|
|
2012年8月22日
Sierpinski三角形

楊輝三角,二項(xiàng)式系數(shù)奇偶性的判定 C(k,n)| k&n==k , 或者比較n!與{k!,(n-k)!}中2的個(gè)數(shù)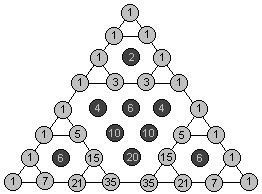
2012年4月13日
摘要: Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->#include <iostream>#include <math.h>using namespace std;const int... 閱讀全文
 #include <iostream> #include <iostream>
using namespace std;
const int MAXN=50*10005;
const int MAXL=1005;
const int K=26;
struct Node
   { {
 Node *next[K], *fail; Node *next[K], *fail;
int flag, id;
void Init(int index)
  { {
id=index;
flag=0;
fail=NULL;
for(int i=0; i<K; i++)next[i]=NULL;
 } }
 }* Q[MAXN/2], *root, T[MAXN];// Q for queue, root&T for tree; }* Q[MAXN/2], *root, T[MAXN];// Q for queue, root&T for tree;
int index=0;
Node * newNode()
{
T[index].Init(index);
return &T[index++];
}
int tokind(char k){return k-'a';}
void insert(char *str)
{
if(root==NULL)
root=newNode();
Node *now=root;
for(int i=0; str[i]; i++)
{
int kind=tokind(str[i]);
if(now->next[kind]==NULL)
now->next[kind]=newNode();
now=now->next[kind];
}
now->flag++;
}
void buildAC()
{
int head=0, tail=0;
root->fail=NULL;
Q[tail++]=root;
while(head<tail)
{
Node *now=Q[head++];
for(int i=0; i<K; i++)
{
if(now->next[i]!=NULL)
{
if(now==root)now->next[i]->fail=root;
else
{
Node *p=now->fail;
while(p->next[i]==NULL&&p!=root)p=p->fail;
p=p->next[i];
now->next[i]->fail=(p==NULL)?root:p;
}
Q[tail++]=now->next[i];
}
}
}
}
int query(char *str)
{
int res=0;
Node *p=root;
for(int i=0; str[i]; i++)
{
int kind=tokind(str[i]);
while(p->next[kind]==NULL&&p!=root)p=p->fail;
p=p->next[kind];
p=(p==NULL)?root:p;
Node *now=p;
while(now!=root&&now->flag!=-1)
{
res+=now->flag;
now->flag=-1;
now=now->fail;
}
}
return res;
}
int main()
{
//freopen ("in.txt", "r", stdin);
int T;
scanf("%d", &T);
while(T--)
{
int n;
root=NULL;
scanf("%d",&n);getchar();
while(n--)
{
char str[55];
scanf("%s",str);
insert(str);
}
buildAC();
char ch[1000005];
scanf("%s",ch);
printf("%d\n",query(ch));
}
return 0;
}
2012年4月9日
1#include <iostream>
2#include <vector>
3#include <string>
4using namespace std;
5
6#define madd(a,b) a=(a+b)%MOD
7
8const int MOD=1000000007;
9const int MAXC=55, MAXH=75, MAXW=10, MAXB=15;
10long g[MAXC], Comb[MAXC][MAXC];
11int dp[MAXW][MAXB][MAXC][MAXH][MAXW][2];
12
13class SkewedPerspective
14{
15
16public:
17 int countThem(vector <int> cubes, int B, int w)
18 {
19 int n=cubes.size(), total=0;
20 int i, j, k;
21 for(i=0; i<n; i++) total+=cubes[i];
22
23 for(i=0; i<=total; i++)
24 for(j=0; j<=i; j++)
25 Comb[i][j]=(j?(Comb[i-1][j]+Comb[i-1][j-1])%MOD:1);
26 g[0]=1;
27 for(i=0; i<n; i++)
28 for(j=total; j; j--)
29 for(k=1; k<=j && k<=cubes[i]; k++)
