一�?/strong> ����?/strong>
history
started by chad walters and jim
2006.11 G release paper on BigTable
2007.2 inital HBase prototype created as Hadoop contrib
2007.10 First useable Hbase
2008.1 Hadoop become Apache top-level project and Hbase becomes subproject
2008.10 Hbase 0.18,0.19 released
hbase是bigtable的开源山寨版本。是建立的hdfs之上�Q�提供高可靠性、高性能、列存储、可伸羃、实时读写的数据库系�l��?/p>
它介于nosql和RDBMS之间�Q�仅能通过主键(row key)和主键的range来检索数据,仅支持单行事�?可通过hive支持来实现多表join�{�复杂操�?。主要用来存储非�l�构化和半结构化的松散数据�?/p>
与hadoop一��P��Hbase目标主要依靠横向扩展�Q�通过不断增加廉�h的商用服务器�Q�来增加计算和存储能力�?/p>
HBase中的表一般有�q�样的特点:
1 大:一个表可以有上亿行�Q�上百万�?/p>
2 面向�?面向�?�?的存储和权限控制�Q�列(�?独立���索�?/p>
3 �E��?对于为空(null)的列�Q��ƈ不占用存储空��_��因此�Q�表可以设计的非常稀疏�?/p>
下面一�q�图是Hbase在Hadoop Ecosystem中的位置�?/p>

二�?/strong> 逻辑视图
HBase以表的�Ş式存储数据。表有行和列�l�成。列划分������q�个列族(row family)
| Row Key | column-family1 | column-family2 | column-family3 | |||
| column1 | column1 | column1 | column2 | column3 | column1 | |
| key1 | t1:abc t2:gdxdf | t4:dfads t3:hello t2:world | ||||
| key2 | t3:abc t1:gdxdf | t4:dfads t3:hello | t2:dfdsfa t3:dfdf | |||
| key3 | t2:dfadfasd t1:dfdasddsf | t2:dfxxdfasd t1:taobao.com |
Row Key
与nosql数据库们一�?row key是用来检索记录的主键。访问hbase table中的行,只有三种方式�Q?/p>
1 通过单个row key讉K��
2 通过row key的range
3 全表扫描
Row key行键 (Row key)可以是�Q意字�W�串(最大长度是 64KB�Q�实际应用中长度一般�ؓ 10-100bytes)�Q�在hbase内部�Q�row key保存为字节数�l��?/p>
存储�Ӟ��数据按照Row key的字典序(byte order)排序存储。设计key�Ӟ��要充分排序存储这个特性,���经�怸�赯���取的行存储放��C��赗��?位置相关�?
注意�Q?/p>
字典序对int排序的结果是1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整�Ş的自然序�Q�行键必��ȝ��0作左填充�?/p>
