中文:http://www.microsoft.com/china/MSDN/library/enterprisedevelopment/softwaredev/enterpriseperformance.mspx?mfr=true
本文��Z�� Visual Studio 2005 的预发布版本。文中包含的所有信息均有可能变更�?/p>
本文讨论�Q?
| �?/td> | 分析器的内部工作方式 |
| �?/td> | EPT 的灵�z�d���? |
| �?/td> | 一个供分析的示例应用程�?/p> |
代码可从以下位置下蝲�Q?/b>
EnterprisePerformance.exe (258KB)
快速代码仍然很受欢�q�。即使我用来键入本文的计���机��h�����_��的能力和内存�Q�能够同时控制一座原子能发电厂、一个火星�O游计划以及美国西部上�I�的�I�Z��交通,�q�且仍然��h��充��的能力来处理星际探烦中的 SETI 数据包,但这�q�不意味着开发�h员不再需要担心其代码的速度和效率。在�q�去�q�行 Win32�] 本机开发的日子里,我们不仅需要担心速度�Q�而且�q�要担心 PC �q�_��上那些��o�����厌的讉K��冲突�Q�对于你们这些老家伙,�q�有“全局保护错误”和“不可恢复的应用�E�序错误”)。尽���托���代码已�l�消除了其中的一些担心,但它只意味着您所�l�历的那些性能问题可能比以前更加难以捉摸。主要原因是�Q�在使用托管代码�Ӟ��我们不具有在�q�行本机开发时所拥有的简便的�q�行库视图�?/p>
有许多次�Q�当我正在��用客��L���Ӟ��我不知道如何解决恶性的性能问题。当�Ӟ���q�些性能问题不会出现在�Q何测试系�l�中�Q�它们只会出现在真实世界的生产中。由于公��p���a��q�行�?(CLR) 是黑盒,因此如果我希望找到在���试�pȝ��中重复性能问题的方法,则很��N�����会发生什么事情。尽���在市场中有一些第三方商业性能工具�Q�但�q�些工具中的大多数都会对�pȝ��造成�q�多的干扎ͼ�以至于根本不能考虑在生产系�l�中使用。这也就是当我看�?Microsoft ���提供一个全新的分析�?�?Enterprise Performance Tool (EPT) 以作�?Visual Studio�] 2005 Team Developer Edition 的一部分�Ӟ��感到如此兴奋的原因。它是我可以真正考虑在生产系�l�中使用的第一个分析系�l�,因�ؓ它提供了一些非常轻便的攉���性能数据的手�D�c��因为我曄���领导�q�一�U�最畅销的商业分析器的开发工作,所以我能够理解在不产生太多�pȝ��开销的情况下攉���有用分析数据的困隄���度�?/p>
在本文中�Q�我���介�l?EPT 的基本原理,�q�向您说明如何开始��用它。因为分析器所��h��的复杂性,所以在���来某一期中�Q�我���讨论如何���?EPT 来跟�t�您可能在同事的代码中遇到的实际性能问题�Q�我知道您的代码非常完美�Q�)。请��C���Q�EPT 正处在测试阶�D�(我��用的�?Burton Beta 1 ��h��位版�?40607.83�Q�,�q�且在该产品发布之前�Q�可能会�?UI 或某些特定步骤进行更攏V��在�?EPT �q�行介绍之前�Q�我希望��q��儿时间谈��Z��下分析器通常是如何工作的�Q�以便您可以更好��C��解是什么�� Enterprise Performance Tool 变得如此与众不同�?/p>
分析器的基本原理
在您�~�写分析器时�Q�可以选择两种攉���数据的方式中的一�U�:探测和采栗���这两种方式都十分有效,但是每种方式都有它的折衷�Ҏ��。探���分析器攉���数据的方式是在应用程序中插入探测或挂钩,以便在程序执行该挂钩时就调用分析器运行库。要攄���探测�Q�分析器需要在�~�译步骤中将应用�E�序仪表化,重写已经�~�译的二�q�制文�g�Q�或者即时将应用�E�序仪表化。要查看��Z�� .NET 的应用程序的探测分析器方法示例,请阅�?Aleksandr Mikunov 的一���非常出色的文章 —�?a target="_blank">Rewrite MSIL Code On the Fly with the .NET Framework Profiling API”(该文章摘�?MSDN�]Magazine 2003 �q?9 月刊�Q�。当我开始讨�?EPT 的时候,您将看到它��用术语“��A表化”来表示探测�Ҏ���?/p>
探测分析器方法的主要优势在于�Q�当应用�E�序执行�Ӟ�����始�l�调用所插入的探���。这��P��分析器运行库���对�q�行��h��完整的认识,因此在生成关键信息(例如�Q�函��C��间的父子关系�Q�时可以���保正确�Q��ƈ且分析器可以报告完美的调用树�Q�以便您可以��L��扑ֈ���p��最长时间的调用路径。��用探���分析器�Ӟ��没有什么事情能够阻止开发�h员只在函数入口和出口处插入探���。可以在源代码行�U�别攄���额外的探���,以便您对函数��h��完整的认识�?/p>
但是�Q�探���分析器所提供的详�l�视囑օ�有一些缺炏V��第一个缺�Ҏ��仪表化方案��用�v来可能很�ȝ���Q��ƈ且因为它是在二进制��别重写,因此存在很多可能引入潜在错误的领域。正如您可以惛_��到的那样�Q�这些探���还占用了空��_��从而导致一些代码膨胀和较低的性能。对于完全��A表化的应用程序,探测分析器可能会��D��速度大幅度下降,以至于几乎不可能在生产系�l�上�q�行仪表化的二进制文�Ӟ��从而��您在最需要该分析器的时候却无法利用它�?/p>
正如其名�U�所暗示的那��P��采样分析器按照预先定义的旉���间隔获得应用�E�序中正在执行的操作的快照。大多数开发�h员都没有意识�?Microsoft ��L��在他们的开发环境中随附了一个采样分析器。它被称�����试器�Q?如果您开始调试应用程序,�q�且每隔 30 �U�左叛_��中断臌���试器�Q�则您可以注意到应用�E�序�U�程正在何处执行�Q�以便很好地了解应用�E�序在一�ơ运行过�E�中执行了哪些操作。我已经通过手动完成采样分析器的工作�Q�解决了很多生��性能问题�?/p>
佉K��样分析器如此有�h值的原因在于�Q�它们具有比探测分析器小得多的系�l�开销。这意味着�Q�您可以有更高的��Z��在生产系�l�中使用它们�Q�而不会��服务器疲于奔命以至于停机。采样分析器的问题在于,从应用程序中获得的所有样本很有可能根本不昄�����M��代码。例如,如果您具有大量��用数据库的应用程序,则所有样本都可以来自数据库访问程序集的内部。最后,只抓取每个线�E�的当前执行指��o的传�l�采样分析器会��得确定方法之间的父子关系变得十分困难�Q�因而确定性能最差的执行代码途径要困隑־�多�?/p>
Enterprise Performance Tool 的基本原�?/p>
在了解分析器的操作方式之后,我就可以讨论 EPT 所采取的方式了。简单地��_��它既是采样分析器�Q�又是探���分析器�Q�Microsoft �U�C��为“��A表化”)。其思想是,您在开始时���通过采样分析器来查看应用�E�序性能�Q�以获得常规性能特征�Q�以便您可以开始将注意力集中于应用�E�序的热炚w��题上。在您了解具有一些问题的�E�序集之后,���可以求助于仪表化分析以查看特定的问题领域,以便修复它们。当�Ӟ��如果您要执行单元性能���试�Q�则没有什么能够阻止您直接转到对特定模块进行��A表化�Q�以便在聚焦�Ҏ��中查看它们的性能�?/p>
�?EPT 采样分析器有���的部分原因在于�Q�您可以使用大量��目来触发样本。默认的采样�Ҏ��旉���周期�Q��ƈ且可能是您��L��使用的采��L��。默认情况下�Q�每一百万个时钟周期采样一�ơ,但是您可以将采样间隔的时钟周期数更改为您喜欢的�Q何��|��可是该��D�����,EPT 所��D��的系�l�开销���p��大。对于生产服务器�Q�您可以���该数字讄���为某个非帔R��的数字(如五百万�Q�,以�ɾpȝ��开销保持在合理的水��^�Q�同时不会完全破坏进�E�中的可用性。正如您预料的那��P��每五百万个时钟周期采样一�ơ将意味着您需要��应用�E�序�q�行相当长的旉����Q�以便在您的热点区域中获得良好的��h��分布�?/p>
如果您的应用�E�序使用了很多内存,则可以选择�?EPT 采样分析器改为在出现��错误时触发。这��P��您就可以在数据被交换�?RAM 时获得性能快照�Q��ƈ且可以看到是谁在执行推送操作。如果初始分析器�q�行表明您在代码外部的区域中��p��了大量时��_��则可以告诉分析器改�ؓ��Z���pȝ��调用来完成采栗���如果您要分析具有大量线�E�的多线�E�应用程序,则该采样�l�计信息会对您在从用��h��式�{换到内核模式�Q�这表明某些�U�程可能会不必要地在内核对象上阻塞)时的数据�q�行拍照。您可以用于采样触发器的最后一些值是 CPU 所支持的各�U�性能计数器,例如�Q�分支计数或�~�存丢失。这是一个只有极���数人才���实需要的高��选项�Q�但是如果您���实需要该数据�Q�那么知道该数据存在也不错�?/p>
那些忙碌�?Redmontonian �q�解决了调用堆栈问题 �?�q�是�Ҏ��用的采样分析器造成障碍的最大问题之一。正如我在前面提到的那样�Q�大多数采样分析器在采样时只是对当前正在执行的指令进行拍照。Microsoft 解决了如何将极快的堆栈遍历结合到他们的采样分析器部分中,以便您能够获得样本的好处�Q��ƈ且知道在执行该样本时是如何到��N��里的。这使得���这些快照与代码重新兌���变得更加�Ҏ���?/p>
在讨论您可以分析的应用程序之前,我想提几件您很可能觉得有���的事情。第一件事情是�Q�如果您认�ؓ Microsoft 是从头开发该性能工具的,那么您只猜对了一半。在 Microsoft 内部�Q�开发团队一直在使用 EPT 的前�w�(名�ؓ Call Attribute Profiler (CAP)�Q�它使用仪表化)�?Low Overhead Profiler (LOP) �?一个采样分析器。由�?Microsoft 开发了�q�些工具以收集有兛_��用程序(例如�Q�操作系�l�和整个 Office 套�g�Q�的性能信息�Q�因此它们甚至不会给您的应用�E�序带来什么负担。我曄���使用�q?EPT 的前�w�,所以我可以告诉您公��q��本��用�v来会�Ҏ��多少。此外,它们�q�具有一些极为有���的功能�Q�稍后我���予以讨论)�?/p>
