2、較差的GPU渲染速度的低下不影響邏輯速度
第一個(gè)目標(biāo)已經(jīng)很明確了,我來解釋下需要達(dá)到第二個(gè)目標(biāo)的原因:許多動(dòng)作游戲的邏輯判定是基于幀的,所以在渲染較慢的情況下,邏輯不能跳幀,而仍然需要嚴(yán)格執(zhí)行才能保證游戲邏輯的正確性,這就導(dǎo)致了游戲速度的放慢,而實(shí)際上個(gè)人認(rèn)為渲染保持15幀以上就已經(jīng)可以正常進(jìn)行游戲了。
在較差的GPU上跑《鬼泣4》《刺客信條》《波斯王子4》簡直就像是慢鏡頭一樣,完全沒法玩。而實(shí)際上CPU跑滿幀是沒有問題的,如果能把邏輯幀和渲染幀徹底分離,即使渲染幀達(dá)不到要求,但CPU仍能正確的執(zhí)行游戲邏輯,就可以解決動(dòng)作游戲?qū)PU要求過高的問題。
我們先來看多線程Ogre的兩種架構(gòu),第一種是middle-level multithread
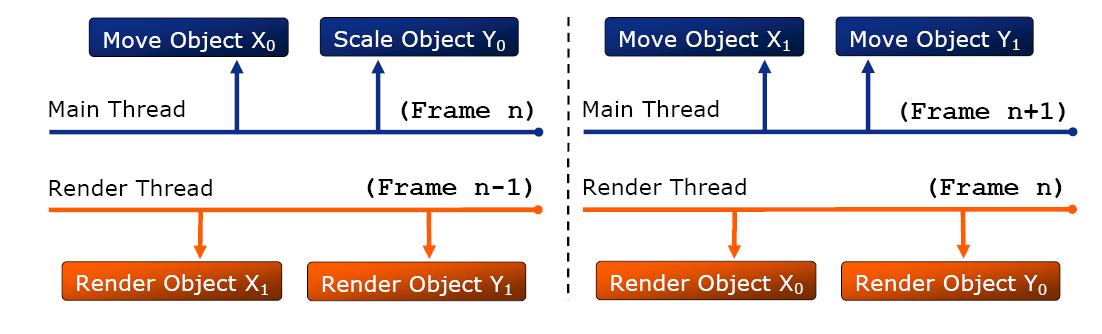
如上圖所示,每個(gè)需渲染的實(shí)體被復(fù)制成了兩份,主線程和渲染線程交替更新和渲染同一個(gè)實(shí)體的兩個(gè)備份,并在一幀結(jié)束時(shí)同步,這種解決方案達(dá)到了第一個(gè)目標(biāo)而并沒有達(dá)到第二個(gè)目標(biāo),同時(shí)兩份實(shí)體的維護(hù)也相對復(fù)雜,并且沒法為更多核數(shù)的CPU進(jìn)行擴(kuò)展優(yōu)化。
