实现�Ҏ(gu��)���Q�在PHP讑֮�(configure)时加入如下选项�?
 --enable-shmop --enable-sysvsem
--enable-shmop --enable-sysvsem
�q�样��׃��得你的PHP�pȝ��可以处理相关的IPC函数了�?
IPC是什么?
IPC (Inter-process communication) 是一个Unix标准通讯机制�Q�它提供了��得在同一��C����Z��同进�E�之间可以互盔R��讯的方法。基本的IPC处理机制�?�U�:(x��)它们分别是共享内存、信号量和消息队列。本文中我们主要讨论�׃�n内存和信号量的��用。关于消息队列,�W�者在不久的将来还�?x��)专门介�l��?
在PHP中��用共享内存段
在不同的处理�q�程之间使用�׃�n内存是一个实��C��同进�E�之间相互通讯的好�Ҏ(gu��)��。如果你在一个进�E�中向所�׃�n的内存写入一�D�信息,那么所有其他的�q�程也可以看到这�D�被写入的数据。非常方�ѝ��在PHP中有了共享内存的帮助�Q�你可以实现不同�q�程在运行同一�D�PHP脚本时返回不同的�l�果。或实现对PHP同时�q�行数量的实时查询等�{��?
�׃�n内存允许两个或者多个进�E�共享一�l�定的存储区。因为数据不需要在客户机和服务器之间复�Ӟ��所以这是最快的一�U�IPC。��用共享内存的唯一�H�门是多个进�E�对一�l�定存储区的同步存取�?
如何建立一个共享内存段呢?下面的代码可以帮你徏立共享内存�?nbsp;
$shm_id = shmop_open($key, $mode, $perm, $size);
注意�Q�每个共享内存段都有一个唯一的ID, 在PHP中,shmop_open�?x��)把建立好的�׃�n内存�D늚�ID�q�回�Q�这里我们用$shm_id记录它。�?key是一个我们逻辑上表�C�共享内存段的Key倹{��不同进�E�只要选择同一个Key id���可以共享同一�D�存储段。习(f��n)惯上我们用一个串�Q�类似文件名一��L(f��ng)��东西�Q�的散列��g��为key id. $mode指明了共享内存段的��用方式。这里由于是新徏�Q�因此��gؓ(f��)’c’ –取create之意。如果你是访问已�l�徏立过的共享内存那么请�?#8217;a’,-- 取Access之意�?perm参数定义了访问的权限�Q?�q�制�Q�关于权限定义请看UNIX文�g�pȝ��帮助�?size定义了共享内存的大小。尽���有点象fopen(文�g处理)你可不要当它同文件处理一栗���后面的描述你将看到着一炏V�?
例如�Q?
$shm_id = shmop_open(0xff3, "c", 0644, 100);
�q�里我们打开了一个共享内存段 键�?xff3 –rw-r—r—格式,大小�?00字节�?
如果需要访问已有的�׃�n内存�D�,你必���d��调用shmop_open中设�W?�?个参��Cؓ(f��)0�?
IPC工作状态的查询
在Unix下,你可以用一个命令行�E�序ipcs查询�pȝ��所有的IPC资源状态。不�q�有些系�l�要求需要超�U�用��h��能执行。下图是一�D�ipcs的运行结果�?/p>
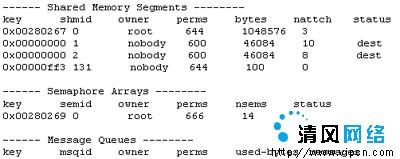
上图中系�l�显�C�Z��4个共享内存段�Q�注意其中第4个键��gؓ(f��)0x00000ff3的就是我们刚刚运行过的PHP�E�序所创徏的。关于ipcs的用法请参考UNIX用户手册�?
如何释放�׃�n内存�?