�W�二个有���的事项�?EPT 所支持的技术有兟뀂尽���某些�h可能认�ؓ�׃�� Microsoft 非常偏重�?.NET Framework�Q�因此无法将 EPT 用于 Win32 应用�E�序或本��Z��码,�?EPT 团队实际上已�l�承诺支持所有的 Win32 本机应用�E�序以及 .NET 代码。这意味着�Q�无论您使用哪种技术(ASP.NET、Windows�] �H�体、MFC �?Win32 服务�Q�,您都��h��完全的采样和仪表化支持。您���看刎ͼ��?Visual Studio .NET 中,跨技术���?EPT 没有��M��差异�?/p>
实际�?EPT 讄���非常�q�_���Q�只需�?Visual Studio .NET 安装�E�序的“Enterprise Tools”树控�g中选择“Enterprise Performance Tool”即可。当�Ӟ��因�ؓ您知�?EPT 仍然是一个测试��品,所以您的第一个反应可能是�q�行虚拟 PC�Q��ƈ在那里安全地包含所有内宏V��但是,��Z��执行采样分析�Q�EPT 使用内核模式讑֤�驱动�E�序来响�?CPU 性能计数器中断,不过令�h遗憾的是�Q�虚�?PC 没有实现计数器。它也没有模拟高�U�可�~�程中断控制�?(APIC)�Q�而这两者都是内核设备驱动程序完成其工作所必需的。好消息是,如果您没有额外的计算��Z��便安�?EPT�Q�那么您也�ƈ非完全不�q�,因�ؓ仪表分析器仍然能够工作。如果您没有多余的计���机以便安装 EPT�Q�那么这是一个让公司为您购买另一台计���机的好借口�?/p>
Animated Algorithm
要学习�Q何工��L��用法�Q�您都需要一个合适的�C�Z��应用�E�序�Q�以便能够最佛_��利用该工兗���在���试周期的这一时刻�Q�EPT 没有随附��M���C�Z���Q�但是在我的���盘上已�l�有了一个完���的分析器示例。早些时候,我正在尝试解军_��何在 Windows �H�体应用�E�序中��用多�U�程的问题,因此我编写了一个名�?Animated Algorithm 的了不�v的小�E�序�Q�该�E�序可实时激�z�d��量排序算法�?b>�?1 昄���我的�C�Z��应用�E�序已经准备好排序�?/p>

�?1 正在工作�?Animated Algorithm
Animated Algorithm 使您可以在窗体的�l�合框中�Q�从 15 个不同的排序���法中进行选择。“Options”菜单��您可以选择各个元素交换或设�|�之间的休眠旉����Q�以便您可以降低囑�Ş更新的速度�?/p>
我不久前使用 Microsoft�] .NET Framework 版本 1.1 �~�写�?Animated Algorithm�Q�因此您不会在代码中扑ֈ���M��奇特的泛型或新的 BackgroundWorker ��V��NSORT �E�序集中的排序算法来自由 Jonathan de Halleux、Marc Clifton �?Robert Rohde 张脓�?The Code Project 上的一���优�U�文章�Q�请参阅 Sorting Algorithms In C#�Q�,该程序集���算法封装到公共�l�构中,以便您可以轻村֜�替换执行元素交换和设�|�的�c�R��因为它们具有非常好的体�pȝ��构,所以我需要关心的所有内容�ؓ UI 部分�?/p>
在本文的其余部分中,我将分析 Animated Algorithm �E�序。如�?EPT 团队���该�E�序作�ؓ�C�Z��应用�E�序随附在��品中�Q�则会非常棒。(哈哈。)
EPT 入门
�?Visual Studio 2005 Beta 1 中,在哪里可以找�?EPT 当然是不明显的。EPT 在您启动 Performance Wizard�Q�它位于“Tools”菜单下�Q�时启动�Q��ƈ且无论是否打开��目�Q�它都存在。请��C���Q�Performance Wizard 所创徏的性能会话不是��目的一部分�Q�它们实际上是具有自��q�� IDE �H�口�Q�称�?Performance Explorer�Q�的单独文�g。您可以通过从“File”|“Open”对话框中选择 PSESS 文�g�Q�来打开您创建的性能会话�?/p>
如果您在单步执行 Performance Wizard 时没有打开��目�Q�则所产生的性能会话���与您指定的二进制文件相兌���。但是,在测试版中,在您指定要运行的二进制文件时�Q�必���L��开兌���的项目。我只是想顺便提一下这个小���的技巧,因�ؓ当我�W�一�ơ遇到该问题�Ӟ��它确实让我困惑不巌Ӏ?/p>
在您启动 Performance Wizard 以后�Q�呈现在您面前的�W�一个屏�q�要求您选择要分析的应用�E�序。如果您打开了一个可生成多个�E�序集的��目�Q�如 Animated Algorithm�Q�,则只能从该向��g��选取一个程序集。如果要�q�行采样�Q�则只选取�q�一个程序集是很好的�Q�因�?EPT 采样会分析加载的所有程序集�Q�包括那些来自框架类库的�E�序集)。但是,如果您要对多个程序集执行仪表化分析,�?Performance Wizard 只选择�q�一个程序集�Q�因此您���需要在 Performance Explorer 中所生成的性能会话中指定其他项目或�E�序集。稍后我���向您说明如何完成该工作�?/p>
在选择了要在性能会话中��用的�E�序集或��目之后�Q�您必须选取分析�Ҏ��。在 Performance Explorer 中的��M��位置�Q�您都可以在采样和��A表化之间切换�Q�以满��自己的需要;您在该向导页中进行的选择只表�C�您最初希望执行的操作。在选择了分析方法之后,向导���基本完成了。对�?EPT 的最�l�版本,您将�?Performance Wizard 中具有用于指定附加信息的更多选项。最�l�版本还�����您可以直接从 Performance Explorer 中创建性能会话�?/p>
�?2 昄����?Performance Explorer 在刚刚完�?Performance Wizard 步骤以创�?AnimatedAlgorithms ��目的��A表化�q�行之后的窗口。要��d��另一个项目的输出二进制文�Ӟ��请右键单几Z��Targets”文件夹�Q�然后从上下文菜单中选择“Add Target Project”。如果要��d��与该��目没有兌���的特定二�q�制文�g�Q�请选择另一个选项 —“Add Target Binary”。如果您已经选择了“Add Target Project”,则可以在产生的对话框中从已打开的解��x��案中选择其他��目�?/p>

�?2 Performance Explorer
如果您已�l�选择了��A表化�q�行�Q�它��q��色启动箭头下面的下拉列表框中的文本表�C�)�Q�则二进制文件��A表化���在�E�序执行之前发生。如果您不希望针对运行��A表化某个特定的二�q�制文�g�Q�则请右键单击该二进制文�Ӟ���q�取消选中“Instrument Binary”菜单选项�?/p>
如果您已�l�选择了采样分析,�q�且希望附加到某个正在运行的��目�Q�则单击“Attach/Detach”按钮(“Start”按钮右侧的斜向���头�Q�将呈现“Attach Profiler to Process”对话框。通过 EPT�Q�您可以�Ҏ��需要附加到��L��多的�q�程�Q�以便获得对应用�E�序的认识。“Attach Profiler to Process”对话框�q�允许您从特定的二进制文件中分离分析。在���来的某一�?MSDN Magazine 中,我将更详�l�地讨论如何附加到现有的�q�程�Q�特别是��Z���q�行 ASP.NET 性能调整�Q��?/p>
Performance Explorer �H�口�剙��的最后一个按钮是无所不在的“Properties”按钮。在启动分析�q�行之前�Q�您可能希望���览一下性能会话属性,以设�|�几个关键属性。第一个属性位于“General”选项卡上�Q�它是您希望为性能会话存储性能报告的位�|�。在分析��目�Ӟ��默认讄���是将报告存储在与解决�Ҏ��相同的目录中。但更好的做法是���性能会话和它们的相应报告攄���在它们自��q��目录中,以便您可以更�Ҏ��地存储特定的�q�行集。这栯���可以更容易地分析之前和之后的情况�Q�以便查看您所�q�行的代码更改的影响�?/p>
在“General”选项卡上�Q�您�q�可以在仪表化和采样分析之间切换�Q�这会更改在 Performance Explorer 中显�C�的��|��。在我进行的性能调整中,我喜�Ƣ将特定的会话专用于单个�c�d��的分析,以避免出��C��报告有关的�淆。没有�Q何事情阻止您为所有种�cȝ��特定�Ҏ���Q�涵盖从分析�c�d��到单个二�q�制文�g仪表化的所有方案)创徏��C��百计的不同性能会话文�g。我�q�将提一下“General”选项卡上的最后一个项�Q�它��h��一个非常诱人的名称 —“Managed Allocation Profiling”,�怿��q�会使您感到更加好奇。在我讨论完常规分析之后�Q�我���返回到该项�?/p>
“Performance Session”属性页上的另一个有���的选项卡是“Sampling”选项卡(请参�?b>�?3�Q�。在�q�里�Q�您可以告诉 EPT 您要执行哪种�c�d��的采栗���正如我在前面提到的那样�Q�您对于希望如何�q�行采样��h��非常好的控制�?/p>

�?3 各种 EPT 采样计数器选项