行的一�ơ读写是原子操作 (不论一�ơ读写多���列)。这个设计决�{�能够��用户很容易的理解�E�序在对同一个行�q�行�q�发更新操作时的行�ؓ�?/p>
列族
hbase表中的每个列�Q�都归属与某个列族。列族是表的chema的一部分(而列不是)�Q�必���d��使用表之前定义。列名都以列族作为前�~�。例�?em>courses:history �Q?/em> courses:math 都属�?/em> courses �q�个列族�?/p> 讉K��控制、磁盘和内存的��用统计都是在列族层面�q�行的。实际应用中�Q�列族上的控制权限能 帮助我们���理不同�c�d��的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据�ƈ创徏�l�承的列族、一些应用则只允许浏览数据(甚至可能�?为隐�U�的原因不能���览所有数据)�?/p> 旉����?/strong> HBase中通过row和columns���定的�ؓ一个存贮单元称为cell。每�?cell都保存着同一份数据的多个版本。版本通过旉�����x��索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋��|��此时旉�����x���_����到毫�U�的当前�pȝ��旉���。时间戳也可以由客户昑ּ�赋倹{��如果应用程序要避免数据版本冲突�Q�就必须自己生成��h��唯一性的旉���戟뀂每�?cell中,不同版本的数据按照时间倒序排序�Q�即最新的数据排在最前面�?/p> ��Z��避免数据存在�q�多版本造成的的���理 (包括存贮和烦�?负担�Q�hbase提供了两�U�数据版本回收方式。一是保存数据的最后n个版本,二是保存最�q�一�D�|��间内的版本(比如最�q�七天)。用户可以针�Ҏ��个列族进行设�|��?/p> Cell �?em>{row key, column( 1 已经提到�q�,Table中的所有行都按照row key的字典序排列�?/p> 2 Table 在行的方向上分割为多个Hregion�?/p> 5 HRegion虽然是分布式存储的最���单元,但�ƈ不是存储的最���单元�?/p> 事实上,HRegion�׃��个或者多个Store�l�成�Q�每个store保存一个columns family�?/p> 每个Strore又由一个memStore�?臛_��个StoreFile�l�成。如图: StoreFile以HFile格式保存在HDFS上�?/p> HFile分�ؓ六个部分�Q?/p> Data Block �D?#8211;保存表中的数据,�q�部分可以被压羃 Meta Block �D?(可选的)–保存用户自定义的kv对,可以被压�~��?/p> File Info �D?#8211;Hfile的元信息�Q�不被压�~�,用户也可以在�q�一部分��d��自己的元信息�?/p> Data Block Index �D?#8211;Data Block的烦引。每条烦引的key是被索引的block的第一条记录的key�?/p> Meta Block Index�D?(可选的)–Meta Block的烦引�?/p> Trailer–�q�一�D�|��定长的。保存了每一�D늚�偏移量,��d��一个HFile�Ӟ��会首�?��d��Trailer�Q�Trailer保存了每个段的�v始位�|?�D늚�Magic Number用来做安全check)�Q�然后,DataBlock Index会被��d��到内存中�Q�这��P��当检索某个key�Ӟ��不需要扫描整个HFile�Q�而只需从内存中扑ֈ�key所在的block�Q�通过一�ơ磁盘io���整�?block��d��到内存中�Q�再扑ֈ�需要的key。