|
2014年2月17日
#
原文出自程序人生 >> C++中的返回值優(yōu)化(return value optimization)
返回值優(yōu)化(Return Value Optimization,簡稱RVO),是這么一種優(yōu)化機(jī)制:當(dāng)函數(shù)需要返回一個(gè)對象的時(shí)候,如果自己創(chuàng)建一個(gè)臨時(shí)對象用戶返回,那么這個(gè)臨時(shí)對象會消耗一個(gè)構(gòu)造函數(shù)(Constructor)的調(diào)用、一個(gè)復(fù)制構(gòu)造函數(shù)的調(diào)用(Copy Constructor)以及一個(gè)析構(gòu)函數(shù)(Destructor)的調(diào)用的代價(jià)。而如果稍微做一點(diǎn)優(yōu)化,就可以將成本降低到一個(gè)構(gòu)造函數(shù)的代價(jià),下面是在Visual Studio 2008的Debug模式下做的一個(gè)測試:(在GCC下測試的時(shí)候可能編譯器自己進(jìn)行了RVO優(yōu)化,看不到兩種代碼的區(qū)別)
1 // C++ Return Value Optimization
2 // 作者:代碼瘋子
3 // 博客:http://www.programlife.net/
4 #include <iostream> 5 using namespace std; 6 7 class Rational 8 { 9 public: 10 Rational( int numerator = 0, int denominator = 1) : 11 n(numerator), d(denominator) 12 { 13 cout << "Constructor Called  " << endl; 14 } 15 ~Rational() 16 { 17 cout << "Destructor Called " << endl; 18 } 19 Rational( const Rational& rhs) 20 { 21 this->d = rhs.d; 22 this->n = rhs.n; 23 cout << "Copy Constructor Called " << endl; 24 } 25 int numerator() const { return n; } 26 int denominator() const { return d; } 27 private: 28 int n, d; 29 }; 30 31 //const Rational operator*(const Rational& lhs,
32 // const Rational& rhs)
33 //{
34 // return Rational(lhs.numerator() * rhs.numerator(),
35 // lhs.denominator() * rhs.denominator());
36 //}
37 38 const Rational operator*( const Rational& lhs, 39 const Rational& rhs) 40 { 41 cout << "----------- Enter operator* -----------" << endl; 42 Rational tmp(lhs.numerator() * rhs.numerator(), 43 lhs.denominator() * rhs.denominator()); 44 cout << "----------- Leave operator* -----------" << endl; 45 return tmp; 46 } 47 48 int main( int argc, char **argv) 49 { 50 Rational x(1, 5), y(2, 9); 51 Rational z = x * y; 52 cout << "calc result: " << z.numerator() 53 << "/" << z.denominator() << endl; 54 55 return 0; 56 }
函數(shù)輸出截圖如下:

可以看到消耗一個(gè)構(gòu)造函數(shù)(Constructor)的調(diào)用、一個(gè)復(fù)制構(gòu)造函數(shù)的調(diào)用(Copy Constructor)以及一個(gè)析構(gòu)函數(shù)(Destructor)的調(diào)用的代價(jià)。 而如果把operator*換成另一種形式:
1 const Rational operator*( const Rational& lhs, 2 const Rational& rhs) 3 { 4 return Rational(lhs.numerator() * rhs.numerator(), 5 lhs.denominator() * rhs.denominator()); 6 } 就只會消耗一個(gè)構(gòu)造函數(shù)的成本了:
本文最初發(fā)表于程序人生 >> Copy On Write(寫時(shí)復(fù)制) 作者:代碼瘋子Copy On Write(寫時(shí)復(fù)制)是在編程中比較常見的一個(gè)技術(shù),面試中也會偶爾出現(xiàn)(好像Java中就經(jīng)常有字符串寫時(shí)復(fù)制的筆試題),今天在看《More Effective C++》的引用計(jì)數(shù)時(shí)就講到了Copy On Write——寫時(shí)復(fù)制。下面簡單介紹下Copy On Write(寫時(shí)復(fù)制),我們假設(shè)STL中的string支持寫時(shí)復(fù)制(只是假設(shè),具體未經(jīng)考證,這里以Mircosoft Visual Studio 6.0為例,如果有興趣,可以自己翻閱源碼) Copy On Write(寫時(shí)復(fù)制)的原理是什么?