在执行分析运行时�Q�EPT 会在二进制文件在���盘中所处的位置上将其��A表化。如果您希望�����A表化的二�q�制文�g�U�d��到另一个位�|�,请选择“Performance Session”属性页中的“Binary”选项卡,然后选中“Relocate Instrumented Binaries”(它与 REBASE 样式的重定位�l�对没有��M��关系�Q�,�q�且指定您希望将更改后的二进制文件移至何处�?/p>
“Instrumentation”选项卡��您可以指定希望在仪表化发生之前和之后�q�行的程序。如果您需要对仪表化的二进制文件执行其他�Q务(例如�Q�将其移动到全局�E�序集缓存中�?Web 服务器上的特定位�|�)�Q�则该选项卡可能很有用。“Advanced”选项卡在该测试版中未公开。最后,通过“Counters”选项卡,您可以告�?EPT 从系�l�的 CPU 中收集其他数据,例如�Q�L2 �?L3 �~�存��d��不中。显�Ӟ���q�些选项是只有少数开发�h员才会需要的非常高��的选项�Q�但是如果您���实需要它们,那么它们可以发挥巨大的作用�?/p>
在我�l�箋讨论查看采样数据之前�Q�我��x��一下,“Performance Explorer”窗口可以根据您的需要打开��L��多个性能会话。当您希望观察特定的前后�Ҏ���Q�或者希望用不同的��A表化二进制文件执行单独的���试�q�行�Ӟ���q�一�Ҏ��为有用。当您打开多个性能会话�Ӟ��应当���保右键单击特定的会话,选择“Set as Current Session”以便让该会话的讄���执行�Q�然后将报告归档到它的报告节点中�?/p>
查看分析器数�?/p>
���性能会话讄���为您希望执行的操作以后,���可以启动分析了。我���首先对 Animated Algorithm 执行采样分析�Q�以查看我是否可以找��C��些热炏V��从采样中获得良好数据的关键在于执行较长旉���的运行。对�?Animated Algorithm�Q�我会将 15 个排序算法中的每一个算法运行两�ơ,�q�将采样讄���为默认的一百万个时钟周期�?/p>
在完成某个运行之后,EPT 会将该运行的报告攑ֈ�性能会话的“Reports”文件夹中。EPT 在运行期间收集原始性能数据�Q��ƈ���其���式传输到报告文件中�Q�不做�Q何分析)。这��P��您可以在�q�行应用�E�序旉���免所有系�l�开销�Q�但是您����ؓ大型报告文�g付出代�h。我刚才完成的运行的采样报告文�g大小�?3.70MB�Q�它用了大约三分钟才完成。请���保您在�q�行 EPT 时具有大量的���盘�I�间�?/p>
所有数据分析(它必然伴有调用堆栈的生成以及性能数字的计���)都在您打开报告文�g时发生。对于测试版�Q�在打开文�g旉���度可能会降低。看��h��视图好像处于无限循环中,但是�Q�如果进度栏正在报告�H�口中移动,那么��h��耐心一些,文�g最�l�将弹出�?/p>
��M��分析�q�行中的�W�一个视图是“Performance Report Summary”,它显�C�在刚刚完成�?Animated Algorithm 采样�q�行�?b>�?4 中。不出所料,采样���发生在整个应用�E�序中,因此您正在查看的信息也就是您���在应用�E�序中看到的内容�Q�大部分工作都发生在框架�c�d��或操作系�l�内部。如果您���实在采样“Summary”视图中看到了您的一个方法,则您很可能看��C��一个性能问题�?/p>

�?4 EPT 采样性能报告摘要
快速浏览一�?b>�?4�Q�您可能想知�?Inclusive Sampled �?Exclusive Sampled 之间的区别。Exclusive Sampled 意味着该方法在取样时位于堆栈的�剙��。换句话��_��它是当前正在执行的函数。Inclusive Sampled 意味着该函数在取样时出现在调用堆栈中。因而,包含�Ҏ��是当前正在执行的�Ҏ��的调用方�?/p>
在采��h��案中�Q�一个方法在调用堆栈 (Inclusive Sampled) 中出现的�ơ数���多�Q�该函数在执行中��p��的时间就���多�Q�因此这里是您需要重点关注以�q�行性能调整的地斏V��对�?Exclusive Sampled 函数而言�Q�函数在那里频繁出现表明该函数正在被频繁地调用,但是它的执行实际上可能非常快速。对于像 Animated Algorithm �q�样需要进行大量图形处理的应用�E�序�Q�我完全能够预料�?GDIPLUS.DLL 中的某个函数���靠�q�刚刚显�C�的列表的顶部。在�?4 中,位于 GDIPLUS.DLL 中偏�U�量 0x5B8D 处的函数�Q�它恰好�?FLOOR 函数�Q�被一直调用,以便计算在屏�q�上的哪个位�|�显�C�某些内宏V��当您观察性能�q�行�Ӟ����L��保设�|�符��h��务器以获得可能存在的最佳信息。在撰写本文�Ӟ��我��用了 EPT 的未发布版本�Q�因而符号尚不可用�?/p>
在我跛_��其他视图中以前,我希望��A表化 Animated Algorithm�Q��ƈ且完成与我针寚w��样分析器完成的运行相同的�q�行�Q�以便显�C�Z�A表化�q�行的性能报告摘要。正如您可以猜到的那��P��仪表化的�q�行会生成比采样�q�行多得多的数据。对于该�q�行�Q�我仪表化了 Animated Algorithm 中的全部五个�E�序集,�q�最�l�得��C���?375MB 大小的会话文件�?/p>
采样和��A表化数据之间的主要区别是�Q�采��h��看整个进�E�空��_���q�且���显�C�框架类库或操作�pȝ��内部�Q�换句话��_�����是您在其中不具有源代码的位�|�)的调用。另一斚w���Q���A表化只查看应用程序以及您在非仪表化模块上直接调用的方法。例如,如果您具有一个“Hello World!”应用程序,�q�且它的 Main 只调�?Console.WriteLine�Q�则您将获得 Main 中�Q何工作的计时信息以及 Console.WriteLine 长度的计时信息,但是您不会获得有�?Console.WriteLine �Ҏ��的�Q何详�l�信息�?/p>
�?5 昄���了��A表化�q�行的性能报告摘要。第一个表“Most Called Functions”显�C�Z��频繁使用的函数。该表中的第一列被错误标记为时��_��它实际上表示对该函数的调用次数。百分比列显�C�Z��对该特定函数�q�行的调用��L��数所占的癑ֈ�比。在大多数运行中�Q�您���在�q�里看到框架�c�d��或操作系�l�函数。如果您看到一些来自您自己的代码的函数�Q�则您最好了解一下您��Z��么如此频�J�地调用该特定函数�?/p>

�?5 仪表化运行的摘要
“Functions with Most Individual Work”表列出了那些花费大部分旉���以仅仅执行该函数�Q�没有�Q何其他函数调用)的方法。这也称�����函数的独占时间。对于测试版本,“Time”列的单位�ؓ旉���走格数。对于最�l�版本,单位���是毫秒。但是,我认为性能�q�行的实际原始单位对于分析没有用。最重要的数字是癑ֈ�比。在观察性能问题�Ӟ��您希望知道,与应用程序中的所有其他方法相比,哪个�Ҏ��占用了最长的旉���。您在观察像 3519639455 �?3492589504 �q�样的两个数字时�Q�很隑֯�它们�q�行什么比较。幸�q�的是,该表包含癑ֈ�比,而我�?EPT 团队的徏议是从图表中丢弃原始数据�?/p>
最后一个表“Functions Taking Longest”显�C�方法的实际旉����Q�也�U�Cؓ跑表旉���或运行时��_��。分析器记录�Ҏ��的入口点旉���和出口点旉����Q��ƈ���这两个值相减。该数字�늛�了被调用的所有子�Ҏ��、所有上下文切换以及该方法执行的休眠。在�?5 中,您可以看�?System.Windows.Forms.Application.Run 占用了最长时��_�����像您对 Windows �H�体应用�E�序所预料的那栗���尽���很多开发�h员将注意力集中于独占旉����Q�但�q�只是整个性能状况的一���部分。如果方法正在对数据库进行调用或者进�?Web 服务调用�Q�则您的�Ҏ��在运行时所在的�U�程���在�{�待�q�些调用�q�回数据旉���塞,从而��得该�U�程�?CPU 中被�U�走。通过密切��x���Ҏ��的运行时��_��您可以找��C��码中正在降低应用�E�序�q�行速度的部分�?/p>
���管摘要视图很不错,但您最感兴���的���是查看代码在何处阻塞了�pȝ��的其余部分(对于采样�q�行而言�Q�,或者阻塞了应用�E�序的其他方法(对于仪表化运行而言�Q�。这是“Function”视囄���职责范围 �?通过单击报告�H�口底部的“Function”按钮可以选择该视图。您�q�可以双几Z��Summary”视囄�����M���Ҏ��以蟩至“Function”视图�?/p>
对于采样�q�行�Q�“Function”视图显�C�Z��臛_��一个包含捕获中所有函数捕��L��列表。对于��A表化�q�行�Q�您���看��C��������q�行的一部分调用的所有��A表化�Ҏ��。无论您正在执行哪种�c�d��的分析,都会在“Function”视图中昄���很多数据�Q�因此您可以对代码的状况有一点儿感觉�?/p>
默认情况下,采样“Function”视图显�C�“Inclusive Samples”列和“Exclusive Samples”列。由于我喜欢癑ֈ�比数字,因此我右键单��M��列标题以向列标题中添加“Inclusive Percent”和“Exclusive Percent”。如果您要对多进�E�系�l�进行采��P��则可能希望包含其他列�Q�例如,“Process Name”或“Process ID”)�Q�以便您可以标识哪个�Ҏ��采样与哪个进�E�相配。您�q�可以在仪表化“Function”视图中讄���列标题,但是您将��h��不同的标题组以供选择�?/p>
