(金庆的专�?2018.6)
因�ؓk8s使用 etcd, 所以�?etcd 作�ؓ服务发现�?DB.
registrator 可以�?docker 方式�q�行的服务自动注册到 etcd.
confd ��d�� etcd, 生成配置文�g�?br />
先运行一个etcd用于���试�Q?br />
docker run -d \
-p 12379:2379 \
--name jinqing-etcd \
quay.io/coreos/etcd \
/usr/local/bin/etcd \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:12379
再运�?registrator:
docker run -d --rm \
--name=jinqing-registrator \
--net=host \
--volume=/var/run/docker.sock:/tmp/docker.sock \
gliderlabs/registrator:latest \
-ip="192.168.93.183" \
etcd://127.0.0.1:12379/registrator
好像只能使用本机�?etcd. 一般需要用-ip参数指定本机IP。注册到 registrator 目录�?br />
�?etcdkeeper 可以查看自动注册的服务。registrator 不支�?etcd v3.
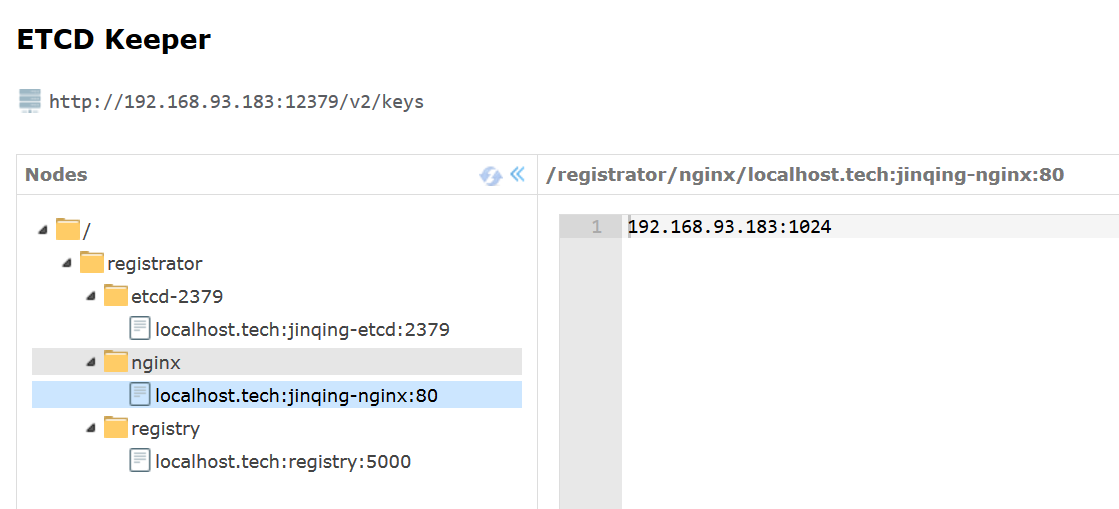
然后配置 confd
mkdir -p /etc/confd/{conf.d,templates}
/etc/confd/conf.d/myconfig.toml
[template]
src = "services.toml.tmpl"
dest = "/tmp/services.toml"
keys = [
"/registrator",
]
/etc/confd/templates/services.toml.tmpl
[config]
{{- range lsdir "/registrator"}}
{{- $serviceName := . }}
{{- $serviceDir := printf "/registrator/%s/*" $serviceName }}
[config.{{ $serviceName }}]
# {{ $serviceDir }}
{{- range gets $serviceDir }}
{{ base .Key }} = {{ .Value }}
{{- end }}
{{- end}}
# End of [config].
�?lsdir 列出所有服务目录,然后�?gets 取服务目录下的键值对�?br />
执行 confd:
~/go/bin/confd -onetime -backend etcd -node http://127.0.0.1:12379
[jinqing@localhost confd]$ cat /tmp/services.toml
[config]
[config.etcd-2379]
# /registrator/etcd-2379/*
localhost.tech:jinqing-etcd:2379 = 192.168.93.183:12379
[config.nginx]
# /registrator/nginx/*
localhost.tech:jinqing-nginx:80 = 192.168.93.183:1024
[config.registry]
# /registrator/registry/*
localhost.tech:registry:5000 = 192.168.93.183:5000
# End of [config].
]]>
(金庆的专�?2017.10)
�?个docker swarm节点�Q�开启redis cluster.