第二種Ogre多線程的方法是 low-level multithread
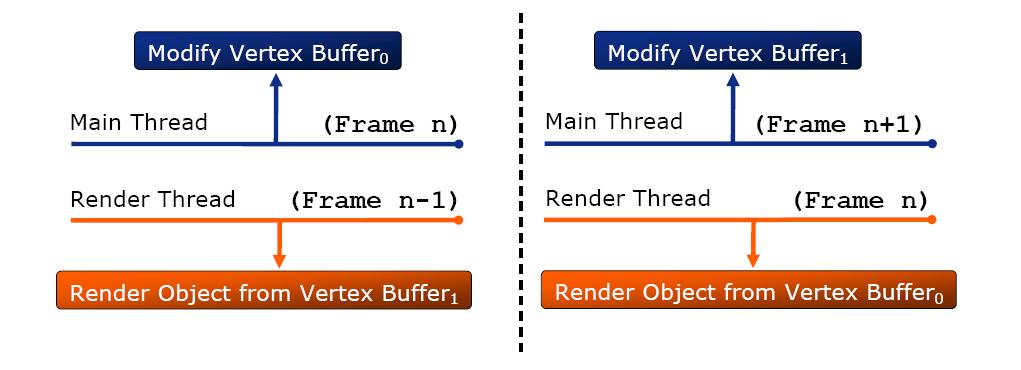
如圖,將D3D對象復(fù)制兩份,同樣是在幀結(jié)束時(shí)同步并交換,和上面的優(yōu)缺點(diǎn)類似。兩種多線程Ogre的解決方案都是在引擎層完成的,對上層應(yīng)用透明,對于用戶而言無需考慮多線程細(xì)節(jié),這點(diǎn)是非常不錯(cuò)的。
接下來我們來看SIGGRAPH2008上,id soft提出的多線程3D引擎的方案
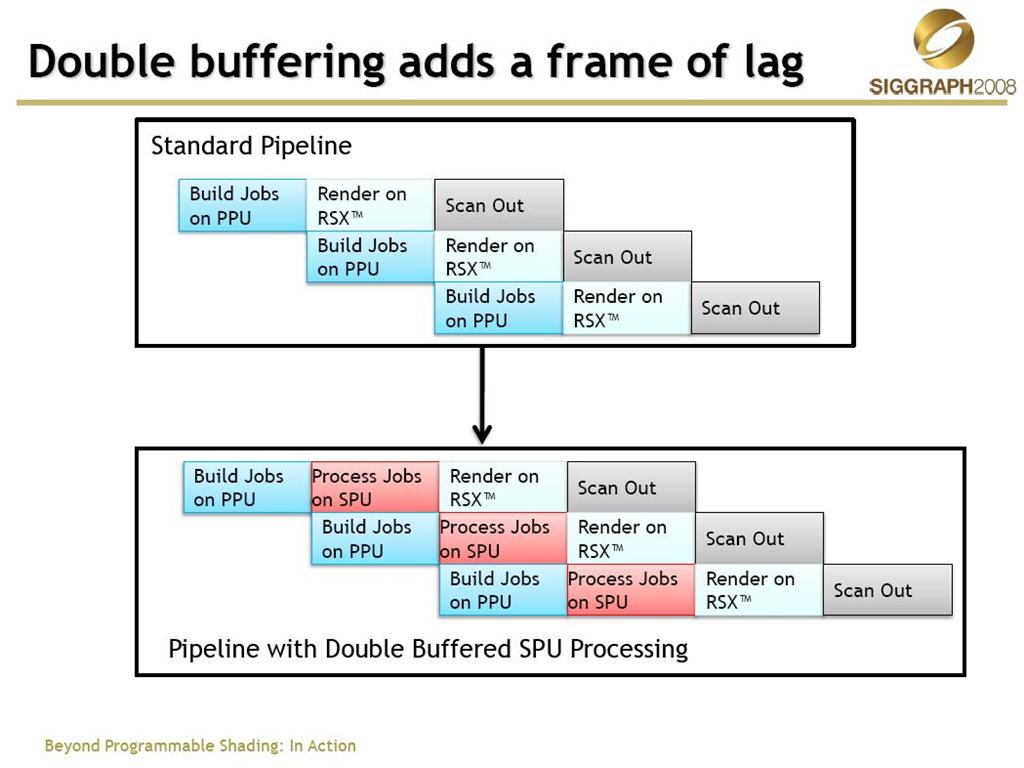
這里是已PS3的引擎結(jié)構(gòu)為例的,與PC有較大的差別,其中SPU是Cell芯片的8個(gè)協(xié)處理器,擁有強(qiáng)大的并行能力,id的解決方案在SPU上進(jìn)行了諸如骨骼動(dòng)畫、形變動(dòng)畫、頂點(diǎn)和索引緩存的壓縮、Progressive Mesh的計(jì)算等諸多內(nèi)容,同時(shí)與PPU上的物理計(jì)算RSX上的渲染工作交錯(cuò)進(jìn)行,最大化的利用了PS3的硬件結(jié)構(gòu),最終的游戲產(chǎn)品《Rage》很快就會面世了!