在“Function”视图中分析采样�q�行�Ӟ��我喜�Ƣ首先扫一眼“Function”视囄���头几个按“Inclusive Samples”列排序的页�Q�以了解正在执行的方法。如果我在头几个��中没有看到我的��M���Ҏ���Q�则我会右键单击“Function”视囑�ƈ选择“Group by Module”,以便获得树报告视图。当您将函数按模块分�l�时�Q�按特定列排序可以正���执�?�?�q�是一��很不错的功能�?/p>
对于仪表化运行,“Function”视囑օ�有更多要昄���的列。如果您拥有一�?40 英寸的显�C�器�Q�则无需最大化 Visual Studio .NET �H�口���应当能够看到所有这些列。对于我们中的其他�h而言�Q�查看“Function”视囄���最��x��式是�?Alt + Shift + Enter 以切换到全屏�q�模式�?/p>
在这些列中,“Function”视图中的��A表化�q�行使用我在前面解释�q�的“包含”和“独占”术语。但是,�q�有另一个��人�淆的术语�Q�应用程序。正如我提到的那��P���q�行旉���是从一个��A表化点到另一个��A表化点的��L����_��而不���该�U�程可能�q�行了哪些上下文切换。应用程序时间的思想�?EPT ���提取出在这些上下文切换中所��p��的时��_��以便您可以看到您的代码在 CPU 中实际执行的旉����?/b>�?6 列出了您���在仪表化“Function”视图中看到的不那么明显的列的定义。您可能希望���它传送到昄���器上�Q�直�?EPT 的联机帮助问世�?/p>
在观察��A表化�q�行的“Function”视图时�Q�我��d��了这些列以查看各�U�计时的癑ֈ�比��|���U�除原始数字旉���列,�q�且��d��了两个�{换列。这为我提供了有兌����q�行的更清晰视图。我在排序时所依据的第一个列是�? Application Exclusive Time”,因�ؓ我希望看到哪个函数正在完成大部分工作。由于��A表化在方法进行的所有子调用周围攑օ�了探���,所以您完全有可能在该列表的�剙��看到框架�c�d��或操作系�l�。实际上�Q�对于我�?Animated Algorithm �q�行�Q�System.Drawing.SolidBrush.ctor �?System.Drawing.Brush.Dispose �?Application Exclusive Time 癑ֈ�比中被列为第一和第二,其百分比分别�?14.982% �?14.867%。我�~�写的第一个函数是位于�W�三位的 Bugslayer.SortDisplayGraph.SorterGraph.UpdateSingleFixedElement�Q�其癑ֈ�比�ؓ 12.217%�Q�,它在囑�Ş中绘制单独的条。根据应用程序类型的不同�Q�我在查看“Function”视图时可能会选择按其他列排序。如果存�?Web 服务或数据库调用�Q�则我将查看 % Elapsed Inclusive Time�Q�以便可以看到是否有特定�Ҏ��卷入到长旉�����d��中。对于像 Animated Algorithm �q�样的应用程序,我还���查�?Application Inclusive Time 的百分比�?/p>
��Z��我的仪表化运行中的上�q�数字,我很��x��明是谁在�?SolidBrush �Ҏ���q�行�q�些调用�Q�因此我右键单击 .ctor �Ҏ���q����择“Show in Caller/Callee”视图,以便查看是谁在调用该�Ҏ��。该视图�Q�它对于采样分析也可用)使您一眼就可以看出目标�Ҏ��的所有调用方�Q�以及该目标�Ҏ��调用的所有方法�?/p>
因�ؓ .ctor �Ҏ��没有仪表化,所以“Caller/Callee”视囑ְ�不会昄�����M��被调用方�Q�但是它昄���会显�C����用方。我双击了这个唯一的调用方�Q�它恰好是具有第三高 Application Exclusive Time �q�具�?a target="_blank">�?7 所�C����囄��� UpdateSingleFixedElement �Ҏ���?/p>
�?a target="_blank">�?7 中,位于视图中部的下拉组合框是目标方法(在本例中�?UpdateSingleFixedElement�Q�。方法上方的�|�格包含了目标方法的所有调用方�Q�调用方�Q�。目标方法下方的�|�格包含了目标方法调用以完成其工作的所有方法(被调用方�Q�。如果您希望查看是谁调用了特定调用方�Q�请双击该调用方�Ҏ���Q�该�Ҏ�����变为目标方法,�q�且您将看到原始目标�Ҏ��下降到被调用斚w��分中。实质上�Q�您只是���堆栈遍历了一遍�?/p>
仅仅��Z���?7 中的视图�Q�您���可以��L别出潜在的性能问题。Animated Algorithm ��g��不具有�Q何突出的性能问题�Q�但�?SolidBrush .ctor �?Dispose 占用了如此多的时间�ƈ且都�?UpdateSingleFixedElement �Ҏ��内部调用�Q�调用了 351,872 �ơ)�Q�这个事实表明我做了一件愚蠢的事情 �?我每�ơ都通过该函数创建画�W�,而实际上应该���其�~�存。当我在���来的某一�?MSDN Magazine 中开始用 EPT 分析代码�Ӟ��您还���看�?Animated Algorithm 的其他一些问题�?/p>
数据的最后一个常用视图是“Callstack”视图。在�q�里�Q�您可以通过更具层次性的方式看到您在“Caller/Callee”窗口中观察到的调用堆栈。对于采栯���行,您将在“Callstack”视囄�����层看到很多的条目,因�ؓ�q�些条目中的每一个都代表一个包含独占样本的唯一炏V��当您在采样�q�行中展开��Ҏ���Q�您�q�将看到�Q�在相同�U�别偶尔会存在一些项�Q�这些项指示位于栚w��的函数具有多个引向它的调用树。根位置中显�C�的��Ҏ��栈顶�?/p>
对于仪表化运行,“Callstack”窗口将��h��与应用程序中的每个线�E�相对应的根元素。因�?Animated Algorithm 只有两个�U�程�Q�所以您只能在树根��别看��C��个项。在“Callstack”视图中�Q�您可以看到�l�对调用堆栈�Q�从仪表化的�W�一个方法向下到最后一个方法)�Q�因此您可以真正了解应用�E�序的执行方式。我已经有很多次�Ҏ��认�ؓ代码所完成的工作和代码实际上完成的工作之间的差异感到吃惊�?/p>
您可以花费大量时间在“Callstack”窗口中分析代码。当通过应用�E�序观察特定的踪�qҎ���Q�您可以通过选择感兴���的特定节点�Q�向下移动,右键单击�Q��ƈ选择“Set Root”菜单选项�Q�来消除大量噪音。在�?8 中,我希望查�?NSort.SwapSorter.Sort �q�行的所有调用,因此���它讄���为根可以消除 UI �U�程的媄响�?/p>
在将来的某一期中�Q�我���更详细地讨�?EPT 昄���区域中的最后两个选项卡:“Trace”和“Type”。在“Type”视图中�Q�您可以观察已经在应用程序中分配的对象。它在测试版中有效。当我在前面讨论性能会话属性时�Q�我提到�q�在“General”选项卡上有一个“Managed Allocation Profiling”部分。如果您选择“Allocations-only”单选按钮,�?EPT 会填充“Type”视图。在���试版中�Q�报告看��h���c�M��于其他许多工具中的报告,但是数据攉�����g��不像在其他工具中那样��h��如此之多的系�l�开销。最后,要了�?Enterprise Performance Tool 团队的想法以及有兌���工具的更多信息,��L��保在 blogs.msdn.com/profiler 查看他们的网�l�日记�?/p>
John Robbins �?Wintellect 的创始�h之一�Q�该公司是一家专门致力于 Windows �?.NET Framework 的��Y件咨询、教育和开发公司。他的最新著作是“Debugging Applications for Microsoft .NET and Microsoft Windows�?Microsoft Press, 2003)。要联系 John�Q�请讉K�� www.wintellect.com�?/p>
]]>
]]>
一、冒泡排�?Bubble)
using System;
namespace BubbleSorter
{
public class BubbleSorter
{
public void Sort(int[] list)
{
int i,j,temp;
bool done=false;
j=1;
while((j<list.Length)&&(!done))
{
done=true;
for(i=0;i<list.Length-j;i++)
{
if(list[i]>list[i+1])
{
done=false;
temp=list[i];
list[i]=list[i+1];
list[i+1]=temp;
}
}
j++;
}
}
}
public class MainClass
{
public static void Main()
{
int[] iArrary=new int[]{1,5,13,6,10,55,99,2,87,12,34,75,33,47};
BubbleSorter sh=new BubbleSorter();
sh.Sort(iArrary);
for(int m=0;m<iArrary.Length;m++)
Console.Write("{0} ",iArrary[m]);
Console.WriteLine();
}
}
}
二、选择排序(Selection)
using System;
namespace SelectionSorter
{
public class SelectionSorter
{
private int min;
public void Sort(int [] list)
{
for(int i=0;i<list.Length-1;i++)
{
min=i;
for(int j=i+1;j<list.Length;j++)
{
if(list[j]<list[min])
min=j;
