 |
字節(jié)2 |
字節(jié)3 |
| 0 |
00000000 |
|
|
| 1 |
00000001 |
|
|
| 2 |
00000010 |
|
|
| 127 |
01111111 |
|
|
| 128 |
10000000 |
00000001 |
|
| 129 |
10000001 |
00000001 |
|
| 130 |
10000010 |
00000001 |
|
| 16383 |
10000000 |
10000000 |
00000001 |
| 16384 |
10000001 |
10000000 |
00000001 |
| 16385 |
10000010 |
10000000 |
00000001 |
|
| Chars |
不定,最少1字節(jié) |
采用UTF-8編碼[20]的Unicode字符序列 |
| String |
不定,最少2字節(jié) |
由VInt和Chars組成的字符串類型,VInt表示Chars的長度,Chars則表示了String的值 |
以上的數(shù)據(jù)類型就是Lucene索引文件格式中用到的全部數(shù)據(jù)類型,由于它們都以字節(jié)為基礎(chǔ)定義而來,因此保證了是平臺無關(guān),這也是Lucene索引文件格式平臺無關(guān)的主要原因。接下來我們看看Lucene索引文件的概念組成和結(jié)構(gòu)組成。

以上就是Lucene的索引文件的概念結(jié)構(gòu)。Lucene索引index由若干段(segment)組成,每
一段由若干的文檔(document)組成,每一個文檔由若干的域(field)組成,每一個域由若干的項(term)組成。項是最小的索引概念單位,它直接代表了一個字符串以及其在文件中的位置、出現(xiàn)次數(shù)等信息。域是一個關(guān)聯(lián)的元組,由一個域名和一個域值組成,域名是一個字串,域值是一個項,比如將“標(biāo)題”和實際標(biāo)題的項組成的域。文檔是提取了某個文件中的所有信息之后的結(jié)果,這些組成了段,或者稱為一個子索引。子索引可以組合為索引,也可以合并為一個新的包含了所有合并項內(nèi)部元素的子索引。我們可以清楚的看出,Lucene的索引結(jié)構(gòu)在概念上即為傳統(tǒng)的倒排索引結(jié)構(gòu)[21]。
從概念上映射到結(jié)構(gòu)中,索引被處理為一個目錄(文件夾),其中含有的所有文件即為其內(nèi)容,這些文件按照所屬的段不同分組存放,同組的文件擁有相同的文件名,不同的擴展名。此外還有三個文件,分別用來保存所有的段的記錄、保存已刪除文件的記錄和控制讀寫的同步,它們分別是segments, deletable和lock文件,都沒有擴展名。每個段包含一組文件,它們的文件擴展名不同,但是文件名均為記錄在文件segments中段的名字。讓我們看如下的結(jié)構(gòu)圖3.2。

關(guān)于圖3.2中的各個文件具體的內(nèi)部格式,在參考文獻3中,均可以找到詳細(xì)的說明。接下來我們從宏觀關(guān)系上說明一下這些文件組成。在這些宏觀上的關(guān)系理清楚之后,仔細(xì)閱讀參考文獻3,即可清楚的明白具體的Lucene文件格式。
每個段的文件中,主要記錄了兩大類的信息:域集合與項集合。這兩個集合中所含有的文件在圖3.2中均有表明。由于索引信息是靜態(tài)存儲的,域集合與項集合中的文件組采用了一種類似的存儲辦法:一個小型的索引文件,運行時載入內(nèi)存;一個對應(yīng)于索引文件的實際信息文件,可以按照索引中指示的偏移量隨機訪問;索引文件與信息文件在記錄的排列順序上存在隱式的對應(yīng)關(guān)系,即索引文件中按照“索引項1、索引項2…”排列,則信息文件則也按照“信息項1、信息項2…”排列。比如在圖3.2所示文件中,segment1.fdx與segment1.fdt之間,segment1.tii與segment1.tis、 segment1.prx、segment1.frq之間,都存在這樣的組織關(guān)系。而域集合與項集合之間則通過域的在域記錄文件(比如 segment1.fnm)中所記錄的域記錄號維持對應(yīng)關(guān)系,在圖3.2中segment1.fdx與segment1.tii中就是通過這種方式保持聯(lián)系。這樣,域集合和項集合不僅僅聯(lián)系起來,而且其中的文件之間也相互聯(lián)系起來。此外,標(biāo)準(zhǔn)化因子文件和被刪除文檔文件則提供了一些程序內(nèi)部的輔助設(shè)施(標(biāo)準(zhǔn)化因子用在評分排序機制中,被刪除文檔是一種偽刪除手段)。這樣,整個段的索引信息就通過這些文檔有機的組成。