DataBlock Index采用LRU机制淘汰�?/p> HFile的Data Block�Q�Meta Block通常采用压羃方式存储�Q�压�~�之后可以大大减���网�l�IO和磁盘IO�Q�随之而来的开销当然是需要花费cpu�q�行压羃和解压羃�?/p> 目标Hfile的压�~�支持两�U�方式:Gzip�Q�Lzo�?/p> HLog(WAL log) WAL 意�ؓWrite ahead log(http://en.wikipedia.org/wiki/Write-ahead_logging)�Q�类似mysql中的binlog,用来 做灾难恢复只用,Hlog记录数据的所有变�?一旦数据修改,���可以从log中进行恢复�?/p> 每个Region Server�l�护一个Hlog,而不是每个Region一个。这样不同region(来自不同table)的日志会混在一��P���q�样做的目的是不断追加单�?文�g相对于同时写多个文�g而言�Q�可以减���磁盘寻址�ơ数�Q�因此可以提高对table的写性能。带来的�ȝ��是,如果一台region server下线�Q��ؓ了恢复其上的region�Q�需要将region server上的log�q�行拆分�Q�然后分发到其它region server上进行恢复�?/p> HLog文�g���是一个普通的Hadoop Sequence File�Q�Sequence File 的Key是HLogKey对象�Q�HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时�q�包�?sequence number和timestamp�Q�timestamp�?#8221;写入旉���”�Q�sequence number的�v始��gؓ0�Q�或者是最�q�一�ơ存入文件系�l�中sequence number。HLog Sequece File的Value是HBase的KeyValue对象�Q�即对应HFile中的KeyValue�Q�可参见上文描述�?/p> Client 1 包含讉K��hbase的接口,client�l�护着一些cache来加快对hbase的访问,比如regione的位�|�信息�?/p> Zookeeper 1 保证��M��时候,集群中只有一个master 2 存贮所有Region的寻址入口�?/p> 3 实时监控Region Server的状态,���Region server的上�U�和下线信息实时通知�l�Master 4 存储Hbase的schema,包括有哪些table�Q�每个table有哪些column family Master 1 为Region server分配region 2 负责region server的负载均�?/p> 3 发现失效的region server�q����新分配其上的region 4 GFS上的垃圾文�g回收 5 处理schema更新��h�� Region Server 1 Region server�l�护Master分配�l�它的region�Q�处理对�q�些region的IO��h�� 2 Region server负责切分在运行过�E�中变得�q�大的region 可以看到�Q�client讉K��hbase上数据的�q�程�q�不需要master参与�Q�寻址讉K��zookeeper和region server�Q�数据读写访问regione server�Q�,master仅仅�l�护者table和region的元数据信息�Q�负载很低�?