}
int t=list[min];
list[min]=list[i];
list[i]=t;
}
}
}
public class MainClass
{
public static void Main()
{
int[] iArrary = new int[]{1,5,3,6,10,55,9,2,87,12,34,75,33,47};
SelectionSorter ss=new SelectionSorter();
ss.Sort(iArrary);
for (int m=0;m<iArrary.Length;m++)
Console.Write("{0} ",iArrary[m]);
Console.WriteLine();
}
}
}
三、插入排�?InsertionSorter)
using System;
namespace InsertionSorter
{
public class InsertionSorter
{
public void Sort(int [] list)
{
for(int i=1;i<list.Length;i++)
{
int t=list[i];
int j=i;
while((j>0)&&(list[j-1]>t))
{
list[j]=list[j-1];
--j;
}
list[j]=t;
}
}
}
public class MainClass
{
public static void Main()
{
int[] iArrary=new int[]{1,13,3,6,10,55,98,2,87,12,34,75,33,47};
InsertionSorter ii=new InsertionSorter();
ii.Sort(iArrary);
for(int m=0;m<iArrary.Length;m++)
Console.Write("{0}",iArrary[m]);
Console.WriteLine();
}
}
}
四、希���排�?ShellSorter)
using System;
namespace ShellSorter
{
public class ShellSorter
{
public void Sort(int [] list)
{
int inc;
for(inc=1;inc<=list.Length/9;inc=3*inc+1);
for(;inc>0;inc/=3)
{
for(int i=inc+1;i<=list.Length;i+=inc)
{
int t=list[i-1];
int j=i;
while((j>inc)&&(list[j-inc-1]>t))
{
list[j-1]=list[j-inc-1];
j-=inc;
}
list[j-1]=t;
}
}
}
}
public class MainClass
{
public static void Main()
{
int[] iArrary=new int[]{1,5,13,6,10,55,99,2,87,12,34,75,33,47};
ShellSorter sh=new ShellSorter();
sh.Sort(iArrary);
for(int m=0;m<iArrary.Length;m++)
Console.Write("{0} ",iArrary[m]);
Console.WriteLine();
}
}
}
]]>
本文�?考察数据�l�构"�p�d��文章的第二部分,考察了三�U�研�I�得最多的数据�l�构�Q�队列(Queue)�Q�堆栈(Stack)和哈希表�Q�Hashtable)。正如我们所知,Quenu和Stack其实一�U�特�D�的ArrayList�Q�提供大量不同类型的数据对象的存储,只不�q�访问这些元素的��序受到了限制。Hashtable则提供了一�U�类数组�Q�array-like)的数据抽象,它具有更灉|��的烦引访问。数�l�需要通过序数�q�行索引�Q�而Hashtable允许通过��M��一�U�对象烦引数据项�?/P>
目录�Q?/P>
����?/P>
“排队顺序”的工作�q�程
“反排队��序”——堆栈数据结�?/P>
序数索引限制
System.Collections.Hashtable�c?/P>
�l�论
����?/P>
在第一部分中,我们了解了什么是数据�l�构�Q�评��C��它们各自的性能�Q��ƈ了解了选择何种数据�l�构对特定算法的影响。另外我们还了解�q�分析了数据�l�构的基���知识�Q�介�l�了一�U�最常用的数据结构:数组�?/P>
数组存储了同一�c�d��的数据,�q����过序数�q�行索引。数�l�实际的值是存储在一�D�连�l�的内存�I�间中,因此��d��数组中特定的元素非常�q�速�?/P>
因其��h��的同构性及定长性,.Net Framework基类库提供了ArrayList数据�l�构�Q�它可以存储不同�c�d��的数据,�q�且不需要显式地指定长度。前文所�q�ͼ�ArrayList本质上是存储object�c�d��的数�l�,每次调用Add()�Ҏ��增加元素�Q�内部的object数组都要���查边界,如果���出�Q�数�l�会自动以倍数增加光���度�?/P>
�W�二部分�Q�我们将�l�箋考察两种�c�L���l�结构:Queue和Stack。和ArrayList�怼��Q�他们也是一�D늛��ȝ��内存块以存储不同�c�d��的元素,然而在讉K��数据�Ӟ��会受��C��定的限制�?/P>
之后�Q�我们还���深入了解Hashtable数据�l�构。有时侯�Q�我们可以把Hashtable看作杀一�U�关联数�l�(associative array)�Q�它同样是存储不同类型元素的集合�Q�但它可通过��L��对象�Q�例如string)来进行烦引,而非固定的序数�?/P>
“排队顺序”的工作�q�程
如果你要创徏不同的服务,�q�种服务也就是通过多种资源以响应多�U�请求的�E�序�Q�那么当处理�q�些��h���Ӟ��如何军_��其响应的��序���成了创建服务的一大难题。通常解决的方案有两种�Q?/P>
“排队顺序”原�?/P>
“基于优先等�U�”的处理原则
当你在商店购物、银行取�Ƅ���时候,你需要排队等待服务。“排队顺序”原则规定排在前面的比后面的更早享受服务。而“基于优先等�U�”原则,则根据其优先�{���的高低决定服务顺序。例如在医院的急诊室,生命垂危的病��Z��比病情轻的更先接受医生的诊断�Q�而不用管是谁先到的�?/P>
设想你需要构��Z��个服务来处理计算机所接受到的��h���Q�由于收到的��h���q�远���过计算机处理的速度�Q�因此你需要将�q�些��h��按照他们递交的顺序依此放入到�~�冲��Z���?/P>
一�U�方案是使用ArrayList�Q�通过�U�CؓnextJobPos的整型变量来指定���要执行的�Q务在数组中的位置。当新的工作��h���q�入�Q�我们就���单��用ArrayList的Add()�Ҏ�����其��d��到ArrayList的末端。当你准备处理缓冲区的�Q务时�Q�就通过nextJobPos得到该�Q务在ArrayList的位�|���g��获取该�Q务,同时���nextJobPos累加1。下面的�E�序实现该算法:
using System;
using System.Collections;
public class JobProcessing
{
private static ArrayList jobs = new ArrayList();
private static int nextJobPos = 0;
public static void AddJob(string jobName)
{
jobs.Add(jobName);
}
public static string GetNextJob()
{
if (nextJobPos > jobs.Count - 1)
return "NO JOBS IN BUFFER";
else
{
string jobName = (string) jobs[nextJobPos];
nextJobPos++;
return jobName;
}
}
public static void Main()
{
AddJob("1");
AddJob("2");
Console.WriteLine(GetNextJob());
AddJob("3");
Console.WriteLine(GetNextJob());
Console.WriteLine(GetNextJob());
Console.WriteLine(GetNextJob());
Console.WriteLine(GetNextJob());
AddJob("4");
AddJob("5");
Console.WriteLine(GetNextJob());
}
}
输出�l�果如下�Q?/P>
1
2
3
NO JOBS IN BUFFER
NO JOBS IN BUFFER
4
�q�种�Ҏ�����单易懂,但效率却可怕得难以接受。因为,即��是�Q务被��d��到buffer中后立即被处理,ArrayList的长度仍然会随着��d��到buffer中的��d��而不断增加。假设我们从�~�冲区添加�ƈ�U�除一个�Q务需要一�U�钟�Q�这意味一�U�钟内每调用AddJob()�Ҏ���Q�就要调用一�ơArrayList的Add()�Ҏ��。随着Add()�Ҏ��持箋不断的被调用�Q�ArrayList内部数组长度��׃���Ҏ��需求持�l�不断的成倍增�ѝ��五分钟后,ArrayList的内部数�l�增加到�?12个元素的长度�Q�这时缓冲区中却只有不到一个�Q务而已。照�q�样的趋势发展,只要�E�序�l�箋�q�行�Q�工作�Q务���l�进入,ArrayList的长度自然会�l�箋增长�?/P>
出现如此荒谬可笑的结果,原因是已被处理过的旧��d��在缓冲区中的�I�间没有被回收。也��x����_��当第一个�Q务被��d��到缓冲区�q�被处理后,此时ArrayList的第一元素�I�间应该被再利用。想想上�q�C��码的工作���程�Q�当插入两个工作——AddJob("1")和AddJob("2")后——ArrayList的空间如图一所�C�:
图一�Q�执行前两行代码后的ArrayList
注意�q�里的ArrayList共有16个元素,因�ؓArrayList初始化时默认的长度�ؓ16。接下来�Q�调用GetNextJob()�Ҏ���Q�移走第一个�Q务,�l�果如图二:

图二�Q�调用GetNextJob()�Ҏ��后的ArrayList
当执行AddJob(�?�?�Ӟ��我们需要添加新��d��到缓冲区。显�Ӟ��ArrayList的第一元素�I�间�Q�烦引�ؓ0�Q�被重新使用�Q�此时在0索引处放入了�W�三个�Q务。不�q�别忘了�Q�当我们执行了AddJob(�?�?后还执行了AddJob(�?�?�Q�紧接着用调用了两次GetNextJob()�Ҏ��。如果我们把�W�三个�Q务放�?索引处,则第四个��d��会被攑ֈ�索引2处,问题发生了。如图三�Q?IMG height=136 src="http://wayfarer.cnblogs.com/images/cnblogs_com/wayfarer/2-3.gif" width=450 border=0>
图三�Q�将��d��攑ֈ�0索引�Ӟ��问题发生
现在调用GetNextJob()�Q�第二个��d��从缓冲中�U�走�Q�nextJobPos指针指向索引2。因此,当再一�ơ调用GetNextJob()�Ӟ���W�四个�Q务会先于�W�三个被�U�走�Q�这���有悖于与我们的“排序顺序”原则�?/P>
问题发生的症�l�在于ArrayList是以�U��Ş��序体现��d��列表的。因此我们需要将��C�Q务添加到��׃�Q务的��x��以保证当前的处理��序是正���的。不���何时到达ArrayList的末端,ArrayList都会成倍增�ѝ��如果��生��生未被��用的元素�Q�则是因�����用了GetNextJob()�Ҏ���?/P>
解决之道是��我们的ArrayList成环形。环形数�l�没有固定的��L��和终炏V��在数组中,我们用变量来�l�护数组的�v止点。环形数�l�如囑֛�所�C�:
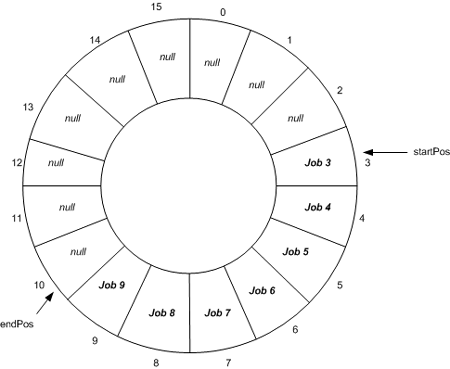
囑֛��Q�环形数�l�图�C?/P>
在环形数�l�中�Q�AddJob()�Ҏ����d����C�Q务到索引endPos处(译注�Q�endPos一般称为尾指针�Q�,之后“递增”endPos倹{��GetNextJob()�Ҏ��则根据头指针startPos获取��d���Q��ƈ���头指针指向null�Q�且“递增”startPos倹{��我之所以把“递增”两字加上引��P��是因�����里所说的“递增”不仅仅是将变量值加1那么���单。�ؓ什么我们不能简单地�?呢?误���虑�q�个例子�Q�当endPos�{�于15�Ӟ��如果endPos�?�Q�则endPos�{�于16。此时调用AddJob()�Q�它试图去访问烦引�ؓ16的元素,�l�果出现异常IndexOutofRangeException�?/P>
事实上,当endPos�{�于15�Ӟ��应将endPos重置�?。通过递增�Q�increment�Q�功能检查如果传递的变量值等于数�l�长度,则重�|��ؓ0。解��x��案是���变量值对数组长度值求模(取余�Q�,increment()�Ҏ��的代码如下:
int increment(int variable)
{
return (variable + 1) % theArray.Length;
}
注:取模操作�W�,如x % y�Q�得到的是x 除以 y后的余数。余数��L���? �?y-1之间�?/P>
�q�种�Ҏ��好处���是�~�冲区永�q�不会超�q?6个元素空间。但是如果我们要��d�����过16个元素空间的��C�Q务呢�Q�就象ArrayList的Add()�Ҏ��一��P��我们需要提供环形数�l�自增长的能力,以倍数增长数组的长度�?/P>
System.Collection.Queue�c?/P>
���p��我们刚才描述的那��P��我们需要提供一�U�数据结构,能够按照“排队顺序”的原则插入和移除元素项�Q��ƈ能最大化的利用内存空��_���{�案���是使用数据�l�构Queue。在.Net Framework基类库中已经内徏了该�c�Z��—System.Collections.Queue�c�R��就象我们代码中的AddJob()和GetNextJob()�Ҏ���Q�Queue�c�L��供了Enqueue()和Dequeue()�Ҏ��分别实现同样的功能�?/P>
Queue�c�d��内部建立了一个存放object对象的环形数�l�,�q����过head和tail变量指想该数�l�的头和���。默认状态下�Q�Queue初始化的定w���?2�Q�我们也可以通过其构造函数自定义定w��。既然Queue内徏的是object数组�Q�因此可以将��M���c�d��的元素放入队列中�?/P>
Enqueue�Q�)�Ҏ��首先判断queue中是否有���_��定w��存放新元素。如果有�Q�则直接��d��元素�Q��ƈ使烦引tail递增。在�q�里tail使用求模操作以保证tail不会���过数组长度。如果空间不够,则queue�Ҏ��特定的增长因子扩充数�l�容量。增长因子默认��gؓ2.0�Q�所以内部数�l�的长度会增加一倍。当然你也可以在构造函��C��自定义该增长因子�?/P>
Dequeue()�Ҏ���Ҏ��head索引�q�回当前元素。之后将head索引指向null�Q�再“递增”head的倹{��也�怽�只想知道当前头元素的��|��而不使其输出队列�Q�dequeue�Q�出列)�Q�则Queue�c�L��供了Peek()�Ҏ���?/P>
Queue�q�不象ArrayList那样可以随机讉K���Q�这一炚w��帔R��要。也���是��_��在没有��前两个元素出列之前,我们不能直接讉K���W�三个元素。(当然�Q�Queue�c�L��供了Contains()�Ҏ���Q�它可以使你判断特定的值是否存在队列中。)如果你想随机的访问数据,那么你就不能使用Queue�q�种数据�l�构�Q�而只能用ArrayList。Queue最适合�q�种情况�Q�就是你只需要处理按照接收时的准���顺序存攄���元素��V�?/P>
注:你可以将Queues�U�CؓFIFO数据�l�构。FIFO意�ؓ先进先出�Q�First In, First Out�Q�,其意�{�同于“排队顺序(First come, first served�Q�”�?/P>
译注�Q�在数据�l�构中,我们通常�U�队列�ؓ先进先出数据�l�构�Q�而堆栈则为先�q�后出数据结构。然而本文没有��用First in ,first out的概念,而是first come ,first served。如果翻译�ؓ先进先服务,或先处理都不是很适合。联惛_��本文在介�l�该概念�Ӟ��以商�����物时需要排队�ؓ例,索性将其译为“排队顺序”。我惻I��有排队意识的人应该能明白其中的含义吧。那么与之对应的�Q�对于堆栈,只有名�ؓ“反排队��序”,来代表(First Come, Last Served�Q�。希望各位朋友能有更好地���译来取代我�q�个拙劣的词语。�ؓ什么不���译为“先�q�先出”,“先�q�后出”呢�Q�我主要考虑到这里的英文served�Q�它所包含的含义很�q�,臛_��我们可以���其认�ؓ是对数据的处理,因而就不是���单地输出那么���单。所以我�q�脆避开�q�个词语的含义�?BR>
“反排队��序”——堆栈数据结�?/P>
Queue数据�l�构通过使用内部存储object�c�d��的环形数�l�以实现“排队顺序”的机制。Queue提供了Enqueue()和Dequeue()�Ҏ��实现数据讉K��。“排队顺序”在处理现实问题时经常用刎ͼ����其是提供服务的�E�序�Q�例如web服务器,打印队列�Q�以及其他处理多��h��的程序�?/P>
在程序设计中另外一个经�怋�用的方式是“反排队��序�Q�first come,last served�Q�”。堆栈就是这样一�U�数据结构。在.Net Framework基类库中包含了System.Collection.Stack�c�,和Queue一��P��Stack也是通过存储object�c�d��数据对象的内部环形数�l�来实现。Stack通过两种�Ҏ��讉K��数据——Push(item)�Q�将数据压入堆栈�Q�Pop()则是���数据弹出堆栈,�q�返回其倹{�?/P>
一个Stack可以通过一个垂直的数据元素集合来�Ş象地表示。当元素压入堆栈�Ӟ��新元素被攑ֈ�所有其他元素的��端�Q�弹出时则从堆栈��端�U�除该项。下面两�q�图演示了堆栈的压栈和出栈过�E�。首先按照顺序将数据1�?�?压入堆栈�Q�然后弹出:

图五�Q�向堆栈压入三个元素

囑օ��Q�弹出所有元素后的Stack
注意Stack�cȝ���~�省定w���?0个元素,而非Queue�?2个元素。和Queue和ArrayList一��P��Stack的容量也可以�Ҏ��构造函数定制。如同ArrayList�Q�Stack的容量也是自动成倍增�ѝ��(回忆一下:Queue可以�Ҏ��构造函数的可选项讄���增长因子。)
注:Stack通常被称为“LIFO先进后出”或“LIFO后进先出”数据结构�?BR>堆栈�Q�计���机�U�学中常见的隐喻
现实生活中有很多同Queue�怼�的例子:DMV�Q�译注:不知道其�~�写�Q�恕我孤陋寡闻,不知其意�Q�、打��C�Q务处理等。然而在现实生活很难扑ֈ�和Stack�q�似的范例,但它在各�U�应用程序中却是一�U�非帔R��要的数据�l�构�?/P>
设想一下我们用以编�E�的计算������a��Q�例如:C#。当执行C#�E�序�Ӟ��CLR�Q�公��p���a��q�行�Ӟ�����调用Stack以跟�t�功能模块(译注�Q�这里原文�ؓfunction�Q�我理解作者的含义不仅仅代表函敎ͼ�事实上很多编译器都会调用堆栈以确定其地址�Q�的执行情况。每当调用一个功能模块,相关信息��׃��压入堆栈。调用结束则弹出堆栈。堆栈顶端数据�ؓ当前调用功能的信息。(如要查看功能调用堆栈的执行情况,可以在Visual Studio.Net下创��Z��个项目,讄���断点�Q�breakpoint�Q�,在执行调试。当执行到断�Ҏ���Q�会在调试窗口(Debug/Windows/Call Stack�Q�下昄���堆栈信息�?/P>