30 g[j]=(g[j]+g[j-k]*Comb[j][k])%MOD;
31
32 long ans=0;
33 dp[1][0][0][0][0][0]=1;
34 for(int tower=1; tower<=w; tower++)for(int black=0; black<=B; black++)
35 for(int color=0; color<=total; color++)for(int need=0; need<=total+black*2; need++)
36 for(int needOdd=0; needOdd<=tower; needOdd++)for(int lastBlack=0; lastBlack<2; lastBlack++)
37 {
38 int x=dp[tower][black][color][need][needOdd][lastBlack];
39 if(!x)continue;
40 //get result
41 if(black+color>0 && (B-black)*2+total-color>=need && total-color>=needOdd)
42 ans=(ans+g[color]*x)%MOD;
43 //put colored
44 madd(dp[tower][black][color+1][need][needOdd][0], x);
45 if(lastBlack) continue;
46 //put black
47 int layer=black*2+color-(tower-1);
48 for(int blackSize=1; blackSize+black*2<=B*2; blackSize++)
49 if(blackSize%2==0)
50 madd(dp[tower][black+blackSize/2][color][need][needOdd][1], x);
51 else
52 {
53 if(!layer && blackSize==1) continue; //"b1bbbb"
54 int needNow=(layer?layer-1:layer+1);
55 if(need+needNow<=total+B*2)
56 madd(dp[tower+1][black+(blackSize+1)/2][color][need+needNow][needOdd+needNow%2][1], x);
57 }
58
59 }
60 return int(ans);
61 }
62};
63
64int main()
65{
66 SkewedPerspective a;
67 int cubes[]={1, 1, 0};
68 vector<int> t(cubes, cubes+3);
69
70 cout<<a.countThem(t, 1, 2)<<endl;
71 return 0;
72}
73
2011年5月21日
轉(zhuǎn)載自:http://www.iteye.com/topic/398782
很久很久以前,有一群人,他們決定用8個(gè)可以開(kāi)合的晶體管來(lái)組合成不同的狀態(tài),以表示世界上的萬(wàn)物。他們看到8個(gè)開(kāi)關(guān)狀態(tài)是好的,于是他們把這稱為"字節(jié)"。
再后來(lái),他們又做了一些可以處理這些字節(jié)的機(jī)器,機(jī)器開(kāi)動(dòng)了,可以用字節(jié)來(lái)組合出很多狀態(tài),狀態(tài)開(kāi)始變來(lái)變?nèi)ァK麄兛吹竭@樣是好的,于是它們就這機(jī)器稱為"計(jì)算機(jī)"。
開(kāi)始計(jì)算機(jī)只在美國(guó)用。八位的字節(jié)一共可以組合出256(2的8次方)種不同的狀態(tài)。
他們把其中的編號(hào)從0開(kāi)始的32種狀態(tài)分別規(guī)定了特殊的用途,一但終端、打印機(jī)遇上約定好的這些字節(jié)被傳過(guò)來(lái)時(shí),就要做一些約定的動(dòng)作。遇上00x10, 終端就換行,遇上0x07, 終端就向人們嘟嘟叫,例好遇上0x1b, 打印機(jī)就打印反白的字,或者終端就用彩色顯示字母。他們看到這樣很好,于是就把這些0x20以下的字節(jié)狀態(tài)稱為"控制碼"。
他們又把所有的空格、標(biāo)點(diǎn)符號(hào)、數(shù)字、大小寫(xiě)字母分別用連續(xù)的字節(jié)狀態(tài)表示,一直編到了第127號(hào),這樣計(jì)算機(jī)就可以用不同字節(jié)來(lái)存儲(chǔ)英語(yǔ)的文字了。大家看到這樣,都感覺(jué)很好,于是大家都把這個(gè)方案叫做 ANSI 的"Ascii"編碼(American Standard Code for Information Interchange,美國(guó)信息互換標(biāo)準(zhǔn)代碼)。當(dāng)時(shí)世界上所有的計(jì)算機(jī)都用同樣的ASCII方案來(lái)保存英文文字。
后來(lái),就像建造巴比倫塔一樣,世界各地的都開(kāi)始使用計(jì)算機(jī),但是很多國(guó)家用的不是英文,他們的字母里有許多是ASCII里沒(méi)有的,為了可以在計(jì)算機(jī)保存他們的文字,他們決定采用127號(hào)之后的空位來(lái)表示這些新的字母、符號(hào),還加入了很多畫(huà)表格時(shí)需要用下到的橫線、豎線、交叉等形狀,一直把序號(hào)編到了最后一個(gè)狀態(tài)255。從128到255這一頁(yè)的字符集被稱"擴(kuò)展字符集"。從此之后,貪婪的人類再?zèng)]有新的狀態(tài)可以用了,美帝國(guó)主義可能沒(méi)有想到還有第三世界國(guó)家的人們也希望可以用到計(jì)算機(jī)吧!