最后是我的解決方案
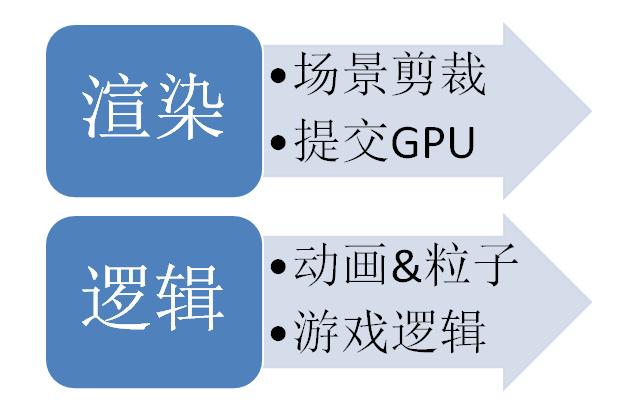
特點(diǎn)是邏輯完全分離,無需同步,雖然成功的達(dá)到了文章開始提出的兩個(gè)目標(biāo),但對于引擎的使用者必須考慮多線程的諸多問題,各種計(jì)算需放在哪個(gè)線程,如何在兩個(gè)線程間交互,都需要深入思考,所以要應(yīng)用到實(shí)際的游戲制作,恐怕還有很長的一段路要走。
結(jié)合目前的架構(gòu)和上面看到的幾種多線程架構(gòu),同時(shí)也為了迎接DX11的到來,我準(zhǔn)備將我的方案進(jìn)一步改進(jìn)成如下所示
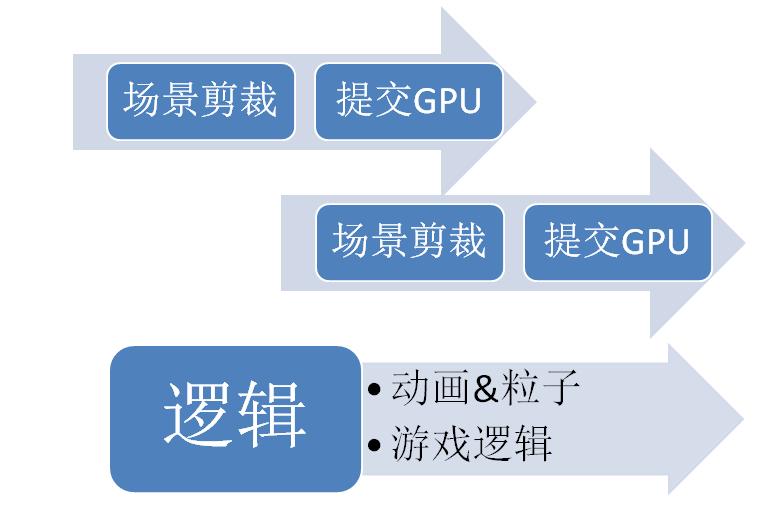
場景剪裁與提交渲染交替進(jìn)行,并在渲染幀末進(jìn)行一次同步,而多個(gè)渲染表面的場景剪裁可再并行執(zhí)行。
圖片多,文字少,需更詳細(xì)資料請自行g(shù)oogle,本文就此結(jié)束!