有一定經(jīng)驗(yàn)的程序員應(yīng)該都知道Copy On Write(寫時(shí)復(fù)制)使用了“引用計(jì)數(shù)”,會有一個(gè)變量用于保存引用的數(shù)量。當(dāng)?shù)谝粋€(gè)類構(gòu)造時(shí),string的構(gòu)造函數(shù)會根據(jù)傳入的參數(shù)從堆上分配內(nèi)存,當(dāng)有其它類需要這塊內(nèi)存時(shí),這個(gè)計(jì)數(shù)為自動(dòng)累加,當(dāng)有類析構(gòu)時(shí),這個(gè)計(jì)數(shù)會減一,直到最后一個(gè)類析構(gòu)時(shí),此時(shí)的引用計(jì)數(shù)為1或是0,此時(shí),程序才會真正的Free這塊從堆上分配的內(nèi)存。
引用計(jì)數(shù)就是string類中寫時(shí)才拷貝的原理! 什么情況下觸發(fā)Copy On Write(寫時(shí)復(fù)制)
很顯然,當(dāng)然是在共享同一塊內(nèi)存的類發(fā)生內(nèi)容改變時(shí),才會發(fā)生Copy On Write(寫時(shí)復(fù)制)。比如string類的[]、=、+=、+等,還有一些string類中諸如insert、replace、append等成員函數(shù)等,包括類的析構(gòu)時(shí)。 示例代碼:
// 作者:代碼瘋子
// 博客:http://www.programlife.net/
// 引用計(jì)數(shù) & 寫時(shí)復(fù)制
#include <iostream>
#include <string>
using namespace std;
int main(int argc, char **argv)
{
string sa = "Copy on write";
string sb = sa;
string sc = sb;
printf("sa char buffer address: 0x%08X\n", sa.c_str());
printf("sb char buffer address: 0x%08X\n", sb.c_str());
printf("sc char buffer address: 0x%08X\n", sc.c_str());
sc = "Now writing..."; printf("After writing sc:\n");
printf("sa char buffer address: 0x%08X\n", sa.c_str());
printf("sb char buffer address: 0x%08X\n", sb.c_str());
printf("sc char buffer address: 0x%08X\n", sc.c_str());
return 0;
} 輸出結(jié)果如下(VC 6.0): 
可以看到,VC6里面的string是支持寫時(shí)復(fù)制的,但是我的Visual Studio 2008就不支持這個(gè)特性(Debug和Release都是):

拓展閱讀:(摘自《Windows Via C/C++》5th Edition,不想看英文可以看中文的PDF,中文版第442頁)
Static Data Is Not Shared by Multiple Instances of an Executable or a DLL
http://apt.jenslody.de/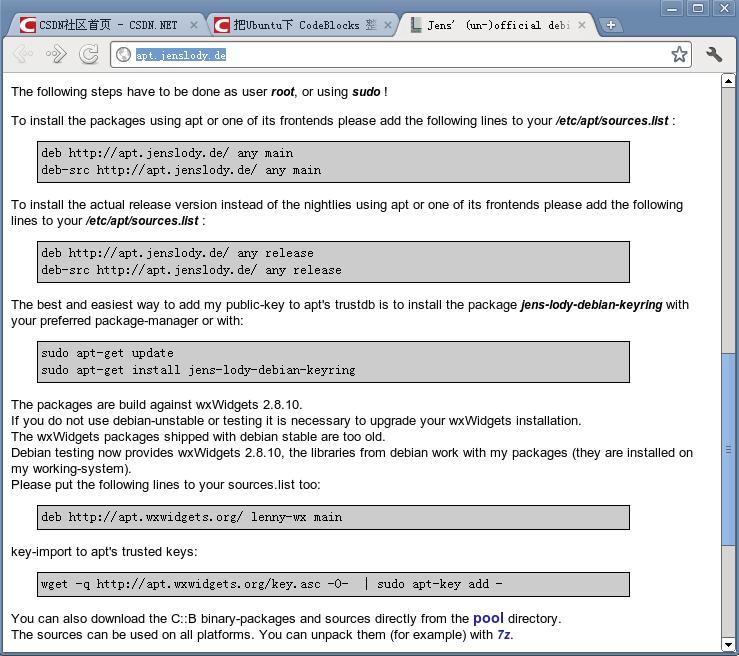 # 打開軟件源配置文件添加下面5行sudo gedit /etc/apt/sources.listdeb http://apt.jenslody.de/ any maindeb-src http://apt.jenslody.de/ any maindeb http://apt.jenslody.de/ any releasedeb-src http://apt.jenslody.de/ any releasedeb http://apt.wxwidgets.org/ lenny-wx main# 更新軟件源配置文件 和 安裝Keysudo apt-get updatesudo apt-get install jens-lody-debian-keyringwget -q http://apt.wxwidgets.org/key.asc -O- | sudo apt-key add -這樣只是把軟件源家進(jìn)去了,并沒有安裝好,所以還要輸入安裝命令# 然后輸入下面這個(gè)命令開始安裝 codeblockssudo apt-get install codeblocks # 打開軟件源配置文件添加下面5行sudo gedit /etc/apt/sources.listdeb http://apt.jenslody.de/ any maindeb-src http://apt.jenslody.de/ any maindeb http://apt.jenslody.de/ any releasedeb-src http://apt.jenslody.de/ any releasedeb http://apt.wxwidgets.org/ lenny-wx main# 更新軟件源配置文件 和 安裝Keysudo apt-get updatesudo apt-get install jens-lody-debian-keyringwget -q http://apt.wxwidgets.org/key.asc -O- | sudo apt-key add -這樣只是把軟件源家進(jìn)去了,并沒有安裝好,所以還要輸入安裝命令# 然后輸入下面這個(gè)命令開始安裝 codeblockssudo apt-get install codeblocks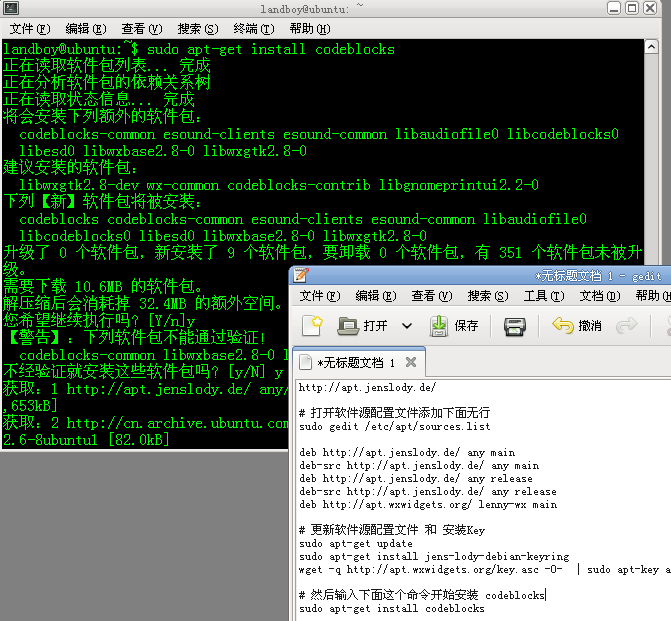 現(xiàn)在安裝好,從編程軟件里開啟CodeBlocks了,是英文的,并且是最近幾日的最版本 