释放�׃�n内存的办法是调用PHP指��o(h��):shmop_delete($id)
shmop_delete($id);
$id ���是你调用shmop_open所存的shmop_op的返回倹{��还有一个办法就是用UNIX的管理指�?
ipcrm id, id���是你用ipcs看到的ID.和你�E�序中的$id不一栗���不�q�要���心�Q�如果你用ipcrm直接删除�׃�n内存�D�那么有可能��D��其他不知道这一情况的进�E�在引用�q�个已经不复存在的共享内存器时出��C��些不可预���的错误(往往�l�果不妙)�?
如何使用(��d��)�׃�n内存�?
使用如下所�C�函数向�׃�n内存写入数据
int shmop_write (int shmid, string data, int offset)
其中shmid是用shmop_open�q�回的句柄�?Data变量存放了要存放的数据�?offset描述了写入从�׃�n内存的开始第一个字节的位置�Q�以0开始)(j��)�?
��d��操作是:(x��)
string shmop_read (int shmid, int start, int count)
同样�Q�指�?shmid,开始偏�U�量�Q�以0开始)(j��)、总读取数量。返回结果串。这��P��你就可以把共享内存段当作是一个字节数�l�。读几个再写几个�Q�想�q�嘛���干嘛,十分方便�?
多进�E�问题的考虑
现在�Q�在单独的一个PHP�q�程中读写、创建、删除共享内存方面上你应该没有问题了。但是,昄���实际�q�行中不可能只是一个PHP�q�程在运行中。如果在多个�q�程的情况下你还是沿用单个进�E�的处理�Ҏ(gu��)���Q�你一定会(x��)���到问题 ---- 著名的�ƈ行和互斥问题。比如说�?个进�E�同旉���要对同一�D�内存进行读写。当两个�q�程同时执行写入操作�Ӟ��你将得到一个错误的数据�Q�因������D�内存将之可能是最后执行的�q�程的内容,甚至是由2个进�E�写入的数据轮流随机出现的一�D�|合的四不象。这昄���是不能接受的。�ؓ(f��)了解册���个问题,我们必须引入互斥机制。互斥机制在很多操作�pȝ��的教材上都有专门讲述�Q�这里不多重复。实��C��斥机制的最���单办法就是��用信��L(f��ng)��。信号量是另外一�U�进�E�间通讯(IPC)的方式,它同其他IPC机构(���道、FIFO、消息队�?不同。它是一个记数器�Q�用于控制多�q�程对共享数据的存储。同��L(f��ng)��是你可以用ipcs和ipcrm实现对信��L(f��ng)��使用状态的查询和对其实现删除操作。在PHP中你可以用下列函数创��Z��个新的信号量�q�返回操作该信号量的句柄。如果该key指向的信号量已经存在�Q�sem_get直接�q�回操作该信号量的句柄�?
int sem_get (int key [, int max_acquire [, int perm]])
$max_acquire 指明同时最多可以用几个�q�程�q�入该信可��(g��)�不必等待该信号被释放(也就是最大同时处理某一资源的进�E�数�?一般该值均��Z���Q��?perm指明了访问权限�?
一旦你成功的拥有了一个信号量�Q�你对它所能做的只�?�U�:(x��)��h��、释放。当你执行释放操作时, �pȝ�����把该信号值减一。如果小�?那就�q�设�?。而当你执行请求操作时�Q�系�l�将把该信号值加一�Q�如果该值大于设定的最大值那么系�l�将挂�v你的处理�q�程直到其他�q�程释放到小于最大��gؓ(f��)止。一般情况下最大��D���?,�q�样一来当一个进�E�获得请求时其他后面的进�E�只能等待它退��Z��斥区后释放信号量才能�q�入该互斥区�q�同时设为独占方式。这��L(f��ng)��信号量常�U�Cؓ(f��)双态信号量。当�?d��ng)���如果初值是��L��一个正数就表明有多���个�׃�n资源单位可供�׃�n应用�?
甌���、释放操作的PHP格式如下�Q?
int sem_acquire (int sem_identifier)
甌���
int sem_release (int sem_identifier)
释放
其中sem_identifier是调用sem_get的返回��|��句柄�Q��?nbsp;
一个简单的互斥协议例子
下面是一�D�很���单的互斥操作规程�?