]]>
但實(shí)踐后發(fā)現(xiàn),陰影和光照會隨著骨骼動(dòng)畫的播放而閃爍,甚至鏡頭的移動(dòng)也會造成閃爍,究其原因,還是邏輯線程和渲染線程的同步問題,由于對場景內(nèi)的同一個(gè)物體渲染了多次,而邏輯線程又在不停的更新攝像機(jī)和骨骼動(dòng)畫數(shù)據(jù),導(dǎo)致了兩Pass渲染取到的數(shù)據(jù)很可能不一致,造成了光照和陰影的閃爍。
所以共享數(shù)據(jù)結(jié)構(gòu)必須做一些修改,在多Pass渲染開始前進(jìn)行一次備份,渲染中只取備份數(shù)據(jù),這樣就保證了多次渲染的數(shù)據(jù)一致性了
也就是加這么兩個(gè)簡單的set和get方法,在渲染相關(guān)數(shù)據(jù)讀取時(shí)調(diào)用get,邏輯相關(guān)時(shí)調(diào)用read
 template <class T>struct SharedData
template <class T>struct SharedData
 {
{ T m_pData[DATACENTER_CACHE]; T m_kCloneData; int m_iIndex; SharedData()
T m_pData[DATACENTER_CACHE]; T m_kCloneData; int m_iIndex; SharedData()
 { ZeroMemory( m_pData, DATACENTER_CACHE * sizeof(T) ); m_iIndex = 0;
{ ZeroMemory( m_pData, DATACENTER_CACHE * sizeof(T) ); m_iIndex = 0; } void Write( T& rData ) { int iNewIndex = m_iIndex == DATACENTER_CACHE - 1 ? 0 : m_iIndex + 1; m_pData[iNewIndex] = rData; m_iIndex = iNewIndex; } T& Read() { return m_pVector[m_iIndex]; } void Set() { m_kCloneData = Read(); } T& Get() { return m_kCloneData; }
} void Write( T& rData ) { int iNewIndex = m_iIndex == DATACENTER_CACHE - 1 ? 0 : m_iIndex + 1; m_pData[iNewIndex] = rData; m_iIndex = iNewIndex; } T& Read() { return m_pVector[m_iIndex]; } void Set() { m_kCloneData = Read(); } T& Get() { return m_kCloneData; } };
};
]]>
一、SM5.0 從類C變成類C++了,有類有繼承有虛函數(shù),太夸張了。。。
二、支持Shader動(dòng)態(tài)Link,DX9里面就有個(gè)FragmentLinker,不太好用,DX10直接取消了,這次變本加厲的又回來了!
三、渲染的多線程支持,我重點(diǎn)來談?wù)勥@個(gè)
DX11提供了一個(gè)新的接口:ID3D11DeviceContext,取代了以前Device接口所有與渲染相關(guān)的功能,有兩個(gè)類型:immediate和deferred,前者和現(xiàn)在的效果一樣,收到渲染指令就立即執(zhí)行,而后者則會將命令緩存起來,由用戶決定何時(shí)執(zhí)行。
在例子MultithreadedRendering11中,渲染了三面帶反射的鏡子和一個(gè)人物模型,Sample創(chuàng)建了四個(gè)Context,三個(gè)deferred用于鏡子反射表面的渲染,一個(gè)immediate用于最終場景,Sample創(chuàng)建了三個(gè)線程,渲染幀開始時(shí),首先并行的執(zhí)行三個(gè)鏡子反射的渲染,完成后,在主線程順序執(zhí)行三個(gè)Context,然后用immediate的Context渲染最終場景。