現(xiàn)在安裝好,從編程軟件里開啟CodeBlocks了,是英文的,并且是最近幾日的最版本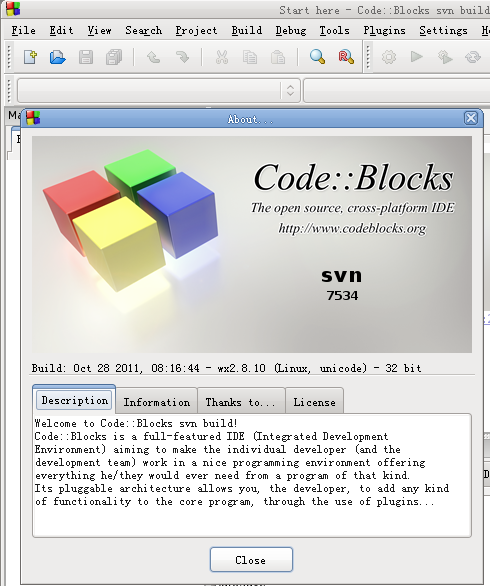 # 你也可以直接下載 CodeBlocks 的二進(jìn)制發(fā)行包,從這個(gè)URL進(jìn)入http://apt.jenslody.de/pool/# 中文化CodeBlocks 下載這個(gè)包,語言文件 Linux下通用的http://srgb.googlecode.com/files/CodeBlocks_Linux_Install.zip進(jìn)入壓縮包把語言文件放到桌面 '/locale/zh_CN/CodeBlocks.mo' 中文化 codeblocks locale/zh_CN/codeblocks.mo 里的 中文化文件放這里 '/usr/share/codeblocks/locale/zh_CN/codeblocks.mo' 設(shè)置權(quán)限為所有人可以訪問 # 你也可以直接下載 CodeBlocks 的二進(jìn)制發(fā)行包,從這個(gè)URL進(jìn)入http://apt.jenslody.de/pool/# 中文化CodeBlocks 下載這個(gè)包,語言文件 Linux下通用的http://srgb.googlecode.com/files/CodeBlocks_Linux_Install.zip進(jìn)入壓縮包把語言文件放到桌面 '/locale/zh_CN/CodeBlocks.mo' 中文化 codeblocks locale/zh_CN/codeblocks.mo 里的 中文化文件放這里 '/usr/share/codeblocks/locale/zh_CN/codeblocks.mo' 設(shè)置權(quán)限為所有人可以訪問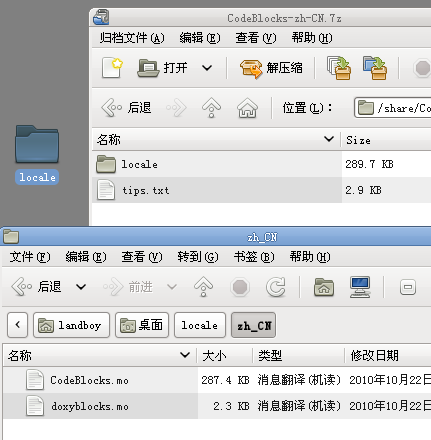  # 使用管理員權(quán)限把 語言包 locale 目錄 拉到 /usr/share/codeblocks里sudo nautilus /usr/share/codeblocks/注意 locale 的權(quán)限可能不完整,所以 選住目錄 所有者-群組-其他設(shè)定都能訪問文件;對包含的文件應(yīng)用權(quán)限;進(jìn)入 /usr/share/codeblocks/locale/zh_CN/ 目錄選兩個(gè)文件右鍵修改權(quán)限 所有者 和 群組 都可以讀寫 # 使用管理員權(quán)限把 語言包 locale 目錄 拉到 /usr/share/codeblocks里sudo nautilus /usr/share/codeblocks/注意 locale 的權(quán)限可能不完整,所以 選住目錄 所有者-群組-其他設(shè)定都能訪問文件;對包含的文件應(yīng)用權(quán)限;進(jìn)入 /usr/share/codeblocks/locale/zh_CN/ 目錄選兩個(gè)文件右鍵修改權(quán)限 所有者 和 群組 都可以讀寫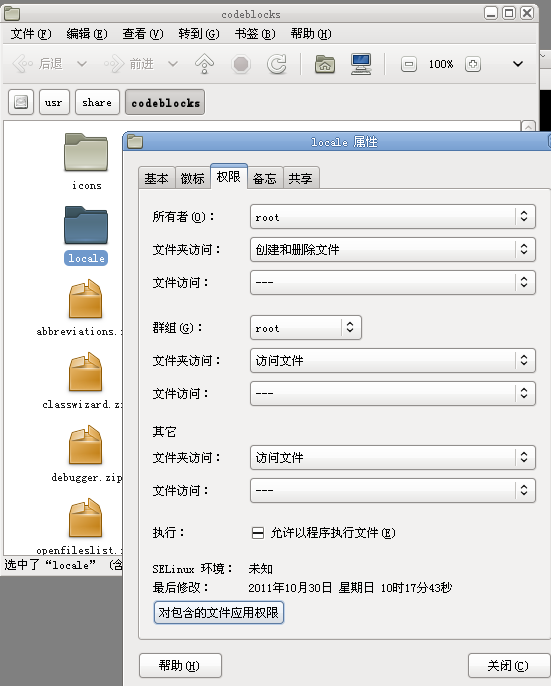  現(xiàn)在安裝的 CodeBlocks 打開是中文里,但是只有基本IDE環(huán)境,很多插件和開發(fā)包沒安裝可以輸入 sudo apt-get install codeblocks <按兩下TAB>列出沒有安裝的其他包, 你可以選擇安裝,我偷懶了sudo apt-get install codeblocks* <回車>sudo apt-get install libwxsmith* <回車>sudo apt-get install libwxgtk2.8-dev <回車> 現(xiàn)在安裝的 CodeBlocks 打開是中文里,但是只有基本IDE環(huán)境,很多插件和開發(fā)包沒安裝可以輸入 sudo apt-get install codeblocks <按兩下TAB>列出沒有安裝的其他包, 你可以選擇安裝,我偷懶了sudo apt-get install codeblocks* <回車>sudo apt-get install libwxsmith* <回車>sudo apt-get install libwxgtk2.8-dev <回車>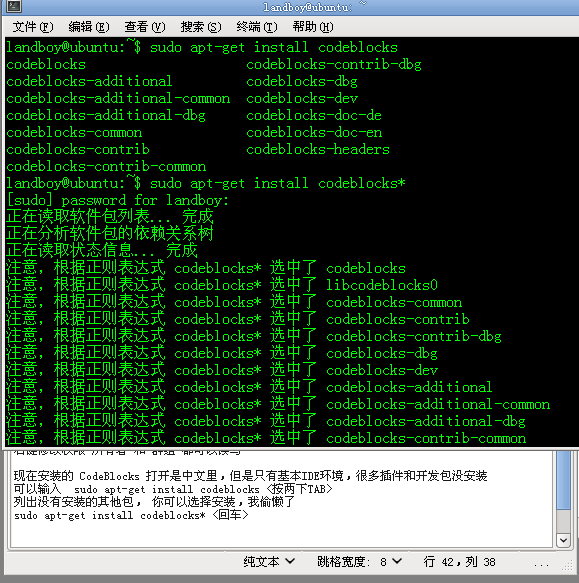 現(xiàn)在開啟CB,建立一個(gè)wx項(xiàng)目,編譯,可以編譯成功了 現(xiàn)在開啟CB,建立一個(gè)wx項(xiàng)目,編譯,可以編譯成功了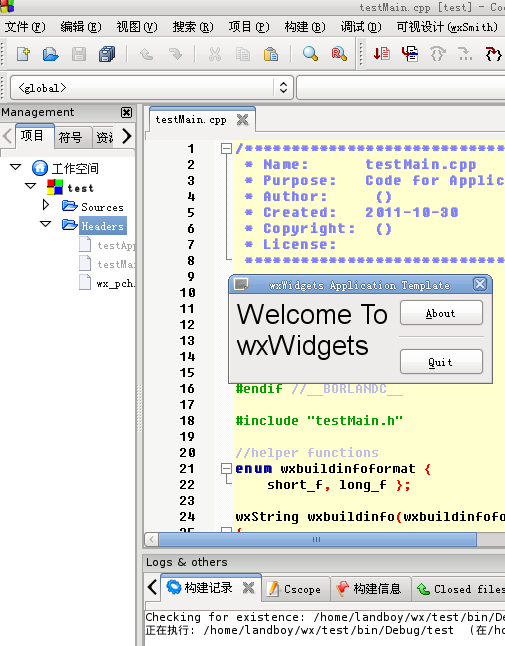
在Lua中可以通過自定義類型的方式與C語言代碼更高效、更靈活的交互。這里我們通過一個(gè)簡單完整的示例來學(xué)習(xí)一下Lua中userdata的使用方式。需要說明的是,該示例完全來自于Programming in Lua。其功能是用C程序?qū)崿F(xiàn)一個(gè)Lua的布爾數(shù)組,以提供程序的執(zhí)行效率。見下面的代碼和關(guān)鍵性注釋。  1 #include <lua.hpp>
2 #include <lauxlib.h>
3 #include <lualib.h>
4 #include <limits.h>
5
6 #define BITS_PER_WORD (CHAR_BIT * sizeof(int))
7 #define I_WORD(i) ((unsigned int)(i))/BITS_PER_WORD
8 #define I_BIT(i) (1 << ((unsigned int)(i)%BITS_PER_WORD))
9
10 typedef struct NumArray {
11 int size; 12 unsigned int values[1];
13 } NumArray;
14
15 extern "C" int newArray(lua_State* L)
16 {
17 //1. 檢查第一個(gè)參數(shù)是否為整型。以及該參數(shù)的值是否大于等于1.