$semid=sem_get(0xee3,1,0666); $shm_id = shmop_open(0xff3, "c", 0644, 100); sem_acquire($semid);�?nbsp;//甌��� /* �q�入临界�?/span>*/ /*�q�里�Q�对�׃�n内存�q�行处理 */sem_release($semid); �?/span>//释放
正如你所看到的,互斥的实现很���单:(x��)甌����q�入临界区,对��(f��)界区资源�q�行操作�Q�比如修改共享内存)(j��)退��Z��(f��)界区�q����放信受���这样一来就可以保证在同一个时间片中不可能有同�?个进�E�对同一�D�共享内存进行操作。因��Z��号量机制保证一个时间片只能�׃��个进�E�进入,其他�q�程必须�{�待当前处理的进�E�完成后方能�q�入�?
临界��Z��般是指那些不允许同时有多个进�E��ƈ发处理的代码�D�c(di��n)�?
要注意的�?在PHP中必��ȝ��同一个进�E�释攑֮�所占用的信号量。在一般系�l�中允许�q�程释放别的�q�程占用的信受���在�~�写临界��Z��码一定要���心设计资源的分配,避免A�{�B�Q�B�{�A的死锁情况发生�?nbsp;
�q��?/strong>
IPC的运用是十分�q�泛的。比如,在不同进�E�间保存一个解释过的复杂的配置文�g、或具体讄���的用��L(f��ng)���Q�以避免重复处理。我也曾�l�用�׃�n内存的技术把一大批PHP脚本必须引用的一个很大的文�g攑օ��׃�n内存�Q��ƈ由此显著提升了Web服务的速度、消除了部分瓉���。关于它的��用还有聊天室�Q�多路广播等�{�。IPC的威力取决于你的惌���力的大小。如果本文对你有一点点启发�Q�那我不胜荣�q�。愿意很你讨�����令�h入迷的电(sh��)脑技术。Email: qwyaxm@163.net
]]>
]]>
function smarty_modifier_truncate_cn($string, $length = 80, $code = 'UTF-8', $etc = ' ')
')2
{3
if ($length == 0)4
return '';5
if($code == 'UTF-8'){6
$pa = "/[\x01-\x7f]|[\xc2-\xdf][\x80-\xbf]|\xe0[\xa0-\xbf][\x80-\xbf]|[\xe1-\xef][\x80-\xbf][\x80-\xbf]|\xf0[\x90-\xbf][\x80-\xbf][\x80-\xbf]|[\xf1-\xf7][\x80-\xbf][\x80-\xbf][\x80-\xbf]/";7
}8
else{9
$pa = "/[\x01-\x7f]|[\xa1-\xff][\xa1-\xff]/";10
}11
preg_match_all($pa, $string, $t_string);12
if(count($t_string[0]) > $length)13
return join('', array_slice($t_string[0], 0, $length)).$etc;14
return join('', array_slice($t_string[0], 0, $length));15
}以下代码保存为ascii格式
<html>2
<head>3
<title>Truncate ���试</title>4
<meta http-equiv="Content-Type" content="text/html; charset=gbk" />5
</head>6
<body>7
{{$string}}<br>8
{{$string|truncate_cn:15:"":""}}<br>9
</body>10
</html>以下代码保存�?UTF-8格式
<html>2
<head>3
<title>Truncate ���试</title>4
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />5
</head>6
<body>7
{{$string}}<br>8
{{$string|truncate_cn:15:"UTF-8":""}}<br>9