由這個(gè)例子,我們來展望一下美好的未來:所有的渲染表面都可以并行執(zhí)行,比如水面、鏡子、甚至ShadowMap,并行的進(jìn)行場景剪裁,使得多核CPU的使用更有效率。
DX11預(yù)計(jì)在今年年底推出,于Windows7捆綁,到那時(shí),四核CPU應(yīng)該已經(jīng)普及了吧。。。
]]>
刪除也是一樣,邏輯線程向渲染線程發(fā)送WM_DELETEENTITY消息,并不再使用該Entity指針,渲染對象則處理改消息,將此Entity從場景中刪除并卸載資源。
這里有一個(gè)非常危險(xiǎn)的情況,前面一篇提到,資源加載也是通過消息傳遞實(shí)現(xiàn)的,同樣是傳遞的資源指針,如果邏輯線程添加了一個(gè)Entity,還沒加載就刪掉了它,則資源加載線程會拿到一個(gè)過期指針,一切就結(jié)束了。。。
解決這一問題,最穩(wěn)妥的方法是消息的wParam并不傳遞指針,而是傳遞該Entity或資源的唯一ID,這樣的話即使ID過期,也可輕松忽略掉這條消息,壞處是每次消息處理都的從全局的map里檢查是否存在此ID對應(yīng)的Entity或資源,這可是筆不小的開銷。
第二種方案,我們?nèi)匀粋鬟f指針,只是在接受到WM_DELETEENTITY消息時(shí),檢查該Entity是否已經(jīng)加載完成,如果沒有完成,則重新將此消息加入消息隊(duì)列,下個(gè)渲染幀再次判斷。
FlagshipEngine的多線程設(shè)計(jì)大致就是如此了。
]]>
然后,主線程是邏輯線程還是渲染線程?因?yàn)檫壿嬀€程需要處理鍵盤鼠標(biāo)等輸入設(shè)備的消息,所以我起初將邏輯線程設(shè)為主線程,而渲染線程另外創(chuàng)建,但實(shí)際發(fā)現(xiàn),幀數(shù)很不正常,估計(jì)與WM_PAINT消息有關(guān),有待進(jìn)一步驗(yàn)證。于是掉轉(zhuǎn)過來,幀數(shù)正常了,但帶來了一個(gè)新的問題,邏輯線程如何處理鍵盤鼠標(biāo)消息?
對于第一個(gè)問題,有兩種解決方案:
第一,我們可以創(chuàng)建一個(gè)Event,資源讀取線程使用WaitForSingleObject等待著個(gè)Event,當(dāng)渲染線程向加載隊(duì)列添加新的需加載的資源后,將這個(gè)Event設(shè)為Signal,將資源讀取線程喚醒,為了安全,我們?nèi)孕枰阡秩揪€程向加載隊(duì)列添加元素,以及資源加載線程從加載隊(duì)列讀取元素時(shí)對操作過程加鎖。
第二,使用在渲染線程調(diào)用PostThreadMessage,將資源加載的請求以消息的形式發(fā)送到資源價(jià)值線程,并在wParam中傳遞該資源對象的指針,資源加載線程調(diào)用WaitMessage進(jìn)行等待,收到消息后即被喚醒,這種解決方案完全不需要加鎖。
對于第二個(gè)問題,我們同樣可以用PostThreadMessage來解決,在主線程的WndProc中,將邏輯線程需要處理的消息發(fā)送出去,邏輯線程收到后進(jìn)行相關(guān)處理。
需要注意的是,我們必須搞清楚線程是在何時(shí)創(chuàng)建消息隊(duì)列的,微軟如是說:
The thread to which the message is posted must have created a message queue, or else the call to PostThreadMessage fails. Use one of the following methods to handle this situation.
- Call PostThreadMessage. If it fails, call the
- Create an event object, then create the thread. Use the
PeekMessage(&msg, NULL, WM_USER, WM_USER, PM_NOREMOVE)
Set the event, to indicate that the thread is ready to receive posted messages.