/p> region定位 �pȝ��如何扑ֈ�某个row key (或者某�?row key range)所在的region bigtable 使用三层�c�M��B+树的�l�构来保存region位置�?/p> �W�一层是保存zookeeper里面的文�Ӟ��它持有root region的位�|��?/p> �W�二层root region�?META.表的�W�一个region其中保存�?META.z表其它region的位�|�。通过root region�Q�我们就可以讉K��.META.表的数据�?/p> .META.是第三层�Q�它是一个特�D�的表,保存了hbase中所有数据表的region 位置信息�?/p> 说明�Q?/p> 1 root region永远不会被split�Q�保证了最需要三�ơ蟩转,���p��定位��C�Q意region �?/p> 2.META.表每行保存一个region的位�|�信息,row key 采用表名+表的最后一��L��码而成�?/p> 3 ��Z��加快讉K���Q?META.表的全部region都保存在内存中�?/p> 假设�Q?META.表的一行在内存中大�U�占�?KB。�ƈ且每个region限制�?28MB�?/p> 那么上面的三层结构可以保存的region数目为: (128MB/1KB) * (128MB/1KB) = = 2(34)个region 4 client会将查询�q�的位置信息保存�~�存��h���Q�缓存不会主动失效,因此如果client上的�~�存全部失效�Q�则需要进�?�ơ网�l�来回,才能定位到正���的region(其中三次用来发现�~�存失效�Q�另外三�ơ用来获取位�|�信�?�?/p> ��d���q�程 上文提到�Q�hbase使用MemStore和StoreFile存储对表的更新�?/p> 数据在更新时首先写入Log(WAL log)和内�?MemStore)中,MemStore中的数据是排序的�Q�当MemStore累计��C��定阈值时�Q�就会创��Z��个新的MemStore�Q��ƈ 且将老的MemStore��d��到flush队列�Q�由单独的线�E�flush到磁盘上�Q�成��Z��个StoreFile。于此同�Ӟ���pȝ��会在zookeeper�?记录一个redo point�Q�表�C����个时��M��前的变更已经持久化了�?minor compact) 当系�l�出现意外时�Q�可能导致内�?MemStore)中的数据丢失�Q�此时��用Log(WAL log)来恢复checkpoint之后的数据�?/p> 前面提到�q�StoreFile是只�ȝ���Q�一旦创建后��׃��可以再修攏V��因此Hbase的更 新其实是不断�q�加的操作。当一个Store中的StoreFile辑ֈ�一定的阈值后�Q�就会进行一�ơ合�q?major compact),���对同一个key的修改合�q�到一��P��形成一个大的StoreFile�Q�当StoreFile的大���达��C��定阈值后�Q�又会对 StoreFile�q�行split�Q�等分�ؓ两个StoreFile�?/p> �׃��对表的更新是不断�q�加的,处理读请求时�Q�需要访问Store中全部的 StoreFile和MemStore�Q�将他们的按照row key�q�行合�ƈ�Q�由于StoreFile和MemStore都是�l�过排序的,�q�且StoreFile带有内存中烦引,合�ƈ的过�E�还是比较快�?