</body>10
</html>]]>
]]>
]]>
]]>
]]>
3.4 串操�?/h3>
我们前面已经提到�Q�内存可以和寄存器交换数据,也可以被赋予立即数。问题是�Q�如果我们需要把内存的某部分内容复制到另一个地址�Q�又怎么做呢�Q?/p>
设想���DS:SI处的�q�箋512字节内容复制到ES:DI�Q�先不考虑可能的重叠)(j��)。也�怼�(x��)有�h写出�q�样的代码:(x��)
NextByte: | mov cx,512 mov al,ds:[si] mov es:[di],al inc si inc di loop NextByte | ; 循环�ơ数 |
我不喜欢上面的代码。它的确能达��C��用,但是�Q�效率不好。如果你是在做优化,那么写出�q�样的代码意味着赔了夫�h又折��c(di��n)�?/p>
Intel的CPU的强��Ҏ(gu��)��串操作。所谓串操作���是由CPU��d��成某一数量的、重复的内存操作。需要说明的是,我们常用的KMP���法�Q�用于匹配字�W�串中的模式�Q�的改进——Boyer���法�Q�由于没有利用串操作�Q�因此在Intel的CPU上的效率�q����最优。好的编译器往往可以利用Intel CPU的这一�Ҏ(gu��)��优化代码,然而,�q����所有的时候它都能产生最好的代码�?/p>
某些指��o(h��)可以加上REP前缀�Q�repeat, 反复之意�Q�,�q�些指��o(h��)通常被叫做串操作指��o(h��)�?/p>
举例来说�Q�STOSD指��o(h��)���EAX的内容保存到ES:DI�Q�同时在DI上加或减四。类似的�Q�STOSB和STOSW分别�?字节�?字的上述操作�Q�在DI上加或减的数�?�?�?/p>
计算������a�通常是不允许二义性的。�ؓ(f��)什么我要说“加或减”呢�Q�没错,孤立地看STOS?指��o(h��)�Q��ƈ不能知道到底是加�q�是减,因�ؓ(f��)�q�取决于“方向”标�?DF, Direction Flag)。如果DF被复位,则加�Q�反之则减�?/p>
�|�位、复位的指��o(h��)分别是STD和CLD�?/p>
当然�Q�REP只是几种可用前缀之一。常用的�q�包括REPNE�Q�这个前�~�通常被用来比较两个串�Q�或搜烦(ch��)某个特定字符�Q�字、双字)(j��)。REPZ、REPE、REPNZ也是非常常用的指令前�~��Q�分别代表ZF(Zero Flag)在不同状态时重复执行�?/p>
下面说三个可以复制数据的指��o(h��)�Q?/p>
| 助记�W?/font> | 意义 |
| movsb | ���DS:SI的一字节复制到ES:DI�Q�之后SI++、DI++ |
| movsw | ���DS:SI的一字节复制到ES:DI�Q�之后SI+=2、DI+=2 |
| movsd | ���DS:SI的一字节复制到ES:DI�Q�之后SI+=4、DI+=4 |
于是上面的程序改写�ؓ(f��)
| cld mov cx, 128 rep movsd | ; 复位DF ; 512/4 = 128�Q�共128个双�?br />; 行动�Q?/font> |
�W�一句cld很多时候是多余的,因�ؓ(f��)实际写程序时�Q�很���会(x��)出现�|�DF的情��c(di��n)��不�q�在正式军_��删掉它之前,�����你仔�l�地调试自己的程序,�q�确认每一个能够走到这里的路径中都不会(x��)���DF�|�位�?/p>
错误�Q�非预期的)(j��)的DF是危险的。它很可能断送掉你的�E�序�Q�因�����直接造成�~�冲区溢�?/b>问题�?/p>
什么是�~�冲区溢出呢�Q�缓冲区溢出分�ؓ(f��)两类�Q�一�c�L��写入�~�冲��Z��外的内容�Q�一�c�L����d���~�冲��Z��外的内容。后一�U�往往更隐蔽,但随便哪一个都有可能断送掉你的�E�序�?/p>
�~�冲区溢出对于一个网�l�服务来说很可能更加危险。怀有恶意的用户能够利用它执行自己希望的指��o(h��)。服务通常拥有更高的特权,而这很可能会(x��)造成�Ҏ(gu��)��提升�Q�即使不能提升攻击者拥有的�Ҏ(gu��)���Q�他也可以利用这�U�问题��服务崩溃�Q�从而�Ş成一�ơ成功的DoS�Q�拒�l�服务)(j��)��d��。每�q�CERT的安全公告中�Q�都�?成左右的问题是由于缓冲区溢出造成的�?/p>