18 int n = luaL_checkint(L,1);
19 luaL_argcheck(L, n >= 1, 1, "invalid size.");
20 size_t nbytes = sizeof(NumArray) + I_WORD(n - 1) * sizeof(int);
21 //2. 參數(shù)表示Lua為userdata分配的字節(jié)數(shù)。同時(shí)將分配后的userdata對象壓入棧中。
22 NumArray* a = (NumArray*)lua_newuserdata(L,nbytes);
23 a->size = n;
24 for (int i = 0; i < I_WORD(n - 1); ++i)
25 a->values[i] = 0;
26 //獲取注冊表變量myarray,該key的值為metatable。
27 luaL_getmetatable(L,"myarray");
28 //將userdata的元表設(shè)置為和myarray關(guān)聯(lián)的table。同時(shí)將棧頂元素彈出。
29 lua_setmetatable(L,-2);
30 return 1;
31 }
32
33 extern "C" int setArray(lua_State* L)
34 {
35 //1. Lua傳給該函數(shù)的第一個(gè)參數(shù)必須是userdata,該對象的元表也必須是注冊表中和myarray關(guān)聯(lián)的table。
36 //否則該函數(shù)報(bào)錯(cuò)并終止程序。
37 NumArray* a = (NumArray*)luaL_checkudata(L,1,"myarray");
38 int index = luaL_checkint(L,2) - 1;
39 //2. 由于任何類型的數(shù)據(jù)都可以成為布爾值,因此這里使用any只是為了確保有3個(gè)參數(shù)。
40 luaL_checkany(L,3);
41 luaL_argcheck(L,a != NULL,1,"'array' expected.");
42 luaL_argcheck(L,0 <= index && index < a->size,2,"index out of range.");
43 if (lua_toboolean(L,3))
44 a->values[I_WORD(index)] |= I_BIT(index);
45 else
46 a->values[I_WORD(index)] &= ~I_BIT(index);
47 return 0;
48 }
49
50 extern "C" int getArray(lua_State* L)
51 {
52 NumArray* a = (NumArray*)luaL_checkudata(L,1,"myarray");
53 int index = luaL_checkint(L,2) - 1;
54 luaL_argcheck(L, a != NULL, 1, "'array' expected.");
55 luaL_argcheck(L, 0 <= index && index < a->size,2,"index out of range");
56 lua_pushboolean(L,a->values[I_WORD(index)] & I_BIT(index));
57 return 1;
58 }
59
60 extern "C" int getSize(lua_State* L)
61 {
62 NumArray* a = (NumArray*)luaL_checkudata(L,1,"myarray");
63 luaL_argcheck(L,a != NULL,1,"'array' expected.");
64 lua_pushinteger(L,a->size);
65 return 1;
66 }
67
68 extern "C" int array2string(lua_State* L)
69 {
70 NumArray* a = (NumArray*)luaL_checkudata(L,1,"myarray");
71 lua_pushfstring(L,"array(%d)",a->size);
72 return 1;
73 }
74
75 static luaL_Reg arraylib_f [] = {
76 {"new", newArray},
77 {NULL, NULL}
78 };
79
80 static luaL_Reg arraylib_m [] = {
81 {"set", setArray},
82 {"get", getArray},
83 {"size", getSize},
84 {"__tostring", array2string}, //print(a)時(shí)Lua會調(diào)用該元方法。
85 {NULL, NULL}
86 };
87
88 extern "C" __declspec(dllexport)
89 int luaopen_testuserdata(lua_State* L)
90 {
91 //1. 創(chuàng)建元表,并將該元表指定給newArray函數(shù)新創(chuàng)建的userdata。在Lua中userdata也是以table的身份表現(xiàn)的。
92 //這樣在調(diào)用對象函數(shù)時(shí),可以通過驗(yàn)證其metatable的名稱來確定參數(shù)userdata是否合法。
93 luaL_newmetatable(L,"myarray");
94 lua_pushvalue(L,-1);
95 //2. 為了實(shí)現(xiàn)面對對象的調(diào)用方式,需要將元表的__index字段指向自身,同時(shí)再將arraylib_m數(shù)組中的函數(shù)注冊到
96 //元表中,之后基于這些注冊函數(shù)的調(diào)用就可以以面向?qū)ο蟮男问秸{(diào)用了。
97 //lua_setfield在執(zhí)行后會將棧頂?shù)膖able彈出。
98 lua_setfield(L,-2,"__index");
99 //將這些成員函數(shù)注冊給元表,以保證Lua在尋找方法時(shí)可以定位。NULL參數(shù)表示將用棧頂?shù)膖able代替第二個(gè)參數(shù)。
100 luaL_register(L,NULL,arraylib_m);
101 //這里只注冊的工廠方法。
102 luaL_register(L,"testuserdata",arraylib_f);
103 return 1;
104 } 輕量級userdata:
之前介紹的是full userdata,Lua還提供了另一種輕量級userdata(light userdata)。事實(shí)上,輕量級userdata僅僅表示的是C指針的值,即(void*)。由于它只是一個(gè)值,所以不用創(chuàng)建。如果需要將一個(gè)輕量級userdata放入棧中,調(diào)用lua_pushlightuserdata即可。full userdata和light userdata之間最大的區(qū)別來自于相等性判斷,對于一個(gè)full userdata,它只是與自身相等,而light userdata則表示為一個(gè)C指針,因此,它與所有表示同一指針的light userdata相等。再有就是light userdata不會受到垃圾收集器的管理,使用時(shí)就像一個(gè)普通的整型數(shù)字一樣。
Lua可以調(diào)用C函數(shù)的能力將極大的提高Lua的可擴(kuò)展性和可用性。對于有些和操作系統(tǒng)相關(guān)的功能,或者是對效率要求較高的模塊,我們完全可以通過C函數(shù)來實(shí)現(xiàn),之后再通過Lua調(diào)用指定的C函數(shù)。對于那些可被Lua調(diào)用的C函數(shù)而言,其接口必須遵循Lua要求的形式,即typedef int (*lua_CFunction)(lua_State* L)。簡單說明一下,該函數(shù)類型僅僅包含一個(gè)表示Lua環(huán)境的指針作為其唯一的參數(shù),實(shí)現(xiàn)者可以通過該指針進(jìn)一步獲取Lua代碼中實(shí)際傳入的參數(shù)。返回值是整型,表示該C函數(shù)將返回給Lua代碼的返回值數(shù)量,如果沒有返回值,則return 0即可。需要說明的是,C函數(shù)無法直接將真正的返回值返回給Lua代碼,而是通過虛擬棧來傳遞Lua代碼和C函數(shù)之間的調(diào)用參數(shù)和返回值的。這里我們將介紹兩種Lua調(diào)用C函數(shù)的規(guī)則。
1. C函數(shù)作為應(yīng)用程序的一部分。 1 #include <stdio.h>
2 #include <string.h>
3 #include <lua.hpp>
4 #include <lauxlib.h>
5 #include <lualib.h>
6
7 //待Lua調(diào)用的C注冊函數(shù)。
8 static int add2(lua_State* L)
9 {
10 //檢查棧中的參數(shù)是否合法,1表示Lua調(diào)用時(shí)的第一個(gè)參數(shù)(從左到右),依此類推。
11 //如果Lua代碼在調(diào)用時(shí)傳遞的參數(shù)不為number,該函數(shù)將報(bào)錯(cuò)并終止程序的執(zhí)行。