/p> 写请求处理过�E?/p> 1 client向region server提交写请�?/p> 2 region server扑ֈ�目标region 3 region���查数据是否与schema一�?/p> 4 如果客户端没有指定版本,则获取当前系�l�时间作为数据版�?/p> 5 ���更新写入WAL log 6 ���更新写入Memstore 7 判断Memstore的是否需要flush为Store文�g�?/p> region分配 ��M��时刻�Q�一个region只能分配�l�一个region server。master记录了当前有哪些可用的region server。以及当前哪些region分配�l�了哪些region server�Q�哪些region�q�没有分配。当存在未分配的region�Q��ƈ且有一个region server上有可用�I�间�Ӟ��master���q���q�个region server发送一个装载请求,把region分配�l�这个region server。region server得到��h��后,���开始对此region提供服务�?/p> region server上线 master使用zookeeper来跟�t�region server状态。当某个region server启动�Ӟ��会首先在zookeeper上的server目录下徏立代表自��q��文�g�Q��ƈ获得该文件的独占锁。由于master订阅了server 目录上的变更消息�Q�当server目录下的文�g出现新增或删除操作时�Q�master可以得到来自zookeeper的实旉���知。因此一旦region server上线�Q�master能马上得到消息�?/p> region server下线 当region server下线�Ӟ��它和zookeeper的会话断开�Q�zookeeper而自动释放代表这台server的文件上的独占锁。而master不断轮询 server目录下文件的锁状态。如果master发现某个region server丢失了它自己的独占锁�Q?或者master�q�箋几次和region server通信都无法成�?,master���是���试去获取代表这个region server的读写锁�Q�一旦获取成功,���可以确定: 1 region server和zookeeper之间的网�l�断开了�?/p> 2 region server挂了�?/p> 的其中一�U�情况发生了�Q�无论哪�U�情况,region server都无法���l��ؓ它的region提供服务了,此时master会删除server目录下代表这台region server的文�Ӟ���q�将�q�台region server的region分配�l�其它还�zȝ��的同志�?/p> 如果�|�络短暂出现问题��D��region server丢失了它的锁�Q�那么region server重新�q�接到zookeeper之后�Q�只要代表它的文件还在,它就会不断尝试获取这个文件上的锁�Q�一旦获取到了,���可以���l�提供服务�?/p> master上线 master启动�q�行以下步骤: 1 从zookeeper上获取唯一一个代码master的锁�Q�用来阻止其它master成�ؓmaster�?/p> 2 扫描zookeeper上的server目录�Q�获得当前可用的region server列表�?/p> 3 �?中的每个region server通信�Q�获得当前已分配的region和region server的对应关�p�R�?