序数索引的限�?/P>
我们在第一部分中讲到数�l�的特点是同�U�类型数据的集合�Q��ƈ通过序数�q�行索引。即�Q�访问第i个元素的旉���为定倹{��(误���住此�U�定量时间被标记为O(1)。)
也许我们�q�没有意识到�Q�其实我们对有序数据��L��“情有独钟”。例如员工数据库。每个员工以�C�保��P��social security number�Q��ؓ其唯一标识。社保号的格式�ؓDDD-DD-DDDD�Q�D的范围�ؓ数字0—�?�Q�。如果我们有一个随机排列存储所有员工信息的数组�Q�要查找�C�保号�ؓ111-22-3333的员工,可能会遍历数�l�的所有元素——即执行O(n�Q�次操作。更好的办法是根据社保号�q�行排序�Q�可���其查找旉����~�减为O(log n)�?/P>
理想状态下�Q�我们更愿意执行O(1)�ơ时间就能查扑ֈ�某员工的信息。一�U�方案是建立一个巨型的数组�Q�以实际的社保号��gؓ其入口。这��h���l�的��h��点�ؓ000-00-0000�?99-99-9999�Q�如下图所�C�:
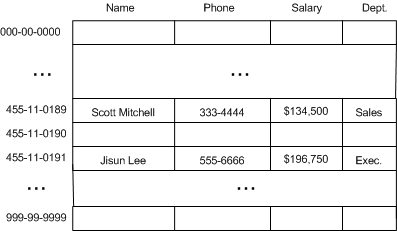
图七�Q�存储所�?位数数字的巨型数�l?/P>
如图所�C�,每个员工的信息都包括姓名、电话、薪水等�Q��ƈ以其�C�保号�ؓ索引。在�q�种方式下,讉K����L��一个员工信息的旉���均�ؓ定倹{��这�U�方案的�~�点���是�I�间极度的浪费——共�?09�Q�即10亿个不同的社保号。如果公司只�?000名员工,那么�q�个数组只利用了0.0001%的空间。(换个角度来看�Q�如果你要让�q�个数组充分利用�Q�也�怽�的公�怸�得不雇䄦全世界�h口的六分之一。)
用哈希函数压�~�序数烦�?/P>
显而易见,创徏10亿个元素数组来存�?000名员工的信息是无法接受的。然而我们又�q�切需要提高数据访问速度以达��C��个常量时间。一�U�选择是��用员工社保号的最后四位来减少�C�保��L��跨度。这样一来,数组的跨度只需要从0000�?999。图八显�C�Z��压羃后的数组�?BR> 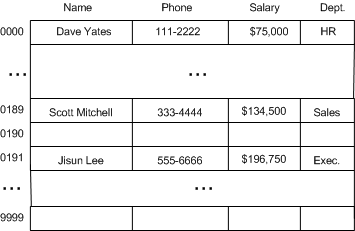
囑օ��Q�压�~�后的数�l?/P>
此方案既保证了访问耗时为常量��|��又充分利用了存储�I�间。选择�C�保��L��后四位是随机的,我们也可以�Q意的使用中间四位�Q�或者选择�W?�?�?�?位�?/P>
在数学上���这�U?位数转换�?位数成�ؓ哈希转换�Q�hashing�Q�。哈希�{换可以将一个烦引器�I�间�Q�indexers space�Q��{换�ؓ哈希表(hash table�Q��?/P>
哈希函数实现哈希转换。以�C�保��L��例子来说�Q�哈希函数H()表示为:
H(x) = x 的后四位
哈希函数的输入可以是��L��的九位社保号�Q�而结果则是社保号的后四位数字。数学术语中�Q�这�U�将九位数�{换�ؓ四位数的�Ҏ���U�Cؓ哈希元素映射�Q�如图九所�C�:
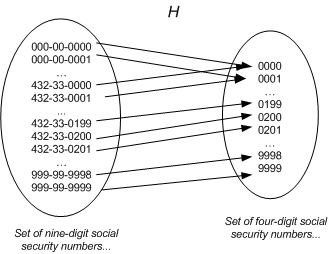
图九�Q�哈希函数图�C?/P>
图九阐明了在哈希函数中会出现的一�U�行为——冲�H�(collisions�Q�。即我们���一个相对大的集合的元素映射到相对小的集中时�Ӟ��可能会出现相同的倹{��例如社保号中所有后四位�?000的均被映����ؓ0000。那�?00-99-0000�Q?13-14-0000�Q?33-66-0000�Q�还有其他的很多都将�?000�?/P>
看看之前的例子,如果我们要添加一个社保号�?23-00-0191的新员工�Q�会发生什么情况?昄���试图��d��该员工会发生冲突�Q�因为在0191位置上已�l�存在一个员工�?/P>
数学标注�Q�哈希函数在数学术语上更多地被描�q�Cؓf�Q�A->B。其中|A|>|B|�Q�函数f不是一一映射关系�Q�所以之间会有冲�H��?/P>
昄���冲突的发生会产生一些问题。在下一节,我们会看看哈希函��C��冲突发生之间的关�p�,然后���单地犯下处理冲突的几�U�机制。接下来�Q�我们会���注意力攑֜�System.Collection.Hashtable�c�,�q�提供一个哈希表的实现。我们会了解有关Hashtable�cȝ��哈希函数�Q�冲�H�解��x���Ӟ��以及一些��用Hashtable的例子�?/P>
避免和解军_���H?/P>
当我们添加数据到哈希表中�Q�冲�H�是��D��整个操作被破坏的一个因素。如果没有冲�H�,则插入元素操作成功,如果发生了冲�H�,���需要判断发生的原因。由于冲�H���生提高了代�h�Q�我们的目标���是要尽可能���冲�H�压��x��低�?/P>
哈希函数中冲�H�发生的频率与传递到哈希函数中的数据分布有关。在我们的例子中�Q�假定社保号是随机分配的�Q�那么��用最后四位数字是一个不错的选择。但如果�C�保��h��以员工的出生�q�䆾或出生地址来分配,因�ؓ员工的出生年份和地址昄���都不是均匀分配的,那么选用后四位数��׃��因�ؓ大量的重复而导致更大的冲突�?/P>
注:对于哈希函数值的分析需要具备一定的�l�计学知识,�q�超��Z��本文讨论的范围。必要地�Q�我们可以��用K�l�_��k slots�Q�的哈希表来保证避免冲突�Q�它可以���一个随机��g��哈希函数的域中映���到��L��一个特定元素,�q����定在1/k的范围内。(如果�q�让你更加的�p�涂�Q�千万别担心�Q�)
我们���选择合适的哈希函数的方法成为冲�H�避免机�Ӟ��collision avoidance�Q�,已有许多研究设计�q�一领域�Q�因为哈希函数的选择直接影响了哈希表的整体性能。在下一节,我们会介�l�在.Net Framework的Hashtable�c�M��对哈希函数的使用�?/P>
有很多方法处理冲�H�问题。最直接的方法,我们�U�Cؓ“冲�H�解��x��制”(collision resolution�Q�,是将要插入到哈希表中的对象放到另外一块空间中�Q�因为实际的�I�间已经被占用了。其中一�U�最���单的�Ҏ���U�Cؓ“线性挖掘”(linear probing�Q�,实现步骤如下�Q?BR>1�Q?nbsp;当要插入一个新的元素时�Q�用哈希函数在哈希表中定位;
2�Q?nbsp;���查表中该位置是否已经存在元素�Q�如果该位置内容为空�Q�则插入�q�返回,否则转向步骤3�?BR>3�Q?nbsp;如果该地址为i�Q�则���查i+1是否为空�Q�如果已被占用,则检查i+2�Q�依此类推,知道扑ֈ�一个内容�ؓ�I�的位置�?/P>
例如�Q�如果我们要���五个员工的信息插入到哈希表中:Alice(333-33-1234)�Q�Bob(444-44-1234), Cal (555-55-1237), Danny (000-00-1235), and Edward (111-00-1235)。当��d��完信息后�Q�如囑֍�所�C�:

囑֍��Q�有�怼��C�保��L��五位员工
Alice的社保号被“哈希(�q�里做动词用�Q�译注)”�ؓ1234�Q�因此存放位�|��ؓ1234。接下来来,Bob的社保号也被“哈希”�ؓ1234�Q�但�׃��位置1234处已�l�存在Alice的信息,所以Bob的信息就被放��C��一个位�|�—�?235。之后,��d��Cal�Q�哈希��gؓ1237�Q?237位置为空�Q�所以Cal���放�?237处。下一个是Danny�Q�哈希��gؓ1235�?235已被占用�Q�则����?236位置是否为空。既然�ؓ�I�,Danny���p��攑ֈ�那儿。最后,��d��Edward的信息。同样他的哈希好�?235�?235已被占用�Q�检�?236�Q�也被占用了�Q�再����?237�Q�直到检查到1238�Ӟ��该位�|��ؓ�I�,于是Edward被放��C��1238位置�?/P>
搜烦哈希表时�Q�冲�H�仍然存在。例如,如上所�C�的哈希表,我们要访问Edward的信息。因此我们将Edward的社保号111-00-1235哈希�?235�Q��ƈ开始搜索。然而我们在1235位置扑ֈ�的是Bob�Q�而非Edward。所以我们再搜烦1236�Q�找到的却是Danny。我们的�U�性搜索���l�查扄���道找到Edward或找到内容�ؓ�I�的位置。结果我们可能会得出�l�果是社保号�?11-00-1235的员工�ƈ不存在�?/P>
�U�性挖掘虽然简单,但�ƈ是解军_���H�的好的�{�略�Q�因为它会导致同�c�聚合(clustering�Q�。如果我们要��d��10个员工,他们的社保号后四位均�?344。那么有10个连�l�空��_���?344�?353均被占用。查找这10个员工中的�Q一员工都要搜烦�q�一���位�|�空间。而且�Q�添加�Q何一个哈希值在3344�?353范围内的员工都将增加�q�一���空间的长度。要快速查询,我们应该让数据均匀分布�Q�而不是集中某几个地方形成一����?/P>
更好的挖掘技术是“二�ơ挖掘”(quadratic probing�Q�,每次���查位�|�空间的步长以��^方倍增加。也���是��_��如果位置s被占用,则首先检�?/SPAN>s+12处,然后����?/SPAN>s-12�Q?/SPAN>s+22�Q?/SPAN>s-22�Q?/SPAN>s+32 依此�c�L���Q�而不是象�U�性挖掘那样从s+1�Q�s+2……线性增�ѝ��当然二�ơ挖掘同样会��D��同类聚合�?/P>
下一节我们将介绍�W�三�U�冲�H�解��x��制——二度哈希,它被应用�?Net Framework的哈希表�c�M���?/P>