等中國(guó)人們得到計(jì)算機(jī)時(shí),已經(jīng)沒(méi)有可以利用的字節(jié)狀態(tài)來(lái)表示漢字,況且有6000多個(gè)常用漢字需要保存呢。但是這難不倒智慧的中國(guó)人民,我們不客氣地把那些127號(hào)之后的奇異符號(hào)們直接取消掉, 規(guī)定:一個(gè)小于127的字符的意義與原來(lái)相同,但兩個(gè)大于127的字符連在一起時(shí),就表示一個(gè)漢字,前面的一個(gè)字節(jié)(他稱之為高字節(jié))從0xA1用到0xF7,后面一個(gè)字節(jié)(低字節(jié))從0xA1到0xFE,這樣我們就可以組合出大約7000多個(gè)簡(jiǎn)體漢字了。在這些編碼里,我們還把數(shù)學(xué)符號(hào)、羅馬希臘的字母、日文的假名們都編進(jìn)去了,連在 ASCII 里本來(lái)就有的數(shù)字、標(biāo)點(diǎn)、字母都統(tǒng)統(tǒng)重新編了兩個(gè)字節(jié)長(zhǎng)的編碼,這就是常說(shuō)的"全角"字符,而原來(lái)在127號(hào)以下的那些就叫"半角"字符了。
中國(guó)人民看到這樣很不錯(cuò),于是就把這種漢字方案叫做 "GB2312"。GB2312 是對(duì) ASCII 的中文擴(kuò)展。
但是中國(guó)的漢字太多了,我們很快就就發(fā)現(xiàn)有許多人的人名沒(méi)有辦法在這里打出來(lái),特別是某些很會(huì)麻煩別人的國(guó)家領(lǐng)導(dǎo)人。于是我們不得不繼續(xù)把 GB2312 沒(méi)有用到的碼位找出來(lái)老實(shí)不客氣地用上。
后來(lái)還是不夠用,于是干脆不再要求低字節(jié)一定是127號(hào)之后的內(nèi)碼,只要第一個(gè)字節(jié)是大于127就固定表示這是一個(gè)漢字的開(kāi)始,不管后面跟的是不是擴(kuò)展字符集里的內(nèi)容。結(jié)果擴(kuò)展之后的編碼方案被稱為 GBK 標(biāo)準(zhǔn),GBK 包括了 GB2312 的所有內(nèi)容,同時(shí)又增加了近20000個(gè)新的漢字(包括繁體字)和符號(hào)。
后來(lái)少數(shù)民族也要用電腦了,于是我們?cè)贁U(kuò)展,又加了幾千個(gè)新的少數(shù)民族的字,GBK 擴(kuò)成了 GB18030。從此之后,中華民族的文化就可以在計(jì)算機(jī)時(shí)代中傳承了。
中國(guó)的程序員們看到這一系列漢字編碼的標(biāo)準(zhǔn)是好的,于是通稱他們叫做 "DBCS"(Double Byte Charecter Set 雙字節(jié)字符集)。在DBCS系列標(biāo)準(zhǔn)里,最大的特點(diǎn)是兩字節(jié)長(zhǎng)的漢字字符和一字節(jié)長(zhǎng)的英文字符并存于同一套編碼方案里,因此他們寫(xiě)的程序?yàn)榱酥С种形奶幚恚仨氁⒁庾执锏拿恳粋€(gè)字節(jié)的值,如果這個(gè)值是大于127的,那么就認(rèn)為一個(gè)雙字節(jié)字符集里的字符出現(xiàn)了。那時(shí)候凡是受過(guò)加持,會(huì)編程的計(jì)算機(jī)僧侶們都要每天念下面這個(gè)咒語(yǔ)數(shù)百遍:
"一個(gè)漢字算兩個(gè)英文字符!一個(gè)漢字算兩個(gè)英文字符......"