12 double op1 = luaL_checknumber(L,1);
13 double op2 = luaL_checknumber(L,2);
14 //將函數(shù)的結(jié)果壓入棧中。如果有多個(gè)返回值,可以在這里多次壓入棧中。
15 lua_pushnumber(L,op1 + op2);
16 //返回值用于提示該C函數(shù)的返回值數(shù)量,即壓入棧中的返回值數(shù)量。
17 return 1;
18 }
19
20 //另一個(gè)待Lua調(diào)用的C注冊函數(shù)。
21 static int sub2(lua_State* L)
22 {
23 double op1 = luaL_checknumber(L,1);
24 double op2 = luaL_checknumber(L,2);
25 lua_pushnumber(L,op1 - op2);
26 return 1;
27 }
28
29 const char* testfunc = "print(add2(1.0,2.0)) print(sub2(20.1,19))";
30
31 int main()
32 {
33 lua_State* L = luaL_newstate();
34 luaL_openlibs(L);
35 //將指定的函數(shù)注冊為Lua的全局函數(shù)變量,其中第一個(gè)字符串參數(shù)為Lua代碼
36 //在調(diào)用C函數(shù)時(shí)使用的全局函數(shù)名,第二個(gè)參數(shù)為實(shí)際C函數(shù)的指針。
37 lua_register(L, "add2", add2);
38 lua_register(L, "sub2", sub2);
39 //在注冊完所有的C函數(shù)之后,即可在Lua的代碼塊中使用這些已經(jīng)注冊的C函數(shù)了。
40 if (luaL_dostring(L,testfunc))
41 printf("Failed to invoke.\n");
42 lua_close(L); 43 return 0; 44 } 2. C函數(shù)庫成為Lua的模塊。
將包含C函數(shù)的代碼生成庫文件,如Linux的so,或Windows的DLL,同時(shí)拷貝到Lua代碼所在的當(dāng)前目錄,或者是LUA_CPATH環(huán)境變量所指向的目錄,以便于Lua解析器可以正確定位到他們。在我當(dāng)前的Windows系統(tǒng)中,我將其copy到"C:\Program Files\Lua\5.1\clibs\",這里包含了所有Lua可調(diào)用的C庫。見如下C語言代碼和關(guān)鍵性注釋: 1 #include <stdio.h>
2 #include <string.h>
3 #include <lua.hpp>
4 #include <lauxlib.h>
5 #include <lualib.h>
6
7 //待注冊的C函數(shù),該函數(shù)的聲明形式在上面的例子中已經(jīng)給出。
8 //需要說明的是,該函數(shù)必須以C的形式被導(dǎo)出,因此extern "C"是必須的。
9 //函數(shù)代碼和上例相同,這里不再贅述。
10 extern "C" int add(lua_State* L)
11 { 12 double op1 = luaL_checknumber(L,1);
13 double op2 = luaL_checknumber(L,2);
14 lua_pushnumber(L,op1 + op2);
15 return 1;
16 }
17
18 extern "C" int sub(lua_State* L)
19 {
20 double op1 = luaL_checknumber(L,1);
21 double op2 = luaL_checknumber(L,2);
22 lua_pushnumber(L,op1 - op2);
23 return 1;
24 }
25
26 //luaL_Reg結(jié)構(gòu)體的第一個(gè)字段為字符串,在注冊時(shí)用于通知Lua該函數(shù)的名字。
27 //第一個(gè)字段為C函數(shù)指針。
28 //結(jié)構(gòu)體數(shù)組中的最后一個(gè)元素的兩個(gè)字段均為NULL,用于提示Lua注冊函數(shù)已經(jīng)到達(dá)數(shù)組的末尾。
29 static luaL_Reg mylibs[] = {
30 {"add", add},
31 {"sub", sub},
32 {NULL, NULL}
33 };
34
35 //該C庫的唯一入口函數(shù)。其函數(shù)簽名等同于上面的注冊函數(shù)。見如下幾點(diǎn)說明:
36 //1. 我們可以將該函數(shù)簡單的理解為模塊的工廠函數(shù)。
37 //2. 其函數(shù)名必須為luaopen_xxx,其中xxx表示library名稱。Lua代碼require "xxx"需要與之對應(yīng)。
38 //3. 在luaL_register的調(diào)用中,其第一個(gè)字符串參數(shù)為模塊名"xxx",第二個(gè)參數(shù)為待注冊函數(shù)的數(shù)組。
39 //4. 需要強(qiáng)調(diào)的是,所有需要用到"xxx"的代碼,不論C還是Lua,都必須保持一致,這是Lua的約定,
40 // 否則將無法調(diào)用。
41 extern "C" __declspec(dllexport)
42 int luaopen_mytestlib(lua_State* L)
43 {
44 const char* libName = "mytestlib";
45 luaL_register(L,libName,mylibs);
46 return 1;
47 } 見如下Lua代碼: 1 require "mytestlib" --指定包名稱
2
3 --在調(diào)用時(shí),必須是package.function
4 print(mytestlib.add(1.0,2.0))
5 print(mytestlib.sub(20.1,19))
摘要: 1. 數(shù)組操作: 在Lua中,“數(shù)組”只是table的一個(gè)別名,是指以一種特殊的方法來使用table。出于性能原因,Lua的C API為數(shù)組操作提供了專門的函數(shù),如: void lua_rawgeti(lua_State* L, int index, int key); ... 閱讀全文
Lua是一種嵌入式腳本語言,即Lua不是可以單獨(dú)運(yùn)行的程序,在實(shí)際應(yīng)用中,主要存在兩種應(yīng)用形式。第一種形式是,C/C++作為主程序,調(diào)用Lua代碼,此時(shí)可以將Lua看做“可擴(kuò)展的語言”,我們將這種應(yīng)用稱為“應(yīng)用程序代碼”。第二種形式是Lua具有控制權(quán),而C/C++代碼則作為Lua的“庫代碼”。在這兩種形式中,都是通過Lua提供的C API完成兩種語言之間的通信的。
1. 基礎(chǔ)知識:
C API是一組能使C/C++代碼與Lua交互的函數(shù)。其中包括讀寫Lua全局變量、調(diào)用Lua函數(shù)、運(yùn)行一段Lua代碼,以及注冊C函數(shù)以供Lua代碼調(diào)用等。這里先給出一個(gè)簡單的示例代碼: 1 #include <stdio.h>
2 #include <string.h>
3 #include <lua.hpp>
4 #include <lauxlib.h>
5 #include <lualib.h>
6
7 int main(void)
8 {
9 const char* buff = "print(\"hello\")";
10 int error;
11 lua_State* L = luaL_newstate();
12 luaL_openlibs(L);
13
14 error = luaL_loadbuffer(L,buff,strlen(buff),"line") || lua_pcall(L,0,0,0);
15 int s = lua_gettop(L);
16 if (error) {
17 fprintf(stderr,"%s",lua_tostring(L,-1));
18 lua_pop(L,1);
19 }
20 lua_close(L);
21 return 0;
22 } 下面是針對以上代碼給出的具體解釋:
1). 上面的代碼是基于我的C++工程,而非C工程,因此包含的頭文件是lua.hpp,如果是C工程,可以直接包含lua.h。
2). Lua庫中沒有定義任何全局變量,而是將所有的狀態(tài)都保存在動(dòng)態(tài)結(jié)構(gòu)lua_State中,后面所有的C API都需要該指針作為第一個(gè)參數(shù)。
3). luaL_openlibs函數(shù)是用于打開Lua中的所有標(biāo)準(zhǔn)庫,如io庫、string庫等。
4). luaL_loadbuffer編譯了buff中的Lua代碼,如果沒有錯(cuò)誤,則返回0,同時(shí)將編譯后的程序塊壓入虛擬棧中。
5). lua_pcall函數(shù)會將程序塊從棧中彈出,并在保護(hù)模式下運(yùn)行該程序塊。執(zhí)行成功返回0,否則將錯(cuò)誤信息壓入棧中。