每个机器上开2个redis节点�Q�共10个redis节点�?br />采用官方的redis:alpine镜像�?br />
docker-stack.yml 如下�Q?br />
version: "3"
services:
redis001:
image: redis:alpine
volumes:
- /home/redis/001/data:/data
- /home/redis/001/conf:/conf
command: redis-server --appendonly yes --cluster-enabled yes --cluster-config-file /conf/nodes.conf --cluster-announce-ip 10.240.79.8 --cluster-announce-port 7001 --cluster-announce-bus-port 17001
ports:
- "7001:6379"
- "17001:16379"
networks:
- redisnet
deploy:
placement:
constraints:
- node.hostname == host-10-240-79-8
redis002:
image: redis:alpine
volumes:
- /home/redis/002/data:/data
- /home/redis/002/conf:/conf
command: redis-server --appendonly yes --cluster-enabled yes --cluster-config-file /conf/nodes.conf --cluster-announce-ip 10.240.79.9 --cluster-announce-port 7002 --cluster-announce-bus-port 17002
ports:
- "7002:6379"
- "17002:16379"
networks:
- redisnet
deploy:
placement:
constraints:
- node.hostname == host-10-240-79-9
redis003:
...
redis010:
...
networks:
redisnet:
数据保存文�g�?/home/redis/001/data
集群配置文�g���保存到 /home/redis/001/conf/nodes.conf
各机器上目录需要预先创建,不然docker开启失败�?br />�q�且需要设�|�目录权限,不然�?Permission denied".
redis-server以用户uid=100(redis)�q�行�Q�所�?br /> chown -R 100 /home/redis/
启动redis服务�?
docker stack deploy -c docker-stack.yml redis
redis-server启动后,�q�行 redis-trib.rb 来组�?redis cluster:
docker run --rm -it inem0o/redis-trib create --replicas 1 10.240.79.8:7001 10.240.79.9:7002 ... 10.240.79.12:7010
注意 inem0o/redis-trib 的说明中�Q�命令示例缺��?"-it", 会报错退出:
Can I set the above configuration? (type 'yes' to accept): : undefined method `chomp' for nil:NilClass (NoMethodError)
from /usr/bin/redis-trib:1295:in `create_cluster_cmd'
from /usr/bin/redis-trib:1701:in `<main>'
�q�行 redis-cli ���试�Q?-c" 参数表示集群�Q�可�q�接��L��机器�?001-7010��L��端口�Q?br />[root@host-10-240-79-9 ~]# docker run -it --rm redis:alpine redis-cli -h 10.240.79.8 -p 7006 -c
10.240.79.8:7006> get a
-> Redirected to slot [15495] located at 10.240.79.10:7003
(nil)
用swarm mode开启redis服务比较方便�?br />但是��Z��性能考虑�Q�应该禁�?swarm 的NAT转发和负载均衡�?br />研究了下�Q�暂时还没学会�?br />
]]>
(金庆的专�?
CentOS/RHEL yum 安装�?subversion �?1.6.11 版本�Q?br />�q�VisulaSVN服务器时会有"Key usage violation"�Q?br />
[jinq@jinqing-centos ~]$ svn co https://.../server
svn: OPTIONS of 'https://.../server': SSL handshake failed: SSL error: Key usage violation in certificate has been detected. (https://...)
subversion升��到最新版可解册���错误�?br />
Install Subversion 1.8.9 ( SVN Client ) on CentOS/RHEL
Thanks to Wandisco, which is maintaining the rpm packages for latest Subversion version.