因?yàn)楫?dāng)時(shí)各個(gè)國(guó)家都像中國(guó)這樣搞出一套自己的編碼標(biāo)準(zhǔn),結(jié)果互相之間誰(shuí)也不懂誰(shuí)的編碼,誰(shuí)也不支持別人的編碼,連大陸和臺(tái)灣這樣只相隔了150海里,使用著同一種語(yǔ)言的兄弟地區(qū),也分別采用了不同的 DBCS 編碼方案。當(dāng)時(shí)的中國(guó)人想讓電腦顯示漢字,就必須裝上一個(gè)"漢字系統(tǒng)",專門用來(lái)處理漢字的顯示、輸入的問(wèn)題,但是那個(gè)臺(tái)灣的愚昧封建人士寫(xiě)的算命程序就必須加裝另一套支持 BIG5 編碼的什么"倚天漢字系統(tǒng)"才可以用,裝錯(cuò)了字符系統(tǒng),顯示就會(huì)亂了套!這怎么辦?而且世界民族之林中還有那些一時(shí)用不上電腦的窮苦人民,他們的文字又怎么辦?
真是計(jì)算機(jī)的巴比倫塔命題啊!
正在這時(shí),大天使加百列及時(shí)出現(xiàn)了:一個(gè)叫 ISO (國(guó)際標(biāo)誰(shuí)化組織)的國(guó)際組織決定著手解決這個(gè)問(wèn)題。他們采用的方法很簡(jiǎn)單:廢了所有的地區(qū)性編碼方案,重新搞一個(gè)包括了地球上所有文化、所有字母和符號(hào)的編碼!他們打算叫它"Universal Multiple-Octet Coded Character Set",簡(jiǎn)稱 UCS, 俗稱 "UNICODE"。
UNICODE 開(kāi)始制訂時(shí),計(jì)算機(jī)的存儲(chǔ)器容量極大地發(fā)展了,空間再也不成為問(wèn)題了。于是 ISO 就直接規(guī)定必須用兩個(gè)字節(jié),也就是16位來(lái)統(tǒng)一表示所有的字符,對(duì)于ascii里的那些"半角"字符,UNICODE 包持其原編碼不變,只是將其長(zhǎng)度由原來(lái)的8位擴(kuò)展為16位,而其他文化和語(yǔ)言的字符則全部重新統(tǒng)一編碼。由于"半角"英文符號(hào)只需要用到低8位,所以其高8位永遠(yuǎn)是0,因此這種大氣的方案在保存英文文本時(shí)會(huì)多浪費(fèi)一倍的空間。
這時(shí)候,從舊社會(huì)里走過(guò)來(lái)的程序員開(kāi)始發(fā)現(xiàn)一個(gè)奇怪的現(xiàn)象:他們的strlen函數(shù)靠不住了,一個(gè)漢字不再是相當(dāng)于兩個(gè)字符了,而是一個(gè)!是的,從 UNICODE 開(kāi)始,無(wú)論是半角的英文字母,還是全角的漢字,它們都是統(tǒng)一的"一個(gè)字符"!同時(shí),也都是統(tǒng)一的"兩個(gè)字節(jié)",請(qǐng)注意"字符"和"字節(jié)"兩個(gè)術(shù)語(yǔ)的不同,"字節(jié)"是一個(gè)8位的物理存貯單元,而"字符"則是一個(gè)文化相關(guān)的符號(hào)。在UNICODE 中,一個(gè)字符就是兩個(gè)字節(jié)。一個(gè)漢字算兩個(gè)英文字符的時(shí)代已經(jīng)快過(guò)去了。
從前多種字符集存在時(shí),那些做多語(yǔ)言軟件的公司遇上過(guò)很大麻煩,他們?yōu)榱嗽诓煌膰?guó)家銷售同一套軟件,就不得不在區(qū)域化軟件時(shí)也加持那個(gè)雙字節(jié)字符集咒語(yǔ),不僅要處處小心不要搞錯(cuò),還要把軟件中的文字在不同的字符集中轉(zhuǎn)來(lái)轉(zhuǎn)去。UNICODE 對(duì)于他們來(lái)說(shuō)是一個(gè)很好的一攬子解決方案,于是從 Windows NT 開(kāi)始,MS 趁機(jī)把它們的操作系統(tǒng)改了一遍,把所有的核心代碼都改成了用 UNICODE 方式工作的版本,從這時(shí)開(kāi)始,WINDOWS 系統(tǒng)終于無(wú)需要加裝各種本土語(yǔ)言系統(tǒng),就可以顯示全世界上所有文化的字符了。
但是,UNICODE 在制訂時(shí)沒(méi)有考慮與任何一種現(xiàn)有的編碼方案保持兼容,這使得 GBK 與UNICODE 在漢字的內(nèi)碼編排上完全是不一樣的,沒(méi)有一種簡(jiǎn)單的算術(shù)方法可以把文本內(nèi)容從UNICODE編碼和另一種編碼進(jìn)行轉(zhuǎn)換,這種轉(zhuǎn)換必須通過(guò)查表來(lái)進(jìn)行。
如前所述,UNICODE 是用兩個(gè)字節(jié)來(lái)表示為一個(gè)字符,他總共可以組合出65535不同的字符,這大概已經(jīng)可以覆蓋世界上所有文化的符號(hào)。如果還不夠也沒(méi)有關(guān)系,ISO已經(jīng)準(zhǔn)備了UCS-4方案,說(shuō)簡(jiǎn)單了就是四個(gè)字節(jié)來(lái)表示一個(gè)字符,這樣我們就可以組合出21億個(gè)不同的字符出來(lái)(最高位有其他用途),這大概可以用到銀河聯(lián)邦成立那一天吧!