以上所闡述的,就是 Lucene所采用的索引文件格式。基本上而言,它是一個倒排索引,但是Lucene在文件的安排上做了一些努力,比如使用索引/信息文件的方式,從文件安排的形式上提高查找的效率。這是一種數(shù)據(jù)庫之外的處理方法,其有其優(yōu)點(格式平**立、速度快),也有其缺點(獨立性帶來的共享訪問接口問題等等),具體如何衡量兩種方法之間的利弊,本文這里就不討論了。
三、一些公用的基礎(chǔ)類
分析完索引文件格式,我們接下來應(yīng)該著手對存儲抽象也就是org.apache.lucenestore中的源碼做一些分析。我們先不著急分析這部分,而是分析圖2.1中基礎(chǔ)結(jié)構(gòu)封裝那一部分,因為這是整個系統(tǒng)的基石,然后我們在下一部分再來分析存儲抽象。
基礎(chǔ)結(jié)構(gòu)封裝,或者基礎(chǔ)類,由org.apache.lucene.util和org.apache.lucene.document兩個包組成,前者定義了一些常量和優(yōu)化過的常用的數(shù)據(jù)結(jié)構(gòu)和算法,后者則是對于文檔(document)和域(field)概念的一個類定義。以下我們用列表的方式來分析這些封裝類,指出其要點。
表 3.2 基礎(chǔ)類包org.apache.lucene.util
| 類 |
說明 |
| Arrays |
一個關(guān)于數(shù)組的排序方法的靜態(tài)類,提供了優(yōu)化的基于快排序的排序方法sort |
| BitVector |
C/C++語言中位域的java實現(xiàn)品,但是加入了序列化能力 |
| Constants |
常量靜態(tài)類,定義了一些常量 |
| PriorityQueue |
一個優(yōu)先隊列的抽象類,用于后面實現(xiàn)各種具體的優(yōu)先隊列,提供常數(shù)時間內(nèi)的最小元素訪問能力,內(nèi)部實現(xiàn)機制是哈析表和堆排序算法 |
表 3.3 基礎(chǔ)類包org.apache.lucene.document
| 類 |
說明 |
| Document |
是文檔概念的一個實現(xiàn)類,每個文檔包含了一個域表(fieldList),并提供了一些實用的方法,比如多種添加域的方法、返回域表的迭代器的方法 |
| Field |
是域概念的一個實現(xiàn)類,每個域包含了一個域名和一個值,以及一些相關(guān)的屬性 |
| DateField |
提供了一些輔助方法的靜態(tài)類,這些方法將java中Date和Time數(shù)據(jù)類型和String相互轉(zhuǎn)化 |
總的來說,這兩個基礎(chǔ)類包中含有的類都比較簡單,通過閱讀源代碼,可以很容易的理解,因此這里不作過多的展開。
四、存儲抽象
有了上面的知識,我們接下來來分析存儲抽象部分,也就是org.apache.lucene.store包。存儲抽象是唯一能夠直接對索引文件存取的包,因此其主要目的是抽象出和平臺文件系統(tǒng)無關(guān)的存儲抽象,提供諸如目錄服務(wù)(增、刪文件)、輸入流和輸出流。在分析其實現(xiàn)之前,首先我們看一下UML [22]圖。

圖 3.3 存儲抽象實現(xiàn)UML圖(一)

圖 3.4 存儲抽象實現(xiàn)UML圖(二)

圖 3.4 存儲抽象實現(xiàn)UML圖(三)
圖3.2到3.4展示了整個org.apache.lucene.store中主要的繼承體系。共有三個抽象類定義:Directory、 InputStream和OutputStrem,構(gòu)成了一個完整的基于抽象文件系統(tǒng)的存取體系結(jié)構(gòu),在此基礎(chǔ)上,實作出了兩個實現(xiàn)品:(FSDirectory,F(xiàn)SInputStream,F(xiàn)SOutputStream)和(RAMDirectory,RAMInputStream和 RAMOutputStream)。前者是以實際的文件系統(tǒng)做為基礎(chǔ)實現(xiàn)的,后者則是建立在內(nèi)存中的虛擬文件系統(tǒng)。前者主要用來永久的保存索引文件,后者的作用則在于索引操作時是在內(nèi)存中建立小的索引,然后一次性的輸出合并到文件中去,這一點我們在后面的索引邏輯部分能夠看到。此外,還定以了 org.apache.lucene.store.lock和org.apache.lucene.store.with兩個輔助內(nèi)部實現(xiàn)的類用在實現(xiàn) Directory方法的makeLock的時候,以在鎖定索引讀寫之前來讓客戶程序做一些準(zhǔn)備工作。