看來,我們只需要在線程初始化時(shí)調(diào)一句PeekMessage(&msg, NULL, WM_USER, WM_USER, PM_NOREMOVE)就可以了,然后在主線程中如此這般:
switch ( uMsg )  { case WM_PAINT: { hdc = BeginPaint(hWnd, &ps); EndPaint(hWnd, &ps); } break; case WM_DESTROY: { m_pLogic->StopThread(); WaitForSingleObject( m_pLogic->GetThreadHandle(), INFINITE ); PostQuitMessage(0); } break; default: { if ( IsLogicMsg( uMsg ) ) { PostThreadMessage( m_pLogic->GetThreadID(), uMsg, wParam, lParam ); } else { return DefWindowProc( hWnd, uMsg, wParam, lParam ); } } break; }
{ case WM_PAINT: { hdc = BeginPaint(hWnd, &ps); EndPaint(hWnd, &ps); } break; case WM_DESTROY: { m_pLogic->StopThread(); WaitForSingleObject( m_pLogic->GetThreadHandle(), INFINITE ); PostQuitMessage(0); } break; default: { if ( IsLogicMsg( uMsg ) ) { PostThreadMessage( m_pLogic->GetThreadID(), uMsg, wParam, lParam ); } else { return DefWindowProc( hWnd, uMsg, wParam, lParam ); } } break; }在邏輯線程中這般如此:
MSG msg; while ( m_bRunning ) { if ( PeekMessage( &msg, NULL, 0, 0, PM_NOREMOVE ) ) { if ( ! GetMessageW( &msg, NULL, 0, 0 ) ) { return (int) msg.wParam; } MessageProc( msg.message, msg.wParam, msg.lParam ); } LogicTick(); }]]>
我們首先來分析下這兩個(gè)線程分別需要做什么工作,需要那些數(shù)據(jù)。渲染線程需要獲取實(shí)體的位置、材質(zhì)等信息,并交給GPU渲染,邏輯線程需要更新實(shí)體的位置、材質(zhì)、骨骼動(dòng)畫等數(shù)據(jù),很顯然一個(gè)寫入一個(gè)讀取,這為我們實(shí)現(xiàn)一個(gè)沒有線程同步的多線程3D渲染系統(tǒng)提供了可能。
為了讓讀取和寫入不需要Lock,我們需要為每一份數(shù)據(jù)設(shè)計(jì)一個(gè)帶有冗余緩存的結(jié)構(gòu),讀取線程讀取的是上次寫入完成的副本,而寫入線程則向新的副本寫入數(shù)據(jù),并在完成后置上最新標(biāo)記,置標(biāo)記的操作為原子操作即可。以Vector為例,這個(gè)結(jié)構(gòu)大致是這樣的:
struct VectorData { Vector4f m_pVector[DATACENTER_CACHE]; int m_iIndex; VectorData() { memset( m_pVector, 0, DATACENTER_CACHE * sizeof(Vector4f) ); m_iIndex = 0; } void Write( Vector4f& rVector ) { int iNewIndex = m_iIndex == DATACENTER_CACHE - 1 ? 0 : m_iIndex + 1; m_pVector[iNewIndex] = rVector; m_iIndex = iNewIndex; } Vector4f& Read() { return m_pVector[m_iIndex]; }};SharedData<Matrix4f> m_matWorld;
在渲染線程中調(diào)用pDevice->SetWorldMatrix( m_matWorld.Read() );
在邏輯線程中調(diào)用m_matWorld.Write( matNewWorld );
需要注意的是,這種方案并非絕對健壯,當(dāng)渲染線程極慢且邏輯線程極快的情況下,有可能寫入了超過了DATACENTER_CACHE次,而讀取卻尚未完成,那么數(shù)據(jù)就亂套了,當(dāng)然真要出現(xiàn)了這種情況,游戲早已經(jīng)是沒法玩了,我測試的結(jié)果是渲染幀小于1幀,邏輯幀大于10000幀,尚未出現(xiàn)問題。
FlagshipEngine采用了這一設(shè)想,實(shí)際Demo測試結(jié)果是,計(jì)算25個(gè)角色的骨骼動(dòng)畫,從靜止到開始奔跑,單線程的情況下,幀數(shù)下降了20%~30%,而使用多線程的情況下,幀數(shù)完全沒有變化!