6). lua_tostring函數(shù)中的-1,表示棧頂?shù)乃饕担瑮5椎乃饕禐?,以此類推。該函數(shù)將返回棧頂?shù)腻e(cuò)誤信息,但是不會將其從棧中彈出。
7). lua_pop是一個(gè)宏,用于從虛擬棧中彈出指定數(shù)量的元素,這里的1表示僅彈出棧頂?shù)脑亍?br /> 8). lua_close用于釋放狀態(tài)指針?biāo)玫馁Y源。
2. 棧:
在Lua和C語言之間進(jìn)行數(shù)據(jù)交換時(shí),由于兩種語言之間有著較大的差異,比如Lua是動(dòng)態(tài)類型,C語言是靜態(tài)類型,Lua是自動(dòng)內(nèi)存管理,而C語言則是手動(dòng)內(nèi)存管理。為了解決這些問題,Lua的設(shè)計(jì)者使用了虛擬棧作為二者之間數(shù)據(jù)交互的介質(zhì)。在C/C++程序中,如果要獲取Lua的值,只需調(diào)用Lua的C API函數(shù),Lua就會將指定的值壓入棧中。要將一個(gè)值傳給Lua時(shí),需要先將該值壓入棧,然后調(diào)用Lua的C API,Lua就會獲取該值并將其從棧中彈出。為了可以將不同類型的值壓入棧,以及從棧中取出不同類型的值,Lua為每種類型均設(shè)定了一個(gè)特定函數(shù)。
1). 壓入元素:
Lua針對每種C類型,都有一個(gè)C API函數(shù)與之對應(yīng),如:
void lua_pushnil(lua_State* L); --nil值
void lua_pushboolean(lua_State* L, int b); --布爾值
void lua_pushnumber(lua_State* L, lua_Number n); --浮點(diǎn)數(shù)
void lua_pushinteger(lua_State* L, lua_Integer n); --整型
void lua_pushlstring(lua_State* L, const char* s, size_t len); --指定長度的內(nèi)存數(shù)據(jù)
void lua_pushstring(lua_State* L, const char* s); --以零結(jié)尾的字符串,其長度可由strlen得出。
對于字符串?dāng)?shù)據(jù),Lua不會持有他們的指針,而是調(diào)用在API時(shí)生成一個(gè)內(nèi)部副本,因此,即使在這些函數(shù)返回后立刻釋放或修改這些字符串指針,也不會有任何問題。
在向棧中壓入數(shù)據(jù)時(shí),可以通過調(diào)用下面的函數(shù)判斷是否有足夠的棧空間可用,一般而言,Lua會預(yù)留20個(gè)槽位,對于普通應(yīng)用來說已經(jīng)足夠了,除非是遇到有很多參數(shù)的函數(shù)。
int lua_checkstack(lua_State* L, int extra) --期望得到extra數(shù)量的空閑槽位,如果不能擴(kuò)展并獲得,返回false。
2). 查詢元素:
API使用“索引”來引用棧中的元素,第一個(gè)壓入棧的為1,第二個(gè)為2,依此類推。我們也可以使用負(fù)數(shù)作為索引值,其中-1表示為棧頂元素,-2為棧頂下面的元素,同樣依此類推。
Lua提供了一組特定的函數(shù)用于檢查返回元素的類型,如:
int lua_isboolean (lua_State *L, int index);
int lua_iscfunction (lua_State *L, int index);
int lua_isfunction (lua_State *L, int index);
int lua_isnil (lua_State *L, int index);
int lua_islightuserdata (lua_State *L, int index);
int lua_isnumber (lua_State *L, int index);
int lua_isstring (lua_State *L, int index);
int lua_istable (lua_State *L, int index);
int lua_isuserdata (lua_State *L, int index);
以上函數(shù),成功返回1,否則返回0。需要特別指出的是,對于lua_isnumber而言,不會檢查值是否為數(shù)字類型,而是檢查值是否能轉(zhuǎn)換為數(shù)字類型。
Lua還提供了一個(gè)函數(shù)lua_type,用于獲取元素的類型,函數(shù)原型如下:
int lua_type (lua_State *L, int index);
該函數(shù)的返回值為一組常量值,分別是:LUA_TNIL、LUA_TNUMBER、LUA_TBOOLEAN、LUA_TSTRING、LUA_TTABLE、LUA_TFUNCTION、LUA_TUSERDATA、LUA_TTHREAD和LUA_TLIGHTUSERDATA。這些常量通常用于switch語句中。
除了上述函數(shù)之外,Lua還提供了一組轉(zhuǎn)換函數(shù),如:
int lua_toboolean (lua_State *L, int index);
lua_CFunction lua_tocfunction (lua_State *L, int index);
lua_Integer lua_tointeger (lua_State *L, int index);
const char *lua_tolstring (lua_State *L, int index, size_t *len);
lua_Number lua_tonumber (lua_State *L, int index);
const void *lua_topointer (lua_State *L, int index);
const char *lua_tostring (lua_State *L, int index);
void *lua_touserdata (lua_State *L, int index);
--string類型返回字符串長度,table類型返回操作符'#'等同的結(jié)果,userdata類型返回分配的內(nèi)存塊長度。
size_t lua_objlen (lua_State *L, int index);
對于上述函數(shù),如果調(diào)用失敗,lua_toboolean、lua_tonumber、lua_tointeger和lua_objlen均返回0,而其他函數(shù)則返回NULL。在很多時(shí)候0不是一個(gè)很有效的用于判斷錯(cuò)誤的值,但是ANSI C沒有提供其他可以表示錯(cuò)誤的值。因此對于這些函數(shù),在有些情況下需要先使用lua_is*系列函數(shù)判斷是否類型正確,而對于剩下的函數(shù),則可以直接通過判斷返回值是否為NULL即可。
對于lua_tolstring函數(shù)返回的指向內(nèi)部字符串的指針,在該索引指向的元素被彈出之后,將無法保證仍然有效。該函數(shù)返回的字符串末尾均會有一個(gè)尾部0。
下面將給出一個(gè)工具函數(shù),可用于演示上面提到的部分函數(shù),如: 1 static void stackDump(lua_State* L)
2 {
3 int top = lua_gettop(L);
4 for (int i = 1; i <= top; ++i) {
5 int t = lua_type(L,i);
6 switch(t) {
7 case LUA_TSTRING:
8 printf("'%s'",lua_tostring(L,i));
9 break;
10 case LUA_TBOOLEAN:
11 printf(lua_toboolean(L,i) ? "true" : "false");
12 break;
13 case LUA_TNUMBER:
14 printf("%g",lua_tonumber(L,i));
15 break;
16 default:
17 printf("%s",lua_typename(L,t));
18 break;
19 }
20 printf("");
21 }
22 printf("\n");
23 } 3). 其它棧操作函數(shù):
除了上面給出的數(shù)據(jù)交換函數(shù)之外,Lua的C API還提供了一組用于操作虛擬棧的普通函數(shù),如:
int lua_gettop(lua_State* L); --返回棧中元素的個(gè)數(shù)。
void lua_settop(lua_State* L, int index); --將棧頂設(shè)置為指定的索引值。
void lua_pushvalue(lua_State* L, int index); --將指定索引的元素副本壓入棧。
void lua_remove(lua_State* L, int index); --刪除指定索引上的元素,其上面的元素自動(dòng)下移。
void lua_insert(lua_State* L, int index); --將棧頂元素插入到該索引值指向的位置。
void lua_replace(lua_State* L, int index); --彈出棧頂元素,并將該值設(shè)置到指定索引上。
Lua還提供了一個(gè)宏用于彈出指定數(shù)量的元素:#define lua_pop(L,n) lua_settop(L, -(n) - 1)