UNICODE 來(lái)到時(shí),一起到來(lái)的還有計(jì)算機(jī)網(wǎng)絡(luò)的興起,UNICODE 如何在網(wǎng)絡(luò)上傳輸也是一個(gè)必須考慮的問(wèn)題,于是面向傳輸?shù)谋姸?UTF(UCS Transfer Format)標(biāo)準(zhǔn)出現(xiàn)了,顧名思義,UTF8就是每次8個(gè)位傳輸數(shù)據(jù),而UTF16就是每次16個(gè)位,只不過(guò)為了傳輸時(shí)的可靠性,從UNICODE到UTF時(shí)并不是直接的對(duì)應(yīng),而是要過(guò)一些算法和規(guī)則來(lái)轉(zhuǎn)換。
受到過(guò)網(wǎng)絡(luò)編程加持的計(jì)算機(jī)僧侶們都知道,在網(wǎng)絡(luò)里傳遞信息時(shí)有一個(gè)很重要的問(wèn)題,就是對(duì)于數(shù)據(jù)高低位的解讀方式,一些計(jì)算機(jī)是采用低位先發(fā)送的方法,例如我們PC機(jī)采用的 INTEL 架構(gòu),而另一些是采用高位先發(fā)送的方式,在網(wǎng)絡(luò)中交換數(shù)據(jù)時(shí),為了核對(duì)雙方對(duì)于高低位的認(rèn)識(shí)是否是一致的,采用了一種很簡(jiǎn)便的方法,就是在文本流的開(kāi)始時(shí)向?qū)Ψ桨l(fā)送一個(gè)標(biāo)志符。如果之后的文本是高位在位,那就發(fā)送"FEFF",反之,則發(fā)送"FFFE"。不信你可以用二進(jìn)制方式打開(kāi)一個(gè)UTF-X格式的文件,看看開(kāi)頭兩個(gè)字節(jié)是不是這兩個(gè)字節(jié)?
講到這里,我們?cè)夙槺阏f(shuō)說(shuō)一個(gè)很著名的奇怪現(xiàn)象:當(dāng)你在 windows 的記事本里新建一個(gè)文件,輸入"聯(lián)通"兩個(gè)字之后,保存,關(guān)閉,然后再次打開(kāi),你會(huì)發(fā)現(xiàn)這兩個(gè)字已經(jīng)消失了,代之的是幾個(gè)亂碼!呵呵,有人說(shuō)這就是聯(lián)通之所以拼不過(guò)移動(dòng)的原因。
其實(shí)這是因?yàn)镚B2312編碼與UTF8編碼產(chǎn)生了編碼沖撞的原因。
從網(wǎng)上引來(lái)一段從UNICODE到UTF8的轉(zhuǎn)換規(guī)則:
Unicode
UTF-8
0000 - 007F
0xxxxxxx
0080 - 07FF
110xxxxx 10xxxxxx
0800 - FFFF
1110xxxx 10xxxxxx 10xxxxxx
例如"漢"字的Unicode編碼是6C49。6C49在0800-FFFF之間,所以要用3字節(jié)模板:1110xxxx 10xxxxxx 10xxxxxx。將6C49寫(xiě)成二進(jìn)制是:0110 1100 0100 1001,將這個(gè)比特流按三字節(jié)模板的分段方法分為0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,這就是其UTF8的編碼。
而當(dāng)你新建一個(gè)文本文件時(shí),記事本的編碼默認(rèn)是ANSI, 如果你在ANSI的編碼輸入漢字,那么他實(shí)際就是GB系列的編碼方式,在這種編碼下,"聯(lián)通"的內(nèi)碼是:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
注意到了嗎?第一二個(gè)字節(jié)、第三四個(gè)字節(jié)的起始部分的都是"110"和"10",正好與UTF8規(guī)則里的兩字節(jié)模板是一致的,于是再次打開(kāi)記事本時(shí),記事本就誤認(rèn)為這是一個(gè)UTF8編碼的文件,讓我們把第一個(gè)字節(jié)的110和第二個(gè)字節(jié)的10去掉,我們就得到了"00001 101010",再把各位對(duì)齊,補(bǔ)上前導(dǎo)的0,就得到了"0000 0000 0110 1010",不好意思,這是UNICODE的006A,也就是小寫(xiě)的字母"j",而之后的兩字節(jié)用UTF8解碼之后是0368,這個(gè)字符什么也不是。這就是只有"聯(lián)通"兩個(gè)字的文件沒(méi)有辦法在記事本里正常顯示的原因。
而如果你在"聯(lián)通"之后多輸入幾個(gè)字,其他的字的編碼不見(jiàn)得又恰好是110和10開(kāi)始的字節(jié),這樣再次打開(kāi)時(shí),記事本就不會(huì)堅(jiān)持這是一個(gè)utf8編碼的文件,而會(huì)用ANSI的方式解讀之,這時(shí)亂碼又不出現(xiàn)了。
2010年1月1日
 #include <iostream> #include <iostream>
using namespace std;
const int M=10;
char map[2][M][M];