(FSDirectory, FSInputStream,F(xiàn)SOutputStream)的內(nèi)部實現(xiàn)依托于java語言中的io類庫,只是簡單的做了一個外部邏輯的包裝。這當(dāng)然要歸功于java語言所提供的跨平臺特性,同時也帶了一些隱患:文件存取的效率提升需要依耐于文件類庫的優(yōu)化。如果需要繼續(xù)優(yōu)化文件存取的效率,應(yīng)該還提供一個文件與目錄的抽象,以根據(jù)各種文件系統(tǒng)或者文件類型來提供一個優(yōu)化的機會。當(dāng)然,這是應(yīng)用開發(fā)者所不需要關(guān)系的問題。
(RAMDirectory,RAMInputStream和RAMOutputStream)的內(nèi)部實現(xiàn)就比較直接了,直接采用了虛擬的文件 RAMFile類(定義于文件RAMDirectory.java中)來表示文件,目錄則看作一個String與RAMFile對應(yīng)的關(guān)聯(lián)數(shù)組。 RAMFile中采用數(shù)組來表示文件的存儲空間。在此的基礎(chǔ)上,完成各項操作的實現(xiàn),就形成了基于內(nèi)存的虛擬文件系統(tǒng)。因為在實際使用時,并不會牽涉到很大字節(jié)數(shù)量的文件,因此這種設(shè)計是簡單直接的,也是高效率的。
這部分的實現(xiàn)在理清楚繼承體系后,相當(dāng)?shù)暮唵巍R虼私酉聛淼牟糠郑覀兛梢酝ㄟ^直接閱讀源代碼解決。接下來我們看看這個部分的源代碼如何在實際中使用的。
一般來說,我們使用的是抽象類提供的接口而不是實際的實現(xiàn)類本身。在實現(xiàn)類中一般都含有幾個靜態(tài)函數(shù),比如createFile,它能夠返回一個 OutputStream接口,或者openFile,它能夠返回一個InputStream接口,利用這些接口之中的方法,比如 writeString,writeByte等等,我們就能夠在抽象的層次上處理Lucene定義的數(shù)據(jù)類型的讀寫。簡單的說,Lucene中存儲抽象這部分設(shè)計時采用了工廠模式(Factory parttern)[23]。我們利用靜態(tài)類的方法也就是工廠來創(chuàng)建對象,返回接口,通過接口來執(zhí)行操作。
五、關(guān)于cLucene項目
這一部分詳細(xì)的說明了Lucene系統(tǒng)中所采用的索引文件格式、一些基礎(chǔ)類和存儲抽象。接下來我們來敘述一下我們在項目cLucene中重新實現(xiàn)這些結(jié)構(gòu)時候的一些考慮。
cLucene徹底的遵守了Lucene所定義的索引文件格式,這是Lucene對于各個兼容系統(tǒng)的基本要求。在此基礎(chǔ)上,cLucene系統(tǒng)和Lucene系統(tǒng)才能夠共享索引文件數(shù)據(jù)。或者說,cLucene生成的索引文件和Lucene生成的索引文件完全等價。
在基礎(chǔ)類問題上,cLucene同樣封裝了類似的結(jié)構(gòu)。我們同樣列表描述,請和前面的表3.2與3.3對照比較。
表 3.4 基礎(chǔ)類包cLucene::util
| 類 |
說明 |
| Arrays |
沒有實現(xiàn),直接利用了STL庫中的快排序算法實現(xiàn) |
| BitVector |
C/C++語言版本的實現(xiàn),與java實現(xiàn)版本類似 |
| Constants |
常量靜態(tài)類,定義了一些常量,但是與java版本不同的是,這里主要定義了一些宏 |
| PriorityQueue |
這是一個類型定義,直接利用STL庫中的std::priority_queue |
表 3.3 基礎(chǔ)類包cLucene::document
| 類 |
說明 |