( http://tecadmin.net/install-subversion-1-8-on-centos-rhel/ )
按指�C�����|�新的yum源,然后安装.
[jinq@jinqing-centos ~]$ svn --version
svn, version 1.8.13 (r1667537)
compiled Apr 2 2015, 15:55:22 on x86_64-unknown-linux-gnu
]]>
�Q�金庆的专栏�Q?br />
代码覆盖���试查看�l�果�Ӟ��需要进入代码所在目录,调用gcov�Q�然后vi查看�?br />
因�ؓ代码目录�l�构复杂�Q�进出子目录太麻烦,所以用以下脚本直接生成与查看�?br />
一般是用TSVN列出有更改的文�g�Q�将文�g列表复制到文本,然后复制其中的CPP文�g名作为参敎ͼ�在代码根目录下执行脚本�?br />
#!/bin/sh
# gcov.sh
# Usage: gcov.sh abc.sh
# Find file and cd to it, then call gcov and vim the result.
if [ $# -eq 0 ]
then
echo Usage: $0 SOURCE_FILE
echo Example: $0 abc.cpp
exit
fi
DIR=`find . -name $1.gcda -exec dirname {} \;`
cd ${DIR}
gcov $1.gcda
vim +/##### $1.gcov
说明�Q?br />find 在当前目录下查找文�g�?br />dirname 在查扄���果中获取目录�?br />cd �q�入目录
gcov 在该目录下执�?gcov
vim 打开gcov输出文�g�Q�参�?+/##### 用于查找 ##### �q�蟩到该行�?br /> ##### 是源代码未执行的标记�?br />
该脚本不能处理多个文件具有相同文件名的情��c�?br />
]]>
利用shell�I����句注释整�D�代�?br />
: << COMMENTBLOCK
shell脚本代码�D?br />COMMENTBLOCK
�q�个用来注释整段脚本代码�?: 是shell中的�I����句�?br />
]]>
gcov �l�计 inline 函数
�Q�金庆的专栏�Q?/p>
gcov可以�l�计 inline 函数�Q�可是实际��用中���到�l�计�ơ数��L���?的现象�?/p>
假设�c�A的头文�g�?A.h, 实现文�g�?A.cpp.
A 有几�?inline 成员函数定义�?A.h 中�?/p>
使用 gcov �l�计 A 的代码覆盖率�Ӟ��可能会发�?A.h 中的 inline 成员调用�ơ数为空�?�?/p>
除了���实未调用的原因�Q�可能是 gcov �l�计的对象错了�?/p>
"gcov A.cpp" �l�计的是 A.cpp 中实现的函数代码�Q�如�?A.cpp 中未调用自��n�?inline 函数�Q�统计结果确实�ؓ0�?/p>
只有到这�?inline 的调用方 cpp 文�g中去�l�计�Q�才会有惌���的结果�?/p>
例如�Q�B.cpp 中调用了 A �?inline 函数�Q?gcov B.cpp" 才会�l�计������?inline 代码.
参考:
Why the inline function can not be covered?
另外�Q�CMake 构徏�?o文�g命名不是 A.o, 而是 A.cpp.o, 所�?/p>
gcov A.cpp
会报 A.gcno 不存在�?/p>
实际文�g应该�?A.cpp.gcno.