在��用汇�~�语�a��Q�或C语言�~�写�E�序�Ӟ��很容易在无意中引入缓冲区溢出。然而�ƈ不是所有的语言都会(x��)引入�~�冲区溢出问题,Java和C#�Q�由于没有指针,�q�且�~�冲区采取动态分配的方式�Q�有效地消除了造成�~�冲区溢出的土壤�?/p>
汇编语言中,�׃��REP*前缀都用CX作�ؓ(f��)计数器,因此情况�?x��)好一些(当然�Q�有时也�?x��)更�p�糕�Q�因为由于CX的限�Ӟ��很可能��原本可能改变�E�序行�ؓ(f��)的缓冲区溢出的范围羃?y��u)��,从而更为隐蔽)(j��)。避免缓冲区溢出的一个主要方法就是仔�l�检查,�q�包括两斚w���Q�设�|�合理的�~�冲区大���,和根据大���编写程序。除此之外,非常重要的一点就是,在汇�~�语�a��q�个�U�别写程序,你肯定希望去掉所有的无用指��o(h��)�Q�然而再��L��之前�Q�一定要�q�行严格的测试;更进一步,如果能加上注释,�q����过善用宏来做调试模式检查,往往能够辑ֈ�更好的效果�?/p>
3.5 关于保护模式中内存操作的一点说�?/h3>
正如3.2节提到到的那��P��保护模式中,你可以���?2位的�U�性地址�Q�这意味着直接讉K��4GB的内存。由于这个原因,选择器不用像实模式中�D�寄存器那样频繁��C��攏V��顺便提一句,�q�䆾教程中所说的保护模式指的�?86以上的保护模式,或者,Microsoft通常�U�Cؓ(f��)“增强模式”的那种�?/p>
在�ؓ(f��)选择器装入数值的时候一定要非常���心。错误的数值往往�?x��)导致无效页面错�?在Windows中经常出�?)。同�Ӟ��也不要忘��C��的地址�?2位的�Q�这也是保护模式的主要优势之一�?/p>
现在假设存在一个描�q�符描述从物理的0:0开始的全部内存�Q��ƈ已经加蝲�q�DS(数据选择�?�Q�则我们可以通过下面的程序来操作VGA的VRAM�Q?/p>
| mov edi,0a0000h mov byte ptr [edi],0fh | ; VGA昑֭�的偏�U�量 ; ���第一字节改�ؓ(f��)0fh |
很明显,�q�比实模式下的程�?/p>
| mov ax,0a000h mov ds,ax mov di,0 mov [di],0fh | ; AX -> VGA�D�地址 ; ���AX��D��入DS ; DI清零 ; 修改�W�一字节 |
看上去要舒服一些�?/p>
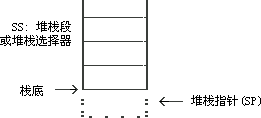
3.6 堆栈
到目前�ؓ(f��)止,�(zh��n)�已�l�了解了基本的寄存器以及(qi��ng)内存的操作知识。事实上�Q��?zh��n)�现在已经可以写出很多的底层数据处理程序了�?/p>
下面我来说说堆栈。堆栈实在不是一个让人陌生的数据�l�构�Q�它是一�?span class="tip" id="oFILO" title="">先进后出(FILO)�Q?b>先进后出(FILO)是这样一个概念:(x��)最�?/b>放进表中的数据在取出�?b>最�?/b>出来�?b>先进后出(FILO)�?b>先进先出(FIFO, 和先�q�后出的规则相反)�Q�以�?b>随机存取是最主要的三�U�存储器讉K��方式。对于堆栈而言�Q�最后放入的数据在取出时最先出现。对于子�E�序调用�Q�特别是递归调用来说�Q�这是一个非常有用的�Ҏ(gu��)��。)(j��)的线性表�Q�能够帮助你完成很多很好的工作�?/p>
一个铁杆的汇编语言�E�序员有时会(x��)发现�pȝ��提供的寄存器不够。很昄����Q�你可以使用普通的内存操作来完成这个工作,���像C/C++中所做的那样�?没错�Q�没错,可是�Q�如果数据段�Q�数据选择器)(j��)以及(qi��ng)偏移量发生变化怎么办?更进一步,如果希望保存某些在这�U�操作中可能受到影响的寄存器的时候怎么办?���实�Q�你可以把他们也存到自己的那片内存中�Q�自己实现堆栈�?/p>
太麻�?ch��)了…�?/p>
既然�pȝ��提供了堆栈,�q�且性能比自己写一份更好,那么��Z��么不直接加以利用呢?