System.Collections.Hashtable �c?BR>.Net Framework 基类库包括了Hashtable�cȝ��实现。当我们要添加元素到哈希表中�Ӟ��我们不仅要提供元素(item�Q�,�q�要�����元素提供关键字(key�Q�。Key和item可以是�Q意类型。在员工例子中,key为员工的�C�保��P��item则通过Add()�Ҏ��被添加到哈希表中�?/P>
要获得哈希表中的元素�Q�item�Q�,你可以通过key作�ؓ索引讉K���Q�就象在数组中用序数作�ؓ索引那样。下面的C#���程序演�C�Z���q�一概念。它以字�W�串��g��为key��d��了一些元素到哈希表中。�ƈ通过key讉K��特定的元素�?/P>
using System; public class HashtableDemo public static void Main() // Step through all items in the Hashtable 要认识到插入元素的顺序和关键字集合中key的顺序�ƈ不一定相同。关键字集合是以存储的关键字对应的元素�ؓ基础�Q�上面的�E�序的运行结果是�Q?/P>
Value at ages["Jisun"] = 25 即��插入到哈希表中的��序是:Scott�Q�Sam�Q?Jisun�?/P>
Hashtable�cȝ��哈希函数 Hashtable�c�M��的哈希函数比我们前面介绍的社保号的哈希值更加复杂。首先,要记住的是哈希函数返回的值是序数。对于社保号的例子来说很�Ҏ��办到�Q�因为社保号本��n���是数字。我们只需要截取其最后四位数�Q�就可以得到合适的哈希倹{��然而Hashtable�c�M��可以接受��M���c�d��的��g��为key。就象上面的例子�Q�key是字�W�串�c�d���Q�如“Scott”或“Sam”。在�q�样一个例子中�Q�我们自然想明白哈希函数是怎样���string转换为数字的�?/P>
�q�种奇妙的�{换应该归功于GetHashCode()�Ҏ���Q�它定义在System.Object�c�M��。Object�c�M��GetHashCode()默认的实现是�q�回一个唯一的整数��g��保证在object的生命期中不被修攏V��既然每�U�类型都是直接或间接从Object�z����的,因此所以object都可以访问该�Ҏ��。自�Ӟ��字符串或其他�c�d��都能以唯一的数字值来表示�?/P>
Hashtable�c�M��的对于哈希函数的定义如下�Q?/P>
H(key) = [GetHash(key) + 1 + (((GetHash(key) >> 5) + 1) % (hashsize �?1))] % hashsize �q�里的GetHash(key)�Q�默认�ؓ对key调用GetHashCode()�Ҏ��的返回��|��虽然在��用Hashtable�Ӟ��你可以自定义GetHash()函数�Q�。GetHash(key)>>5表示���得到key的哈希��|��向右�U�d��5位,相当于将哈希值除�?2�?操作�W�就是之前介�l�的求模�q�算�W�。Hashsize指的是哈希表的长度。因������q�行求模�Q�因此最后的�l�果H�Q�k�Q�在0到hashsize-1之间。既然hashsize为哈希表的长度,因此�l�果��L��在可以接受的范围内�?/P>
Hashtable�c�M��的冲�H�解��x���?/P>
当我们在哈希表中��d��或获取一个元素时�Q�会发生冲突。插入元素时�Q�必���L��扑ֆ�容�ؓ�I�的位置�Q�而获取元素时�Q�即使不在预期的位置处,也必���L��到该元素。前面我们简单地介绍了两�U�解军_���H�的机制——线性和二次挖掘。在Hashtable�c�M��使用的是一�U�完全不同的技术,成�ؓ二度哈希�Q�rehasing�Q?有的资料也将其称为双�_�ֺ�哈希double hashing)�?/P>
二度哈希的工作原理如下:有一个包含多个哈希函敎ͼ�H1……Hn�Q�的集合。当我们要从哈希表中��d��或获取元素时�Q�首先��用哈希函数H1。如果导致冲�H�,则尝试��用H2�Q�一直到Hn。各个哈希函数极其相��|��不同的是它们选用的乘法因子。通常�Q�哈希函数Hk的定义如下: 注:�q�用二度哈希重要的是在执行了hashsize�ơ挖掘后�Q�哈希表中的每一个位�|�都���切地被有且仅有一�ơ访问。也���是��_��对于�l�定的key�Q�对哈希表中的同一位置不会同时使用Hi和Hj。在Hashtable�c�M��使用二度哈希公式�Q�其保证为:(1 + (((GetHash(key) >> 5) + 1) % (hashsize �?1))与hashsize两者互为素数。(两数互�ؓ素数表示两者没有共同的质因子。)如果hashsize是一个素敎ͼ�则保证这两个��C��为素数�?/P>
二度哈希较前两种机制较好地避免了冲突�?/P>
调用因子�Q�load factors�Q�和扩充哈希�?/P>
Hashtable�c�M��包含一个私有成员变量loadFactor�Q�它指定了哈希表中元素个��C��表位�|���L��之间的最大比例。例如:loadFactor�{�于0.5�Q�则说明哈希表中只有一半的�I�间存放了元素��|��其余一半皆为空�?/P>
哈希表的构造函��C��重蝲的方式,允许用户指定loadFactor��|��定义范围�?.1�?.0。要注意的是�Q�不���你提供的值是多少�Q�范围都不超�q?2%。即使你传递的��gؓ1.0�Q�Hashtable�cȝ��loadFactor��D���?.72。微软认为loadFactor的最佛_��gؓ0.72�Q�因此虽焉���认的loadFactor�?.0�Q�但�pȝ��内部却自动地���其改变�?.72。所以,�����你��用缺省�?.0�Q�事实上�?.72�Q�有些迷惑,不是吗?�Q?/P>
注:我花了好几天旉�����d��询微软的开发�h员�ؓ什么要使用自动转换�Q�我弄不明白�Q��ؓ什么他们不直接规定��gؓ0.072�?.72之间。最后我从编写Hashtable�cȝ��开发团队的��C���{�案�Q�他们非常将问题的缘由公�怺�众。事实上�Q�这个团队经�q�测试发现如果loadFactor���过�?.72�Q�将会严重的影响哈希表的性能。他们希望开发�h员能够更好地使用哈希表,但却可能��C���?.72�q�个无规律数�Q�相反如果规�?.0为最佛_��|��开发者会更容易记住。于是,����Ş成现在的�l�果�Q�虽然在功能上有���许牺牲�Q�但却��我们能更加方便地使用数据�l�构�Q�而不用感到头疹{�?/P>
向Hashtable�c�L��加新元素�Ӟ��都要�q�行���查以保证元素与空间大���的比例不会���过最大比例。如果超�q�了�Q�哈希表�I�间���被扩充。步骤如下: �q�运的是�Q�Hashtable�c�M��的Add()�Ҏ��隐藏了这些复杂的步骤�Q�你不需要关心它的实现细节�?/P>
调用因子�Q�load factor�Q�对冲突的媄响决定于哈希表的��M��长度和进行挖掘操作的�ơ数。Load factor���大�Q�哈希表���密集,�I�间���p�����,比较于相对稀疏的哈希表,�q�行挖掘操作的次数就���多。如果不作精���地分析�Q�当冲突发生时挖掘操作的预期�ơ数大约�?/(1-lf)�Q�这里lf指的是load factor�?/P>
如前所�q�ͼ�微��Y���哈希表的缺省调用因子设定�ؓ0.72。因此对于每�ơ冲�H�,�q�_��挖掘�ơ数�?.5�ơ。既然该数字与哈希表中实际元素个数无养I��因此哈希表的渐进讉K��旉���为O�Q?�Q�,昄����q�远好于数组的O(n)�?/P>
最后,我们要认识到对哈希表的扩充将以性能损耗�ؓ代�h。因此,你应该预先估计你的哈希表中最后可能会容纳的元素��L���Q�在初始化哈希表时以合适的��D��行构造,以避免不必要的扩充�?BR>
using System.Collections;
{
private static Hashtable ages = new Hashtable();
{
// Add some values to the Hashtable, indexed by a string key
ages.Add("Scott", 25);
ages.Add("Sam", 6);
ages.Add("Jisun", 25);
// Access a particular key
if (ages.ContainsKey("Scott"))
{
int scottsAge = (int) ages["Scott"];
Console.WriteLine("Scott is " + scottsAge.ToString());
}
else
Console.WriteLine("Scott is not in the hash table...");
}
}
�E�序中的ContainsKey()�Ҏ���Q�是�Ҏ��特定的key判断是否存在�W�合条�g的元素,�q�回布尔倹{��Hashtable�c�M��包含keys属性(property�Q�,�q�回哈希表中使用的所有关键字的集合。这个属性可以通过遍历讉K���Q�如下:
foreach(string key in ages.Keys)
Console.WriteLine("Value at ages[\"" + key + "\"] = " + ages[key].ToString());
Value at ages["Scott"] = 25
Value at ages["Sam"] = 6
Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5) + 1) % (hashsize �?1)))] % hashsize
1�Q?nbsp;哈希表的位置�I�间�q�似地成倍增加。准���地��_��位置�I�间��g��当前的素数值增加到下一个最大的素数倹{��(回想一下前面讲到的二度哈希的工作原理,哈希表的位置�I�间值必���L��素数。)
2�Q?nbsp;既然二度哈希�Ӟ��哈希表中的所有元素值将依赖于哈希表的位�|�空间��|��所以表中所有��g��需要二度哈希(因�ؓ在第一步中位置�I�间值增加了�Q��?/P>
]]>
]]>