| Document |
C/C++語言版本的實現(xiàn),與java實現(xiàn)版本類似 |
| Field |
C/C++語言版本的實現(xiàn),與java實現(xiàn)版本類似 |
| DateField |
沒有實現(xiàn),直接利用OpenTop庫中的ot::StringUtil |
存儲抽象的實現(xiàn)上,也同樣是類似于java實現(xiàn)。由于我們采用了OpenTop庫,因此同樣得以借助其中對于文件系統(tǒng)抽象的ot::io包來解決文件系統(tǒng)問題。這部分問題與前面一樣,存在優(yōu)化的可能。在實現(xiàn)的類層次上、對外接口上,均與java版本的一樣。
作者
Winter
一切復(fù)雜的排序操作,都可以通過STL方便實現(xiàn) !
0 前言: STL,為什么你必須掌握
對于程序員來說,數(shù)據(jù)結(jié)構(gòu)是必修的一門課。從查找到排序,從鏈表到二叉樹,幾乎所有的算法和原理都需要理解,理解不了也要死記硬背下來。幸運的是這些理論都已經(jīng)比較成熟,算法也基本固定下來,不需要你再去花費心思去考慮其算法原理,也不用再去驗證其準(zhǔn)確性。不過,等你開始應(yīng)用計算機語言來工作的時候,你會發(fā)現(xiàn),面對不同的需求你需要一次又一次去用代碼重復(fù)實現(xiàn)這些已經(jīng)成熟的算法,而且會一次又一次陷入一些由于自己疏忽而產(chǎn)生的bug中。這時,你想找一種工具,已經(jīng)幫你實現(xiàn)這些功能,你想怎么用就怎么用,同時不影響性能。你需要的就是STL, 標(biāo)準(zhǔn)模板庫!
西方有句諺語:不要重復(fù)發(fā)明輪子!
STL幾乎封裝了所有的數(shù)據(jù)結(jié)構(gòu)中的算法,從鏈表到隊列,從向量到堆棧,對hash到二叉樹,從搜索到排序,從增加到刪除......可以說,如果你理解了STL,你會發(fā)現(xiàn)你已不用拘泥于算法本身,從而站在巨人的肩膀上去考慮更高級的應(yīng)用。
排序是最廣泛的算法之一,本文詳細(xì)介紹了STL中不同排序算法的用法和區(qū)別。
1 STL提供的Sort 算法
C++之所以得到這么多人的喜歡,是因為它既具有面向?qū)ο蟮母拍睿直3至薈語言高效的特點。STL 排序算法同樣需要保持高效。因此,對于不同的需求,STL提供的不同的函數(shù),不同的函數(shù),實現(xiàn)的算法又不盡相同。
1.1 所有sort算法介紹
所有的sort算法的參數(shù)都需要輸入一個范圍,[begin, end)。這里使用的迭代器(iterator)都需是隨機迭代器(RadomAccessIterator), 也就是說可以隨機訪問的迭代器,如:it+n什么的。(partition 和stable_partition 除外)
如果你需要自己定義比較函數(shù),你可以把你定義好的仿函數(shù)(functor)作為參數(shù)傳入。每種算法都支持傳入比較函數(shù)。以下是所有STL sort算法函數(shù)的名字列表:
| 函數(shù)名 |
功能描述 |
| sort |
對給定區(qū)間所有元素進行排序 |
| stable_sort |
對給定區(qū)間所有元素進行穩(wěn)定排序 |
| partial_sort |
對給定區(qū)間所有元素部分排序 |
| partial_sort_copy |
對給定區(qū)間復(fù)制并排序 |
| nth_element |
找出給定區(qū)間的某個位置對應(yīng)的元素 |
| is_sorted |
判斷一個區(qū)間是否已經(jīng)排好序 |
| partition |
使得符合某個條件的元素放在前面 |
| stable_partition |
相對穩(wěn)定的使得符合某個條件的元素放在前面 |
其中nth_element 是最不易理解的,實際上,這個函數(shù)是用來找出第幾個。例如:找出包含7個元素的數(shù)組中排在中間那個數(shù)的值,此時,我可能不關(guān)心前面,也不關(guān)心后面,我只關(guān)心排在第四位的元素值是多少。
1.2 sort 中的比較函數(shù)
當(dāng)你需要按照某種特定方式進行排序時,你需要給sort指定比較函數(shù),否則程序會自動提供給你一個比較函數(shù)。
vector < int > vect;
//...