bool vis[2][M][M];
  int dx[]={1,0,-1,0}; int dx[]={1,0,-1,0};
int dy[]={0,1,0,-1};
struct point
{
 int layer; int layer;
int x,y;
int time;
 }Q[200]; }Q[200];
bool BFS(int m,int n,int t)
{
point now,next;
now.layer=now.x=now.y=now.time=0;
int Front=0;
int Near=1;
Q[Front]=now;
vis[now.layer][now.x][now.y]=true;
while(Front<Near)
  { {
now=Q[Front++];
if(map[now.layer][now.x][now.y]=='P')
{
if(now.time<=t)
return true;
return false;
 } }
if(map[now.layer][now.x][now.y]=='#')
now.layer=!now.layer;
if(map[now.layer][now.x][now.y]=='P')
{
if(now.time<=t)
return true;
return false;
}
if(map[now.layer][now.x][now.y]=='*'||map[now.layer][now.x][now.y]=='#')
continue;
int k;
for(k=0;k<4;k++)
{
next.layer=now.layer;
next.time=now.time+1;
next.x=now.x+dx[k];
next.y=now.y+dy[k];
if(!vis[next.layer][next.x][next.y]&&next.x>=0&&next.x<m&&next.y>=0&&next.y<n)
{
Q[Near++]=next;
vis[next.layer][next.x][next.y]=true;
}
}
}
return false;
}
int main()
{
int T;
scanf("%d",&T);
while(T--)
{
int m,n,t;
scanf("%d%d%d",&m,&n,&t);
int i,j,k;
for(k=0;k<2;k++)
{
for(i=0;i<m;i++)
{
char s[M];
scanf("%s",&s);
for(j=0;j<n;j++)
{
map[k][i][j]=s[j];
vis[k][i][j]=false;
}
}
}
if(BFS(m,n,t))
printf("YES\n");
else
printf("NO\n");
}
system("pause");
return 0;
}
#include <iostream>
using namespace std;
const int M=10;
bool userow[M][M],usecol[M][M],useblock[M][M];
int map[M][M];
struct node{
int x,y;
int num;
}sudu[M*M];
int find(int x,int y)
{
int row=x/3;
int col=y/3;
return 3*row+col;
}
bool dfs(int n,int cnt)
{
if(n==cnt)return 1;
int i;
for(i=1;i<M;i++)
{
if(!userow[sudu[n].x][i]&&!usecol[sudu[n].y][i]&&!useblock[find(sudu[n].x,sudu[n].y)][i])
{
userow[sudu[n].x][i]=true;
usecol[sudu[n].y][i]=true;
useblock[find(sudu[n].x,sudu[n].y)][i]=true;
sudu[n].num=i;
if(dfs(n+1,cnt))
return 1;
userow[sudu[n].x][i]=false;
usecol[sudu[n].y][i]=false;
useblock[find(sudu[n].x,sudu[n].y)][i]=false;
sudu[n].num=0;
}
}
return 0;
}
int main()
{
int T;
scanf("%d",&T);
while(T--)
{
memset(userow,false,sizeof(userow));
memset(usecol,false,sizeof(usecol));
memset(useblock,false,sizeof(useblock));
int i,j;
int cnt=0;
for(i=0;i<M-1;i++)
{
char mess[M];
scanf("%s",&mess);
for(j=0;j<M-1;j++)
{
map[i][j]=mess[j]-'0';
if(map[i][j])
{
userow[i][map[i][j]]=true;
usecol[j][map[i][j]]=true;