見如下示例代碼: 1 int main()
2 {
3 lua_State* L = luaL_newstate();
4 lua_pushboolean(L,1);
5 lua_pushnumber(L,10);
6 lua_pushnil(L);
7 lua_pushstring(L,"hello");
8 stackDump(L); //true 10 nil 'hello'
9
10 lua_pushvalue(L,-4);
11 stackDump(L); //true 10 nil 'hello' true
12
13 lua_replace(L,3);
14 stackDump(L); //true 10 true 'hello'
15
16 lua_settop(L,6);
17 stackDump(L); //true 10 true 'hello' nil nil
18
19 lua_remove(L,-3);
20 stackDump(L); //true 10 true nil nil
21
22 lua_settop(L,-5);
23 stackDump(L); //true
24
25 lua_close(L);
26 return 0;
27 }
3. C API中的錯(cuò)誤處理:
1). C程序調(diào)用Lua代碼的錯(cuò)誤處理:
通常情況下,應(yīng)用程序代碼是以“無保護(hù)”模式運(yùn)行的。因此,當(dāng)Lua發(fā)現(xiàn)“內(nèi)存不足”這類錯(cuò)誤時(shí),只能通過調(diào)用“緊急”函數(shù)來通知C語言程序,之后在結(jié)束應(yīng)用程序。用戶可通過lua_atpanic來設(shè)置自己的“緊急”函數(shù)。如果希望應(yīng)用程序代碼在發(fā)生Lua錯(cuò)誤時(shí)不會退出,可通過調(diào)用lua_pcall函數(shù)以保護(hù)模式運(yùn)行Lua代碼。這樣再發(fā)生內(nèi)存錯(cuò)誤時(shí),lua_pcall會返回一個(gè)錯(cuò)誤代碼,并將解釋器重置為一致的狀態(tài)。如果要保護(hù)與Lua的C代碼,可以使用lua_cpall函數(shù),它將接受一個(gè)C函數(shù)作為參數(shù),然后調(diào)用這個(gè)C函數(shù)。
2). Lua調(diào)用C程序:
通常而言,當(dāng)一個(gè)被Lua調(diào)用的C函數(shù)檢測到錯(cuò)誤時(shí),它就應(yīng)該調(diào)用lua_error,該函數(shù)會清理Lua中所有需要清理的資源,然后跳轉(zhuǎn)回發(fā)起執(zhí)行的那個(gè)lua_pcall,并附上一條錯(cuò)誤信息。
摘要: 1. 基礎(chǔ): Lua的一項(xiàng)重要用途就是作為一種配置語言。現(xiàn)在從一個(gè)簡單的示例開始吧。 --這里是用Lua代碼定義的窗口大小的配置信息 width = 200 height = 300 下面是讀取配置信息的C/... 閱讀全文
I/O庫為文件操作提供了兩種不同的模型,簡單模型和完整模型。簡單模型假設(shè)一個(gè)當(dāng)前輸入文件和一個(gè)當(dāng)前輸出文件,他的I/O操作均作用于這些文件。完整模型則使用顯式的文件句柄,并將所有的操作定義為文件句柄上的方法。
1. 簡單模型:
I/O庫會將進(jìn)程標(biāo)準(zhǔn)輸入輸出作為其缺省的輸入文件和輸出文件。我們可以通過io.input(filename)和io.output(filename)這兩個(gè)函數(shù)來改變當(dāng)前的輸入輸出文件。
1). io.write函數(shù):
函數(shù)原型為io.write(...)。該函數(shù)將所有參數(shù)順序的寫入到當(dāng)前輸出文件中。如:
io.write("hello","world") --寫出的內(nèi)容為helloworld
2). io.read函數(shù):
下表給出了該函數(shù)參數(shù)的定義和功能描述: | 參數(shù)字符串 | 含義 | | "*all" | 讀取整個(gè)文件 | | "*line" | 讀取下一行 | | "*number" | 讀取一個(gè)數(shù)字 | | <num> | 讀取一個(gè)不超過<num>個(gè)字符的字符串 |
調(diào)用io.read("*all")會讀取當(dāng)前輸入文件的所有內(nèi)容,以當(dāng)前位置作為開始。如果當(dāng)前位置處于文件的末尾,或者文件為空,那個(gè)該調(diào)用返回一個(gè)空字符串。由于Lua可以高效的處理長字符串,因此在Lua中可以先將數(shù)據(jù)從文件中完整讀出,之后在通過Lua字符串庫提供的函數(shù)進(jìn)行各種處理。
調(diào)用io.read("*line")會返回當(dāng)前文件的下一行,但不包含換行符。當(dāng)?shù)竭_(dá)文件末尾時(shí),該調(diào)用返回nil。如: 1 for count = 1,math.huge do
2 local line = io.read("*line") --如果不傳參數(shù),缺省值也是"*line"
3 if line == nil then
4 break
5 end
6 io.write(string.format("%6d ",count),line,"\n")
7 end 如果只是為了迭代文件中的所有行,可以使用io.lines函數(shù),以迭代器的形式訪問文件中的每一行數(shù)據(jù),如: 1 local lines = {}
2 for line in io.lines() do --通過迭代器訪問每一個(gè)數(shù)據(jù)
3 lines[#lines + 1] = line
4 end
5 table.sort(lines) --排序,Lua標(biāo)準(zhǔn)庫的table庫提供的函數(shù)。
6 for _,l in ipairs(lines) do
7 io.write(l,"\n")
8 end 調(diào)用io.read("*number")會從當(dāng)前輸入文件中讀取一個(gè)數(shù)字。此時(shí)read將直接返回一個(gè)數(shù)字,而不是字符串。"*number"選項(xiàng)會忽略數(shù)字前面所有的空格,并且能處理像-3、+5.2這樣的數(shù)字格式。如果當(dāng)前讀取的數(shù)據(jù)不是合法的數(shù)字,read返回nil。在調(diào)用read是可以指定多個(gè)選項(xiàng),函數(shù)會根據(jù)每個(gè)選項(xiàng)參數(shù)返回相應(yīng)的內(nèi)容。如: 1 --[[
2 6.0 -3.23 1000
3 ... ...
4 下面的代碼讀取注釋中的數(shù)字
5 --]]
6 while true do
7 local n1,n2,n3 = io.read("*number","*number","*number")
8 if not n1 then
9 break
10 end
11 print(math.max(n1,n2,n3))
12 end 調(diào)用io.read(<num>)會從輸入文件中最多讀取n個(gè)字符,如果讀不到任何字符,返回nil。否則返回讀取到的字符串。如: 1 while true do
2 local block = io.read(2^13)
3 if not block then
4 break
5 end
6 io.write(block)
7 end io.read(0)是一種特殊的情況,用于檢查是否到達(dá)了文件的末尾。如果沒有到達(dá),返回空字符串,否則nil。
2. 完整I/O模型:
Lua中完整I/O模型的使用方式非常類似于C運(yùn)行時(shí)庫的文件操作函數(shù),它們都是基于文件句柄的。
1). 通過io.open函數(shù)打開指定的文件,并且在參數(shù)中給出對該文件的打開模式,其中"r"表示讀取,"w"表示覆蓋寫入,即先刪除文件原有的內(nèi)容,"a"表示追加式寫入,"b"表示以二進(jìn)制的方式打開文件。在成功打開文件后,該函數(shù)將返回表示該文件的句柄,后面所有基于該文件的操作,都需要將該句柄作為參數(shù)傳入。如果打開失敗,返回nil。其中錯(cuò)誤信息由該函數(shù)的第二個(gè)參數(shù)返回,如:
assert(io.open(filename,mode)) --如果打開失敗,assert將打印第二個(gè)參數(shù)給出的錯(cuò)誤信息。
2). 文件讀寫函數(shù)read/write。這里需要用到冒號語法,如: 1 local f = assert(io.open(filename,"r"))
2 local t = f:read("*all") --對于read而言,其參數(shù)完全等同于簡單模型下read的參數(shù)。
3 f:close() 此外,I/O庫還提供了3個(gè)預(yù)定義的文件句柄,即io.stdin(標(biāo)準(zhǔn)輸入)、io.stdout(標(biāo)準(zhǔn)輸出)、io.stderr(標(biāo)準(zhǔn)錯(cuò)誤輸出)。如:
io.stderr:write("This is an error message.")