把它复制�?A.gcno ���p��了�?/p>
或者用
gcov A.cpp.gcda
不知��Z��么,可以直接�?gcda 文�g作�ؓ输入�?/p>
或�?/p>
gcov -o A.cpp.o A.cpp
�q�样应该是标准的调用方式�?/p>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j='http://jakarta.apache.org/log4j/' debug="false">
<appender name="ROLLING" class="org.apache.log4j.RollingFileAppender">
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d %5p %c %x - %m%n"/>
</layout>
<param name="File" value="/var/log/4j/log_gsX.log"/>
<param name="MaxFileSize" value="50MB"/>
<param name="MaxBackupIndex" value="9"/>
</appender>
<appender name="DAILY_LUA" class="org.apache.log4j.DailyRollingFileAppender">
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d %5p %c %x - %m%n"/>
</layout>
<param name="File" value="/var/log/4j/log_gsX_lua.log"/>
<param name="DatePattern" value="'.'yyyy-MM-dd"/>
</appender>
<appender name="CONSOLE" class="org.apache.log4j.ConsoleAppender">
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d %5p %c %x - %m%n"/>
</layout>
<param name="Threshold" value="info"/>
</appender>
<appender name="ASYNC" class="org.apache.log4j.AsyncAppender">
<param name="BufferSize" value="100000"/>
<param name="Blocking" value="false"/>
<appender-ref ref="ROLLING"/>
<appender-ref ref="CONSOLE"/>
</appender>
<appender name="ASYNC_LUA" class="org.apache.log4j.AsyncAppender">
<param name="BufferSize" value="100000"/>
<param name="Blocking" value="false"/>
<appender-ref ref="DAILY_LUA"/>
</appender>
<root>
<level value="info"/>
<appender-ref ref="ASYNC" />
</root>
<logger name="Lua">
<level value="info"/>
<appender-ref ref="ASYNC_LUA" />
</logger>
<logger name="main">
<level value="info"/>
</logger>
<logger name="THSever">
<level value="debug"/>
</logger>
</log4j:configuration>
ASYNC异步输出到ROLLING和CONSOLE�?/p>
另外�Q�Lua日志异步输出为每天一个的独立日志�?/p>
默认仅输出INFO日志�Q�THServer日志�c�输出DEBUG日志�?/p>
CONSOLE屏蔽DEBUG日志�?/p>每个服务器��用相�c�M��的配�|�,仅输出文件名不同。可用如下Shell脚本生成各个配置文�g�Q?br />
do
sed 's/gsX/gs'${i}'/g' log4j_gsX.xml > log4j_gs${i}.xml
done
]]>
Linux下Debug版不会自动添�?_DEBUG宏,只有NDEBUG宏可用�?/p>
cmake ../src _DCMAKE_BUILD_TYPE=Debug -D_DEBUG
会报错: -D_DEBUG should be: VAR:type=value
需�?D_DEBUG=1.
改�ؓ在CMakeLists.txt中添加:
if (CMAKE_BUILD_TYPE STREQUAL Debug)
add_definitions(
-D_DEBUG
)
endif ()
]]>
Win7讉K��Redhat samba�׃�n
首先是开启samba:
service smb start
service smb restart
samba的配�|�文件是/ect/samba/smb.conf, 几乎不用改,使用默认配置���p��了�?/p>
默认是���?security=user 模式�׃�n�Q�需要输入用户名密码才能讉K���?/p>
默认有[homes]�׃�n配置�Q�各个用户可讉K��自己的主目录�?/p>
如添加新用户�Q?/p>
useradd jinqing
passwd jinqing
smbpasswd -a jinqing
smb需要自��q��用户密码�Q�需用smbpasswd讄����?/p>
�q�样���共享了/home/jinqing.