�pȝ��堆栈不仅仅是一�D�内存。由于CPU对它实施���理�Q�因此你不需要考虑堆栈指针的修正问题。可以把寄存器内容,甚至一个立��x��直接攑ֈ�堆栈里,�q�在需要的时候将其取出。同�Ӟ���pȝ���q�不要求取出的数据仍然回到原来的位置�?/p>
除了昑ּ�地操作堆栈(使用PUSH和POP指��o(h��)�Q�之外,很多指��o(h��)也需要��用堆栈,如INT、CALL、LEAVE、RET、RETF、IRET�{�等。配对��用上�q�指令�ƈ不会(x��)造成什么问题,然而,如果你打�����用LEAVE、RET、RETF、IRET�q�样的指令实现蟩�?比JMP更�ؓ(f��)�ȝ��(ch��)�Q�然而有�Ӟ��例如在加密��Y件中�Q�或者需要修改调用者状态时�Q�这是必要的)的话�Q�那么我的徏议是�Q�先搞清楚它们做的到底是什么,�q�且�Q�精���地了解自己要做什么�?/p>
正如前面所说的�Q�有两个昑ּ�地操作堆栈的指��o(h��)�Q?/p>
| 助记�W?/font> | 功能 |
| PUSH | ���操作数存入堆栈�Q�同时修正堆栈指�?/td> |
| POP | ���栈��内容取出�ƈ存到目的操作��C���Q�同时修正堆栈指�?/td> |
我们现在来看看堆栈的操作�?/p>
执行之前
执行代码
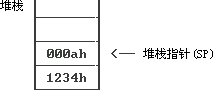
| mov ax,1234h mov bx,10 push ax push bx |
之后�Q�堆栈的状态�ؓ(f��)
之后�Q�再执行
| pop dx pop cx |
堆栈的状态成�?/p>
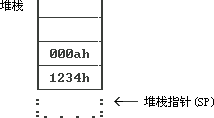
当然�Q�dx、cx中的内容���分别是000ah�?234h�?/p>
注意�Q�最后这张图中,我没有抹�?234h�?00ah�Q�因为POP指��o(h��)�q�不从内存中抹去数倹{��不�q�尽���如此,我个��Z��焉���常反对���l���用这两个敎ͼ�你可以通过修改SP来再�ơPOP它们�Q�,然而这很容易导致错误�?/p>
一定要保证堆栈�D�|�����_��的空间来执行中断�Q�以�?qi��ng)其他一些隐式的堆栈操作。仅仅统计PUSH的数量�ƈ据此计算堆栈所需的大���很可能造成问题�?/p>
CALL指��o(h��)���返回地址攑ֈ�堆栈中。绝大多数C/C++�~�译器提供了“堆栈检查”这个编译选项�Q�其作用在于保证C�E�序�D�中没有忘记对堆栈中多余的数据进行清理,从而保证返回地址有效�?/p>
本章���结
本章中介�l�了内存的操作的一些入门知识。限于篇�q�,我不打算展开�l�讲指��o(h��)�Q�如cmps*�Q�lods*�Q�stos*�Q�等�{�。这些指令的用法和前面介�l�的movs*基本一��P��只是有不同的作用而已�?/p>