sort(vect.begin(), vect.end());
//此時相當(dāng)于調(diào)用
sort(vect.begin(), vect.end(), less<int>() );
上述例子中系統(tǒng)自己為sort提供了less仿函數(shù)。在STL中還提供了其他仿函數(shù),以下是仿函數(shù)列表:
| 名稱 |
功能描述 |
| equal_to |
相等 |
| not_equal_to |
不相等 |
| less |
小于 |
| greater |
大于 |
| less_equal |
小于等于 |
| greater_equal |
大于等于 |
需要注意的是,這些函數(shù)不是都能適用于你的sort算法,如何選擇,決定于你的應(yīng)用。另外,不能直接寫入仿函數(shù)的名字,而是要寫其重載的()函數(shù):
less<int>()
greater<int>()
當(dāng)你的容器中元素時一些標(biāo)準(zhǔn)類型(int float char)或者string時,你可以直接使用這些函數(shù)模板。但如果你時自己定義的類型或者你需要按照其他方式排序,你可以有兩種方法來達到效果:一種是自己寫比較函數(shù)。另一種是重載類型的'<'操作賦。
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
using namespace std;
class myclass {
public:
myclass(int a, int b):first(a), second(b){}
int first;
int second;
bool operator < (const myclass &m)const {
return first < m.first;
}
};
bool less_second(const myclass & m1, const myclass & m2) {
return m1.second < m2.second;
}
int main() {
vector< myclass > vect;
for(int i = 0 ; i < 10 ; i ++){
myclass my(10-i, i*3);
vect.push_back(my);
}
for(int i = 0 ; i < vect.size(); i ++)
cout<<"("<<vect[i].first<<","<<vect[i].second<<")\n";
sort(vect.begin(), vect.end());
cout<<"after sorted by first:"<<endl;
for(int i = 0 ; i < vect.size(); i ++)
cout<<"("<<vect[i].first<<","<<vect[i].second<<")\n";
cout<<"after sorted by second:"<<endl;
sort(vect.begin(), vect.end(), less_second);
for(int i = 0 ; i < vect.size(); i ++)
cout<<"("<<vect[i].first<<","<<vect[i].second<<")\n";
return 0 ;
}
知道其輸出結(jié)果是什么了吧:
(10,0)
(9,3)
(8,6)
(7,9)
(6,12)
(5,15)
(4,18)
(3,21)
(2,24)
(1,27)
after sorted by first:
(1,27)
(2,24)
(3,21)
(4,18)
(5,15)
(6,12)
(7,9)
(8,6)
(9,3)
(10,0)
after sorted by second:
(10,0)
(9,3)
(8,6)
(7,9)
(6,12)
(5,15)
(4,18)
(3,21)
(2,24)
(1,27)
1.3 sort 的穩(wěn)定性
你發(fā)現(xiàn)有sort和stable_sort,還有 partition 和stable_partition, 感到奇怪吧。其中的區(qū)別是,帶有stable的函數(shù)可保證相等元素的原本相對次序在排序后保持不變。或許你會問,既然相等,你還管他相對位置呢,也分不清楚誰是誰了?這里需要弄清楚一個問題,這里的相等,是指你提供的函數(shù)表示兩個元素相等,并不一定是一摸一樣的元素。
例如,如果你寫一個比較函數(shù):
bool less_len(const string &str1, const string &str2)
{
return str1.length() < str2.length();
}
此時,"apple" 和 "winter" 就是相等的,如果在"apple" 出現(xiàn)在"winter"前面,用帶stable的函數(shù)排序后,他們的次序一定不變,如果你使用的是不帶"stable"的函數(shù)排序,那么排序完后,"Winter"有可能在"apple"的前面。
1.4 全排序
全排序即把所給定范圍所有的元素按照大小關(guān)系順序排列。用于全排序的函數(shù)有
template <class RandomAccessIterator>
void sort(RandomAccessIterator first, RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void sort(RandomAccessIterator first, RandomAccessIterator last,
StrictWeakOrdering comp);
template <class RandomAccessIterator>
void stable_sort(RandomAccessIterator first, RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void stable_sort(RandomAccessIterator first, RandomAccessIterator last,
StrictWeakOrdering comp);
在第1,3種形式中,sort 和 stable_sort都沒有指定比較函數(shù),系統(tǒng)會默認(rèn)使用operator< 對區(qū)間[first,last)內(nèi)的所有元素進行排序, 因此,如果你使用的類型義軍已經(jīng)重載了operator<函數(shù),那么你可以省心了。第2, 4種形式,你可以隨意指定比較函數(shù),應(yīng)用更為靈活一些。來看看實際應(yīng)用:
班上有10個學(xué)生,我想知道他們的成績排名。
#include <iostream>
#include <algorithm>
#include <functional>
#include <vector>
#include <string>
using namespace std;
class student{
public:
student(const string &a, int b):name(a), score(b){}
string name;
int score;
bool operator < (const student &m)const {
return score< m.score;
}
};
int main() {
vector< student> vect;
student st1("Tom", 74);
vect.push_back(st1);
st1.name="Jimy";
st1.score=56;
vect.push_back(st1);
st1.name="Mary";
st1.score=92;
vect.push_back(st1);
st1.name="Jessy";
st1.score=85;
vect.push_back(st1);
st1.name="Jone";
st1.score=56;
vect.push_back(st1);
st1.name="Bush";
st1.score=52;
vect.push_back(st1);
st1.name="Winter";
st1.score=77;
vect.push_back(st1);
st1.name="Andyer";
st1.score=63;
vect.push_back(st1);
st1.name="Lily";
st1.score=76;
vect.push_back(st1);
st1.name="Maryia";
st1.score=89;
vect.push_back(st1);
cout<<"------before sort..."<<endl;
for(int i = 0 ; i < vect.size(); i ++) cout<<vect[i].name<<":\t"<<vect[i].score<<endl;
stable_sort(vect.begin(), vect.end(),less<student>());
cout <<"-----after sort ...."<<endl;
for(int i = 0 ; i < vect.size(); i ++) cout<<vect[i].name<<":\t"<<vect[i].score<<endl;
return 0 ;
}
其輸出是:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Bush: 52
Jimy: 56
Jone: 56
Andyer: 63
Tom: 74
Lily: 76
Winter: 77
Jessy: 85
Maryia: 89
Mary: 92
sort采用的是成熟的"快速排序算法"(目前大部分STL版本已經(jīng)不是采用簡單的快速排序,而是結(jié)合內(nèi)插排序算法)。
注1,可以保證很好的平均性能、復(fù)雜度為n*log(n),由于單純的快速排序在理論上有最差的情況,性能很低,其算法復(fù)雜度為n*n,但目前大部分的STL版本都已經(jīng)在這方面做了優(yōu)化,因此你可以放心使用。stable_sort采用的是"歸并排序",分派足夠內(nèi)存是,其算法復(fù)雜度為n*log(n), 否則其復(fù)雜度為n*log(n)*log(n),其優(yōu)點是會保持相等元素之間的相對位置在排序前后保持一致。
1.5 局部排序
局部排序其實是為了減少不必要的操作而提供的排序方式。其函數(shù)原型為:
template <class RandomAccessIterator>
void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last,
StrictWeakOrdering comp);
template <class InputIterator, class RandomAccessIterator>
RandomAccessIterator partial_sort_copy(InputIterator first, InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last);
template <class InputIterator, class RandomAccessIterator,
class StrictWeakOrdering>
RandomAccessIterator partial_sort_copy(InputIterator first, InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last, Compare comp);
理解了sort 和stable_sort后,再來理解partial_sort 就比較容易了。先看看其用途: 班上有10個學(xué)生,我想知道分?jǐn)?shù)最低的5名是哪些人。如果沒有partial_sort,你就需要用sort把所有人排好序,然后再取前5個。現(xiàn)在你只需要對分?jǐn)?shù)最低5名排序,把上面的程序做如下修改:
stable_sort(vect.begin(), vect.end(),less<student>());
替換為:
partial_sort(vect.begin(), vect.begin()+5, vect.end(),less<student>());
輸出結(jié)果為:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Bush: 52
Jimy: 56
Jone: 56
Andyer: 63
Tom: 74
Mary: 92
Jessy: 85
Winter: 77
Lily: 76
Maryia: 89
這樣的好處知道了嗎?當(dāng)數(shù)據(jù)量小的時候可能看不出優(yōu)勢,如果是100萬學(xué)生,我想找分?jǐn)?shù)最少的5個人......