���试�Q�smbclient //localhost/jinqing -Ujinqing
需要设�|�Selinux参数�Q�以允许�׃�n讉K���Q�可参照smb.conf中的注释�q�行�Q?/p>
setsebool -P samba_enable_home_dirs on
然后是win7需要设�|�安全策略,不然也会�q�不上�?br />
打开���理工具�Q?#8220;本地�{�略”->“安全选项”->“�|�络安全�Q�LAN Manager �w�䆾验证�U�别”�Q?br />单击列表中:发送LM和NTLMv2�Q�如果已协商�Q�则使用NTLMv2协议�?br />
]]>
�Q�金庆的专栏�Q?/div>
用到gprof时才知道�Q�原来gprof只能对主�U�程�l�计耗时。manual上也没写�U�程相关的问题啊�Q?/p>
不过有现成的解决�Ҏ���Q�http://sam.zoy.org/writings/programming/gprof.html
该方案封装了pthread_create(), 让线�E�初始化执行一个setitimer(ITIMER_PROF, ...)�?/p>
���易的�Ҏ��是直接在代码中写个setitimer()�?/p>
- #include <sys/time.h>
- #include <boost/thread.hpp>
- struct itimerval g_itimer;
- void foo()
- {
- setitimer(ITIMER_PROF, &g_itimer, NULL);
- for (int i = 0; i < 10000000; i++)
- (void)i;
- }
- int main()
- {
- getitimer(ITIMER_PROF, &g_itimer);
- boost::thread t(&foo);
- t.join();
- return 0;
- }
g++ main.cpp -pg -lboost_thread
./a.out
gprof
�q�样���p���l�计出foo()的耗时了。没有setitimer()��׃��会有foo()的耗时�l�计�?/p>
]]>
未来的MySql 5.6.6 中,CMake选项中添加了gprof性能���试支持�Q�见�Q?br />
http://dev.mysql.com/doc/refman/5.6/en/source-configuration-options.html
ENABLE_GPROF Enable gprof (optimized Linux builds only) OFF 5.6.6
代码库中的CMakeLists.txt 摘录如下�Q?/p>
- OPTION(ENABLE_GCOV "Enable gcov (debug, Linux builds only)" OFF)
- IF (ENABLE_GCOV AND NOT WIN32 AND NOT APPLE)
- SET(CMAKE_CXX_FLAGS_DEBUG
- "${CMAKE_CXX_FLAGS_DEBUG} -fprofile-arcs -ftest-coverage")
- SET(CMAKE_C_FLAGS_DEBUG
- "${CMAKE_C_FLAGS_DEBUG} -fprofile-arcs -ftest-coverage")
- SET(CMAKE_EXE_LINKER_FLAGS_DEBUG
- "${CMAKE_EXE_LINKER_FLAGS_DEBUG} -fprofile-arcs -ftest-coverage -lgcov")
- ENDIF()
- OPTION(ENABLE_GPROF "Enable gprof (optimized, Linux builds only)" OFF)
- IF (ENABLE_GPROF AND NOT WIN32 AND NOT APPLE)
- SET(CMAKE_C_FLAGS_RELWITHDEBINFO
- "${CMAKE_C_FLAGS_RELWITHDEBINFO} -pg")
- SET(CMAKE_CXX_FLAGS_RELWITHDEBINFO
- "${CMAKE_CXX_FLAGS_RELWITHDEBINFO} -pg")
- SET(CMAKE_EXE_LINKER_FLAGS_RELWITHDEBINFO
- "${CMAKE_EXE_LINKER_FLAGS_RELWITHDEBINFO} -pg")
- ENDIF()
]]>
CMake��d��gcov代码覆盖���试支持
�Q�金庆的专栏�Q?/p>
在根CMakeList.txt中添加ENABLE_GCOV选项�Q?br />
OPTION(ENABLE_GCOV "Enable gcov (debug, Linux builds only)" OFF)
IF (ENABLE_GCOV AND NOT WIN32 AND NOT APPLE)SET(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} -fprofile-arcs -ftest-coverage")
SET(CMAKE_C_FLAGS_DEBUG "${CMAKE_C_FLAGS_DEBUG} -fprofile-arcs -ftest-coverage")
SET(CMAKE_EXE_LINKER_FLAGS_DEBUG "${CMAKE_EXE_LINKER_FLAGS_DEBUG} -fprofile-arcs -ftest-coverage -lgcov")
ENDIF()
以上代码来自MySQL的CMakeLists.txt.