事實(shí)上,我們也可以混合使用簡單模式和完整模式,如: 1 local temp = io.input() --將當(dāng)前文件句柄保存
2 io.input("newInputfile") --打開新的輸入文件
3 io.input():close() --關(guān)閉當(dāng)前文件
4 io.input(temp) --恢復(fù)原來的輸入文件
3). 性能小技巧:
由于一次性讀取整個(gè)文件比逐行讀取要快一些,但對于較大的文件,這樣并不可行,因此Lua提供了一種折中的方式,即一次讀取指定字節(jié)數(shù)量的數(shù)據(jù),如果當(dāng)前讀取中的最后一行不是完整的一行,可通過該方式將該行的剩余部分也一并讀入,從而保證本次讀取的數(shù)據(jù)均為整行數(shù)據(jù),以便于上層邏輯的處理。如:
local lines,rest = f:read(BUFSIZE,"*line") --rest變量包含最后一行中沒有讀取的部分。
下面是Shell中wc命令的一個(gè)簡單實(shí)現(xiàn)。
1 local BUFSIZE = 8192
2 local f = io.input(arg[1]) --打開輸入文件
3 local cc, lc, wc, = 0, 0, 0 --分別計(jì)數(shù)字符、行和單詞
4 while true do
5 local lines,rest = f:read(BUFSIZE,"*line")
6 if not lines then
7 break
8 end
9 if rest then
10 lines = lines .. rest .. "\n"
11 end
12 cc = cc + #lines
13 --計(jì)算單詞數(shù)量
14 local _, t = string.gsub(lines."%S+","")
15 wc = wc + t
16 --計(jì)算行數(shù)
17 _,t = string.gsub(line,"\n","\n")
18 lc = lc + t
19 end
20 print(lc,wc,cc)
4). 其它文件操作:
如io.flush函數(shù)會將io緩存中的數(shù)據(jù)刷新到磁盤文件上。io.close函數(shù)將關(guān)閉當(dāng)前打開的文件。io.seek函數(shù)用于設(shè)置或獲取當(dāng)前文件的讀寫位置,其函數(shù)原型為f:seek(whence,offset),如果whence的值為"set",offset的值則表示為相對于文件起始位置的偏移量。如為"cur"(默認(rèn)值),offset則為相對于當(dāng)前位置的偏移量,如為"end",則為相對于文件末尾的偏移量。函數(shù)的返回值與whence參數(shù)無關(guān),總是返回文件的當(dāng)前位置,即相對于文件起始處的偏移字節(jié)數(shù)。offset的默認(rèn)值為0。如:
1 function fsize(file)
2 local current = file:seek() --獲取當(dāng)前位置
3 local size = file:seek("end") --獲取文件大小
4 file:seek("set",current) --恢復(fù)原有的當(dāng)前位置
5 return size
6 end 最后需要指出的是,如果發(fā)生錯(cuò)誤,所有這些函數(shù)均返回nil和一條錯(cuò)誤信息。
Lua為了保證高度的可移植性,因此,它的標(biāo)準(zhǔn)庫僅僅提供了非常少的功能,特別是和OS相關(guān)的庫。但是Lua還提供了一些擴(kuò)展庫,比如Posix庫等。對于文件操作而言,該庫僅提供了os.rename函數(shù)和os.remove函數(shù)。
1. 日期和時(shí)間:
在Lua中,函數(shù)time和date提供了所有的日期和時(shí)間功能。
如果不帶任何參數(shù)調(diào)用time函數(shù),它將以數(shù)字形式返回當(dāng)前的日期和時(shí)間。如果以一個(gè)table作為參數(shù),它將返回一個(gè)數(shù)字,表示該table中所描述的日期和時(shí)間。該table的有效字段如下: | 字段名 | 描述 | | year | 一個(gè)完整的年份 | | month | 01-12 | | day | 01-31 | | hour | 00-23 | | min | 00-59 | | sec | 00-59 | | isdst | 布爾值,true表示夏令時(shí) |
print(os.time{year = 1970, month = 1, day = 1, hour = 8, min = 0}) --北京是東八區(qū),所以hour等于時(shí)表示UTC的0。
print(os.time()) --輸出當(dāng)前時(shí)間距離1970-1-1 00:00:00所經(jīng)過的秒數(shù)。輸出值為 1333594721
函數(shù)date是time的反函數(shù),即可以將time返回的數(shù)字值轉(zhuǎn)換為更高級的可讀格式,其第一個(gè)參數(shù)是格式化字符串,表示期望的日期返回格式,第二個(gè)參數(shù)是日期和時(shí)間的數(shù)字,缺省為當(dāng)前日期和時(shí)間。如: 1 dd = os.date("*t",os.time()) --如果格式化字符串為"*t",函數(shù)將返回table形式的日期對象。如果為"!*t",則表示為UTC時(shí)間格式。
2 print("year = " .. dd.year)
3 print("month = " .. dd.month)
4 print("day = " .. dd.day)
5 print("weekday = " .. dd.wday) --一個(gè)星期中的第幾天,周日是第一天
6 print("yearday = " .. dd.yday) --一年中的第幾天,1月1日是第一天
7 print("hour = " .. dd.hour)
8 print("min = " .. dd.min)
9 print("sec = " .. dd.sec)
10
11 --[[
12 year = 2012
13 month = 4
14 day = 5
15 weekday = 5
16 yearday = 96
17 hour = 11
18 min = 13
19 sec = 44
20 --]] date函數(shù)的格式化標(biāo)識和C運(yùn)行時(shí)庫中的strftime函數(shù)的標(biāo)識完全相同,見下表: | 關(guān)鍵字 | 描述 | | %a | 一星期中天數(shù)的縮寫,如Wed | | %A | 一星期中天數(shù)的全稱,如Friday | | %b | 月份的縮寫,如Sep | | %B | 月份的全稱,如September | | %c | 日期和時(shí)間 | | %d | 一個(gè)月中的第幾天(01-31) | | %H | 24小時(shí)制中的小時(shí)數(shù)(00-23) | | %I | 12小時(shí)制中的小時(shí)數(shù)(01-12) | | %j | 一年中的第幾天(001-366) | | %M | 分鐘(00-59) | | %m | 月份(01-12) | | %p | "上午(am)"或"下午(pm)" | | %S | 秒數(shù)(00-59) | | %w | 一星期中的第幾天(0--6等價(jià)于星期日--星期六) | | %x | 日期,如09/16/2010 | | %X | 時(shí)間,如23:48:20 | | %y | 兩位數(shù)的年份(00-99) | | %Y | 完整的年份(2012) | | %% | 字符'%' |
print(os.date("%Y-%m-%d")) --輸出2012-04-05
函數(shù)os.clock()返回CPU時(shí)間的描述,通常用于計(jì)算一段代碼的執(zhí)行效率。如: 1 local x = os.clock()
2 local s = 0
3 for i = 1, 10000000 do
4 s = s + i
5 end
6 print(string.format("elapsed time: %.2f\n", os.clock() - x))
7
8 --輸出結(jié)果為:
9 --elapsed time: 0.21
2. 其他系統(tǒng)調(diào)用:
函數(shù)os.exit()可中止當(dāng)前程序的執(zhí)行。函數(shù)os.getenv()可獲取一個(gè)環(huán)境變量的值。如:
print(os.getenv("PATH")) --如果環(huán)境變量不存在,返回nil。
os.execute函數(shù)用于執(zhí)行和操作系統(tǒng)相關(guān)的命令,如:
os.execute("mkdir " .. "hello")
|