partial_sort采用的堆排序(heapsort),它在任何情況下的復(fù)雜度都是n*log(n). 如果你希望用partial_sort來實現(xiàn)全排序,你只要讓middle=last就可以了。
partial_sort_copy其實是copy和partial_sort的組合。被排序(被復(fù)制)的數(shù)量是[first, last)和[result_first, result_last)中區(qū)間較小的那個。如果[result_first, result_last)區(qū)間大于[first, last)區(qū)間,那么partial_sort相當(dāng)于copy和sort的組合。
1.6 nth_element 指定元素排序
nth_element一個容易看懂但解釋比較麻煩的排序。用例子說會更方便:
班上有10個學(xué)生,我想知道分?jǐn)?shù)排在倒數(shù)第4名的學(xué)生。
如果要滿足上述需求,可以用sort排好序,然后取第4位(因為是由小到大排), 更聰明的朋友會用partial_sort, 只排前4位,然后得到第4位。其實這是你還是浪費,因為前兩位你根本沒有必要排序,此時,你就需要nth_element:
template <class RandomAccessIterator>
void nth_element(RandomAccessIterator first, RandomAccessIterator nth,
RandomAccessIterator last);
template <class RandomAccessIterator, class StrictWeakOrdering>
void nth_element(RandomAccessIterator first, RandomAccessIterator nth,
RandomAccessIterator last, StrictWeakOrdering comp);
對于上述實例需求,你只需要按下面要求修改1.4中的程序:
stable_sort(vect.begin(), vect.end(),less<student>());
替換為:
nth_element(vect.begin(), vect.begin()+3, vect.end(),less<student>());
運行結(jié)果為:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Jone: 56
Bush: 52
Jimy: 56
Andyer: 63
Jessy: 85
Mary: 92
Winter: 77
Tom: 74
Lily: 76
Maryia: 89
第四個是誰?Andyer,這個倒霉的家伙。為什么是begin()+3而不是+4? 我開始寫這篇文章的時候也沒有在意,后來在
ilovevc 的提醒下,發(fā)現(xiàn)了這個問題。begin()是第一個,begin()+1是第二個,... begin()+3當(dāng)然就是第四個了。
1.7 partition 和stable_partition
好像這兩個函數(shù)并不是用來排序的,'分類'算法,會更加貼切一些。partition就是把一個區(qū)間中的元素按照某個條件分成兩類。其函數(shù)原型為:
template <class ForwardIterator, class Predicate>
ForwardIterator partition(ForwardIterator first,
ForwardIterator last, Predicate pred)
template <class ForwardIterator, class Predicate>
ForwardIterator stable_partition(ForwardIterator first, ForwardIterator last,
Predicate pred);
看看應(yīng)用吧:班上10個學(xué)生,計算所有沒有及格(低于60分)的學(xué)生。你只需要按照下面格式替換1.4中的程序:
stable_sort(vect.begin(), vect.end(),less<student>());
替換為:
student exam("pass", 60);
stable_partition(vect.begin(), vect.end(), bind2nd(less<student>(), exam));
其輸出結(jié)果為:
------before sort...