如下执行cmake:
cmake SRC_DIR -DCMAKE_BUILD_TYPE=Debug -DENABLE_GCOV=1
�~�译后就可以看到图文�?*.gcno�?/p>
�q�行后,可以看到数据文�g*.gcda生成�?/p>执行 gcov main.cpp.gcno ���q���?main.cpp.gcov ���试�l�果�?/div>
摘自�Q?http://www.shnenglu.com/tx7do/archive/2010/08/19/124000.html
建立debug/release两目录,分别在其中执行cmake -DCMAKE_BUILD_TYPE=Debug�Q�或Release�Q�,需要编译不同版本时�q�入不同目录执行make卛_���Q?/p>
Debug版会使用参数-g�Q�Release版���?O3 –DNDEBUG
]]>
�Q�金庆的专栏�Q?br />
Linux重启后,发现不知怎么的MySQL无法本地�q�接�?br />
�l�果phpMyAdmin, Zentao都无法正常工作了�?br />
�q�程的连接用了TCP是正常的�Q�本地连接用了本地socket, 有问题�?br />
本地�q�行mysql客户端会报错�Q?br />Can’t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock’ (2)
重启mysql服务也报错:
# service mysql restart
MySQL server PID file could not be found!
Starting MySQL... ...The server quit without updating PID file (/var/lib/mysql/localhost/localdomain.pid)
�?pid文�g不存在。所以无法关闭mysql. 正在�q�行的mysql服务一直无法关闭�?br />
参考:http://zhujipi.com/vps/109.html
说明�Q�Mysql的进�E�卡��M���Q�这时用���p��把这些卡�ȝ���q�程都关闭�?br />
mysql服务重启成功后恢复正常�?br />
]]>
Starting httpd: httpd: Syntax error on line 57 of /usr/local/apache2/conf/httpd.conf: Cannot load /usr/local/apache2/modules/libphp5.so into server: /usr/local/apache2/modules/libphp5.so: undefined symbol: php_ini_scanned_files
�|�上搜烦的所有方法都没有解决�q�个错误�?/p>
最后make clean;make;make install���好了�?/p>
估计是需要make clean清除上次的错误才行�?/p>
]]>
�Q��{载请注明来源于金庆的专栏�Q?br>
为网�怸�王之�?(KOK3)服务器添加新功能的时�?
发现某个�c�L��员函数应该是const函数, 因�ؓ我的const函数要调用该函数,
��手���加上了const.
再顺便看到该�c�L��好多个明显是getter函数, 所以都加上了const.
�~�译没错���提交了.
�l�果没多久测试就发现了新版本的一个错�? 表现在其他功能上,
但由同事�U�错后发现是我添加const的后�?
原来��d��const的成员函��C��, 有一个是virtual函数, 加了const后与子类的函数原型就不符�?
子类的函数成为父�c�虚函数的一个重�? 使virtual失效, 多态性无法表现出�?
解决�Ҏ�����是子类的相应虚函数中也��d��const.
教训: 更改虚函数原型时, 必须同时更改父类和子�c?
gcc中有�?Woverloaded-virtual警告选项, 会报告这�U�虚函数重蝲.
我在Makefile中打开�?Woverloaded-virtual, 再次�~�译时就产生了许多警�?
大多数警告是正确的函数重�? 但还是发��C��一个与我相同的错误,
�q�次是函数参数const有区�? 我发�l�相关�h员处理了.
因�ؓ开�?Werror, 所有警告都会造成�~�译��p�|,
所以我们不能在Makefile中加�?Woverloaded-virtual警告选项.
代码�C�Z��:
class A
{
virtual void f() {};
};
class B : public A
{
virtual void f() const {};
};
int main()
{
return 0;
}
$ g++ main.cpp -Woverloaded-virtual
main.cpp:3: warning: `virtual void A::f()' was hidden
main.cpp:8: warning: by `virtual void B::f() const'
Google的代码规范中要求所有子�cȝ��虚函��C��都加上virtual, 是很有道理的.
虽然只要与父�c�虚函数�{��相同, 加不加virtual都是虚函�?
但是以后更改函数�{���? 看到virtual很容易知道它是虚函数, 需要父�c�d���c�d��时更�?
]]>
]]>
]]>