]]>
首先我們需要定義一個(gè)Resource基類,它大致上是這樣的:
class _DLL_Export Resource : public Base { public: Resource(); virtual ~Resource(); // 是否過期 bool IsOutOfDate(); public: // 是否就緒 virtual bool IsReady(); // 讀取資源 virtual bool Load(); // 釋放資源 virtual bool Release(); // 緩存資源 virtual bool Cache(); // 釋放緩存 virtual void UnCache(); protected: // 加載標(biāo)記 bool m_bLoad; // 完成標(biāo)記 bool m_bReady; private: };卸載方面,在加載新的單元同時(shí),卸載身后舊的單元,對單元內(nèi)所有資源調(diào)用Release,Load/Release帶有引用計(jì)數(shù),仍被引用的資源不會被卸載。當(dāng)某一資源長時(shí)間沒有被看見,則超時(shí),調(diào)用UnCache釋放VertexBuffer等資源。
為了實(shí)現(xiàn)超時(shí)卸載功能,我們需要一個(gè)ResourceManager類,每幀檢查幾個(gè)已Cache的資源,看起是否超時(shí),另外也需對已加載的資源進(jìn)行分類管理,注冊其資源別名(可以為其文件名),提供查找資源的接口。
另外為了方便使用,我們需要一個(gè)模板句柄類ResHandle<T>,設(shè)置該資源的別名,其內(nèi)部調(diào)用ResourceManange的查找方法,看此資源是否已存在,如不存在則new一個(gè)新的,GetImpliment則返回該資源對象,之后可以將該資源添加到實(shí)體中,而無需關(guān)心其是否已被加載,代碼如下:
template <class T> class _DLL_Export ResHandle { public: ResHandle() { m_pResource = NULL; } virtual ~ResHandle() {} // 設(shè)置資源路徑 void SetPath( wstring szPath ) { Resource * pResource = ResourceManager::GetSingleton()->GetResource( Key( szPath ) ); if ( pResource != NULL ) { m_pResource = (T *) pResource; } else { m_pResource = new T; m_pResource->SetPath( szPath ); ResourceManager::GetSingleton()->AddResource( m_pResource ); } } // 模板實(shí)體類指針 T * GetImpliment() { return (T *) m_pResource; } T * operator-> () { return (T *) m_pResource; } protected: // 模板實(shí)體類指針 Resource * m_pResource; private: };]]>
一、多線程
多核CPU早已普及,但3D引擎卻遲遲不能享受到其好處,還僅僅停留在資源異步加載,音頻獨(dú)立線程等不疼不癢的應(yīng)用,就在一年前吧,公司的牛人們?yōu)榱藘?yōu)化骨骼動(dòng)畫和粒子計(jì)算煞費(fèi)苦心,這兩樣計(jì)算,特別是在無法控制同屏資源的網(wǎng)絡(luò)游戲中,對CPU資源的占用非常可觀,自然也拖累了游戲幀數(shù),于是我便有了將邏輯計(jì)算與渲染分離的想法。
FlagshipEngine實(shí)現(xiàn)了一套沒有線程同步的雙線程結(jié)構(gòu),可以做到骨骼動(dòng)畫、粒子計(jì)算、光源移動(dòng)等邏輯計(jì)算分離到一個(gè)單獨(dú)的線程運(yùn)行,完全不影響渲染幀數(shù)。
二、shader渲染器
DX10已經(jīng)放棄了固定管線,那么我們也沒理由再留戀它,完全基于shader的渲染器實(shí)現(xiàn)起來更加清晰簡潔,并且易于擴(kuò)展,目前FlagshipEngine已經(jīng)實(shí)現(xiàn)了DX9和DX10兩個(gè)渲染器,可以方便的添加特效。
三、統(tǒng)一剪裁
場景組織和剪裁永遠(yuǎn)是3D引擎的核心功能,視錐、四叉樹、BSP、Portal如何選擇,如何統(tǒng)一是個(gè)難題,我的做法是將所有的剪裁都抽象成剪裁面,并用壓棧和出棧的方式,遞歸的對場景進(jìn)行剪裁,另外我們還可以對大塊實(shí)體綁定簡單模型的遮擋體,使用邊緣檢測算法生成遮擋剪裁面,實(shí)現(xiàn)遮擋剪裁。
這套機(jī)制還沒有經(jīng)過嚴(yán)格的測試,有待進(jìn)一步的驗(yàn)證。
就這么多了,希望它有朝一日能修成正果,阿門。。。
]]>