Tom: 74
Jimy: 56
Mary: 92
Jessy: 85
Jone: 56
Bush: 52
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
-----after sort ....
Jimy: 56
Jone: 56
Bush: 52
Tom: 74
Mary: 92
Jessy: 85
Winter: 77
Andyer: 63
Lily: 76
Maryia: 89
看見了嗎,Jimy,Jone, Bush(難怪說美國總統(tǒng)比較笨

)都沒有及格。而且使用的是stable_partition, 元素之間的相對次序是沒有變.
2 Sort 和容器
STL中標(biāo)準(zhǔn)容器主要vector, list, deque, string, set, multiset, map, multimay, 其中set, multiset, map, multimap都是以樹結(jié)構(gòu)的方式存儲其元素詳細(xì)內(nèi)容請參看:
學(xué)習(xí)STL map, STL set之?dāng)?shù)據(jù)結(jié)構(gòu)基礎(chǔ). 因此在這些容器中,元素一直是有序的。
這些容器的迭代器類型并不是隨機型迭代器,因此,上述的那些排序函數(shù),對于這些容器是不可用的。上述sort函數(shù)對于下列容器是可用的:
如果你自己定義的容器也支持隨機型迭代器,那么使用排序算法是沒有任何問題的。
對于list容器,list自帶一個sort成員函數(shù)list::sort(). 它和算法函數(shù)中的sort差不多,但是list::sort是基于指針的方式排序,也就是說,所有的數(shù)據(jù)移動和比較都是此用指針的方式實現(xiàn),因此排序后的迭代器一直保持有效(vector中sort后的迭代器會失效).
3 選擇合適的排序函數(shù)
為什么要選擇合適的排序函數(shù)?可能你并不關(guān)心效率(這里的效率指的是程序運行時間), 或者說你的數(shù)據(jù)量很小, 因此你覺得隨便用哪個函數(shù)都無關(guān)緊要。
其實不然,即使你不關(guān)心效率,如果你選擇合適的排序函數(shù),你會讓你的代碼更容易讓人明白,你會讓你的代碼更有擴充性,逐漸養(yǎng)成一個良好的習(xí)慣,很重要吧 。
如果你以前有用過C語言中的qsort, 想知道qsort和他們的比較,那我告訴你,qsort和sort是一樣的,因為他們采用的都是快速排序。從效率上看,以下幾種sort算法的是一個排序,效率由高到低(耗時由小變大):
- partion
- stable_partition
- nth_element
- partial_sort
- sort
- stable_sort
記得,以前翻譯過Effective STL的文章,其中對
如何選擇排序函數(shù)總結(jié)的很好:
- 若需對vector, string, deque, 或 array容器進行全排序,你可選擇sort或stable_sort;
- 若只需對vector, string, deque, 或 array容器中取得top n的元素,部分排序partial_sort是首選.
- 若對于vector, string, deque, 或array容器,你需要找到第n個位置的元素或者你需要得到top n且不關(guān)系top n中的內(nèi)部順序,nth_element是最理想的;
- 若你需要從標(biāo)準(zhǔn)序列容器或者array中把滿足某個條件或者不滿足某個條件的元素分開,你最好使用partition或stable_partition;
- 若使用的list容器,你可以直接使用partition和stable_partition算法,你可以使用list::sort代替sort和stable_sort排序。若你需要得到partial_sort或nth_element的排序效果,你必須間接使用。正如上面介紹的有幾種方式可以選擇。
總之記住一句話:
如果你想節(jié)約時間,不要走彎路, 也不要走多余的路!
4 小結(jié)
討論技術(shù)就像個無底洞,經(jīng)常容易由一點可以引申另外無數(shù)個技術(shù)點。因此需要從全局的角度來觀察問題,就像觀察STL中的sort算法一樣。其實在STL還有make_heap, sort_heap等排序算法。本文章沒有提到。本文以實例的方式,解釋了STL中排序算法的特性,并總結(jié)了在實際情況下應(yīng)如何選擇合適的算法。
5 參考文檔
條款31:如何選擇排序函數(shù) The Standard Librarian: Sorting in the Standard Library Effective STL中文版 Standard Template Library Programmer's Guide