/p> 4 扫描.META.region的集合,计算得到当前�q�未分配的region�Q�将他们攑օ�待分配region列表�?/p> master下线 �׃��master只维护表和region的元数据�Q�而不参与表数据IO的过 �E�,master下线仅导致所有元数据的修改被�ȝ��(无法创徏删除表,无法修改表的schema�Q�无法进行region的负载均衡,无法处理region 上下�U�,无法�q�行region的合�qӞ��唯一例外的是region的split可以正常�q�行�Q�因为只有region server参与)�Q�表的数据读写还可以正常�q�行。因此master下线短时间内�Ҏ��个hbase集群没有影响。从上线�q�程可以看到�Q�master保存�?信息全是可以冗余信息�Q�都可以从系�l�其它地�Ҏ��集到或者计���出来)�Q�因此,一般hbase集群中��L��有一个master在提供服务,�q�有一个以�?�?#8217;master’在等待时机抢占它的位�|��?/p> 六、访问接�?/strong> § 七、结语: 全文�?/strong> Hbase做了 ���单的介绍�Q�有错误之处�Q�敬��h��正。未来将�l�合 Hbase 在淘宝数据��^台的应用场景�Q�在更多�l�节上进行深入�?/strong> 参考文�?/strong> Bigtable: A Distributed Storage System for Structured Data HFile: A Block-Indexed File Format to Store Sorted Key-Value Pairs for a thorough introduction Hbase Architecture 101 Hbase source code 很久没写博客了,因�ؓ很忙�Q�不�q�今天发��C�����不错的文章�Q�帮我梳理了下HBase�Q�原文地址�Q�http://www.tbdata.org/archives/1509三�?/strong> 物理存储
3 region按大���分割的�Q�每个表一开始只有一个region�Q�随着数据不断插入表,region不断增大�Q�当增大��C��个阀值的时候,Hregion��׃���{�分会两个新的Hregion。当table中的行不断增多,��׃��有越来越多的Hregion�?br />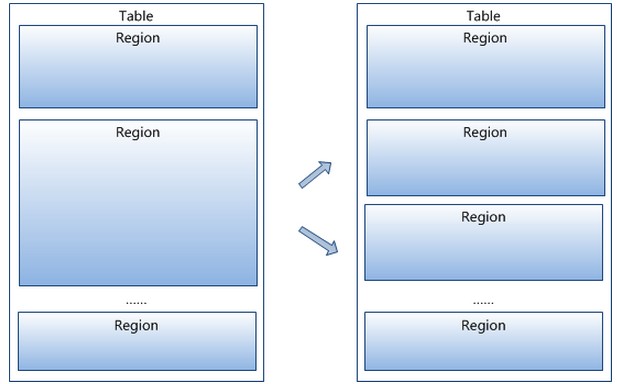
4 Hregion是Hbase中分布式存储和负载均衡的最���单元。最���单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的�?br />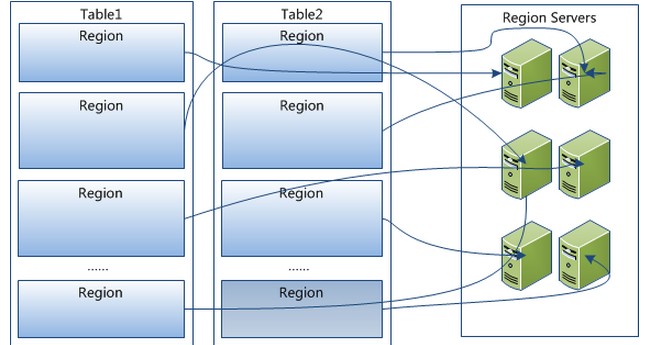
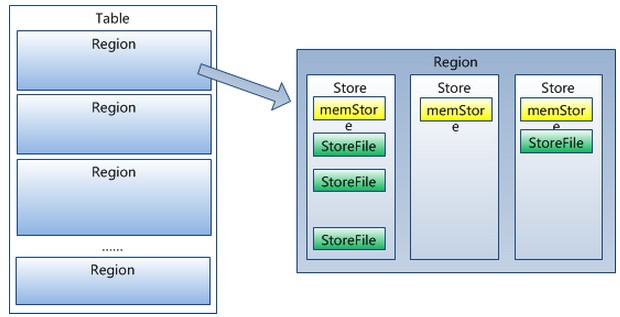
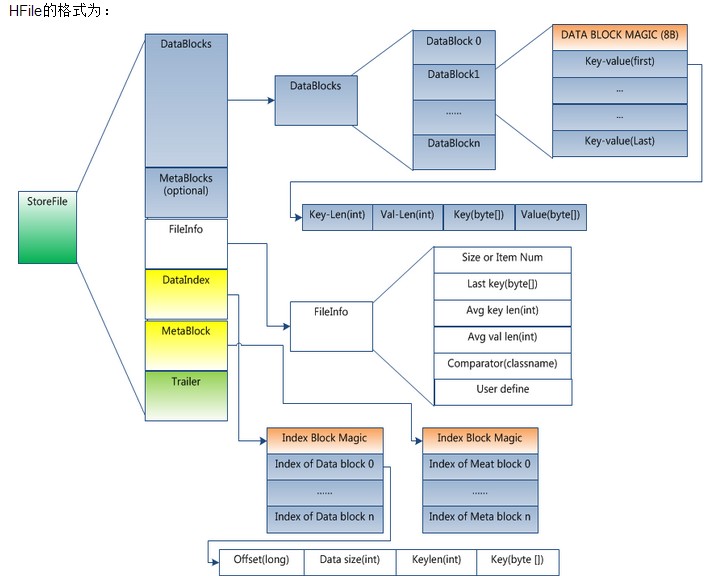
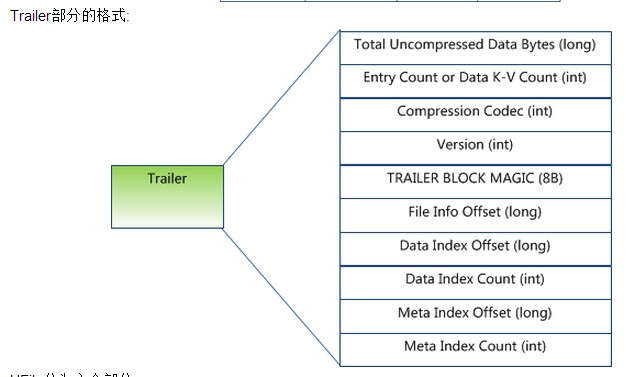
四�?/strong> �pȝ��架构
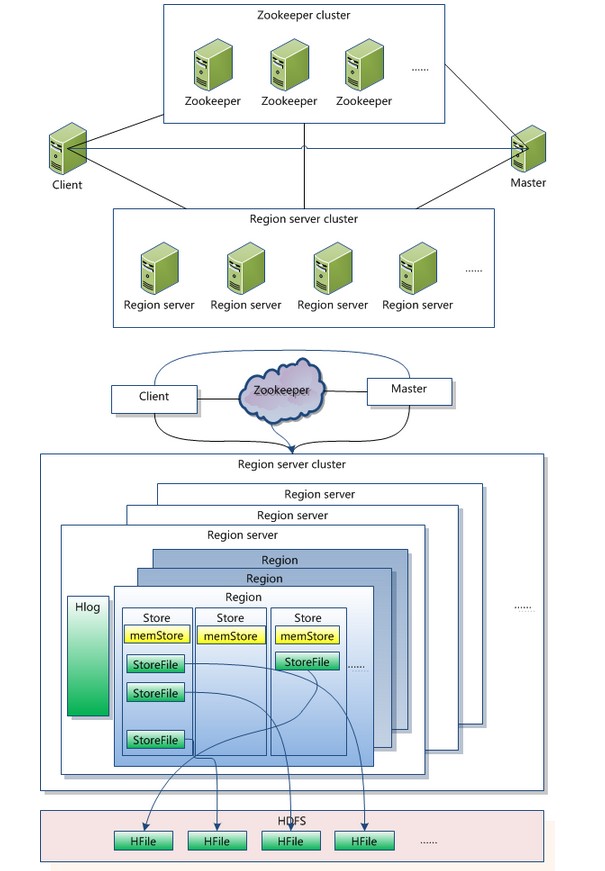
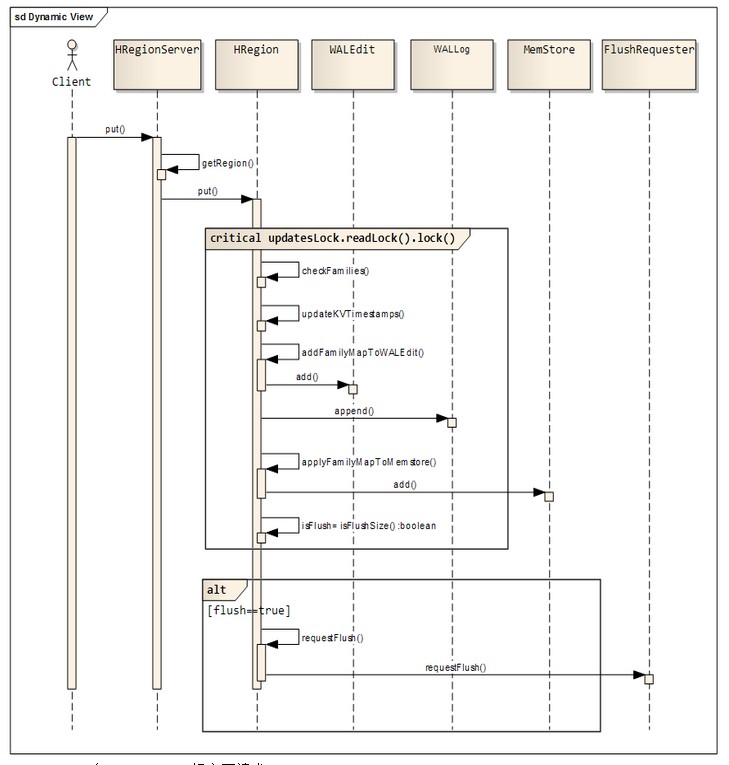
五、关键算�?/strong> / ���程
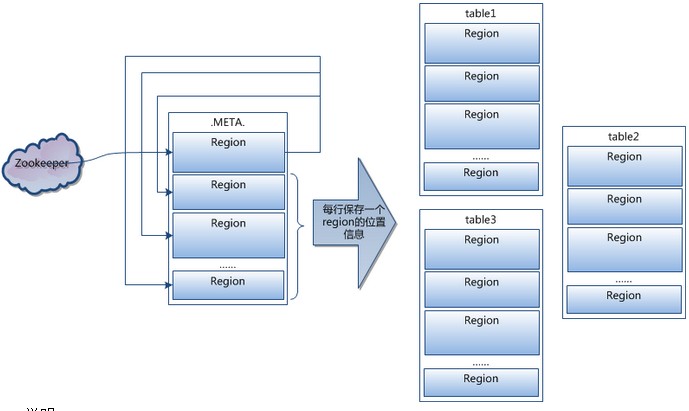
]]>
]]>