useblock[find(i,j)][map[i][j]]=true;
}
else
{
sudu[cnt].x=i;
sudu[cnt].y=j;
sudu[cnt].num=0;
cnt++;
}
}
}
dfs(0,cnt);
for(i=0;i<cnt;i++)
map[sudu[i].x][sudu[i].y]=sudu[i].num;
for(i=0;i<M-1;i++){
for(j=0;j<M-1;j++)
printf("%d",map[i][j]);
printf("\n");
}
}
return 0;
}
2009年11月21日
摘要:
#include <iostream>using namespace std;const int maxn=200;const int INF=1000000;int g[maxn][maxn];int f[maxn][maxn];int r[maxn][maxn];in... 閱讀全文
2009年10月5日
#include <iostream>
#include <algorithm>
using namespace std;
const int maxn=12;
int n;
double p;
struct matrix
{
double m[2][2];
};
int mine[maxn];
matrix operator*(const matrix&a,const matrix&b)
{
matrix tmp;
int i,j,k;
for(i=0;i<2;i++)
for(j=0;j<2;j++)
{
tmp.m[i][j]=0;
for(k=0;k<2;k++)
tmp.m[i][j]+=a.m[i][k]*b.m[k][j];
}
return tmp;
}
matrix power(int k)
{
matrix tmp,res;
matrix A;
A.m[0][0]=p,A.m[0][1]=1-p,A.m[1][0]=1,A.m[1][1]=0;
matrix B;
B.m[0][0]=1,B.m[0][1]=0,B.m[1][0]=0,B.m[1][1]=1;
if(k==0)
return B;
if(k==1)
return A;
else
{
tmp=power(k/2);
res=tmp*tmp;
if(k%2==1)
res=res*A;
return res;
}
}
void slove(int n,double p)
{
double a=1,b=0;
int i;
for(i=0;i<n;i++)
scanf("%d",&mine[i]);
sort(mine,mine+n);
double f2=1.0,f1=0.0;
int now=1;
for(i=0;i<n;i++)
{
if((mine[i]-1)-now>=0)
{
matrix tmp=power(mine[i]-1-now);
f2=(tmp.m[0][0]*f2+tmp.m[0][1]*f1)*(1-p);
f1=0;
now=mine[i]+1;
}
else
{
printf("%.7lf\n",0.0);
return;
}
}
printf("%.7lf\n",f2);
}
int main()
{
while(scanf("%d %lf",&n,&p)!=EOF)
slove(n,p);
return 0;
}
#include <iostream>
using namespace std;
const int maxn=1005;
__int64 n,m;
__int64 F[maxn];
int c[maxn][maxn];
int cal(int n)
{
int t = 1;
while (t <= n) t = t * 2 + 1;
t = (t - 1) / 2;
t = (t - 1) / 2;
int sum = n - 1 - t;
if (sum > 2 * t + 1) {
sum = 2 * t + 1;
}
return sum;
}
void calc_c() {
for (int i = 0; i < maxn; i++)
{
c[i][0] = c[i][i] = 1;
for (int j = 1; j < i; j++)
{
c[i][j] = (c[i - 1][j - 1] + c[i - 1][j]) % m;
}
}
}
__int64 slove(int n)
{
if(F[n])
return F[n];
if(n==0||n==1)
return 1;
int left=cal(n);
int right=(n-1)-left;
return F[n]=( (slove(left)*slove(right) )%m )*(__int64)c[n-1][left]%m;
}
int main()
{
int T;
scanf("%d",&T);
while(T--)
{
memset(F,0,sizeof(F));
scanf("%I64d%I64d",&n,&m);
calc_c();
__int64 ans=slove(n);
printf("%I64d\n",ans);
}
return 0;
}
|